论文题目:《MobileFaceNets: Efficient CNNs for Accurate RealTime Face Verification on Mobile Devices》
论文地址:https://arxiv.org/pdf/1804.07573v4.pdf
1.简介
近年来,MobilenetV1,ShuffleNet和MobileNetV2等轻量级网络多用于移动终端的视觉识别任务,但是由于人脸结构的特殊性,这些网络在人脸识别任务上并没有获得满意的效果。针对这一问题,提出了一种专门针对人脸识别的轻量级网络MobileFaceNet。
如下图所示,在使用MobileNetV2等网络进行人脸识别时,平均池化层对FMap-end的Corner Unit和Center Unit给予了同样的权重,但实际上,对于人脸识别来说,中心单元的重要程度显然比角单元重要。因此,需要对网络进行有针对性的优化。论文中,最重要的一个优化就是使用Global Depthwise Convolution (GDConv,全局逐深度卷积层)代替Global Average Pooling (GAP,全局平均池化层),因为GDConv的weights即相当于实现不同位置的重要性权重系数。
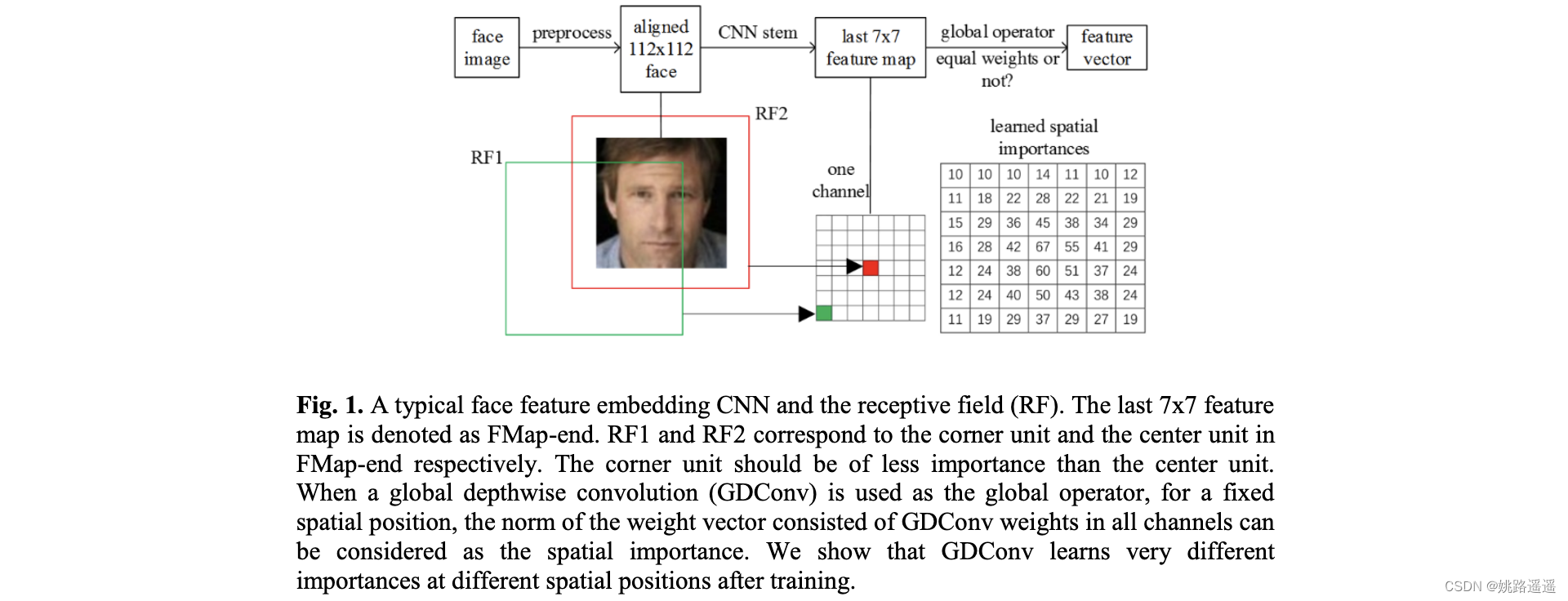
2.Global Depthwise Convolution(全局深度卷积)
作者采用全局深度卷积(GDConv)替代全局平均池化(GAP),GDConv层的kernel大小等于输入维度大小,pad=0,stride=1,GDConv的计算为:
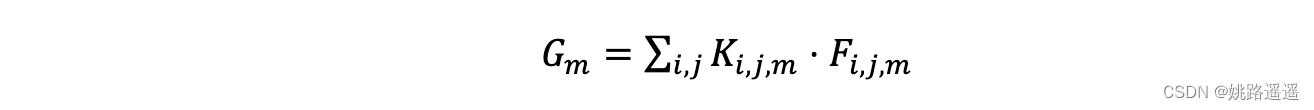
F是输入特征大小WxHxM,K是深度卷积核的大小WxHxM,G是输出大小1x1xM ,深度卷积的计算量为:
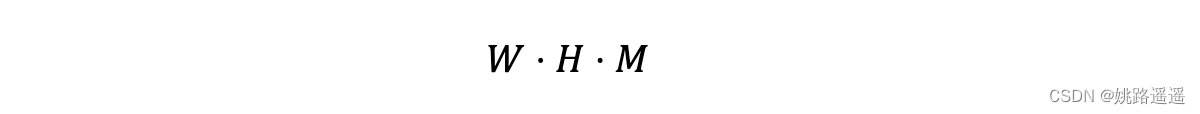
3.网络结构
作者采用MobileNetV2的bottlenecks作为构建网络的主要模块,在mobilefacenet中的bottlenecks比MobileNetV2更小,激励函数采用PReLu(比Relu稍好)此外,在网络的开始部分采用快速下采样,在最后几个卷积层采用早期降维,在线性全局深度卷积层后加入一个1x1的线性卷积层作为特征输出。在训练中采用批量正则化。
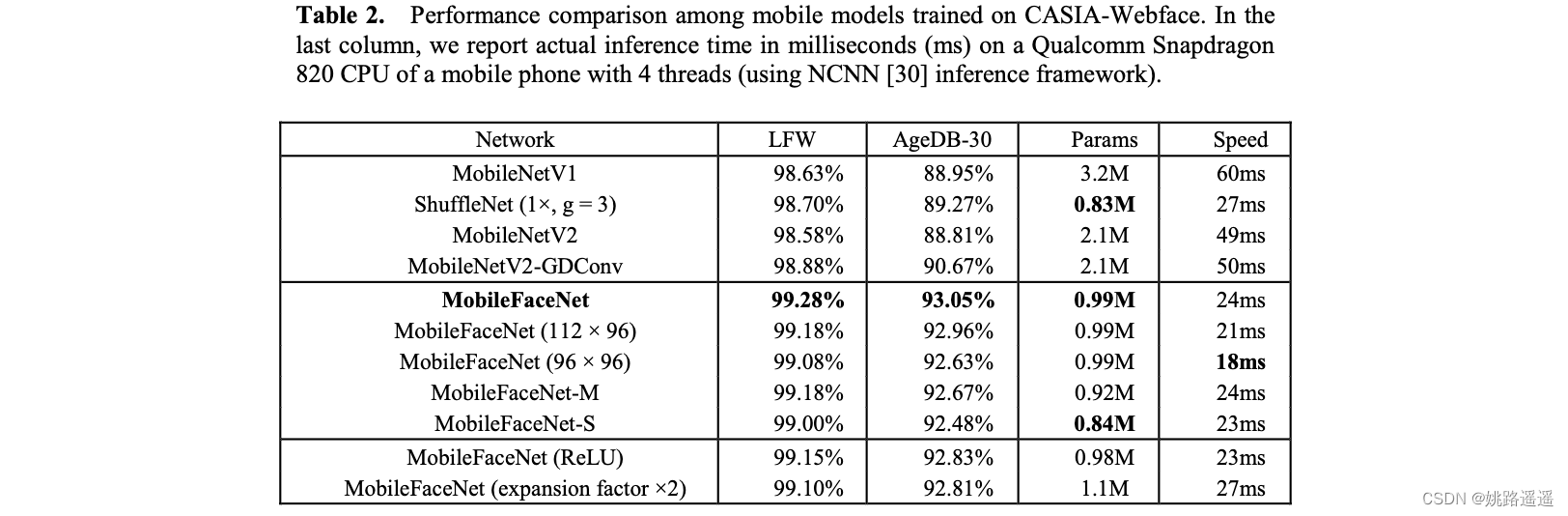
原始的网络计算量是221百万个MAdds,有99万个参数。为减少计算量,将输入维度从112x112改为112x96或96x96。为减少参数量,去掉GDConv 层之后的1x1卷积层,产生新的网络MobileFaceNet-M。在MobileFaceNet-M的基础上产生去掉GDConv layer之前的1x1卷积层,产生新的网络MobileFaceNet-S。

4.实验
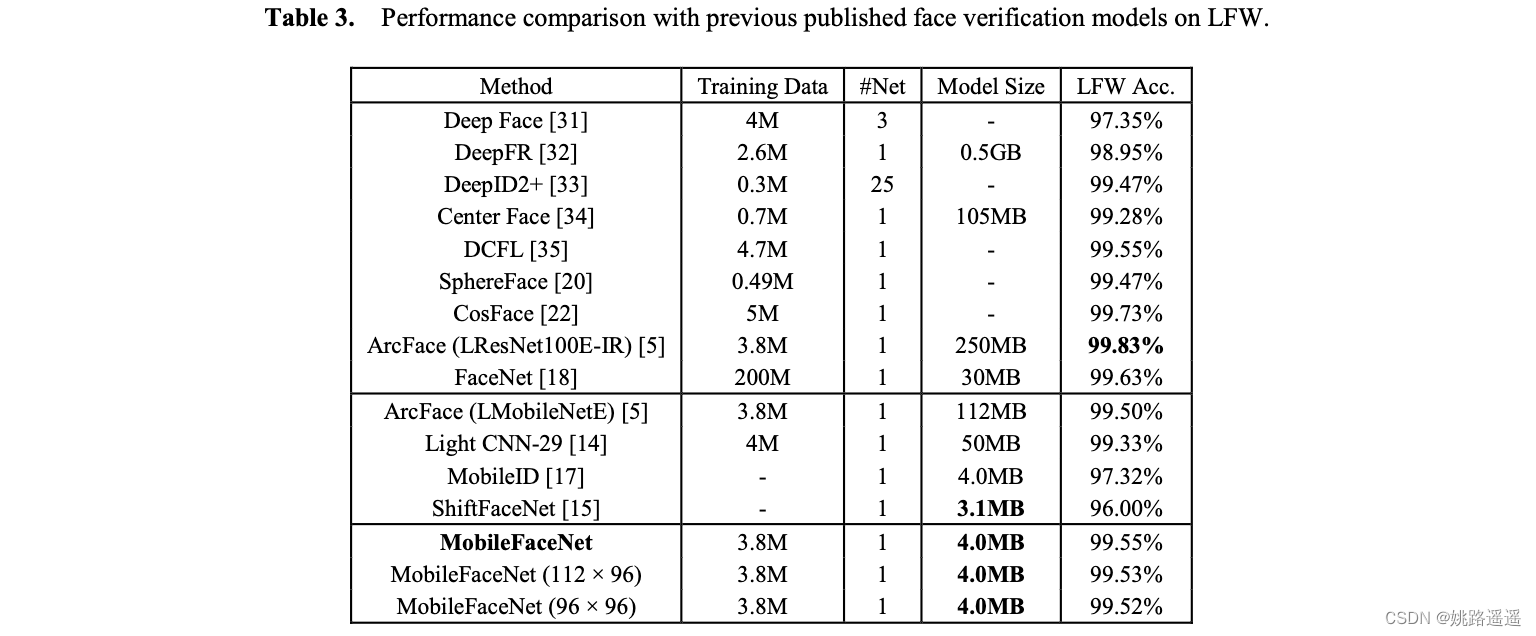
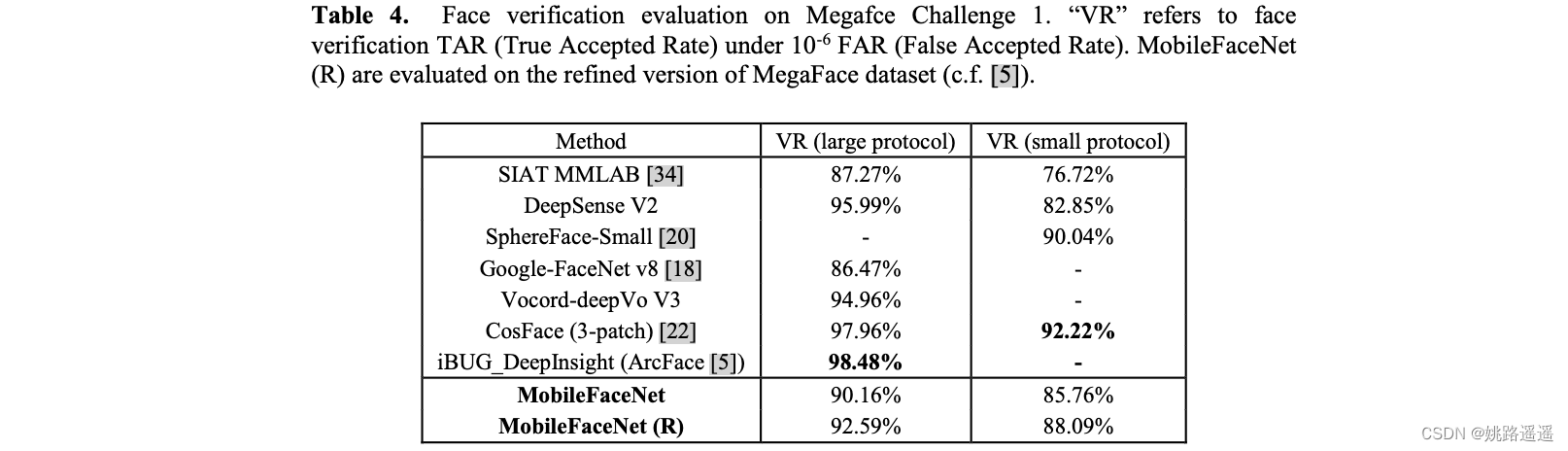
作者采用了MobileNetV1, ShuffleNet和MobileNetV2作为mobilefacenet的基础网络。衰减参数权重设置为4e-5,末端的全局操作层(GDConv或者GAPool)的衰减参数设置为4e-4。采用动量为0.9的SGD作为优化器,batch size设置为512,学习率从0.1开始,在36K、52K和58K次迭代中除以10。在第60K次迭代的时候停止训练。
代码
####################################### MobileFaceNet #############################################
class Conv_block(Module):
def __init__(self, in_c, out_c, kernel=(1, 1), stride=(1, 1), padding=(0, 0), groups=1):
super(Conv_block, self).__init__()
self.conv = Conv2d(in_c, out_channels=out_c, kernel_size=kernel, groups=groups, stride=stride, padding=padding, bias=False)
self.bn = BatchNorm2d(out_c)
self.prelu = PReLU(out_c)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.prelu(x)
return x
class Linear_block(Module):
def __init__(self, in_c, out_c, kernel=(1, 1), stride=(1, 1), padding=(0, 0), groups=1):
super(Linear_block, self).__init__()
self.conv = Conv2d(in_c, out_channels=out_c, kernel_size=kernel, groups=groups, stride=stride, padding=padding, bias=False)
self.bn = BatchNorm2d(out_c)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return x
class Depth_Wise(Module):
def __init__(self, in_c, out_c, residual = False, kernel=(3, 3), stride=(2, 2), padding=(1, 1), groups=1):
super(Depth_Wise, self).__init__()
self.conv = Conv_block(in_c, out_c=groups, kernel=(1, 1), padding=(0, 0), stride=(1, 1))
self.conv_dw = Conv_block(groups, groups, groups=groups, kernel=kernel, padding=padding, stride=stride)
self.project = Linear_block(groups, out_c, kernel=(1, 1), padding=(0, 0), stride=(1, 1))
self.residual = residual
def forward(self, x):
if self.residual:
short_cut = x
x = self.conv(x)
x = self.conv_dw(x)
x = self.project(x)
if self.residual:
output = short_cut + x
else:
output = x
return output
class Residual(Module):
def __init__(self, c, num_block, groups, kernel=(3, 3), stride=(1, 1), padding=(1, 1)):
super(Residual, self).__init__()
modules = []
for _ in range(num_block):
modules.append(Depth_Wise(c, c, residual=True, kernel=kernel, padding=padding, stride=stride, groups=groups))
self.model = Sequential(*modules)
def forward(self, x):
return self.model(x)
class MobileFaceNet(Module):
def __init__(self, embedding_size):
super(MobileFaceNet, self).__init__()
self.conv1 = Conv_block(3, 64, kernel=(3, 3), stride=(2, 2), padding=(1, 1))
self.conv2_dw = Conv_block(64, 64, kernel=(3, 3), stride=(1, 1), padding=(1, 1), groups=64)
self.conv_23 = Depth_Wise(64, 64, kernel=(3, 3), stride=(2, 2), padding=(1, 1), groups=128)
self.conv_3 = Residual(64, num_block=4, groups=128, kernel=(3, 3), stride=(1, 1), padding=(1, 1))
self.conv_34 = Depth_Wise(64, 128, kernel=(3, 3), stride=(2, 2), padding=(1, 1), groups=256)
self.conv_4 = Residual(128, num_block=6, groups=256, kernel=(3, 3), stride=(1, 1), padding=(1, 1))
self.conv_45 = Depth_Wise(128, 128, kernel=(3, 3), stride=(2, 2), padding=(1, 1), groups=512)
self.conv_5 = Residual(128, num_block=2, groups=256, kernel=(3, 3), stride=(1, 1), padding=(1, 1))
self.conv_6_sep = Conv_block(128, 512, kernel=(1, 1), stride=(1, 1), padding=(0, 0))
self.conv_6_dw = Linear_block(512, 512, groups=512, kernel=(7,7), stride=(1, 1), padding=(0, 0))
self.conv_6_flatten = Flatten()
self.linear = Linear(512, embedding_size, bias=False)
self.bn = BatchNorm1d(embedding_size)
def forward(self, x):
out = self.conv1(x)
out = self.conv2_dw(out)
out = self.conv_23(out)
out = self.conv_3(out)
out = self.conv_34(out)
out = self.conv_4(out)
out = self.conv_45(out)
out = self.conv_5(out)
out = self.conv_6_sep(out)
out = self.conv_6_dw(out)
out = self.conv_6_flatten(out)
out = self.linear(out)
out = self.bn(out)
return l2_norm(out)