PriorBox本质上是在原图上的一系列矩形框,如下图所示。某个特征图上的一个点根据下采样率可以得到在原图的坐标,SSD先验性地提供了以该坐标为中心的4个或6个不同大小的PriorBox,然后利用特征图的特征去预测这4个或6个PriorBox的类别与位置偏移量。
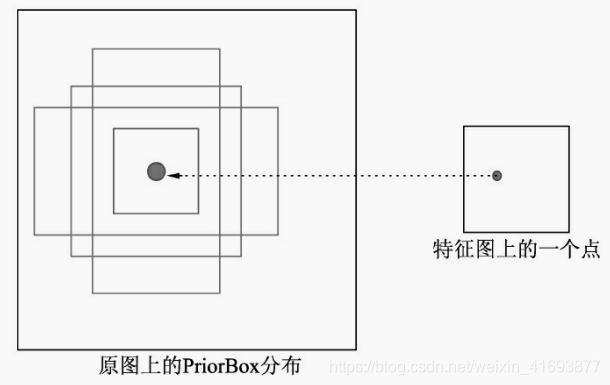
PriorBox生成
虽然Faster RCNN与SSD都采用类似的先验框机制,但是两者还是存在着很大的不同,可以总结为以下三点。
- 得到RoI区域的方式不同。Faster RCNN首先在第一个阶段对固定的Anchor进行了位置修正与筛选,得到感兴趣区域后,在第二个阶段再对该区域进行分类与回归,而SSD直接将固定大小宽高的PriorBox作为先验的感兴趣区域,利用一个阶段完成了分类与回归。
- 使用的特征图数量不同。在Faster RCNN中,所有Anchors对应的特征都来源于同一个特征图,而该层特征的感受野相同,很难处理被检测物体的尺度变化较大的情况,多个大小宽高的Anchors能起到的作用也有限。一般而言,在深度卷积网络中,浅层的特征图拥有较小的感受野,深层的特征图拥有较大的感受野,因此SSD充分利用了这个特性,使用了多层特征图来做物体检测,浅层的特征图检测小物体,深层的特征图检测大物体。
- 锚框的表示形式不同。虽然两者都是以边框中心坐标和边框的宽高(即[cx, cy, w ,h])来表示,然而Faster RCNN是将锚框还原到原图尺寸下,而SSD则是在特征图尺度下,且后两维是特征图尺度与原图大小的比例。
我们知道了SSD使用了多层特征图,即每个特征图上的每一个特征点都对应着一定数量的PriorBox,那如何确定每一个特征图PriorBox的具体大小呢?由于越深的特征图
拥有的感受野越大,因此其对应的PriorBox也应越来越大,SSD采用了一下公式来计算每一个特征图对应的PriorBox的尺度。
S k = S m i n + S m a x − S m i n 5 ( k − 1 ) k ∈ [ 1 , 6 ] S_k=S_{min}+\frac{S_{max}-S_{min}}{5}\left( k-1 \right) k\in[1,6] Sk=Smin+5Smax−Smin(k−1)k∈[1,6]
公式中K的取值为1、2、3、4、5、6,分别对应着SSD中的第4、7、8、9、10、11个卷积层。 S k S_{k} Sk代表这一层对应的尺度, S m i n S_{min} Smin为0.2, S m a x S_{max} Smax为0.9,分别表示最浅层与最深层对应的尺度与原图大小的比例,即第4个卷积层得到的特征图对应的尺度为0.2,第11个卷积层得到的特征图对应的尺度为0.9。
基于每一层的基础尺度 S k S_{k} Sk,对于第1、5、6个特征图,每个点对应
了4个PriorBox,因此其宽高分别为{
S k S_{k} Sk, S k S_{k} Sk}、 {
S k 2 \frac{S_{k}}{\sqrt{2}} 2Sk, 2 S k \sqrt{2}S_{k} 2Sk}、 {
2 S k \sqrt{2}S_{k} 2Sk, S k 2 \frac{S_{k}}{\sqrt{2}} 2Sk} 与
{
S k S k + 1 \sqrt{S_{k}S_{k+1}} SkSk+1, S k S k + 1 \sqrt{S_{k}S_{k+1}} SkSk+1},而对于第2、3、4个特征图,每个点对应了6个PriorBox,则在上述4个宽高值上再增加{
S k 3 \frac{S_{k}}{\sqrt{3}} 3Sk, 3 S k \sqrt{3}S_{k} 3Sk}和 {
3 S k \sqrt{3}S_{k} 3Sk, S k 3 \frac{S_{k}}{\sqrt{3}} 3Sk} 这两种比例的框。
源码
下面利用代码详细介绍如何生成每一层所需的PriorBox,代码位于layers/functions/prior_box.py中。
# 配置信息
class PriorBox(object):
"""
生成每一层特征图所需的PriorBox.
"""
def __init__(self, cfg):
super(PriorBox, self).__init__()
self.image_size = cfg['min_dim'] # 图片大小,为300
# number of priors for feature map location (either 4 or 6)
self.num_priors = len(cfg['aspect_ratios'])
self.variance = cfg['variance'] or [0.1]
self.feature_maps = cfg['feature_maps'] # 每一层特征图的大小
self.min_sizes = cfg['min_sizes']
self.max_sizes = cfg['max_sizes']
self.steps = cfg['steps'] # 每一层特征图的下采样倍数
self.aspect_ratios = cfg['aspect_ratios']
self.clip = cfg['clip']
self.version = cfg['name'] # 数据集名称
for v in self.variance:
if v <= 0:
raise ValueError('Variances must be greater than 0')
# 生成所有的PriorBox,需要每一个特征图的信息
def forward(self):
mean = []
for k, f in enumerate(self.feature_maps):
for i, j in product(range(f), repeat=2):
# f_k为每个特征图的尺寸
f_k = self.image_size / self.steps[k]
# 求取每个box的中心坐标
cx = (j + 0.5) / f_k
cy = (i + 0.5) / f_k
# 对应{S_k, S_k}大小的PriorBox
s_k = self.min_sizes[k]/self.image_size
mean += [cx, cy, s_k, s_k]
# 对应{√(S_k S_(k+1) ), √(S_k S_(k+1) )}大小的PriorBox
s_k_prime = sqrt(s_k * (self.max_sizes[k]/self.image_size))
mean += [cx, cy, s_k_prime, s_k_prime]
# 剩余的比例为2、1/2、3、1/3的PriorBox
for ar in self.aspect_ratios[k]:
mean += [cx, cy, s_k*sqrt(ar), s_k/sqrt(ar)]
mean += [cx, cy, s_k/sqrt(ar), s_k*sqrt(ar)]
# back to torch land
output = torch.Tensor(mean).view(-1, 4)
if self.clip:
output.clamp_(max=1, min=0)
return output