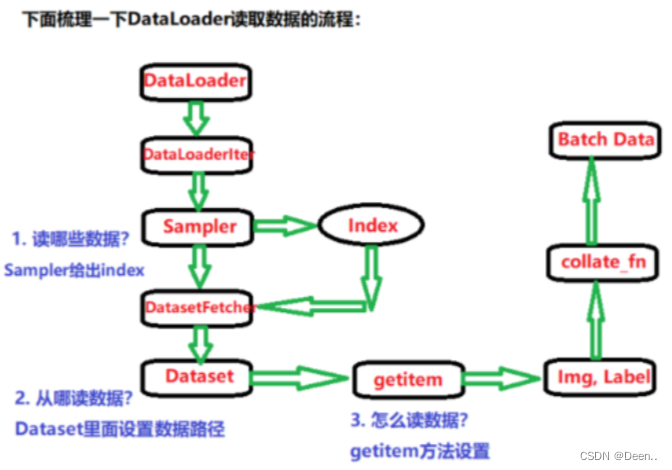
文章目录
个人学习笔记,仅做参考
导读
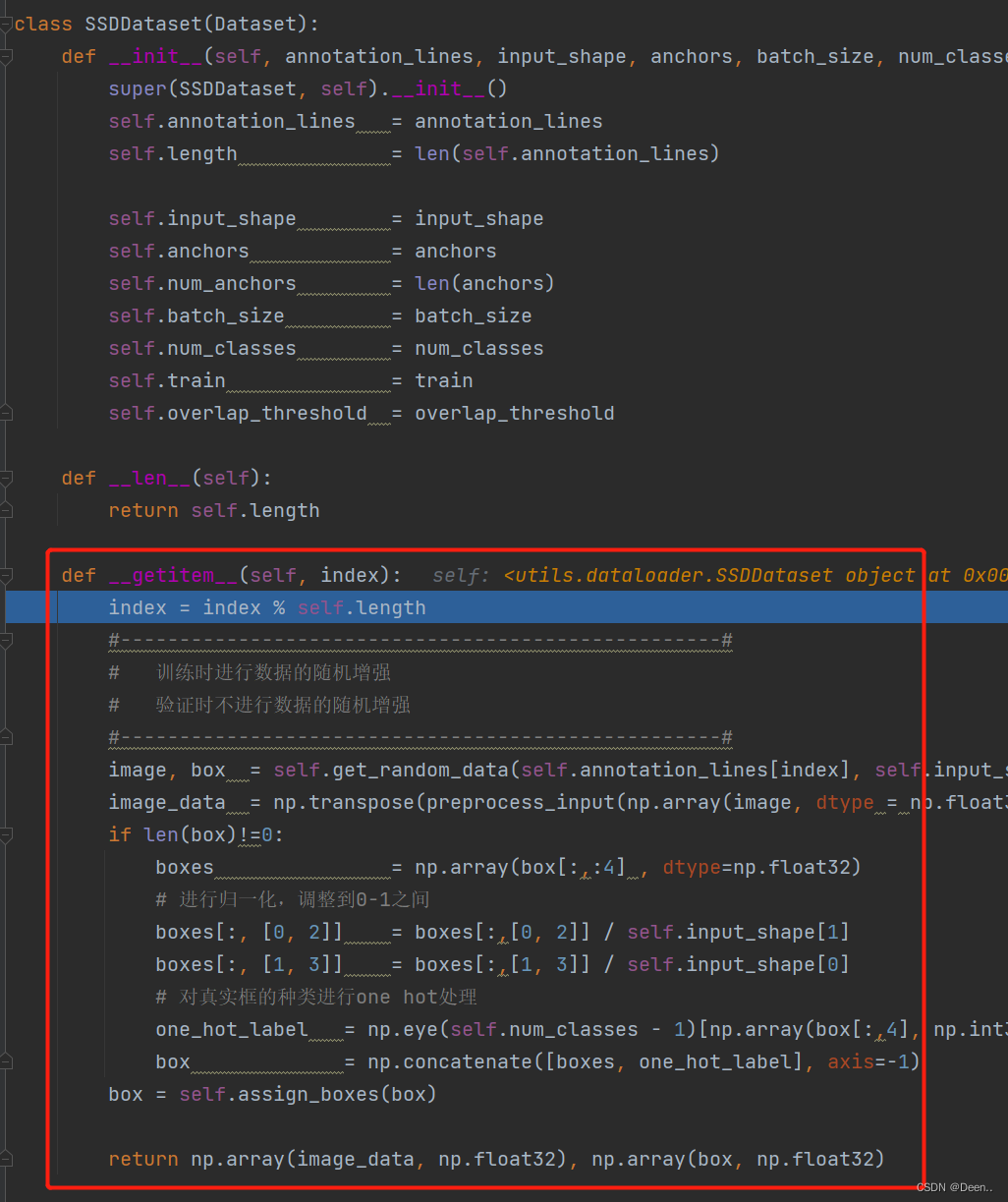
在学习SSDDataset之前我们先看一个python的魔法方法 def__getitem__(self, index):
getitem()可以让对象实现迭代功能
使得SSDDDataset可以接收一个索引, 返回一个样本
SSDDataset类中定义了这个魔法方法,我们就可以把SSDDataset看成一个迭代器,将数据集加载到这个迭代器中。当需要数据的时候,根据索引,一张一张往外蹦数据。
class SSDDataset(Dataset):
从类定义可以看出SSDDataset属于torch.utils.data.Dataset(),是Dataset()的复写。
要弄懂数据读取机制,还需要看torch.utils.data.DataLoader()。
DataLoader(
train_dataset, #从哪里加载数据集
shuffle = shuffle,
batch_size = batch_size, #每次采样多设张图
num_workers = num_workers, #多进程读取机制
pin_memory=True, #选TRUE时 数据加载器返回张量前,将其复制到CUDA固定内存里
drop_last=True, #是非否删除最后一个不完整批次,如果数据集大小不能被完全整除,最后一批就删了
collate_fn=ssd_dataset_collate, #数据输出收集机制
sampler=train_sampler #定义从数据集中抽取样本的策略)
数据采样机制
DataLoader采样时可选择用单线程还是多线程采样,采样的过程全在线程里这里先放出单线程的代码,下面再具体研究。
class _SingleProcessDataLoaderIter(_BaseDataLoaderIter):
def __init__(self, loader):
super(_SingleProcessDataLoaderIter, self).__init__(loader)
assert self._timeout == 0
assert self._num_workers == 0
self._dataset_fetcher = _DatasetKind.create_fetcher(
self._dataset_kind, self._dataset, self._auto_collation, self._collate_fn, self._drop_last)
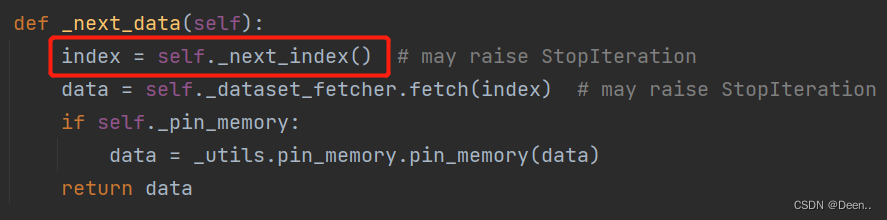
def _next_data(self):
index = self._next_index() # may raise StopIteration
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
if self._pin_memory:
data = _utils.pin_memory.pin_memory(data)
return data
配置数据加载器DataLoader采样前内部配置
前提:
配置好数据集模块的SSDDataset初始参数,配置好数据加载器的初始参数。
train_dataset = SSDDataset(train_lines, input_shape, anchors, batch_size, num_classes, train = True)
gen = DataLoader(train_dataset, shuffle = shuffle, batch_size = batch_size, num_workers = num_workers, pin_memory=True,drop_last=True, collate_fn=ssd_dataset_collate, sampler=train_sampler)
激活:
遍历数据加载器,就开始激活这个DataLoader,开始进行数据按批读取。
for iteration, batch in enumerate(gen):
流程:
因为是遍历数据加载器DataLoader(),直接跳到__iter__下,再根据num_workers判断是多进程加载,还是单进程加载;这里num_workers==0 所以进行单线程读加载
def __iter__(self) -> '_BaseDataLoaderIter':
# When using a single worker the returned iterator should be
# created everytime to avoid reseting its state
# However, in the case of a multiple workers iterator
# the iterator is only created once in the lifetime of the
# DataLoader object so that workers can be reused
if self.persistent_workers and self.num_workers > 0:
if self._iterator is None:
self._iterator = self._get_iterator()
else:
self._iterator._reset(self)
return self._iterator
else:
return self._get_iterator()
def _get_iterator(self) -> '_BaseDataLoaderIter':
if self.num_workers == 0:
return _SingleProcessDataLoaderIter(self)
else:
self.check_worker_number_rationality()
return _MultiProcessingDataLoaderIter(self)
这个单线程_SingleProcessDataLoaderIter继承于_BaseDataLoaderIter类,研究这个线程怎么去读取数据集,我们来看一下它的父类。
class _SingleProcessDataLoaderIter(_BaseDataLoaderIter):
def __init__(self, loader):
super(_SingleProcessDataLoaderIter, self).__init__(loader)
assert self._timeout == 0
assert self._num_workers == 0
self._dataset_fetcher = _DatasetKind.create_fetcher(
self._dataset_kind, self._dataset, self._auto_collation, self._collate_fn, self._drop_last)
这个线程里的参数就是数据加载器DataLoader()的参数,线程就是一个辛勤的工作者,把参数加载到线程里,然后开始进行这个类的功能。
class _BaseDataLoaderIter(object):
def __init__(self, loader: DataLoader) -> None:
self._dataset = loader.dataset
self._dataset_kind = loader._dataset_kind
self._IterableDataset_len_called = loader._IterableDataset_len_called
self._auto_collation = loader._auto_collation
self._drop_last = loader.drop_last
self._index_sampler = loader._index_sampler
self._num_workers = loader.num_workers
self._prefetch_factor = loader.prefetch_factor
self._pin_memory = loader.pin_memory and torch.cuda.is_available()
self._timeout = loader.timeout
self._collate_fn = loader.collate_fn
self._sampler_iter = iter(self._index_sampler)
self._base_seed = torch.empty((), dtype=torch.int64).random_(generator=loader.generator).item()
self._persistent_workers = loader.persistent_workers
self._num_yielded = 0
self._profile_name = "enumerate(DataLoader)#{}.__next__".format(self.__class__.__name__)
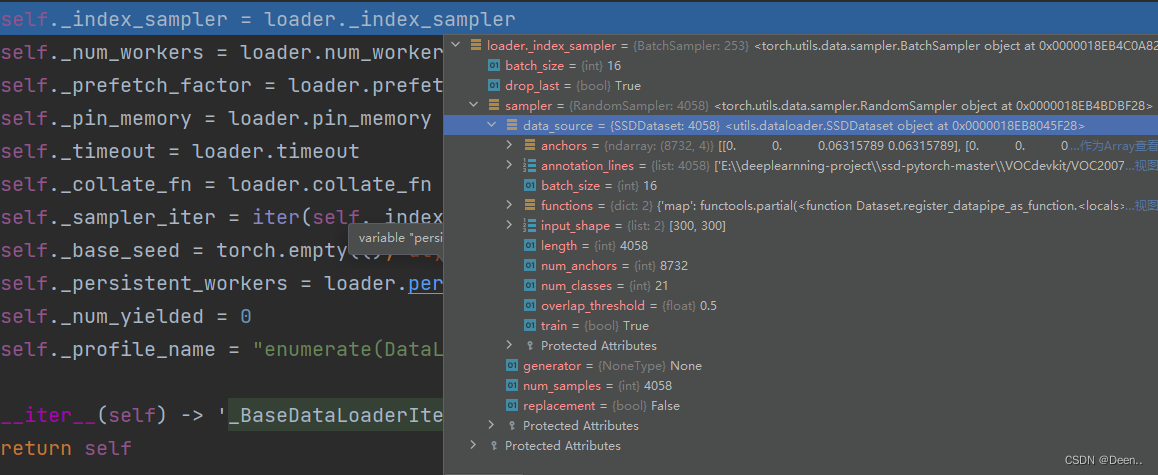
如下图为加载到这个线程的数据,就是train_dataset

从数据集中抽取样本的策略,_index_sampler中定义了batch=16跟drop=True,就是以16张采集一批,最后一批不够16张就丢掉,同时还有数据集的信息。这个就是实现采集功能的主要函数,从哪里去获取图片,sampler给出要获取图片的索引index
图像采集后输出的收集策略,这里用的是ssd_dataset_collate,我们可以自己定义怎么收集采集输出后的图像。

回到单线程采集,传入self._dataset_fetcher继承的参数。根据名字,我们可以知道这是一个数据具体内容抓取器。
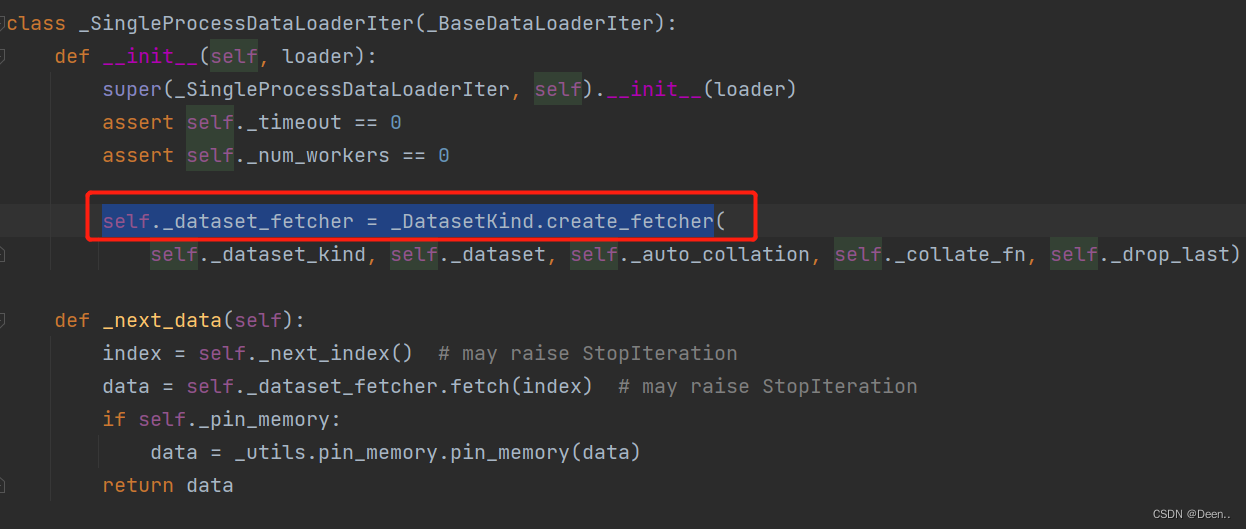
激活
遍历开始
for iteration, batch in enumerate(gen):
在单进程采集下还定义了一个next_index函数,当上述基础设置全部配置完毕,遍历开始的时候这个函数就开始工作,通过这个函数去正式实行数据按批采集。
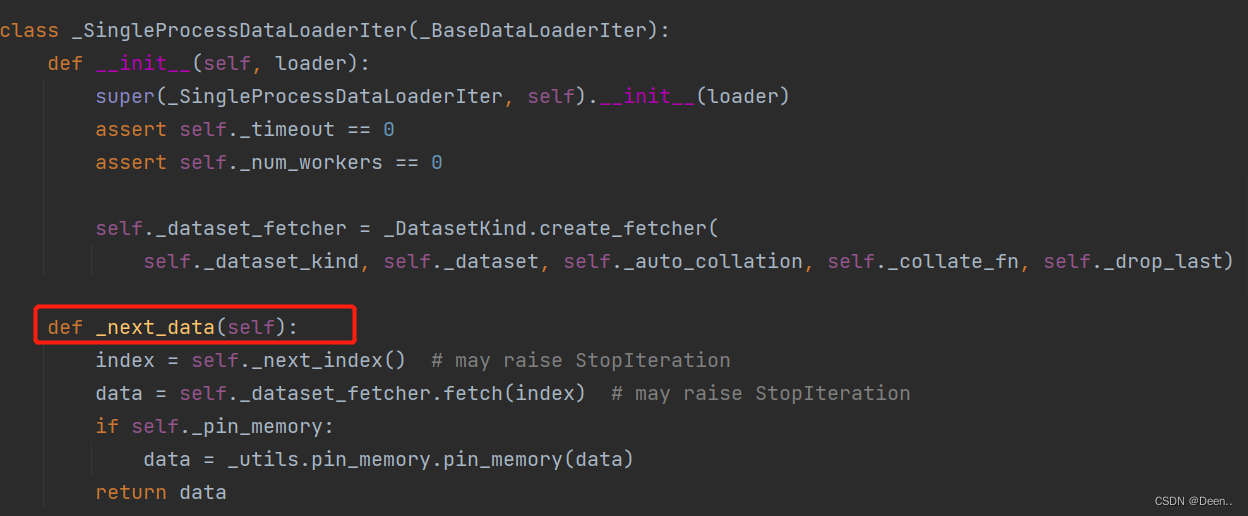
DataLoader开始进行采样工作-next_data()
上述为DataLoaer采样前的内部设置,数据加载器DataLoader正式对数据集进行采样是通过next_data()进行的。
1.索引采样-index=self._next_index()
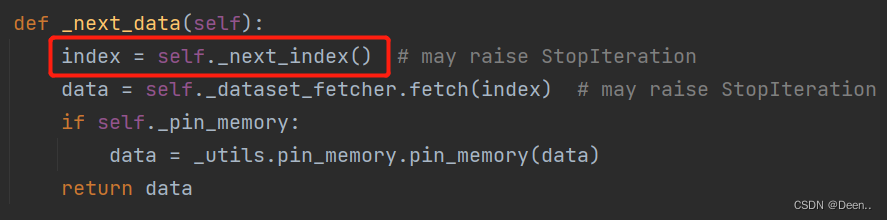
首先看该函数第一行,index = self._next_index() ,同时一步步去找对应的联系,思路就清晰了起来。
当for in开始遍历的时候,数据加载模块DataLoader通过在运行的线程开始调用next_data函数,第一行index = self._next_index() ,对应的 self._next_index() 函数返回self._sampler_iter的next方法,我们知道只有迭代器iter才有next方法,所以self._sampler_iter = iter(self._index_sampler),再看看源头self._index_sampler = loader._index_sampler,发现没,这里就是单线程(_SingleProcessDataLoaderIter)的父类中的属性。
这里面有batch尺寸有是否要drop,有数据集的地址,有anchor,有数据集的总数等等,_index_sampler这个采集策略,将返回batch张图片的索引,也就是16张图片的索引,这16张的索引就复制给了index。
index = self._next_index()
def _next_index(self):
return next(self._sampler_iter)
self._sampler_iter = iter(self._index_sampler)
self._index_sampler = loader._index_sampler
我们再来一步一步往下走,loader._index_sampler函数返回了self.sampler
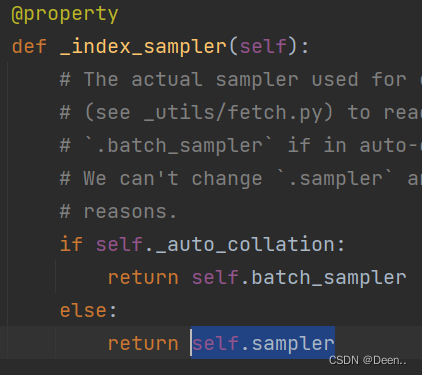

追根溯源我们又发现了一个眼熟的朋友(shuffle),DataLoader最开始的传参中的一个,当shuffle打开的时候sampler采样的策略是Random的也就是随机采样,shuffle关闭时,策略是Sequential,也就是按顺序采样。传入Sampler的参数有dataset [这里传入的是SSDDataset] ,这就解释了sampler里为什么有数据集了。
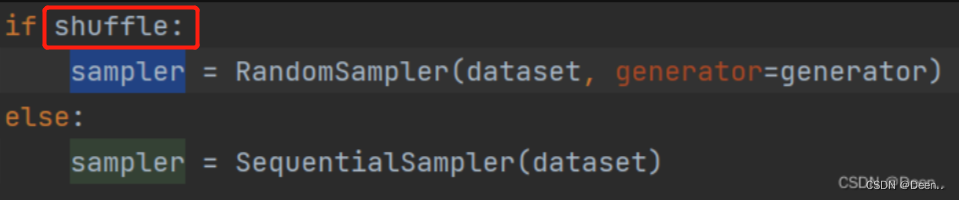
next调用(self._sampler_iter)后,
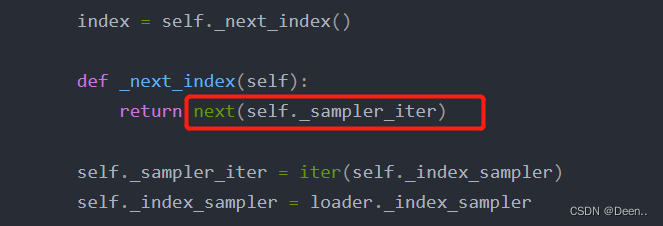
就进入到sampler的采样生成里,如图下,batch列表存储的是采样后的样本索引序列,也就是index。
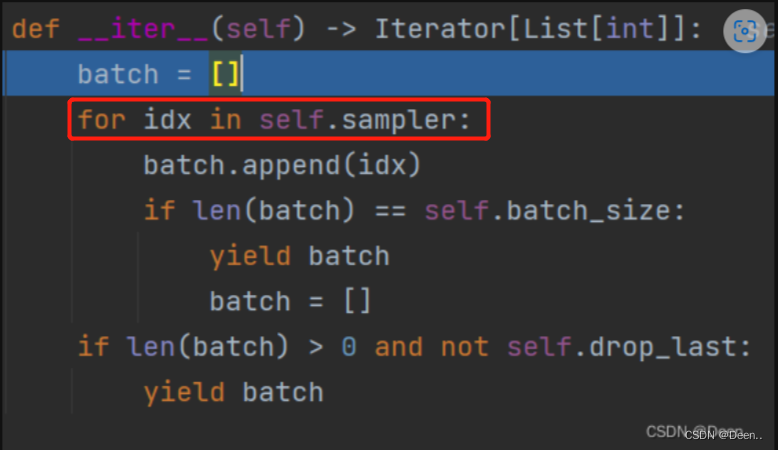
在for idx in self.sampler中,self.sample是RandomSampler类,直接跳到该类的iter部分,首先RandomSampler先获取数据集总数,这里的data_sorce就是RandomSampler(dataset,generator=generator)中的dataset,该例中也就是SSDDataset这个数据迭代器。然后随机生成一个数,处理后将这个随机数返回复制给idx。
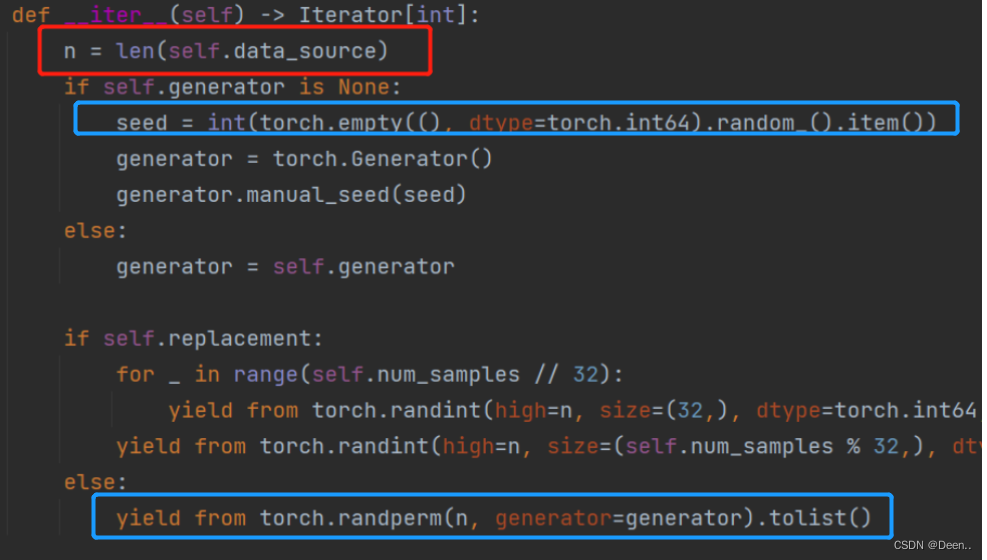
当batch中装满16(batch_size)张图后,将这个batch返回
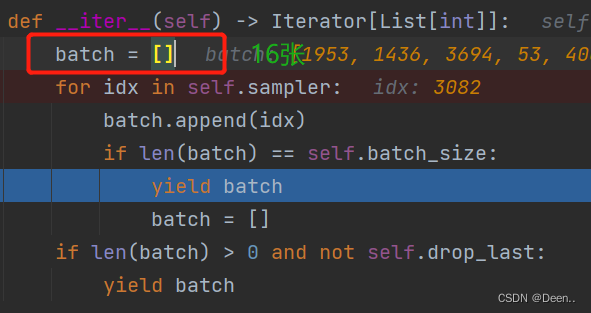
返回的batch赋值给了索引采样,此时index内就有16个顺序打乱的索引。
到此完成索引采样。
2.数据采样-data = self._dataset_fetcher.fetch(index)
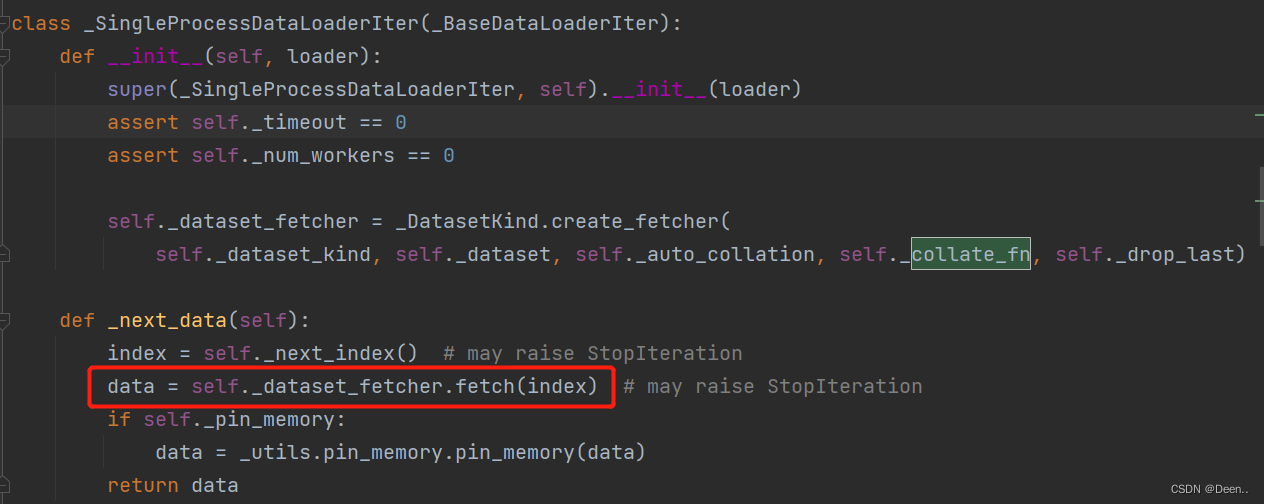
将上述的采样的索引直接送入fetch函数
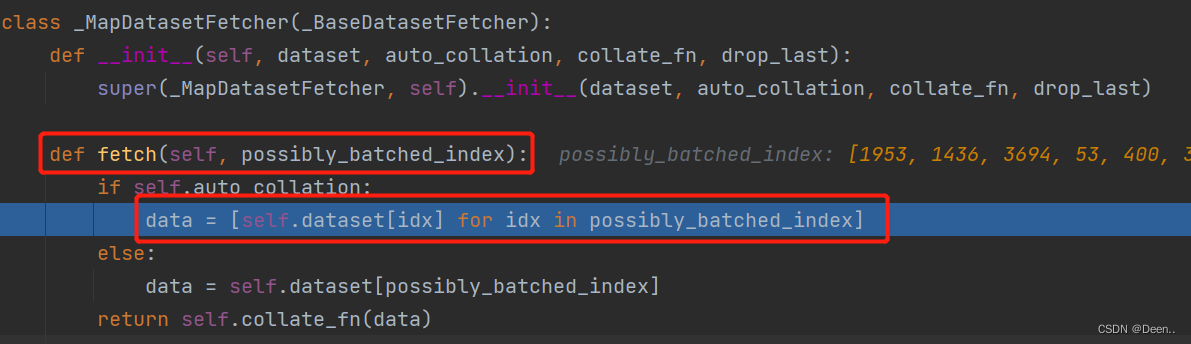
可以看到这里data == [self.dataset[idx] for idx in possibly_batched_index] 也就是让按着给的索引依次让dataset这个数据集迭代器依次往外蹦图,这里的dataset对应的就是SSDDataset,往外蹦图这件事我们熟悉啊,最开头的导读部分就提到了SSDDataset是一个可以根据给进来的索引往外蹦图的迭代器,能实现这一功能还得归公于SSDDataset中的魔法方法 def__getitem__(self, index)
这里得提一下蹦出来的数据包含了图像跟真实框,其中真实框用锚框的偏移量来表示。
采样完毕后的数据集是[16,(image_data, box)]的格式,如图所示:
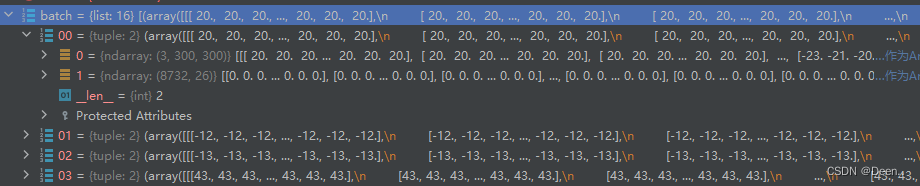
接下来通过输出收集函数,把数据集中的图片跟真实框分别取出来。
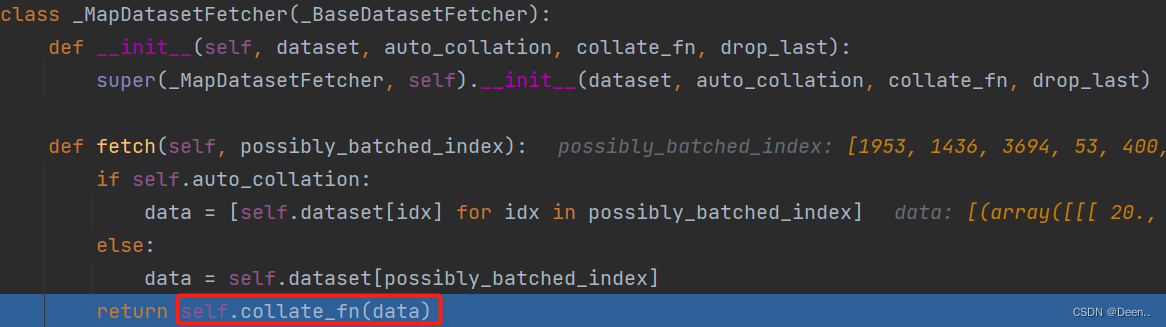
这个收集函数在如下图所示的,self._collate_fn可以自己定义重写,下列是self._collate_fn该例的收集函数。
def ssd_dataset_collate(batch):
images = []
bboxes = []
for img, box in batch:
images.append(img)
bboxes.append(box)
images = torch.from_numpy(np.array(images)).type(torch.FloatTensor)
bboxes = torch.from_numpy(np.array(bboxes)).type(torch.FloatTensor)
return images, bboxes
到此完成数据的采样,采样结果如下图所示

再将此图返回到最开始的训练模型阶段,赋予batch。完成数据集按batch_size采样发放,用以接下来的训练。

for iteration, batch in enumerate(gen):
images, targets = batch[0], batch[1]
到此数据采样完成。