主要是记录一些采样方面的知识。参考来源如下:
https://blog.csdn.net/fengying2016/article/details/80593266
https://www.cnblogs.com/xinzhihao/p/11289108.html
为什么要采样?
从概率论的角度来解释机器学习,就是我们的模型是学习了样本的概率分布,我们认为我们的目标都遵从这个概率分布从而能有效的进行分类或者预测。但是对于我们已有的数据来说,一次性采样得到的数据可能非常的庞大(相对于建立的模型来说会花费特别多的资源),也有可能比较小(小样本问题)。
讨论大样本的问题,这时候我们没法也没有必要对所有的数据进行拟合,我们可以利用采样的方式,从原始的数据集构造出一个训练集,然后用剩下的部分作为测试集。
所以问题就是,在已知数据概率分布的情况下,如何对数据进行采样。这里有一道阿里的面试题:
一道编程题,现在有包含很多个样本数据的数组,现在对这些数进行多次有放回采样,但每个数都有自己的采样概率,这个概率存在另外一个数组里面,总概率是1,问怎么实现这个采样过程。
常见的采样算法
一、逆变换采样
对 任 意 随 机 变 量 ξ , 设 其 概 率 密 度 分 布 函 数 为 P ( x ) , 其 积 分 分 布 函 数 为 P ( x ) = ∫ x − ∝ p ( z ) d z , 只 要 有 均 匀 分 布 的 另 一 随 机 变 量 θ , 则 反 函 数 ξ = F − 1 ( θ ) 即 可 得 到 , 且 ξ 一 定 服 从 P ( x ) 分 布 。 对任意随机变量\xi ,设其概率密度分布函数为P\left( x \right) ,其积分分布函数为P\left( x \right) =∫x−\propto p\left( z \right) dz,只要有均匀分布的另一随机变量\theta ,则反函数\xi =F−1\left( \theta \right) 即可得到,且\xi 一定服从P\left( x \right) 分布。 对任意随机变量ξ,设其概率密度分布函数为P(x),其积分分布函数为P(x)=∫x−∝p(z)dz,只要有均匀分布的另一随机变量θ,则反函数ξ=F−1(θ)即可得到,且ξ一定服从P(x)分布。
逆变换法残生随机数的步骤:
1 、 生成一 个 服从均匀分布的随 机 数 U ∼ U n i t ( 0 , 1 ) ; 2 、 设 F ( x ) 为 指定分布的分布函数,则 X = F − 1 ( U ))即 为 指定分布的随 机 数。 示 例:生成满足 λ = 2 的指数分布随 机 数。分析:由 f ( x ) 得出 F ( x ) — > F ( x ) = 1 − e − λ x ,进而求得 F ( x ) 逆函数,得出 X = F − 1 ( u ) = − 1 λ ln ( 1 − u ) 1、\text{生成一}个\text{服从均匀分布的随}机\text{数}U\sim Unit\left( 0,1 \right) ; 2、\text{设}F\left( x \right) 为\text{指定分布的分布函数,则}X=F−1\text{(}U\text{))即}为\text{指定分布的随}机\text{数。} 示\text{例:生成满足}\lambda =2\text{的指数分布随}机\text{数。} \text{分析:由}f\left( x \right) \text{得出}F\left( x \right) —>F\left( x \right) =1−e−\lambda x\text{,进而求得}F\left( x \right) \text{逆函数,得出}X=F−1\left( u \right) =−1\lambda \ln \left( 1−u \right) 1、生成一个服从均匀分布的随机数U∼Unit(0,1);2、设F(x)为指定分布的分布函数,则X=F−1(U))即为指定分布的随机数。示例:生成满足λ=2的指数分布随机数。分析:由f(x)得出F(x)—>F(x)=1−e−λx,进而求得F(x)逆函数,得出X=F−1(u)=−1λln(1−u)
Len = 1000000;
u = rand(1,Len);
lemda = 2;
x = -1/lemda*(log(1-u));
二、拒绝采样(Rejection Samping)
也 被 称 为 接 受 采 样 ( A c c e p t S a m p i n g ) , 对 于 目 标 分 布 p ( x ) , 选 取 一 个 容 易 采 样 的 参 考 分 布 q ( x ) , 使 得 对 于 任 意 的 x 都 有 : p ( x ) ⩽ M ⋅ q ( x ) 也被称为接受采样(Accept Samping),对于目标分布p(x),选取一个容易采样的参考分布q(x),使得对于任意的x都有:p\left( x \right) \leqslant M\cdot q\left( x \right) 也被称为接受采样(AcceptSamping),对于目标分布p(x),选取一个容易采样的参考分布q(x),使得对于任意的x都有:p(x)⩽M⋅q(x)
其采样过程如下:
1 、 从 参 考 分 布 q ( x ) 中 随 机 抽 取 一 个 样 本 x i 2 、 从 均 匀 分 布 U ( 0 , 1 ) 产 生 一 个 随 机 u i 3 、 如 果 u i < p ( x i ) M ⋅ q ( x i ) , 则 接 受 样 本 x i , 否 则 拒 绝 , 一 直 重 复 1 − 3 步 骤 , 直 到 新 产 生 的 样 本 量 满 足 要 求 。 1、从参考分布q(x)中随机抽取一个样本xi\\ 2、从均匀分布U(0,1)产生一个随机ui\\ 3、如果u_i<\frac{p\left( x_i \right)}{M\cdot q\left( x_i \right)},则接受样本xi,否则拒绝,一直重复1-3步骤,直到新产生的样本量满足要求。 1、从参考分布q(x)中随机抽取一个样本xi2、从均匀分布U(0,1)产生一个随机ui3、如果ui<M⋅q(xi)p(xi),则接受样本xi,否则拒绝,一直重复1−3步骤,直到新产生的样本量满足要求。
三、重要性采样
四、马科夫蒙特卡洛采样法
失衡样本采样
我们在实际的建模中总会遇到很多失衡的数据集,比如点击率模型、营销模型、反欺诈模型等等,往往坏样本(or好样本)的占比才千分之几。虽然目前有些机器学习算法会解决失衡问题,比如XGBoost,但是很多时候还是需要我们去根据业务实际情况,对数据进行采样处理,主要还是分两种方式:
过采样(over-sampling):从占比较少的那一类样本中重复随机抽样,使得最终样本的目标类别不太失衡;
欠采样(under-sampling):从占比较多的那一类样本中随机抽取部分样本,使得最终样本的目标类别不太失衡;
科学家们根据上述两类,衍生出了很多方法,如下:
一、过采样类
1、 Random Oversampling
从样本少的类别随机抽样进行扩充,但是大部分情况会造成过拟合
2、SMOTE
在少数类样本之间通过插值操作来产生额外的样本。
对于一个少数类样本,使用K-Mean法(K值需要人工确定)求出距离。距离最近的k个少数类样本,其中距离定义为样本之间n维特征空间的欧式距离,然后从k个样本点中随机抽取一个,使用下面的公式生成新的样本点:
x n e w = x i + ( x ^ i − x i ) × δ x_{new}\,\,=\,\,x_i\,\,+\,\,\left( \hat{x}_i\,\,-\,\,x_i \right) \,\,\times \delta xnew=xi+(x^i−xi)×δ
但是,SMOTE算法也是有缺点的:
(1)如果选取的少数类样本周围都是少数类样本,那么新合成的样本可能不会提供太多有用的信息;
(2)如果选取的少数类样本周围都是多数类样本,那么这可能会是噪声,也无法提升分类效果。
其实,最好的新样本最好是在两个类别的边界附近,这样子最有利于分类,所以下面介绍一个新算法——Border-Line SMOTE。
3、Border-Line SMOTE
这个算法一开始会先将少数类样本分成3类,分别DANGER、SAFE、NOISE,如下图: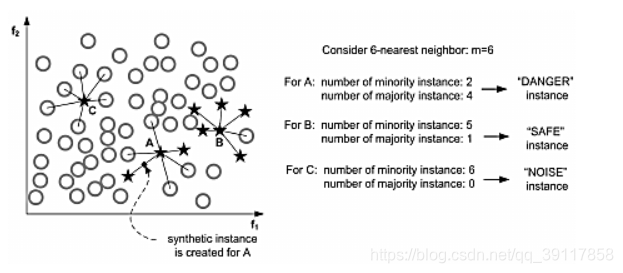
而Border-line SMOTE算法只会在“DANGER”状态的少数类样本中去随机选择,然后利用SMOTE算法产生新样本。
二、降采样类
- Random Undersampling
这类也是比较简单的,就是随机从多数类中删除一些样本,这样子的缺失也是很明显,那就是造成部分信息丢失,整体模型分类效果不理想。
- EasyEnsemble 和 BalanceCascade
这两个算法放在一起的原因是因为都用到了集成思想来处理随机欠采样的信息丢失问题。
-
EasyEnsemble :将多数类样本随机划分成n份,每份的数据等于少数类样本的数量,然后对这n份数据分别训练模型,最后集成模型结果。
-
BalanceCascade:这类算法采用了有监督结合boosting的方式,在每一轮中,也是从多数类中抽取子集与少数类结合起来训练模型,然后下一轮中丢弃此轮被正确分类的样本,使得后续的基学习器能够更加关注那些被分类错误的样本。
-
NearMiss
NearMiss本质上是一种原型选择(prototype selection)方法,即从多数类样本中选取最具代表性的样本用于训练,主要是为了缓解随机欠采样中的信息丢失问题。NearMiss采用一些启发式的规则来选择样本,根据规则的不同可分为3类:
NearMiss-1: 选择到最近的K个少数类样本平均距离最近的多数类样本
NearMiss-2: 选择到最远的K个少数类样本平均距离最近的多数类样本
NearMiss-3: 对于每个少数类样本选择K个最近的多数类样本,目的是保证每个少数类样本都被多数类样本包围
NearMiss-1和NearMiss-2的计算开销很大,因为需要计算每个多类别样本的K近邻点。另外,NearMiss-1易受离群点的影响,如下面第二幅图中合理的情况是处于边界附近的多数类样本会被选中,然而由于右下方一些少数类离群点的存在,其附近的多数类样本就被选择了。相比之下NearMiss-2和NearMiss-3不易产生这方面的问题。
随机数的一些问题
一、10%生成0,90%生成1.均匀生成0和1的rand2()
解决:生成01的概率和生成10的概率相等,将01作为0输出,10作为1输出,可以得到均匀的rand2()
二、任意范围的随机数生成randn()
1、有了均匀的0和1可以通过生成二进制数的方式生成任意数。
2、
rand7() -> rand5() 均匀生成0-6,筛出大于5的数得到均匀的0-4
rand5() -> rand7() 生成rand5()*2 + rand()5 //均匀生成0-15
筛除大于13的得到均匀的0-13,对7求余生成均匀的0-6;
U = s t a r t + ( e n d − s t a r t ) ⋅ r a n d ( ) R A N D _ M A X U\,\,=\,\,start+\,\,\frac{\left( end\,\,-\,\,start \right) \cdot rand\left( \right)}{RAND\_MAX} U=start+RAND_MAX(end−start)⋅rand()
三、按概率生成,a=5/17,b=3/17,c=6/17,d=2/17
1、就是扩充数据,构成五个a,三个b。。。然后随机1-17的随机数进行采样
2、作比较,
生成均匀分布的氛围为0-17的随机数。0-5/17为a, 5/17-8/17为b,以此类推
每次采样查询logN次
数据集的划分
对于得到的数据,我们分为训练集(train),测试集(test)和验证集(validation)。
不管哪一种方式,测试集是不会参与到训练当中的。
一、按比例划分
按照一定的比例,例如训练集,验证集,测试集按照7:2:1或者5:3:2等比例进行划分
二、N折交叉验证
1、除了测试集外的数据平均分为N份(采样成N份等其他方式)。
2、选择其中一份作为验证集,其他作为训练集进行模型训练,最后在测试集中得到模型的精度。
3、将2重复N次,求平均精度作为此时模型的精度。
4、修改模型超参数,重复1-3.
N折交叉验证一般用作超参数调整,学习率、正则化等等。