常见的眼疾包括但不限于以下几种:
-
白内障:白内障是眼睛晶状体变得模糊或不透明,导致视力下降。它通常与年龄相关,但也可以由其他因素引起,如遗传、外伤、糖尿病等。
-
青光眼:青光眼是一组引起视神经损伤的眼病,常常由眼内压升高引起。如果不及时治疗,青光眼可能导致永久性视力损失。
-
视网膜疾病:视网膜是眼睛内的感光层,负责传输视觉信号到大脑。视网膜疾病包括视网膜脱落、黄斑变性等,可以导致中心视力丧失或视野缺损。
-
糖尿病视网膜病变:糖尿病患者可能会出现糖尿病视网膜病变,这是由于高血糖引起的视网膜损伤。如果不及时治疗,糖尿病视网膜病变可能导致严重的视力问题。
-
干眼症:干眼症是眼睛表面缺乏足够的泪液或泪液质量不良,导致眼睛干燥、疼痛、疲劳和视力模糊。
-
斜视:斜视是眼睛的位置或方向异常,导致双眼无法同时对准同一个物体。这可能会导致视觉模糊、眼睛疲劳和深度感知问题。
传统的眼疾大都是基于专业的医生和特殊的医疗设备来进行诊断分析的,而眼球的诊断拍摄图像本身就是可以用于构建识别模型的,这里本文的核心思想就是考虑来基于卷积神经网络模型来构建专用于眼疾诊断识别的辅助模型,首先看下效果图:

这里使用人工构建的数据集来模拟真实的医疗场景,共包含六种常见的眼疾类型,如下所示:
["cataract", "diabetic_retinopathy", "glaucoma", "high", "normal", "pathological"]接下来依次简单看下各类眼疾的数据,如下所示:
【白内障】
【糖尿病视网膜病变】
【青光眼】
【高度近视】

【正常眼球】

【病理性近视】

对原始数据集特性分布进行可视化如下所示:
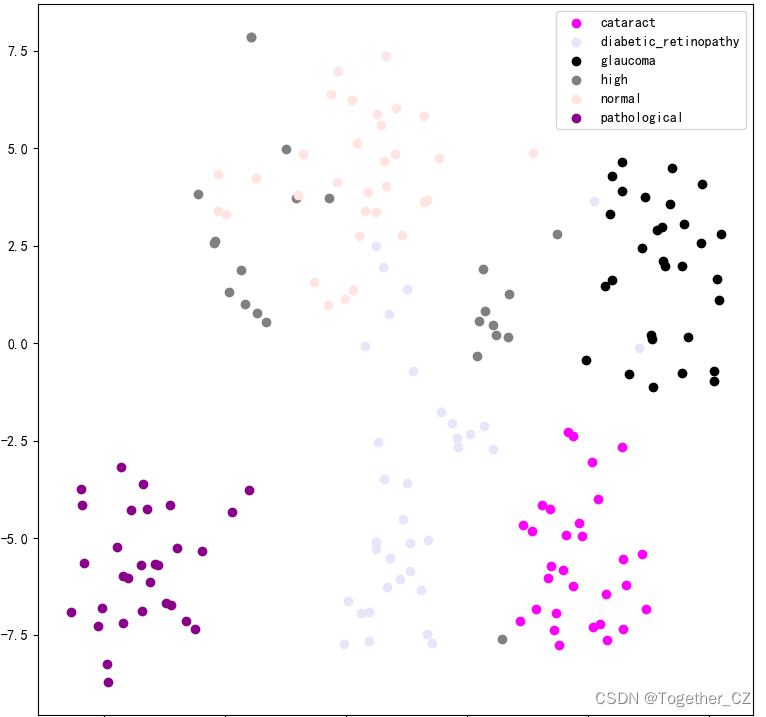
在我前面的文章中已经有不少相关的实践了,这里就不再详细的讲述整个处理流程了,为了便于使用,经过后面几个版本的迭代开发,这里我构建了一个轻量级 卷积神经网络模型开发训练框架,整体项目结构如下所示:
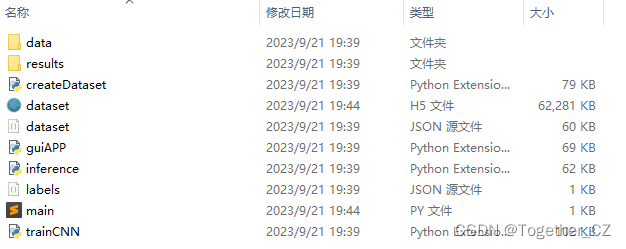
项目文件详情如下所示:
| 文件名称 | 文件说明 |
| data | 原始数据集目录 |
| results | 结果目录 |
| createDataset | 数据集处理模块 |
| dataset.h5 | 数据集 |
| dataset.json | 数据集文件 |
| guiAPP | 可视化系统模块 |
| inference | 离线推理模块 |
| labels.json | 标签类别清单 |
| trainCNN | 模型开发模块 |
| main.py | 总入口模块 |
之前有些伙伴反映,不同环境下容易出现代码或者是模块不匹配不兼容等问题,这里专门做了处理,最终形成了:
createDataset
trainCNN
inference
guiAPP四个基础组件,我提供了完整的方法可供使用,只需要编写简单的业务代码即可实现完整的建模流程,main.py即为自己需要编写的文件,如下所示:
import os
import createDataset
import trainCNN
#参数配置
dataDir="data/"
saveDir="results/"
#构建数据集
createDataset.randomSplit(dataDir=dataDir)
createDataset.buildH5Dataset()
#训练模型
if not os.path.exists(saveDir + "model.h5"):
trainCNN.trainModel(saveDir=saveDir)
#启动系统
import guiAPP
只需要不到10行的代码就可以构建属于自己的图像识别系统了,这里dataDir是自己的数据集目录,saveDir是自己指定的用于存储模型结果文件的目录,不需要自己创建,程序会自动创建,文完整的结果文件如下所示:
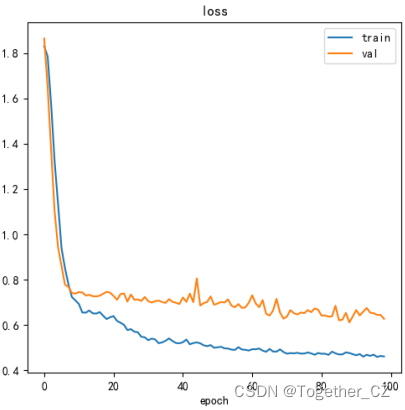
不仅会存储得到模型文件、权重等数据,还会对训练过程的loss和准确率进行自动的可视化,如下所示:
【准确率曲线】
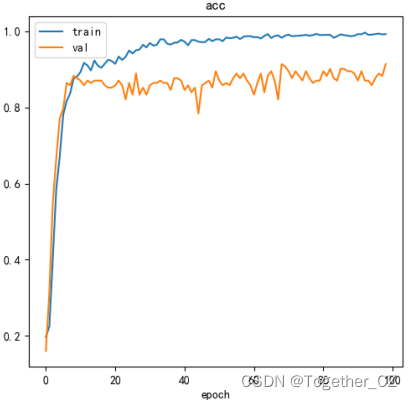
【损失值曲线】
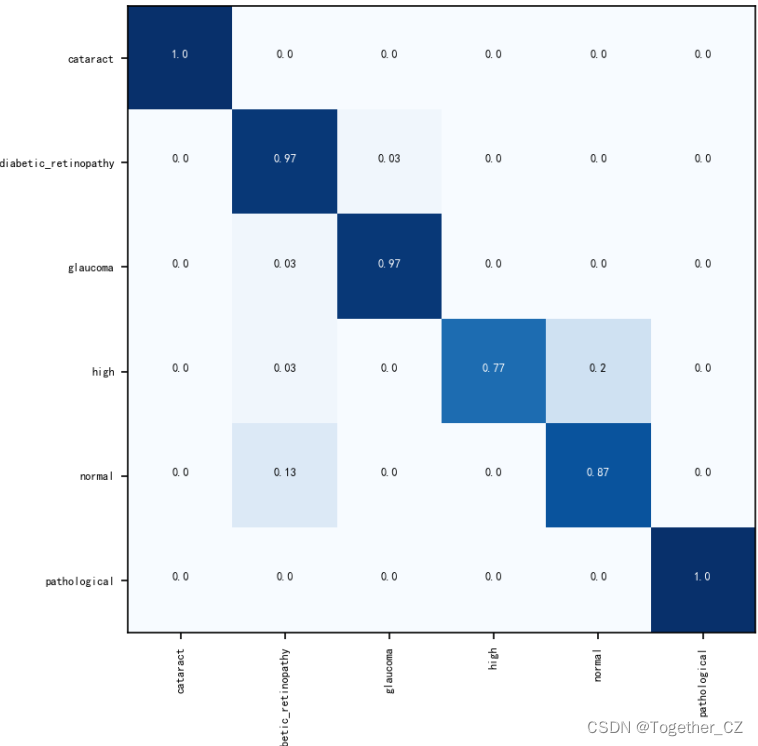
当然了,也可以自行绘制混淆矩阵,如下所示: