一、voc数据集转coco数据集
执行命令:
python tools/dataset_converters/pascal_voc.py ../../../data/devkit ../../../data/coco
通过VOC的xml文件生成COCO的json标签文件。
再把图片复制道coco数据集下:
import os
import cv2
import mmcv
import shutil
import os.path as path
# # root_path = 'data/VOCdevkit/VOC2007/' # voc路径
# trainval_path = root_path + "ImageSets/Main/test.txt" # 改成 trainval.txt / test.txt
# jpg_path = root_path + 'JPEGImages/'
# save_path = "/home/wujian/VOCdevkit/val2017/" # 改成 train2017 / val2017
root_path = 'I:\Miniconda\open-mmlab\data\devkit\VOC2012'
txt_path = path.join(root_path, 'ImageSets/Main/')
jpg_path = path.join(root_path, 'JPEGImages/')
splits = ['train', 'val', 'test']
for split in splits:
print('copy images by', split)
src_path = txt_path + split + '.txt'
save_path = path.join("I:\Miniconda\open-mmlab\data\coco", split)
mmcv.mkdir_or_exist(save_path)
with open(src_path, 'r') as f:
for ele in f.readlines():
cur_jpgname = ele.strip() # 提取当前图像的文件名
total_jpgname = jpg_path + cur_jpgname + '.jpg' # 获取图像全部路径
shutil.copy(total_jpgname, path.join(save_path, cur_jpgname + '.jpg'))
# # 读取图像
# cur_img = cv2.imread(total_jpgname)
# # 保存图像
# cv2.imwrite(save_path + cur_jpgname + '.jpg', cur_img)
print(split, 'copy done!')
# with open(trainval_path,'r') as f:
# for ele in f.readlines():
# cur_jpgname = ele.strip() # 提取当前图像的文件名
# total_jpgname = jpg_path + cur_jpgname + '.jpg' # 获取图像全部路径
# # 读取图像
# cur_img = cv2.imread(total_jpgname)
# # 保存图像
# cv2.imwrite(save_path + cur_jpgname + '.jpg',cur_img)
# print('Done!')
最终coco数据集转换完毕:
二、修改配置
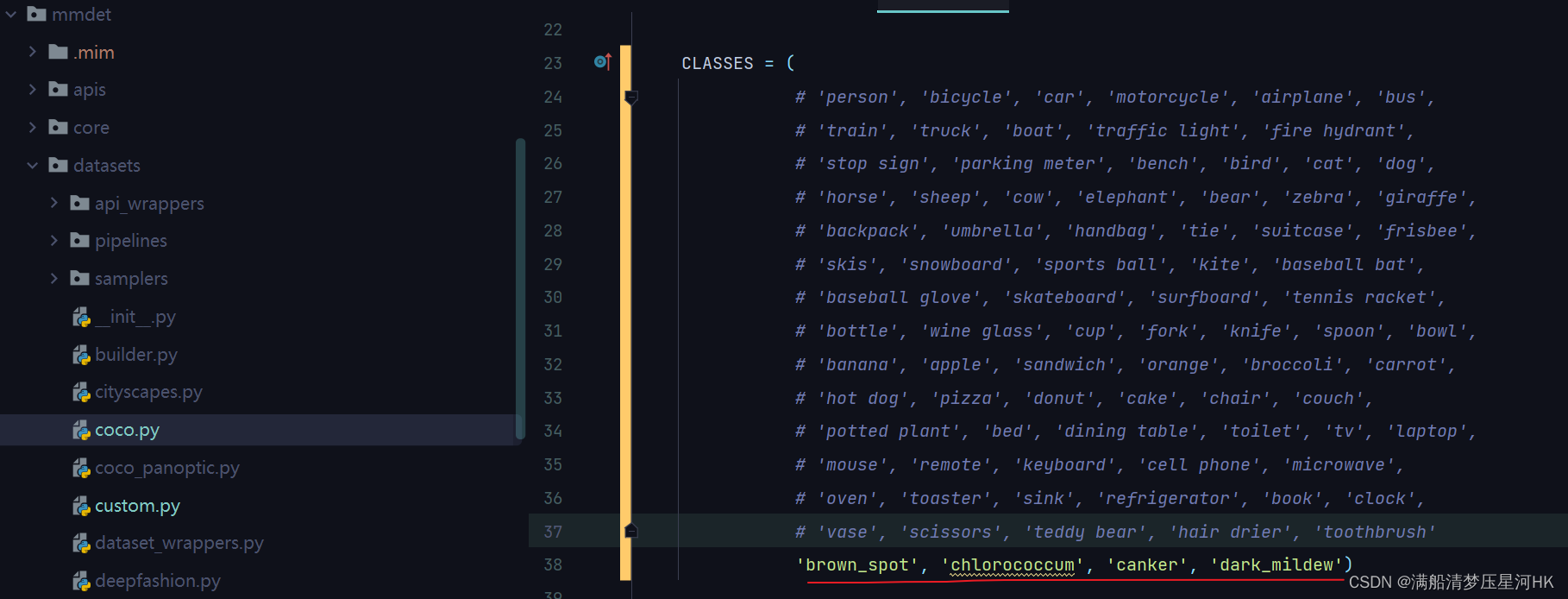
1、先修改mmdet/datasets/coco.py下的标签:
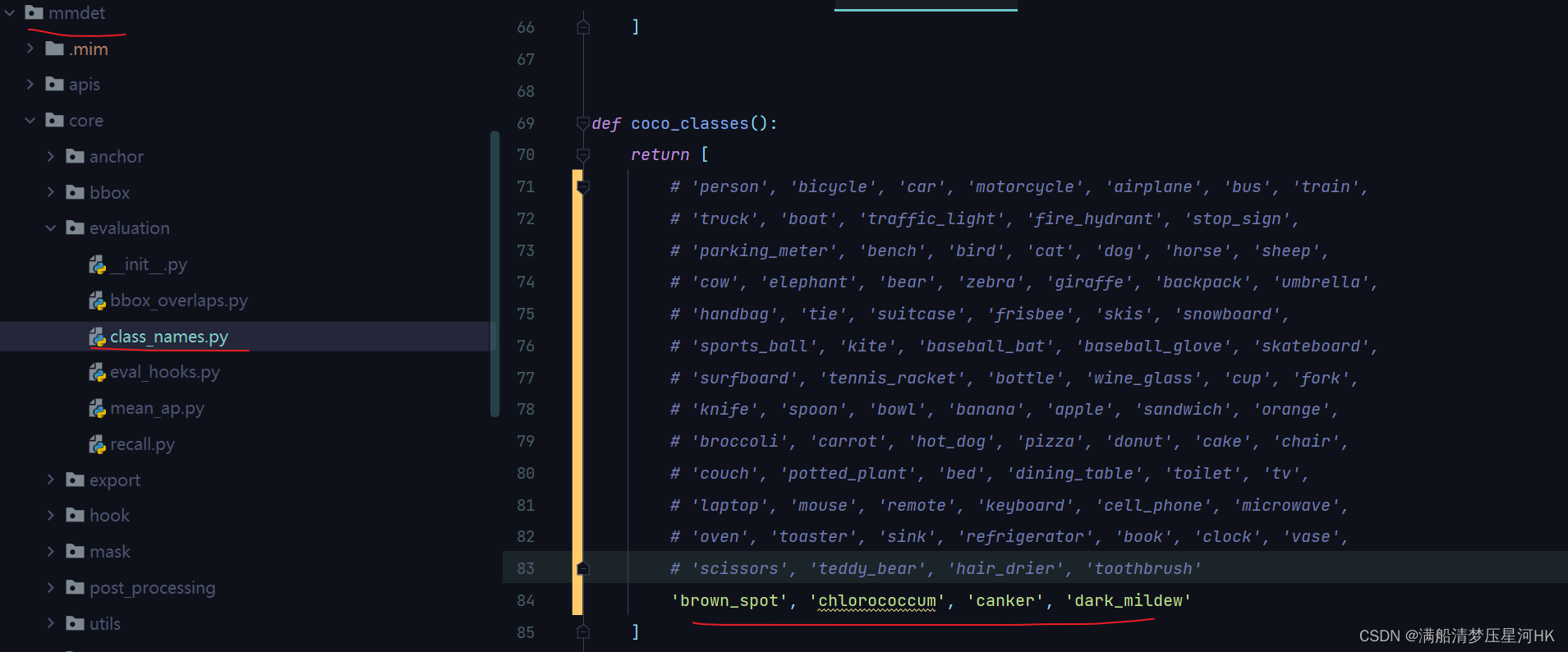
2、再修改mmdet/core/evaluation/class_names.py下的标签:
3、修改配置文件以faster_rcnn_r50_fpn_1x_coco.py为例:
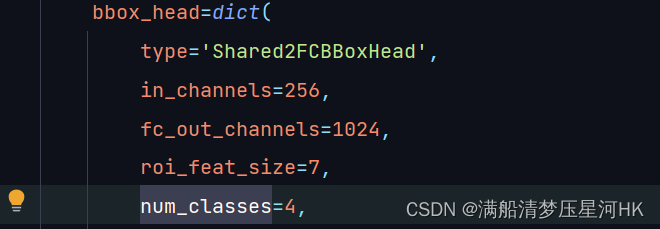
先修改模型输出类别个数num_classes:
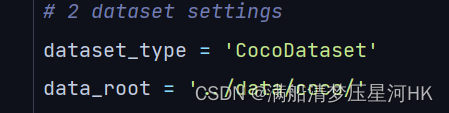
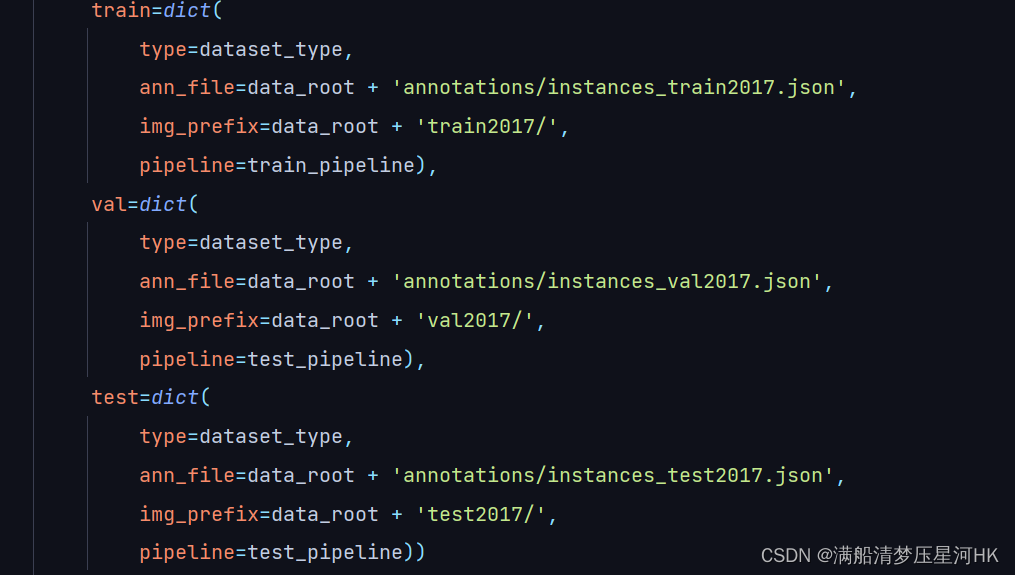
再修改数据集相关配置(路径、文件名要和你自己的对应):
到这一步就可以正常训练了:
单gpu:
python tools/train.py configs/test/faster_rcnn_r50_fpn_1x_coco.py
多gpu:
tools/dist_train.sh configs/test/faster_rcnn_r50_fpn_1x_coco.py 2
可以看到,可以正常训练:

二、验证数据集是否转换成功
执行命令:
python tools/misc/browse_dataset.py configs/test/faster_rcnn_r50_fpn_1x_coco.py
可以开始检验数据集和标签:
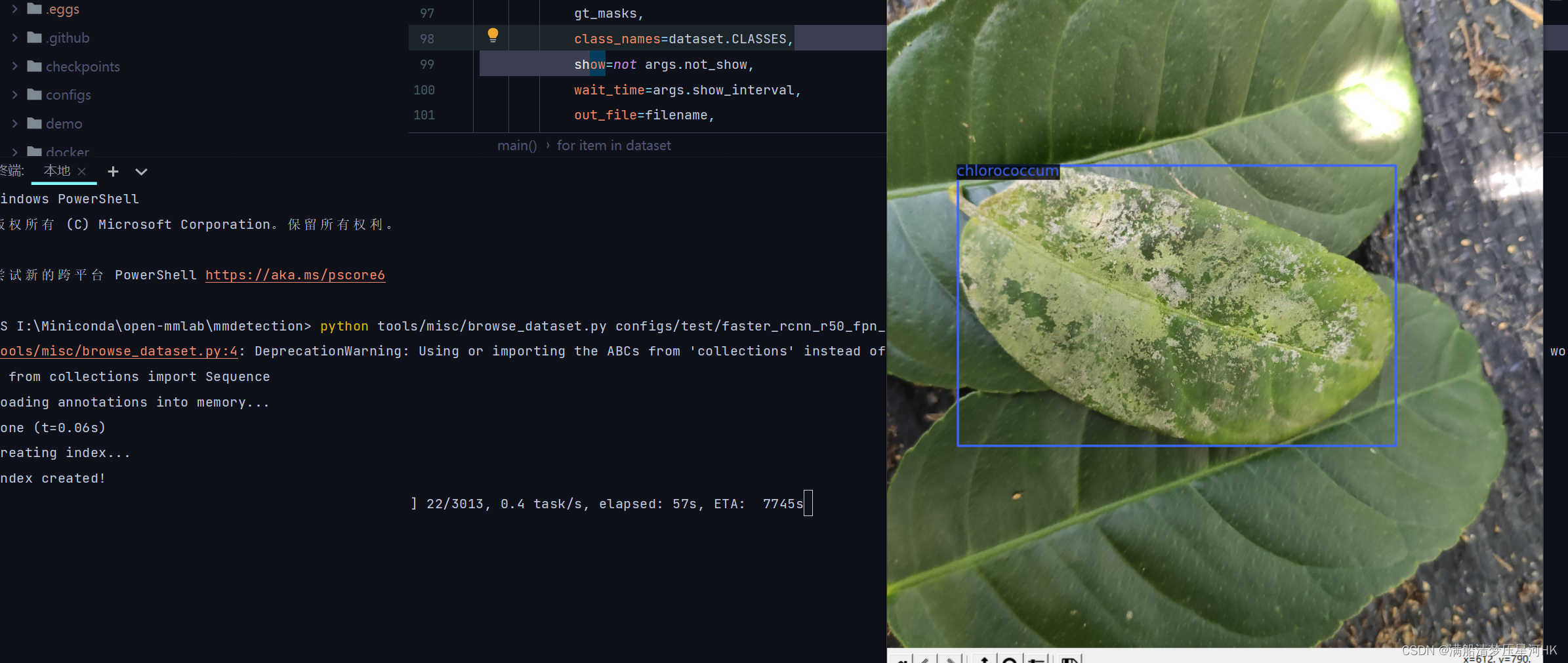
基本上看几张没什么问题就可以说明转换的数据集是ok的!
相关源码文件
tools/dataset_converters/pascal_voc.py
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import os.path as osp
import xml.etree.ElementTree as ET
import mmcv
import numpy as np
from mmdet.core import voc_classes
label_ids = {
name: i for i, name in enumerate(voc_classes())}
def parse_xml(args):
xml_path, img_path = args
tree = ET.parse(xml_path)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
bboxes = []
labels = []
bboxes_ignore = []
labels_ignore = []
for obj in root.findall('object'):
name = obj.find('name').text
label = label_ids[name]
difficult = int(obj.find('difficult').text)
bnd_box = obj.find('bndbox')
bbox = [
int(bnd_box.find('xmin').text),
int(bnd_box.find('ymin').text),
int(bnd_box.find('xmax').text),
int(bnd_box.find('ymax').text)
]
if difficult:
bboxes_ignore.append(bbox)
labels_ignore.append(label)
else:
bboxes.append(bbox)
labels.append(label)
if not bboxes:
bboxes = np.zeros((0, 4))
labels = np.zeros((0, ))
else:
bboxes = np.array(bboxes, ndmin=2) - 1
labels = np.array(labels)
if not bboxes_ignore:
bboxes_ignore = np.zeros((0, 4))
labels_ignore = np.zeros((0, ))
else:
bboxes_ignore = np.array(bboxes_ignore, ndmin=2) - 1
labels_ignore = np.array(labels_ignore)
annotation = {
'filename': img_path.split('/')[-1],
'width': w,
'height': h,
'ann': {
'bboxes': bboxes.astype(np.float32),
'labels': labels.astype(np.int64),
'bboxes_ignore': bboxes_ignore.astype(np.float32),
'labels_ignore': labels_ignore.astype(np.int64)
}
}
return annotation
def cvt_annotations(devkit_path, years, split, out_file):
if not isinstance(years, list):
years = [years]
annotations = []
for year in years:
filelist = osp.join(devkit_path,
f'VOC{
year}/ImageSets/Main/{
split}.txt')
if not osp.isfile(filelist):
print(f'filelist does not exist: {
filelist}, '
f'skip voc{
year} {
split}')
return
img_names = mmcv.list_from_file(filelist)
xml_paths = [
osp.join(devkit_path, f'VOC{
year}/Annotations/{
img_name}.xml')
for img_name in img_names
]
img_paths = [
f'VOC{
year}/JPEGImages/{
img_name}.jpg' for img_name in img_names
]
part_annotations = mmcv.track_progress(parse_xml,
list(zip(xml_paths, img_paths)))
annotations.extend(part_annotations)
if out_file.endswith('json'):
annotations = cvt_to_coco_json(annotations)
mmcv.dump(annotations, out_file)
return annotations
def cvt_to_coco_json(annotations):
image_id = 0
annotation_id = 0
coco = dict()
coco['images'] = []
coco['type'] = 'instance'
coco['categories'] = []
coco['annotations'] = []
image_set = set()
def addAnnItem(annotation_id, image_id, category_id, bbox, difficult_flag):
annotation_item = dict()
annotation_item['segmentation'] = []
seg = []
# bbox[] is x1,y1,x2,y2
# left_top
seg.append(int(bbox[0]))
seg.append(int(bbox[1]))
# left_bottom
seg.append(int(bbox[0]))
seg.append(int(bbox[3]))
# right_bottom
seg.append(int(bbox[2]))
seg.append(int(bbox[3]))
# right_top
seg.append(int(bbox[2]))
seg.append(int(bbox[1]))
annotation_item['segmentation'].append(seg)
xywh = np.array(
[bbox[0], bbox[1], bbox[2] - bbox[0], bbox[3] - bbox[1]])
annotation_item['area'] = int(xywh[2] * xywh[3])
if difficult_flag == 1:
annotation_item['ignore'] = 0
annotation_item['iscrowd'] = 1
else:
annotation_item['ignore'] = 0
annotation_item['iscrowd'] = 0
annotation_item['image_id'] = int(image_id)
annotation_item['bbox'] = xywh.astype(int).tolist()
annotation_item['category_id'] = int(category_id)
annotation_item['id'] = int(annotation_id)
coco['annotations'].append(annotation_item)
return annotation_id + 1
for category_id, name in enumerate(voc_classes()):
category_item = dict()
category_item['supercategory'] = str('none')
category_item['id'] = int(category_id)
category_item['name'] = str(name)
coco['categories'].append(category_item)
for ann_dict in annotations:
file_name = ann_dict['filename']
ann = ann_dict['ann']
assert file_name not in image_set
image_item = dict()
image_item['id'] = int(image_id)
image_item['file_name'] = str(file_name)
image_item['height'] = int(ann_dict['height'])
image_item['width'] = int(ann_dict['width'])
coco['images'].append(image_item)
image_set.add(file_name)
bboxes = ann['bboxes'][:, :4]
labels = ann['labels']
for bbox_id in range(len(bboxes)):
bbox = bboxes[bbox_id]
label = labels[bbox_id]
annotation_id = addAnnItem(
annotation_id, image_id, label, bbox, difficult_flag=0)
bboxes_ignore = ann['bboxes_ignore'][:, :4]
labels_ignore = ann['labels_ignore']
for bbox_id in range(len(bboxes_ignore)):
bbox = bboxes_ignore[bbox_id]
label = labels_ignore[bbox_id]
annotation_id = addAnnItem(
annotation_id, image_id, label, bbox, difficult_flag=1)
image_id += 1
return coco
def parse_args():
parser = argparse.ArgumentParser(
description='Convert PASCAL VOC annotations to mmdetection format')
parser.add_argument('--devkit_path', default='../../../data/devkit', help='pascal voc devkit path')
parser.add_argument('--out_dir', default='../../../data/coco', help='output path')
parser.add_argument(
'--out_format',
default='coco',
choices=('pkl', 'coco'),
help='output format, "coco" indicates coco annotation format')
args = parser.parse_args()
return args
def main():
args = parse_args()
devkit_path = args.devkit_path
out_dir = args.out_dir if args.out_dir else devkit_path
mmcv.mkdir_or_exist(out_dir)
years = []
if osp.isdir(osp.join(devkit_path, 'VOC2007')):
years.append('2007')
if osp.isdir(osp.join(devkit_path, 'VOC2012')):
years.append('2012')
if '2007' in years and '2012' in years:
years.append(['2007', '2012'])
if not years:
raise IOError(f'The devkit path {
devkit_path} contains neither '
'"VOC2007" nor "VOC2012" subfolder')
out_fmt = f'.{
args.out_format}'
if args.out_format == 'coco':
out_fmt = '.json'
for year in years:
if year == '2007':
prefix = 'voc07'
elif year == '2012':
prefix = 'voc12'
elif year == ['2007', '2012']:
prefix = 'voc0712'
for split in ['train', 'val', 'trainval']:
dataset_name = prefix + '_' + split
print(f'processing {
dataset_name} ...')
cvt_annotations(devkit_path, year, split,
osp.join(out_dir, dataset_name + out_fmt))
if not isinstance(year, list):
dataset_name = prefix + '_test'
print(f'processing {
dataset_name} ...')
cvt_annotations(devkit_path, year, 'test',
osp.join(out_dir, dataset_name + out_fmt))
print('Done!')
if __name__ == '__main__':
main()
配置文件faster_rcnn_r50_fpn_1x_coco.py:
# 1 model settings
model = dict(
type='FasterRCNN',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=4,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
# model training and testing settings
train_cfg=dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=-1,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_pre=2000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False)),
test_cfg=dict(
rpn=dict(
nms_pre=1000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100)
# soft-nms is also supported for rcnn testing
# e.g., nms=dict(type='soft_nms', iou_threshold=0.5, min_score=0.05)
))
# 2 dataset settings
dataset_type = 'CocoDataset'
data_root = '../data/coco/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=0,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_test2017.json',
img_prefix=data_root + 'test2017/',
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='bbox')
# 3 optimizer
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
# learning policy
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11])
runner = dict(type='EpochBasedRunner', max_epochs=12)
# 4 runtime
checkpoint_config = dict(interval=1)
# yapf:disable
log_config = dict(
interval=1,
hooks=[
dict(type='TextLoggerHook'),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
custom_hooks = [dict(type='NumClassCheckHook')]
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
browse_dataset.py:
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import os
from collections import Sequence
from pathlib import Path
import mmcv
from mmcv import Config, DictAction
from mmdet.core.utils import mask2ndarray
from mmdet.core.visualization import imshow_det_bboxes
from mmdet.datasets.builder import build_dataset
def parse_args():
parser = argparse.ArgumentParser(description='Browse a dataset')
parser.add_argument('config', help='train config file path')
parser.add_argument(
'--skip-type',
type=str,
nargs='+',
default=['DefaultFormatBundle', 'Normalize', 'Collect'],
help='skip some useless pipeline')
parser.add_argument(
'--output-dir',
default=None,
type=str,
help='If there is no display interface, you can save it')
parser.add_argument('--not-show', default=False, action='store_true')
parser.add_argument(
'--show-interval',
type=float,
default=2,
help='the interval of show (s)')
parser.add_argument(
'--cfg-options',
nargs='+',
action=DictAction,
help='override some settings in the used config, the key-value pair '
'in xxx=yyy format will be merged into config file. If the value to '
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
'Note that the quotation marks are necessary and that no white space '
'is allowed.')
args = parser.parse_args()
return args
def retrieve_data_cfg(config_path, skip_type, cfg_options):
def skip_pipeline_steps(config):
config['pipeline'] = [
x for x in config.pipeline if x['type'] not in skip_type
]
cfg = Config.fromfile(config_path)
if cfg_options is not None:
cfg.merge_from_dict(cfg_options)
# import modules from string list.
if cfg.get('custom_imports', None):
from mmcv.utils import import_modules_from_strings
import_modules_from_strings(**cfg['custom_imports'])
train_data_cfg = cfg.data.train
while 'dataset' in train_data_cfg and train_data_cfg[
'type'] != 'MultiImageMixDataset':
train_data_cfg = train_data_cfg['dataset']
if isinstance(train_data_cfg, Sequence):
[skip_pipeline_steps(c) for c in train_data_cfg]
else:
skip_pipeline_steps(train_data_cfg)
return cfg
def main():
args = parse_args()
cfg = retrieve_data_cfg(args.config, args.skip_type, args.cfg_options)
dataset = build_dataset(cfg.data.train)
progress_bar = mmcv.ProgressBar(len(dataset))
for item in dataset:
filename = os.path.join(args.output_dir,
Path(item['filename']).name
) if args.output_dir is not None else None
gt_masks = item.get('gt_masks', None)
if gt_masks is not None:
gt_masks = mask2ndarray(gt_masks)
imshow_det_bboxes(
item['img'],
item['gt_bboxes'],
item['gt_labels'],
gt_masks,
class_names=dataset.CLASSES,
show=not args.not_show,
wait_time=args.show_interval,
out_file=filename,
bbox_color=(255, 102, 61),
text_color=(255, 102, 61))
progress_bar.update()
if __name__ == '__main__':
main()