目录
完整系统是一个基于人脸识别的签到系统,包含一种改进卷积神经网络算法和基于FaceNet的人脸识别,耗时三个月,之前试过opencv+cnn、vgg16等,但是效果还是FaceNet更好些。因为一些原因,暂时还不能公开整个系统,后面会尽快更新的~,这里我们先介绍FaceNet这一部分,欢迎大家一起交流。
一、原理分析
FaceNet由谷歌提出,发表在CVPR 2015,论文地址FaceNet: A Unified Embedding for Face Recognition and Clustering,论文翻译解读可以参考https://blog.csdn.net/chenriwei2/article/details/45031677。
FaceNet是一种端到端的人脸识别网络,它直接学习图像到欧式空间上点的映射,对输入数据经过深度卷积神经网络生成特征向量,通过对比特征向量欧式距离,判断是否大于阈值来区分是否是同一个人脸。
模型结构如下图所示。

Batch为输入的图像,通过deep architecture(深度学习网络)提取特征,然后通过L2得到128维特征向量。
FaceNet的创新点是Triplet Loss,目标是使相同人的不通图片特征距离尽可能的小,不同人的特征距离尽可能的大,三元组损失如图所示。

损失函数的目的是让当前人脸图片Anchor与当前人的其他不同姿态人脸图片Positive距离尽量小,与当前不同人的人脸图片Negative距离尽量大,并且a、n和a、p之间有一个间隔
,目标公式如下。

从而损失函数如下

训练时所有样本都生成三元组计算资源太大,有的无需进行训练,所以训练时在每个batch里面,先选择a、p,然后选择符合条件的所有可能负样本,之后随机选出一个构造出三元组(a,p,n)进行训练。
二、FcaeNet源码使用
FaceNet的源码使用可以参考下面这篇文章,具有详细的步骤介绍。https://blog.csdn.net/u013044310/article/details/79556099
精简版源码下载地址:FaceNet精简
官方源码下载地址:FaceNet源码
精简版项目结构如下,适合初学者使用。

大家学习参考上面博客可以试着运行源码,就会对FaceNet有一些了解了,然后我们训练自己的数据集并对上述博客进行补充、优化。
三、爬虫自制数据集(提高亚洲人脸准确率)
网上对FaceNet大部分是通过训练svm分类器进行自制数据集的训练,可以参考这篇文章FaceNet源码使用方法及其迁移学习训练自己数据集的代码修改。
但是实用效果并不是很好,而且输入图片后需要经过svm得到类别,这样的话每次增加新的人脸都要重新训练svm分类模型,但是我们更希望通过FaceNet把特征向量存入数据库,然后通过比较特征向量的距离来区分人脸,这样有一个人脸图片输入后,只需要经过FaceNet得到特征向量后,把特征向量与数据库中的特征向量对比欧氏距离判断是否大于阈值就可以得到是否是同一个人的人脸,不需要重新训练模型。如下图模型得到的结果,相同人脸特征向量距离小于1,不同人脸特征向量距离大于1。


网上公开预训练模型为西方人脸图片,在亚洲人脸识别效果不是很好,那么如何增加亚洲人脸识别准确率呢,接下来我们进入探索吧。首先自制人脸数据集,我们通过爬虫进行网络亚洲明星人脸图片,然后结合公开亚洲人脸数据集CASIA-FaceV5制作出自制亚洲人脸数据集。用亚洲人脸数据集在预训练模型上进行再训练,也就是迁移学习训练模型,得到的亚洲人脸识别准确率就提高了很多,本文模型在自制数据集准确率达到99.8%,根据不同复杂度数据集进行十折交叉验证,准确率基本都在97%以上。当然如果感觉数据集数量再想增加一些,得到更好地亚州人脸识别模型,可以通过爬取更多的图片或者通过旋转一定的角度等进行数据增强。爬取图片代码如下。
1.写入想要下载的明星名字.
// An highlighted block
import json
import requests
//爬取网站明星名字并存入文件starName.txt
def getManyPages(pages):
params = []
for i in range(0, 12 * pages + 12, 12):
params.append({
'resource_id': 28266,
# 'from_mid': 1,
# 'format': 'json',
# 'ie': 'utf-8',
# 'oe': 'utf-8',
'query': '明星',
# 'sort_key': '',
# 'sort_type': 1,
# 'stat0': '',
'stat1': '内地',
# 'stat2': '',
# 'stat3': '',
'pn': i,
'rn': 12
})
url = 'https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php'
x = 0
f = open('starName.txt', 'w',encoding='utf-8') #要写入的文件名
for param in params:
try:
res = requests.get(url, params=param)
print(res)
print(res.text)
js = json.loads(res.text)
print(js.get('data')[0])
print(js.get('data')[0].get('result'))
results = js.get('data')[0].get('result')
except AttributeError as e:
print(e)
continue
for result in results:
img_name = result['ename']
f.write(img_name + '\n')
if x % 10 == 0:
print('第%d页......' % x)
x += 1
f.close()
if __name__ == '__main__':
getManyPages(25)
2.图片下载.
// 根据文件starName.txt中的明星名字进行下载图片
import os
from icrawler.builtin import BingImageCrawler
path = 'data/facebaidu/' #图片存储路径
f = open('starName.txt', 'r',encoding='utf-8')
lines = f.readlines()
for i, line in enumerate(lines):
name = line.strip('\n')
file_path = os.path.join(path, name)
if not os.path.exists(file_path):
os.makedirs(file_path)
bing_storage = {'root_dir': file_path}
bing_crawler = BingImageCrawler(parser_threads=2, downloader_threads=4, storage=bing_storage)#解析器数目2,下载线程数目4
bing_crawler.crawl(keyword=name, max_num=10) #每人下载10张
print('第{}位明星:{}'.format(i, name))
然后小编给大家提供了一些数据集,在人脸识别领域使用较多。因为网上很多数据集下载需要积分或者网站失效、外网下载缓慢等各种原因下不下来,小编当时也废了好多时间找各种数据集哈哈哈,所以小编为了方便大家研究,提供了一些公开数据集,可以直接下载。
(1)经典的ORL数据集:ORL数据集
链接:https://pan.baidu.com/s/1gtnHibVFbkjR3IhAIUSwhQ
提取码:451h
(2)包含遮挡等环境的AR数据集:AR数据集
链接:https://pan.baidu.com/s/1zbTAKtBwo8txopCcNDjcyg
提取码:kdzp
(3)标准人脸识别验证集-LFW数据集:LFW数据集
链接:https://pan.baidu.com/s/14DsiN8CP9LmKuU3fuetdXQ
提取码:047o
官网下载:http://vis-www.cs.umass.edu/lfw/
(4)亚洲人脸数据集facev5(0-99):face数据集
链接:https://pan.baidu.com/s/18H4WXpRfd_xoht0GN3I3qQ
提取码:afxa
完整版官网:http://biometrics.idealtest.org/dbDetailForUser.do?id=9
(5)因为FaceNet输入为160x160,所以小编提供了处理好的图片,亚洲人脸数据集facev5(0-99):face_160数据集
链接:https://pan.baidu.com/s/1wxRh2cjKP1nA3Cbrqk9PlA
提取码:jba5
(6)有的人可能刚开始可能想用简单的CNN进行人脸识别,输入分辨率一般稍小一点,所以小编也提供了一份64x64亚洲人脸数据集facev5(0-99),方便大家研究:face_64数据集
链接:https://pan.baidu.com/s/1r7FRGjoZ1Hh382TRcxXrcQ
提取码:63x8
自制数据集制作好后,进行预处理,调成160x160x3格式,然后进行训练。只需要修改train_tripletloss.py中的训练文件路径就行,预训练模型填写2017年或者2018年的预训练模型都可以,在第二部分FaceNet源码介绍那里你已经见到过了,怎么加载预训练模型,为了方便当然这里下图也进行了标注,只需要修改下图的两个部分就行,第一个是预训练模型的路径,第二个是训练数据集的路径,相对路径或者绝对路径都行,然后运行开始训练,训练好的模型保存在第二个参数‘models_base_dir’路径里面,可以在这里进行修改。
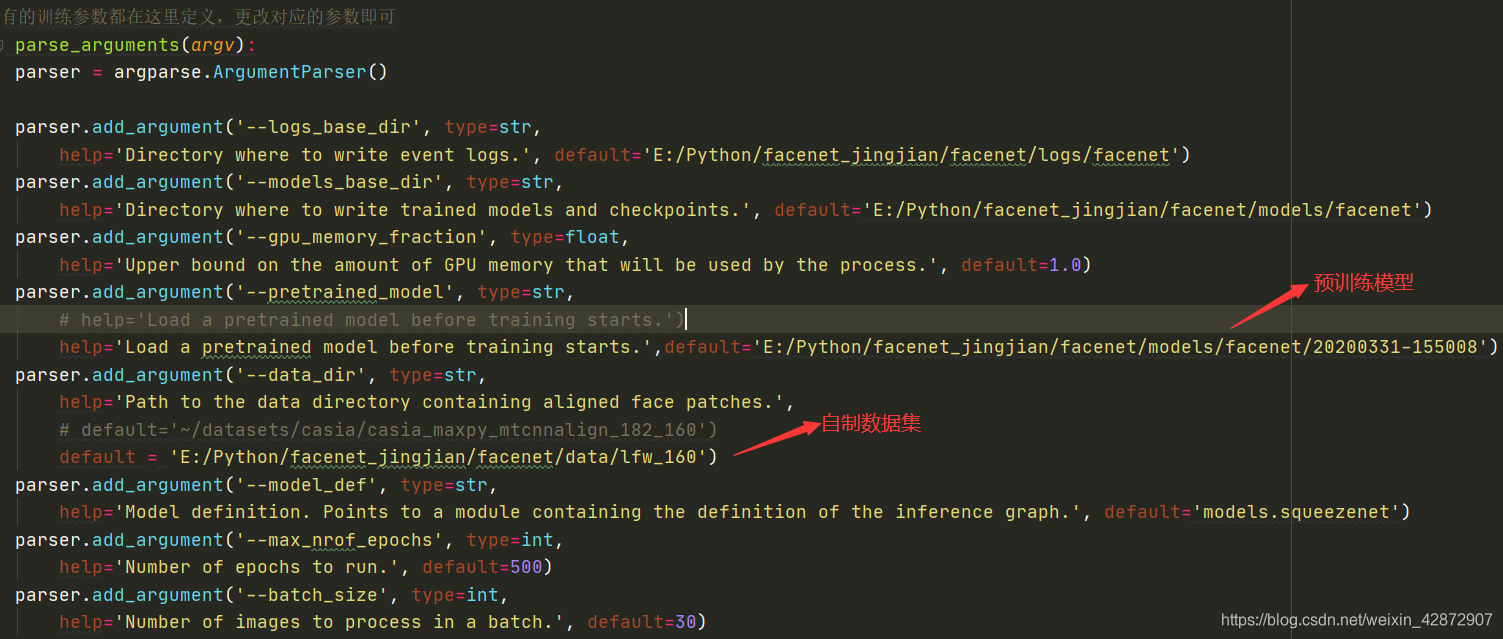
四、加载预训练模型
第二部分时大家已经是用过官网的2017预训练模型了,这里小编把一些预训练模型总结如下,同时提供给大家小编在自制数据集上用gpu训练好久的模型,提高了亚洲人脸识别准确率,三种模型在LFW验证pairs文档上,准确率都在99.0%以上。
(1)2017模型,基于MS-Celeb-1M人脸库:
链接:https://pan.baidu.com/s/1y9C_MpiJ1JTg27wGKwja5w
提取码:rtnk
(2)2018模型:
链接:https://pan.baidu.com/s/130zia7lMY1xw2uB5RQMRGw
提取码:a9ia
(3)自制数据集2020模型:
链接:https://pan.baidu.com/s/1xDF9Sc0vvNLd7WsR2ijPvw
提取码:9v5z
使用自制数据集训练模型进行测试,选择两个不同人脸,如下图,可以看到距离更大了,利于更好地区分人脸。

五、加载自制pairs验证文档
我们需要对自制数据集进行验证,FaceNet源码中使用pairs.txt进行准确率测试,接下来介绍自制数据集如何自制pairs.txt,代码如下。
自制pairs.txt验证集.
import glob
import os.path
import numpy as np
import os
# 图片数据文件夹
INPUT_DATA = 'data/facev5_160/'
def create_image_lists():
matched_result = set()
k = 0
# 获取当前目录下所有的子目录,这里x 是一个三元组(root,dirs,files),第一个元素表示INPUT_DATA当前目录,
# 第二个元素表示当前目录下的所有子目录,第三个元素表示当前目录下的所有的文件
sub_dirs = [x[0] for x in os.walk(INPUT_DATA)]
while len(matched_result) < 1000:
for sub_dir in sub_dirs[1:]:
# 获取当前目录下所有的有效图片文件
extensions = 'png'
# 把图片存放在file_list列表里
file_list = []
# os.path.basename(sub_dir)返回sub_sir最后的文件名
dir_name = os.path.basename(sub_dir)
file_glob = os.path.join(INPUT_DATA, dir_name, '*.' + extensions)
# glob.glob(file_glob)获取指定目录下的所有图片,存放在file_list中
file_list.extend(glob.glob(file_glob))
if not file_list: continue
# 通过目录名获取类别的名称
label_name = dir_name
length = len(file_list)
random_number1 = np.random.randint(50)
random_number2 = np.random.randint(50)
base_name1 = os.path.basename(file_list[random_number1 % length]) # 获取文件的名称
base_name2 = os.path.basename(file_list[ random_number2 % length])
if(file_list[random_number1%length] != file_list[random_number2%length]):
# 将当前类别的数据放入结果字典
matched_result.add(label_name +'\t'+ base_name1+ '\t'+ base_name2)
k = k + 1
# 返回整理好的所有数据
return matched_result, k
#创建pairs.txt
def create_pairs():
unmatched_result = set() # 不同类的匹配对
k = 0
sub_dirs = [x[0] for x in os.walk(INPUT_DATA)]
# sub_dirs[0]表示当前文件夹本身的地址,不予考虑,只考虑他的子目录
for sub_dir in sub_dirs[1:]:
# 获取当前目录下所有的有效图片文件
extensions = ['png']
file_list = []
# 把图片存放在file_list列表里
dir_name = os.path.basename(sub_dir)
for extension in extensions:
file_glob = os.path.join(INPUT_DATA, dir_name, '*.'+extension)
# glob.glob(file_glob)获取指定目录下的所有图片,存放在file_list中
file_list.extend(glob.glob(file_glob))
length_of_dir = len(sub_dirs)
print(length_of_dir)
for j in range(24):
for i in range(length_of_dir):
class1 = sub_dirs[i]
class2 = sub_dirs[(length_of_dir-i+j-1) % length_of_dir]
if ((length_of_dir-i+j-1) % length_of_dir):
class1_name = os.path.basename(class1)
class2_name = os.path.basename(class2)
# 获取当前目录下所有的有效图片文件
extensions = 'png'
file_list1 = []
file_list2 = []
# 把图片存放在file_list列表里
file_glob1 = os.path.join(INPUT_DATA, class1_name, '*.' + extension)
file_list1.extend(glob.glob(file_glob1))
file_glob2 = os.path.join(INPUT_DATA, class2_name, '*.' + extension)
file_list2.extend(glob.glob(file_glob2))
if file_list1 and file_list2:
base_name1 = os.path.basename(file_list1[j % len(file_list1)]) # 获取文件的名称
base_name2 = os.path.basename(file_list2[j % len(file_list2)])
# unmatched_result.add([class1_name, base_name1, class2_name, base_name2])
s = class2_name+'\t'+base_name2+'\t'+class1_name+'\t'+base_name1
if(s not in unmatched_result):
unmatched_result.add(class1_name+'\t'+base_name1+'\t'+class2_name+'\t'+base_name2)
k = k + 1
print(j,k)
return unmatched_result, k
result, k1 = create_image_lists()
print(len(result))
# print(result)
result_un, k2 = create_pairs()
print(len(result_un))
# print(result_un)
file = open('data/facev5_pairs.txt', 'w',encoding='utf-8')
result1 = list(result)
result2 = list(result_un)
file.write('10 100\n')
j = 0
for i in range(10):
j = 0
print("=============================================第" + str(i) + '次, 相同的')
for pair in result1[i*100:i*100+100]:
j = j + 1
print(str(j) + ': ' + pair)
file.write(pair + '\n')
print("=============================================第" + str(i) + '次, 不同的')
for pair in result2[i*100:i*100+100]:
j = j + 1
print(str(j) + ': ' + pair)
file.write(pair + '\n')
六、轻量级网络研究
为了进一步降低参数量,减少模型内存占用率,实现更广泛地应用,进行参数量的优化,随着MobileNet等一些轻量级网络的出现,对FaceNet中的深度卷积神经网络进行轻量级网络研究,小编采用SqueezeNet代替Inception-ResNet-V1进行特征提取。
该模型既减少了参数量同时有不错的性能,模型提出Fire模块,包含压缩层和expand层,用1x1卷积代替3x3卷积,Fire结构如下图所示。

两个层的卷积核数可以调节,通常让squeeze层小于expand层卷积核数,网络结构如下图。

基于SqueezeNet+triplet loss进行网络训练,为增强模型泛化性,减少过拟合,首先用LFW数据集进行训练,然后用预训练模型在自制数据上进行训练与测试,准确率达到99.7%。在FaceNet精简版源码中只需要修改train_tripletloss.py中的深度模型就行,如下图所示。

七、FaceNet扩展使用-FaceNet+SVM/KNN或者改进损失函数
基于FaceNet进行人脸判断主要是以下两种方式,第一种是通过深度网络生成特征向量,然后和数据库中的对比,大于阈值不是同一个人,小于则是同一人;第二种利用深度网络得到特征向量,然后输入分类器进行分类,由分类器判断出是哪个人。两种方式如下图所示,相对来说,第一种实用性更加广泛。
 第二种输入图片后使用预训练模型生成特征向量,接着以特征向量作为输入采用SVM、KNN算法进行分类,从而实现人脸识别。
第二种输入图片后使用预训练模型生成特征向量,接着以特征向量作为输入采用SVM、KNN算法进行分类,从而实现人脸识别。
SVM通过找最大超平面实现分类,对于线性可分问题,从所有可进行分类的线中找出距离支持向量最大的线;对于线性不可分,采用核函数分类,实际是映射到高维进行分类。然而人脸识别是多分类问题,小编采用one-one模式实现多分类。
KNN是对于输入的数据,求距离最近的K个值,在K个里面选择数量最多的类别作为输入数据的类别。
两种方式都可以直接调用sklearn库进行代码实现,首先通过FaceNet模型得到特征向量,然后作为svm、knn的输入进行分类,部分代码思想如下。
FaceNet+SVM/KNN.
//首先通过FaceNet模型得到特征向量,然后作为svm、knn的输入进行分类。
#em是得到的特征向量,labels是对应类别的标签
x_train,x_test,y_train,y_test=train_test_split(ems,labels,test_size=0.2,random_state=6)
print(len(ems))
#sklearn库的使用
knn = KNeighborsClassifier(n_neighbors=1, metric='euclidean')
svc = SVC(kernel='linear')
#喂入数据
knn.fit(x_train, y_train)
svc.fit(x_train, y_train)
#测试模型
test_scores=svc.score(x_test, y_test)
acc_knn = accuracy_score(y_test, knn.predict(x_test))
acc_svc = accuracy_score(y_test, svc.predict(x_test))
print('acc_svm:',acc_svc)
print('acc_knn:',acc_knn)
最后在自制数据集上有着不错的效果,但是准确率不如Inception-ResNet-V1迁移学习+Triplet Loss效果好,因为迁移学习本身模型是通过几百万数据训练过的,性能较好。
八、部署总结和特征向量的存储
最后使用Django+前端实现系统开发应用,这里记录两个问题,大家经常遇到的。
1、django加载keras模型报错如下

解决方法:

2.Mysql 存取数组
特征向量存储长度较大,转为字符串或者其他类型不太合适,可以使用Blob类型,可以参考这篇文章:https://blog.csdn.net/qq_34352603/article/details/81039082
好了,小编对这部分的介绍要结束了,欢迎大家一起交流指正,一起进步~,后面会继续更新,因项目原因,完整代码之后附上以及改进版人脸识别模型,大家喜欢的可以关注呦。
参考文献:
FaceNet源码解读1:
https://blog.csdn.net/u013044310/article/details/79556099
FaceNet源码解读2:
https://blog.csdn.net/u013044310/article/details/80481642