文章目录
书接上文
上一部分我们走完一遍数据加载器的加载机理,接下来我们来看,怎么按照DataLoader的索引往外蹦图片给它的Dataset类,也就是SSDData。
SSDData类传入参数解读
模型训练需要:超调参数、模型、数据集
对应代码里的 optimizer、model_train、train_dataset、val_dataset
optimizer = {
'adam' : optim.Adam(model.parameters(), Init_lr_fit, betas = (momentum, 0.999), weight_decay = weight_decay),
'sgd' : optim.SGD(model.parameters(), Init_lr_fit, momentum = momentum, nesterov=True, weight_decay = weight_decay)
}[optimizer_type]
model_train = model.train()
train_dataset = SSDDataset(train_lines, input_shape, anchors, batch_size, num_classes, train = True)
val_dataset = SSDDataset(val_lines, input_shape, anchors, batch_size, num_classes, train = False)
这里要研究数据集是如何加载到模型里的,首先先来看train_dataset这个实例向SSDDatase类传入了些什么参数:
train_dataset = SSDDataset(train_lines, input_shape, anchors, batch_size, num_classes, train = True)
val_dataset = SSDDataset(val_lines, input_shape, anchors, batch_size, num_classes, train = False)
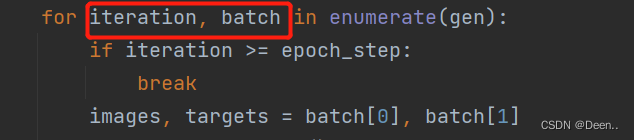
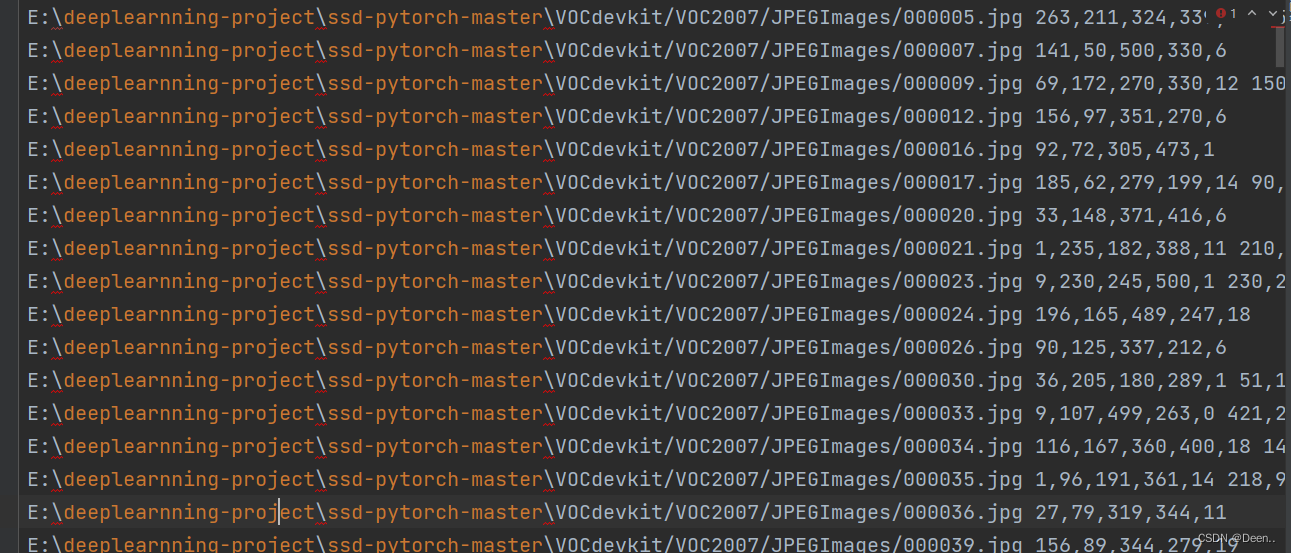
- train_lines 是训练集数据对应的txt文件内容,格式为 [图片绝对路径,图片所有真实框]。如图所示
- input_shape 为设定输入模型的固定尺寸,该例设为 [300,300]
- anchor 是老朋友了,根据input_shape、anchor所设尺寸以及模型自动生成,与输入的具体图片无关,格式为[8743,4]。
- batch_size 将数据集以batch_size为一批分成若干组,这里batch_size取16,数据集有4058张,可分4058/16=253组
- numclasses 数据集类别总数
- train 判断是否是训练模式,训练模式数据集加载中的处理与验证模式存在差异,具体下文分析。
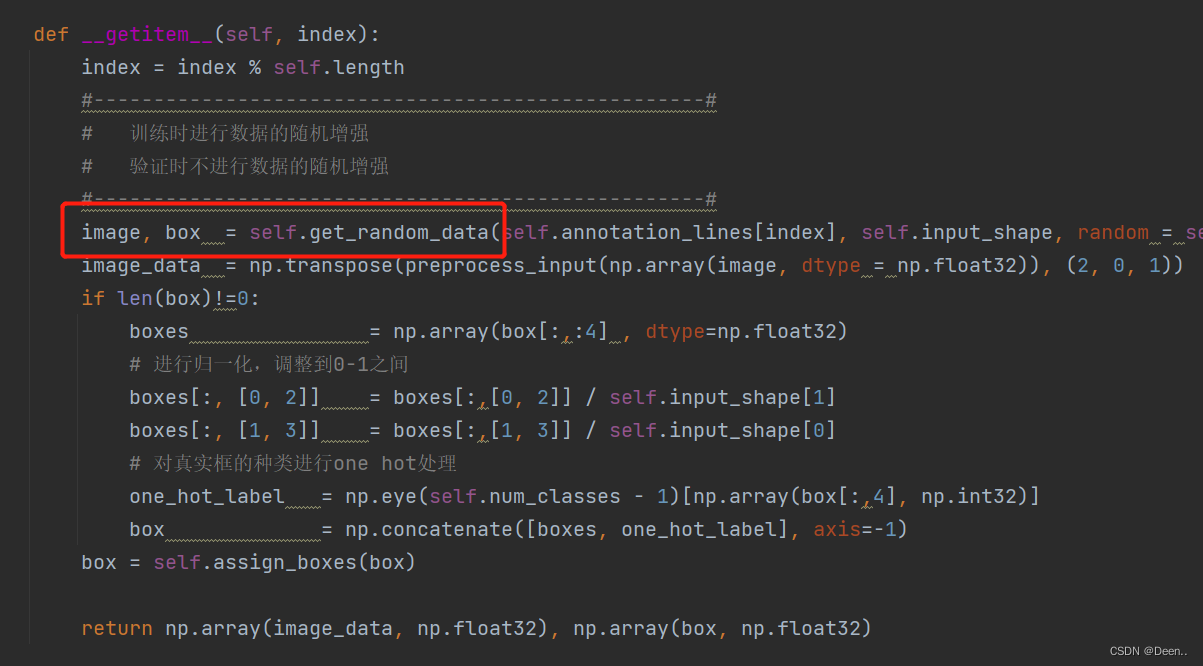
根据索引开始处理单张图片-getitem()
DataLoader通过fetch()去调用SSDDataset()中的__getitem__():
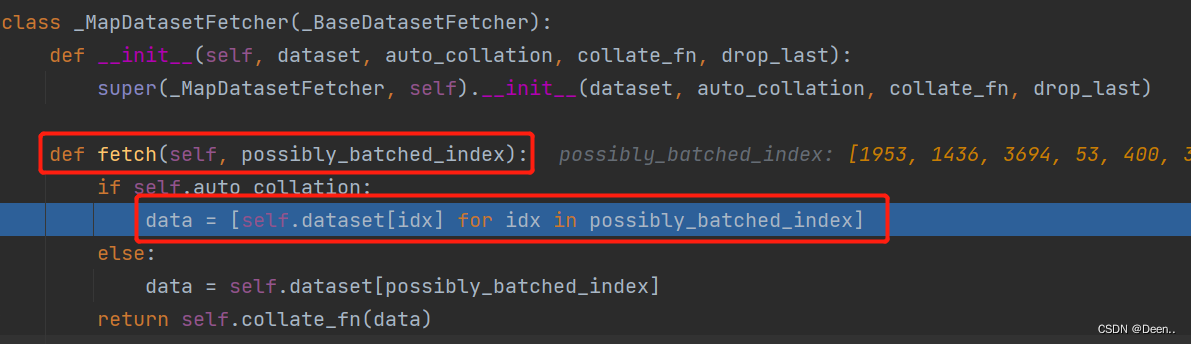
通过getitem()根据fetch下发的索引(inx)往外一张一张蹦图。
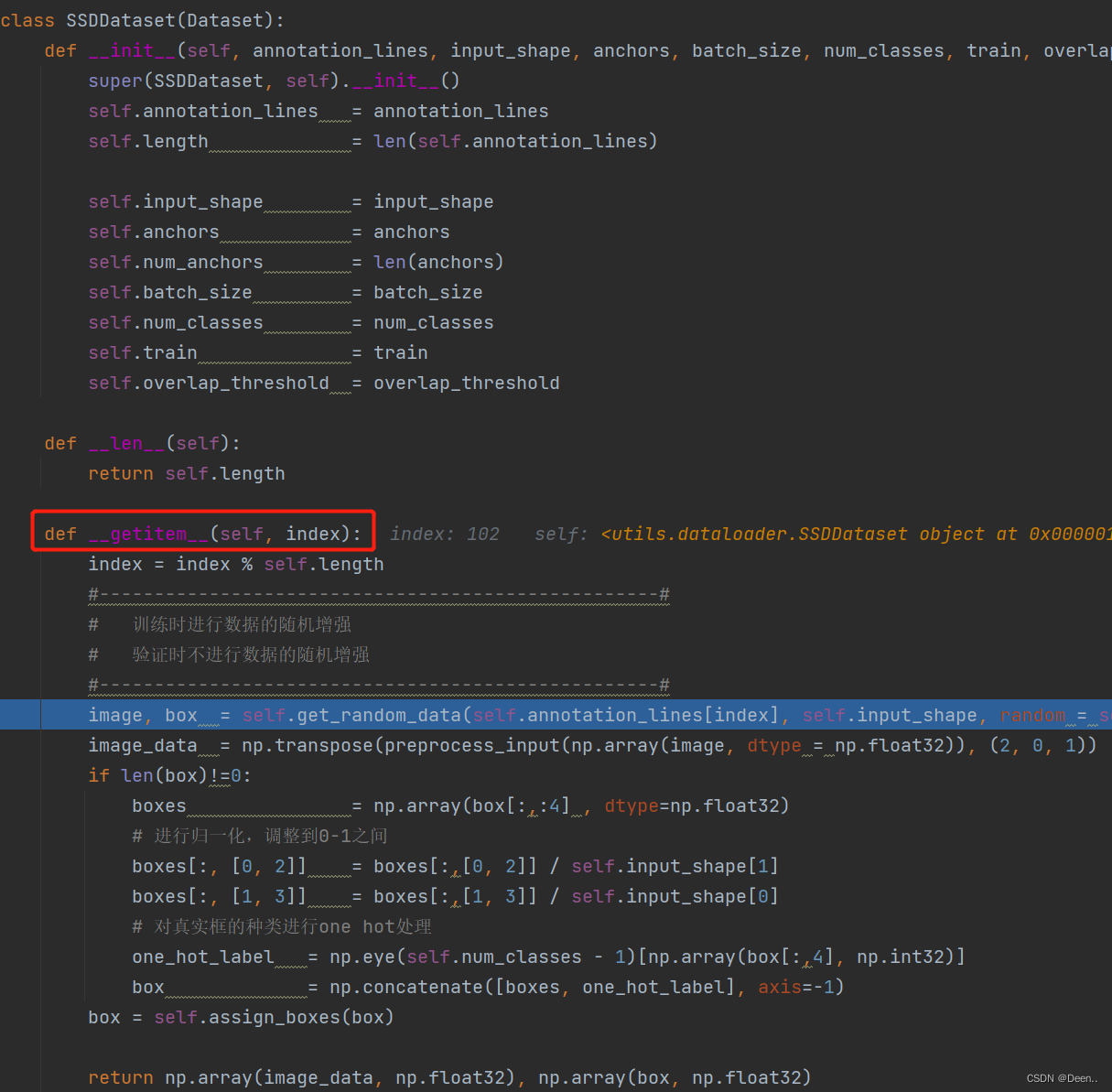
下发的index,先判断是否超出总长度
index = index % self.length
然后通过self.get_random_data()将索引的图片地址跟真实框信息读取进来进行处理。
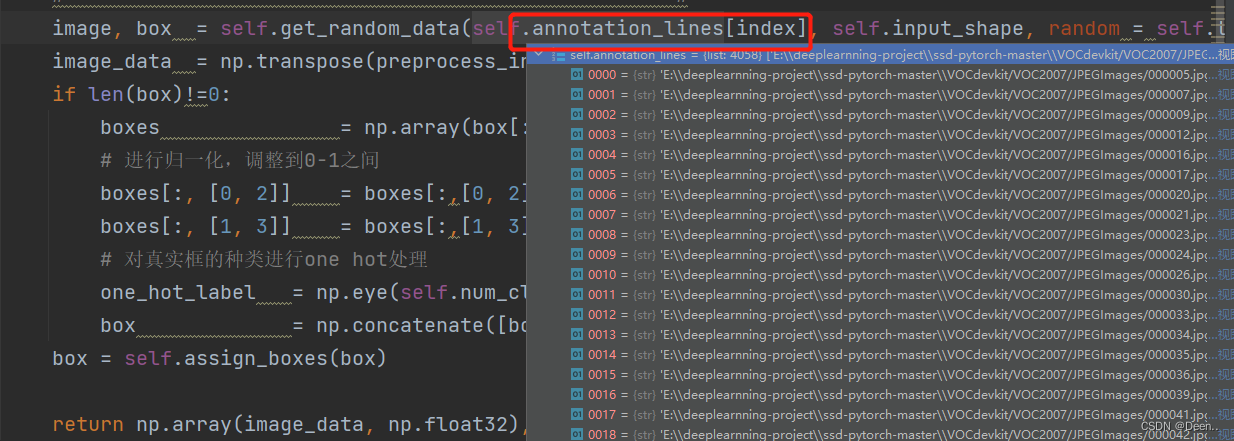
image, box = self.get_random_data(self.annotation_lines[index], self.input_shape, random = self.train)
1.数据初步处理-get_random_data()
传进该函数的annotation_line如图所示,包含了图片的地址跟真实框信息:
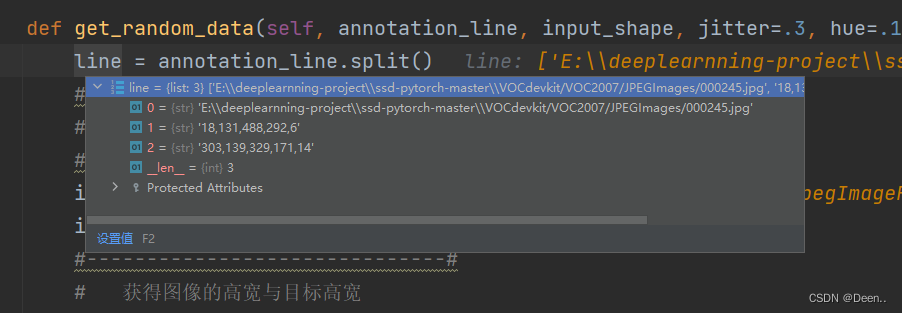
将图片地址加载进来获取图片,然后将图片转RGB格式,如果原来就是RGB就返回,不是的话就转RGB。然后将获取图片真实宽和高,再获取真实框。
def get_random_data(self, annotation_line, input_shape, jitter=.3, hue=.1, sat=0.7, val=0.4, random=True):
line = annotation_line.split()
#------------------------------#
# 读取图像并转换成RGB图像
#------------------------------#
image = Image.open(line[0])
image = cvtColor(image)
#------------------------------#
# 获得图像的高宽与目标高宽
#------------------------------#
iw, ih = image.size
h, w = input_shape
#------------------------------#
# 获得真实框
#------------------------------#
box = np.array([np.array(list(map(int,box.split(',')))) for box in line[1:]])
判断是不是训练模式,random=True时,是训练模式,下图是非训练模式,我们留一会再说,先看训练模式下,怎么处理数据。
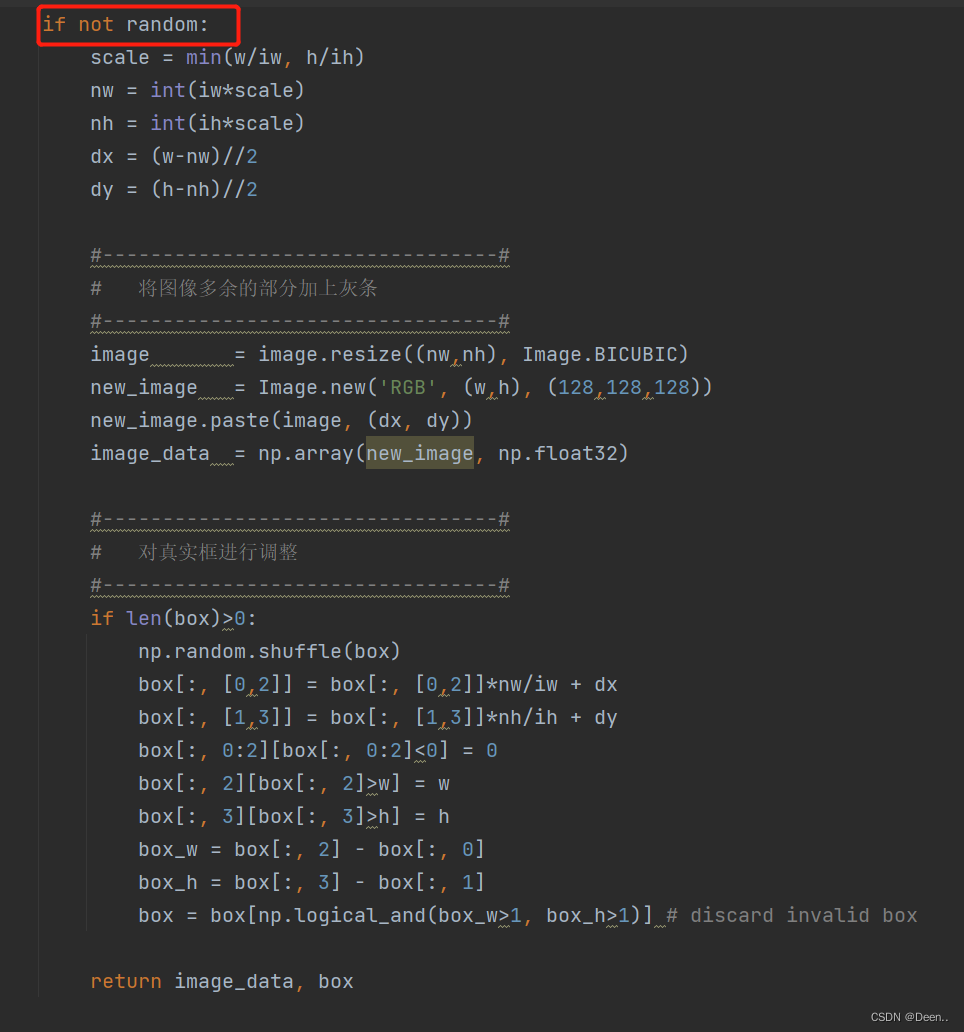
- 图片预处理
获取完图片后,判断是训练模式还是验证模式,如果是训练模式就对图像先进行预处理
图片缩放
new_ar = iw/ih * self.rand(1-jitter,1+jitter) / self.rand(1-jitter,1+jitter)
scale = self.rand(.25, 2)
if new_ar < 1:
nh = int(scale*h)
nw = int(nh*new_ar)
else:
nw = int(scale*w)
nh = int(nw/new_ar)
image = image.resize((nw,nh), Image.BICUBIC)
将图片多余部分设置成灰条
dx = int(self.rand(0, w-nw))
dy = int(self.rand(0, h-nh))
new_image = Image.new('RGB', (w,h), (128,128,128))
new_image.paste(image, (dx, dy))
image = new_image
翻转图片
flip = self.rand()<.5
if flip: image = image.transpose(Image.FLIP_LEFT_RIGHT)
image_data = np.array(image, np.uint8)
色域变换 这里用的是HSV变换
r = np.random.uniform(-1, 1, 3) * [hue, sat, val] + 1
hue, sat, val = cv2.split(cv2.cvtColor(image_data, cv2.COLOR_RGB2HSV))
dtype = image_data.dtype
x = np.arange(0, 256, dtype=r.dtype)
lut_hue = ((x * r[0]) % 180).astype(dtype)
lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
image_data = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))
image_data = cv2.cvtColor(image_data, cv2.COLOR_HSV2RGB)
以上就完成了对图像的预处理,非训练的验证模式没有图片预处理部分,它只做真实框调整。
- 真实框按比例调整
真实框格式如下图所示,真实框的内容是左上角右下角坐标,将真实框送入模型进行预测,需要将真实框转换为相对锚框的偏移量,然后预测处理的预测框也是相对锚框偏移量的格式来表示。转换成[x,y,w,h]格式,中心坐标为(x,y),w为框的宽度,h为高度。
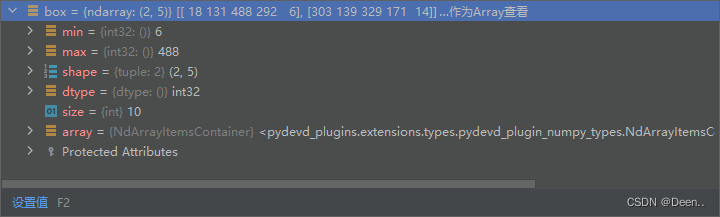
- 因为将图片从原来本身的尺寸压缩到要输入图片的尺寸时,按比例压缩,当真实图片的尺寸跟输入模型图片的尺寸不等比例时,就产生灰边。下列代码将获取图片按输入模型尺寸缩放后的尺寸。
if len(box)>0:
np.random.shuffle(box)
box[:, [0,2]] = box[:, [0,2]]*nw/iw + dx
box[:, [1,3]] = box[:, [1,3]]*nh/ih + dy
if flip: box[:, [0,2]] = w - box[:, [2,0]]
box[:, 0:2][box[:, 0:2]<0] = 0
box[:, 2][box[:, 2]>w] = w
box[:, 3][box[:, 3]>h] = h
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w>1, box_h>1)]
return image_data, box
调整完后,将图片跟真实框返给image, box 。
如果是验证模式,就不进行图像预处理,直接调整真实框。
- 调整图片格式
这一部分不是真实框处理的内容,但是按程序走的流程来讲述这个代码,我也就放在这里了
图片用的from PIL import Image 来读取的,读取进来的格式如图:
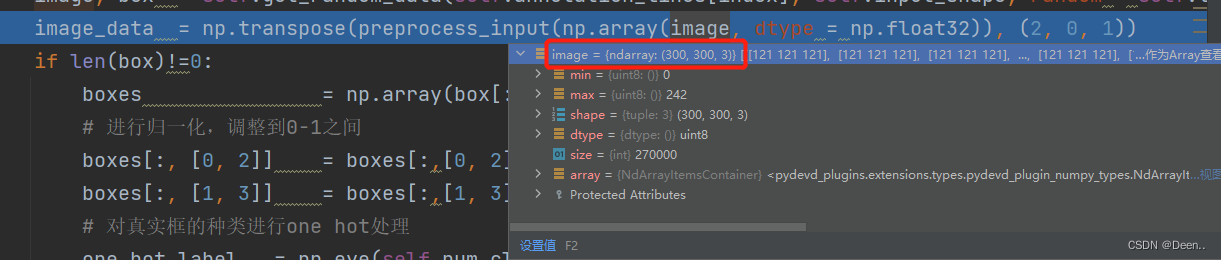
送入模型预测需要[3,300,300]的格式,所以这里通过下列函数进行调整:
image_data = np.transpose(preprocess_input(np.array(image, dtype = np.float32)), (2, 0, 1))
- 归一化
对真实框内容数值进行归一化
boxes = np.array(box[:,:4] , dtype=np.float32)
# 进行归一化,调整到0-1之间
boxes[:, [0, 2]] = boxes[:,[0, 2]] / self.input_shape[1]
boxes[:, [1, 3]] = boxes[:,[1, 3]] / self.input_shape[0]
对真实框的种类进行one hot处理
one_hot_label = np.eye(self.num_classes - 1)[np.array(box[:,4], np.int32)]
处理过后的one_hot_label,20个类别,该真实框是哪个类别,就在20类别的对应位置标志为1:

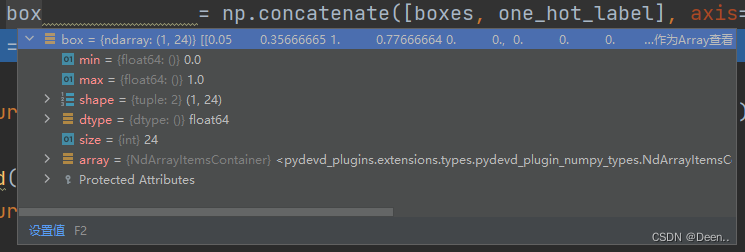
再将真实框的坐标跟类别合到一起,[:4]为坐标,[4:]为类别:
box = np.concatenate([boxes, one_hot_label], axis=-1)
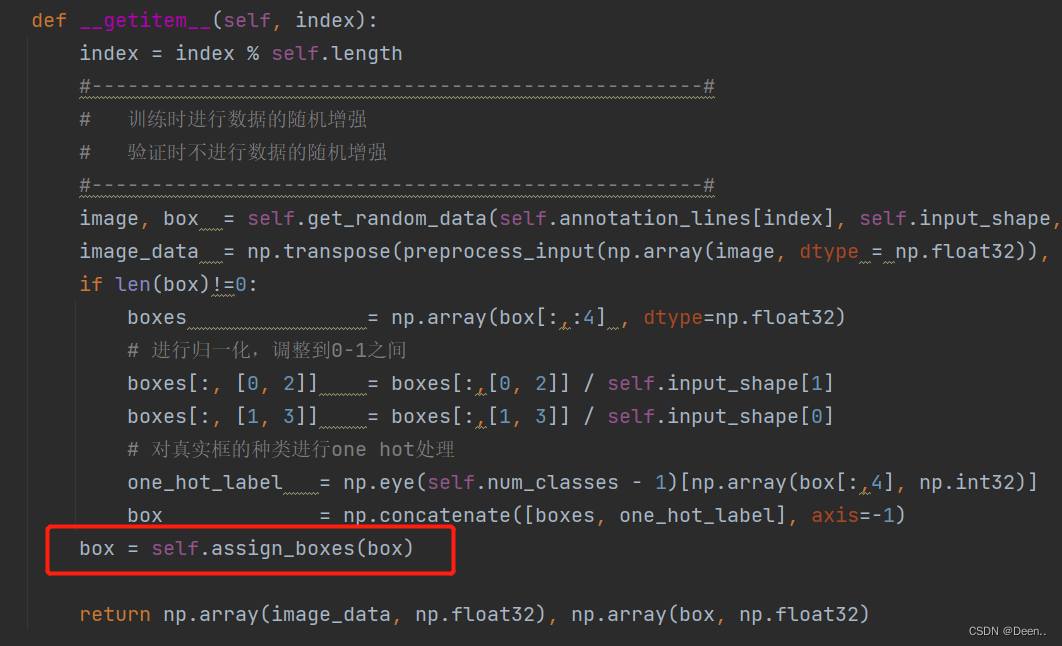
2.将真实框转换为相对锚框的偏移量
终于来讲怎么把真实框转为相对锚框的偏移量了,这个过程是通过box = self.assign_boxes(box)来实现:
转换后的格式如下图所示:
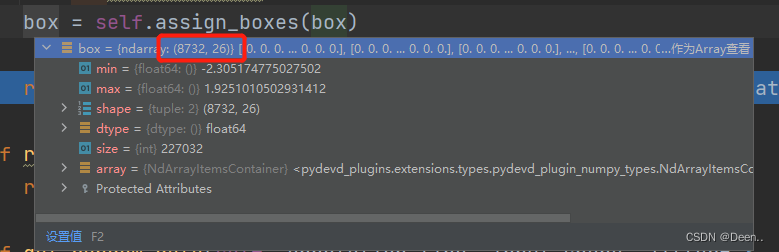
接下来我们来看如果转换。
- 按锚框格式设置载体
先做一个跟锚框格式一样的载体,然后第5个位置设置为,一会根据锚框做偏移量的调整,调整完送入这个载体,这个载体就是真实框处理后的表达形式,其格式为[8732,26],预测框的格式是[8732,25],真实框的第5位判断背景,最后1位判断目标,为互补关系,在损失函数中,取真实框的[4:-1]跟预测框的[4:]计算,也就是真实框最后1位判断目标的不计入loss计算:
def assign_boxes(self, boxes):
#[8732,26]:8732个真实框,第4位是背景,中间20个是类别,最后1位是目标,有目标的话为1,没有目标的话为0,与背景互补。
assignment = np.zeros((self.num_anchors, 4 + self.num_classes + 1))
#第5位意味着这个真实框是不是背景,如果是背景就为1,是目标就为0.
assignment[:, 4] = 1.0
assignment的第5位意味着这个真实框是不是背景,如果是背景就为1,是目标就为0.最后一位判断是否有目标。
- 对坐标进行解码
np.apply_along_axis 的作用是在数组的每一个轴上执行函数,下列代码的意思就是,对boxes的每一行都进行self.encode_box计算,也就是对每一个真实框都进行一次解码计算(encode),注意每次传入encode_box的只有一个真实框。
 再来展开这个解码函数,看看咋样对boxes坐标进行解码
再来展开这个解码函数,看看咋样对boxes坐标进行解码
- 首先将这个真实坐标框boxes与8732个锚框匹配,计算当前真实框跟锚框的重合情况,计算结果例子:
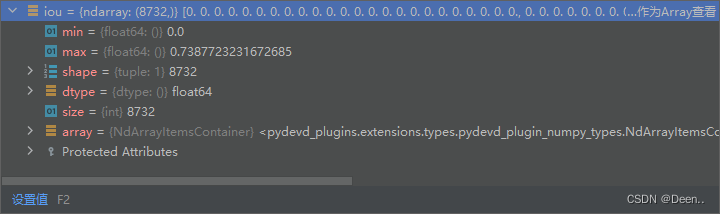
iou计算代码:
def iou(self, box):
#---------------------------------------------#
# 计算出每个真实框与所有的锚框的iou
# 判断真实框与先验框的重合情况
#---------------------------------------------#
inter_upleft = np.maximum(self.anchors[:, :2], box[:2])
inter_botright = np.minimum(self.anchors[:, 2:4], box[2:])
inter_wh = inter_botright - inter_upleft
inter_wh = np.maximum(inter_wh, 0)
inter = inter_wh[:, 0] * inter_wh[:, 1]
#---------------------------------------------#
# 真实框的面积
#---------------------------------------------#
area_true = (box[2] - box[0]) * (box[3] - box[1])
#---------------------------------------------#
# 先验框的面积
#---------------------------------------------#
area_gt = (self.anchors[:, 2] - self.anchors[:, 0])*(self.anchors[:, 3] - self.anchors[:, 1])
#---------------------------------------------#
# 计算iou
#---------------------------------------------#
union = area_true + area_gt - inter
iou = inter / union
return iou
- 找到找到iou大于所设的overlap_threshold阈值,如果这个真实框box坐标与锚框的iou计算结果没有大于所设阈值,就让最大的那个iou对应的边界框来匹配这个真实框。如果这个边框所设的iou大于所设阈值就先记录下来,下图为有若干个计算结果的iou大于所设阈值,经过enconde_box返回到上一层的结果,如下图所示,其中[:4]是iou的值,前4个是坐标:
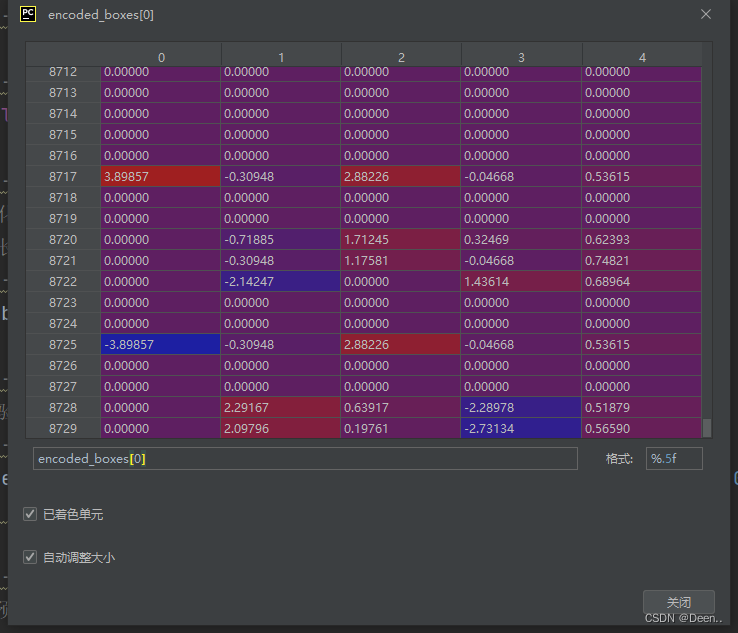
具体代码如下:
def encode_box(self, box, return_iou=True, variances = [0.1, 0.1, 0.2, 0.2]):
#---------------------------------------------#
# 计算当前真实框和锚框的重合情况
# iou [self.num_anchors]
# encoded_box [self.num_anchors, 5]
#---------------------------------------------#
iou = self.iou(box)
encoded_box = np.zeros((self.num_anchors, 4 + return_iou))
#---------------------------------------------#
# 找到每一个真实框,重合程度较高的锚框
# 真实框可以由这个锚框来负责预测
#---------------------------------------------#
assign_mask = iou > self.overlap_threshold
#---------------------------------------------#
# 如果没有一个锚框重合度大于self.overlap_threshold
# 则选择重合度最大的为正样本
#---------------------------------------------#
if not assign_mask.any():
#argmax()就是找iou中最大的值的索引,如果这里iou最大的值比设置的overlap_threshold还小,
#就让最大的那个iou对应的边界框来匹配这个真实框
assign_mask[iou.argmax()] = True
#---------------------------------------------#
# 利用iou进行赋值
#---------------------------------------------#
if return_iou:
encoded_box[:, -1][assign_mask] = iou[assign_mask]
#---------------------------------------------#
# 找到对应的锚框
#---------------------------------------------#
assigned_anchors = self.anchors[assign_mask]
#---------------------------------------------#
# 逆向编码,将真实框转化为ssd预测结果的格式
# 先计算真实框的中心与长宽
#---------------------------------------------#
box_center = 0.5 * (box[:2] + box[2:])
box_wh = box[2:] - box[:2]
#---------------------------------------------#
# 再计算重合度较高的锚框的中心与长宽
#---------------------------------------------#
assigned_anchors_center = (assigned_anchors[:, 0:2] + assigned_anchors[:, 2:4]) * 0.5
assigned_anchors_wh = (assigned_anchors[:, 2:4] - assigned_anchors[:, 0:2])
#------------------------------------------------#
# 逆向求取ssd应该有的预测结果
# 先求取中心的预测结果,再求取宽高的预测结果
# 存在改变数量级的参数,默认为[0.1,0.1,0.2,0.2]
#------------------------------------------------#
encoded_box[:, :2][assign_mask] = box_center - assigned_anchors_center
encoded_box[:, :2][assign_mask] /= assigned_anchors_wh
encoded_box[:, :2][assign_mask] /= np.array(variances)[:2]
encoded_box[:, 2:4][assign_mask] = np.log(box_wh / assigned_anchors_wh)
encoded_box[:, 2:4][assign_mask] /= np.array(variances)[2:4]
return encoded_box.ravel()
所有真实框与锚框计算iou后得到的best_iou如图所示:
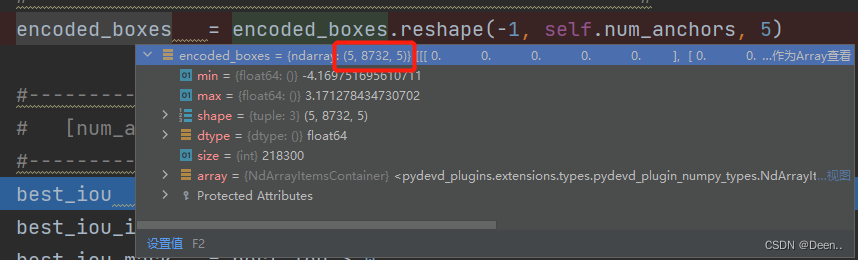
看一下格式[5,8732,5]第一个5意味着有五个真实框。这与锚框[8732,26]维度都不一样,所以我们要把这五个真实框装在一个[8732,5]中表现出来:
具体过程:
先取出encode_boxes的[:,:,4],也就是每个真实框与锚框计算的iou值,得到[5,8732]的数据。
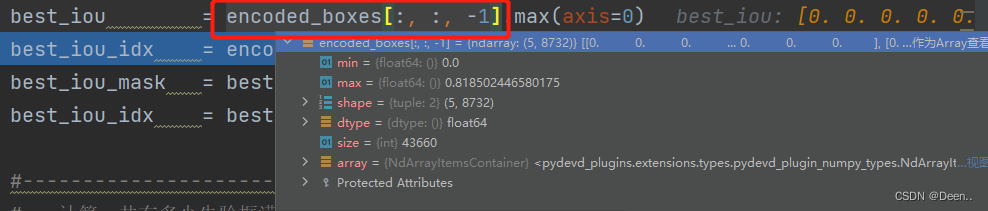
再进行5个真实框与锚框的匹配,axis=0,[5,8732]的0轴是真实框的数量,8732对应着8732个锚框,在ssd算法中,一个锚框只能对应一个真实框,一个真实框可以对应多个锚框。在同一个锚框下,5个真实框中谁的iou大,就保留谁的值,最后得到的结果如图:
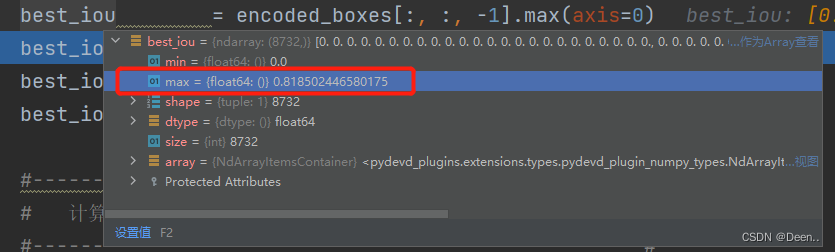
这里只知道哪个锚框要启用,还不知道这个锚框要给5个真实框中的哪个真实框用:
best_iou_idx = encoded_boxes[:, :, -1].argmax(axis=0)
通过这个代码得到如图,best_iou_idx的意思就是8732个锚框,每个锚框与哪个真实框匹配,如图中,best_iou_idx中最大值等4,就说明8732个锚框中至少有一个锚框是跟第五个真实框匹配的。
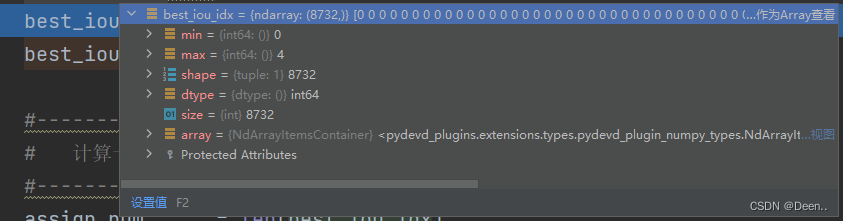
上述解释了一个锚框只能匹配一个真实框,我们来看看一个真实框可能匹配多个锚框:
下列表中是单个真实框与锚框计算得出的iou返回情况(8732个,因为锚框有8732个),这里只举8个
| 真实框编号\锚框编号 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 单个真实框与锚框计算得出的iou>0.5的数量 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0, | 0.62, | 0.63, | 0.63, | 0.86, | 0, | 0, | 0, | 0 | 4 |
| 1 | 0.89, | 0.75, | 0, | 0, | 0, | 0, | 0, | 0, | 0 | 2 |
| 2 | 0, | 0, | 0, | 0.85, | 0.65, | 0, | 0.54, | 0, | 0 | 3 |
| 3 | 0, | 0, | 0, | 0, | 0, | 0, | 0, | 0.74, | 0.88 | 2 |
| 4 | 0, | 0, | 0, | 0, | 0.76, | 0.67, | 0.80, | 0.67, | 0.96 | 4 |
以这8个锚框为例,编号为0的锚框匹配的是编号为1的真实框,编号为1的锚框匹配的是编号为1的真实框,以此类推,可以看到每个锚框只匹配一个真实框。但是编号为0的真实匹配却匹配了编号为2,4的锚框,所以一个真实框可以了若干个锚框。能匹配的前提都是,这个真实框跟8732个锚框计算得到的iou>预设值,也就是重合度高才能匹配。
取出这些匹配好的锚框的真实框:
best_iou_mask = best_iou > 0
best_iou_idx = best_iou_idx[best_iou_mask]
assign_num = len(best_iou_idx)
如图所示,有81个锚框被用来跟这5个真实框匹配了,assign_num=81。
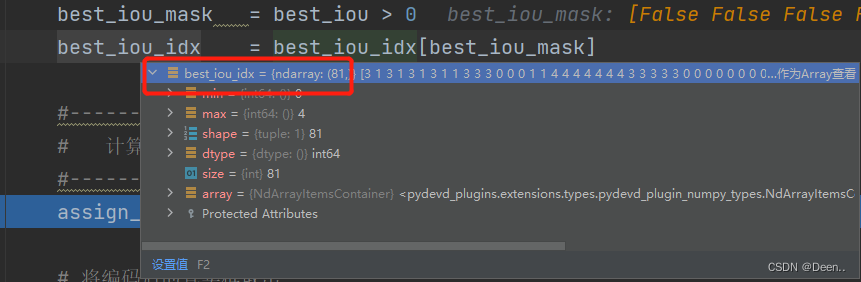
再根据索引将这些真实框编码后的的坐标取出,将坐标赋值给要输出的载体assignment,best_iou_mask是个bool列表,可以对assignment进行筛选。
assignment[:, :4][best_iou_mask] = encoded_boxes[best_iou_idx, np.arange(assign_num), :4]
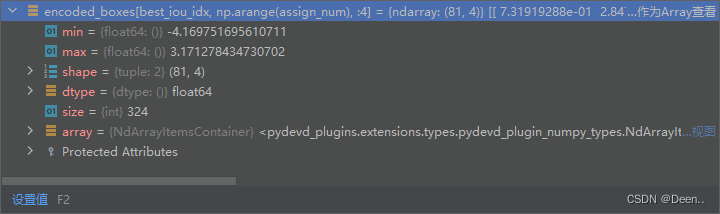
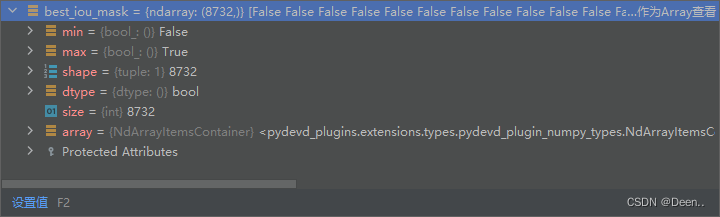
判断锚框是不是有匹配的真实框,如果有的话说明这里有目标,没有的话说明这里没有目标没有目标就是背景。
第5为是背景的判断,所以该位置匹配的话,就设置为0,说明该位置有目标,不是背景。
assignment[:, 4][best_iou_mask] = 0
最后1位是目标,如果该位置匹配的话,就设置为1,说明有目标
assignment[:, -1][best_iou_mask] = 1
再根据81个已经匹配完真实框的锚框,其中每一个锚框选的是5个真实框中的哪个的索引,取检索boxes中的类别,将其赋值给81个锚框的类别属性。
assignment[:, 5:-1][best_iou_mask] = boxes[best_iou_idx, 4:]
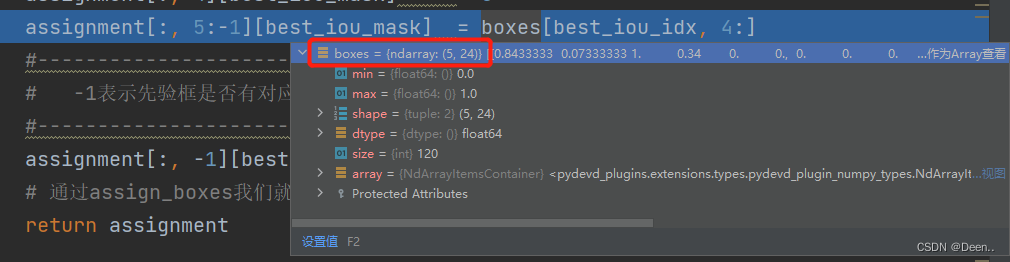
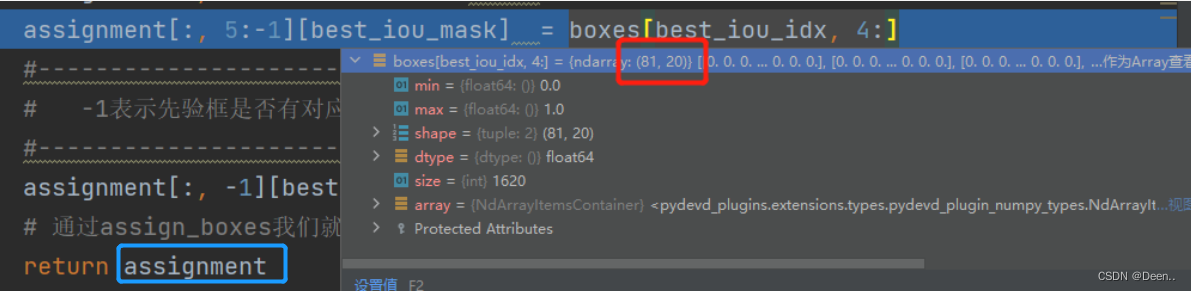
到此就将assignment的26位数据全部赋值完毕,将其返回,完成解码
- 数据返回
这样子就处理完这种图片的box信息。
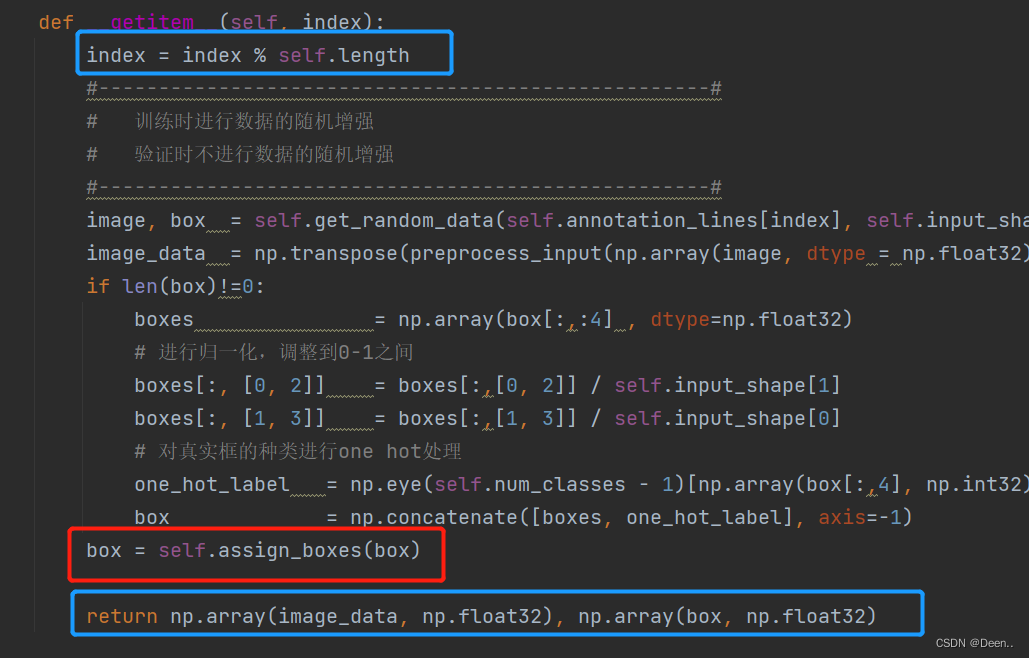
将这张图片的Image与box信息返给DataLoade的fetch函数后,DataLoader开始提供一个新的index送入getietm,进行下一张的处理。
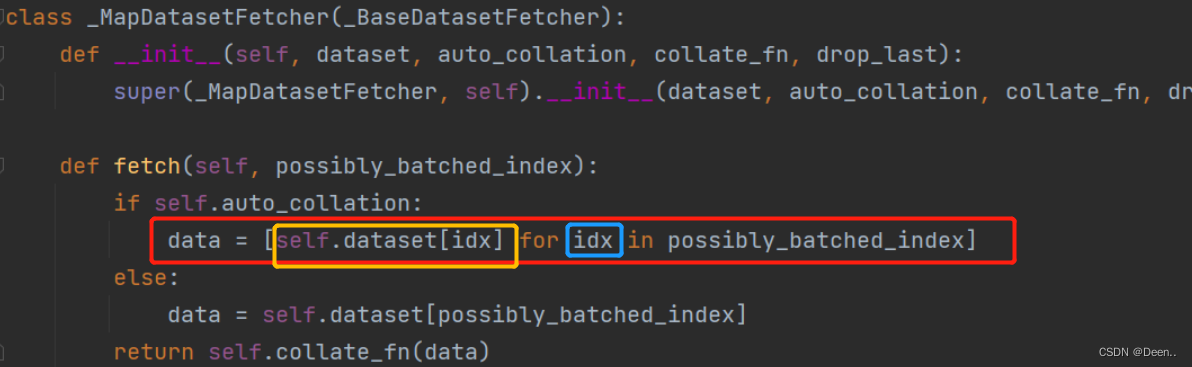
这一部分在加载机制中解读过。
等一个batch_size的数据全部处理完后,送入模型,进行下一步的训练。