导读
个人解读,仅做学习笔记使用
参考文章:
ssd loss详解
博客园:深度学习笔记(七)SSD 论文阅读笔记简化
Pytorch 搭建自己的SSD目标检测平台
损失函数的目的是将预测结果无线逼近真实结果,也就是让模型预测的准确,其本质就是在计算,预测结果与真实结果的差距的函数。如L1Loss:

监督学习的目的就是让训练结果逼近真实结果,所以损失函数越小,这个逼近的效果越好,模型训练的效果就越好。采用不同的损失策略,梯度下降的速度就不同,所以要根据研究内容去选取合适的损失函数。
损失计算在训练中的位置如图所示:
Loss函数计算的是预测值跟真实值的差距。预测框会按着真实框的格式来生成,预测框的格式跟真实框一致时计算,在计算之前我们先看一下真实框的格式,真实框用8732个锚框的相对偏移量表示,26中前4位是真实框相对锚框的偏移量(这里的锚框坐标类型是[x,y,w,h]),第5位用来判断是不是背景,最后1位用来判断是不是目标,中间20位是类别,其实只有真实框与锚框匹配上的时候才处理匹配上的那个锚框,没匹配上框数值都是默认值,最后再提一点,一个锚框只能匹配一个真实框,一个真实框可以匹配多个锚框:
![[x,y,w,h,背景,···种类···,目标]](https://img-blog.csdnimg.cn/9fed32a1072c420f91318e7fd90985be.png)
[x,y,w,h,背景,···种类···,目标]
预测框的第5位对应背景,最后1位对应目标,设置标签为背景的预测框为负样本,标签不为背景的为正样本,通常负样本的数量远远多于正样本,所以进行loss计算时,不取全部负样本进行计算。按正负样本比例,根据正样本数量,挑出一定数量的负样本。
对于负样本的挑选,论文中称之为"困难样本挖掘",其实就是对负样本按照loss大小排序,选择前n个loss大的负样本进行梯度更新。
综上,ssd的最终loss就是挑选的正负样本的总loss。
损失函数由分类损失函数(conf)跟位置损失(loc)函数构成

让每一个 prior box 经过Jaccard系数计算(就是IOU交并集计算)和真实框的相似度,阈值只有大于 0.5 的才可以列为候选名单(真实框相对锚框转换完后8732个框里背景为0框);假设选择出来的是N个匹配度高于百分之五十的框吧,我们令 i 表示第 i 个默认框,j 表示第 j 个真实框,p表示第p个类。那么 x i , j p x_{i,j}^{p} xi,jp表示 第 i 个 prior box(锚框) 与 类别 p 的 第 j 个 ground truth box(真实框) 相匹配的Jaccard系数,若不匹配的话,则 x i , j p x_{i,j}^{p} xi,jp=0。总的目标损失函数(objective loss function)就由 localization loss(loc) 与 confidence loss(conf) 的加权求和:
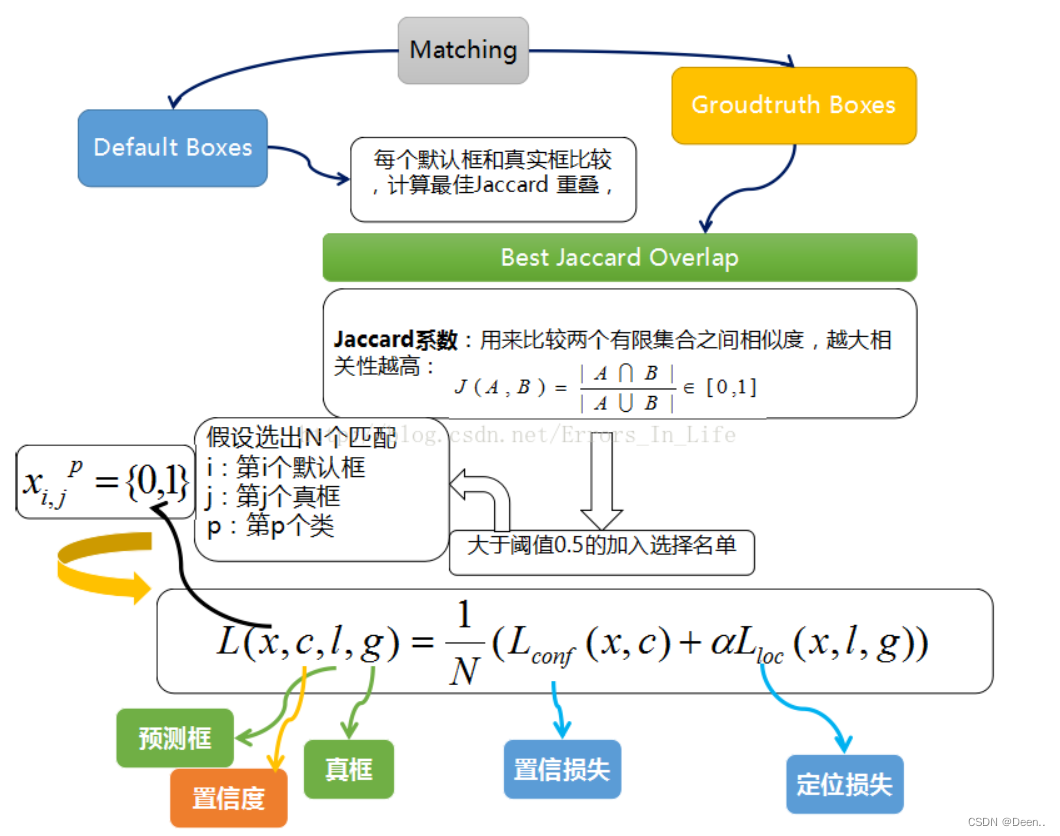
- N 是与 ground truth box 相匹配的 prior boxes 个数(真样本跟负样本的和)
- localization loss(loc) 是 Fast R-CNN 中 Smooth L1 Loss,用在 predict box(l) 与 ground truth box(g) 参数(即中心坐标位置,width、height)中,回归 bounding boxes 的中心位置,以及 width、height
- confidence loss(conf) 是 Softmax Loss,输入为每一类的置信度 c
- 权重项 α默认设置为 1
分类损失函数
分类损失函数用的是softmax_loss(),经过softmax后的交叉熵计算。下列式子中是选取正负样本的softmax_loss为分类损失计算内容,而负样本数量是按正负样本比例挑选的,所以实际还有许多负样本被pass了。在代码中先计算所有样本的分类损失,然后再挑出正负样本的损失求和。
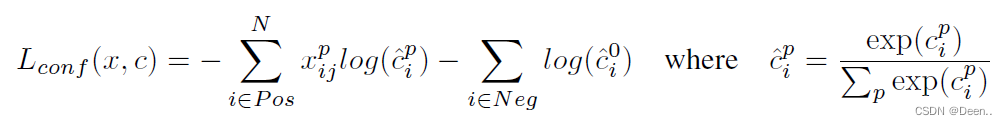
- 计算所有样本的softmax_loss:
# batch_size,8732,21 -> batch_size,8732
# --------------------------------------------- #
conf_loss = self._softmax_loss(y_true[:, :, 4:-1], y_pred[:, :, 4:])
def _softmax_loss(self, y_true, y_pred):
#torch.clamp将输入input张量每个元素的夹紧到区间 [min,max],并返回结果到一个新张量。
y_pred = torch.clamp(y_pred, min = 1e-7)
softmax_loss = -torch.sum(y_true * torch.log(y_pred),
axis=-1)
return softmax_loss
- 挑选正样本的分类损失函数并求和:
#batch_size,8732
pos_conf_loss = torch.sum(conf_loss * y_true[:, :, -1],
axis=1)
- 选负样本的分类损失函数:
预测结果中把不是背景的每个预测框预测的各类的预测值求和,求和后的概率越大,认为这个预测框越难分类。按从大到小排序后,跳出负样本总数量的预测框,认为他们就是负样本。假设负样本数量有1245个,则挑选中格式变化:
[batch_size,8732,20]->[batch_size,8732]->[batch_size,1245]
然后根据这100个负样本(一会补上)
具体流程:
- 统计每张图正样本的数量:
#num_pos [batch_size,]
num_pos = torch.sum(y_true[:, :, -1], axis=-1)
- 统计每张图负样本的数量:
按正负样本比例提取正样本,这里按1:3选取负样本:
num_neg = torch.min(self.neg_pos_ratio * num_pos, num_boxes - num_pos)
- 统计每一批(16张)图中负样本的数量:
num_neg_batch = torch.sum(num_neg)
- 挑出是背景的预测框:
预测框的最后1位目标判断
可以按最后1位来挑是背景的预测框:
max_confs = (max_confs * (1 - y_true[:, :, -1])).view([-1])
也可以按第5位来挑是背景的预测框:
max_confs = (max_confs * y_true[:, :, 4]).view([-1])
找到概率求和最大的k个值,这里的k是负样本的数量。
通过torch.topk()函数找到负样本的索引
#torch.topk
#返回列表中最大的n个值
#input -> 输入tensor
# k -> 前k个
# dim -> 默认为输入tensor的最后一个维度
# sorted -> 是否排序
# largest -> False表示返回第k个最小值
#indeces 负样本的索引
_, indices = torch.topk(max_confs, k = int(num_neg_batch.cpu().numpy().tolist()))
然后将batch_size张图片的全部的分类损失函数平铺开,根据索引,找到这些负样本的损失值。
例如,k为1245,总共有16张图,每张图有8732个框,全部平铺开有16*8732=139712个框,根据索引挑出1245个分类损失函数。
#torch.gather作用:收集输入的特定维度指定位置的数值
# input(tensor): 待操作数。
# dim(int): 待操作的维度。
# index(LongTensor): 如何对input进行操作.
neg_conf_loss = torch.gather(conf_loss.view([-1]), 0, indices)
到此就求得负样本的分类损失函数。
回归损失函数
回归损失函数既计算预测框跟真实框坐标的差距情况。
SSD算法的位置损失函数:
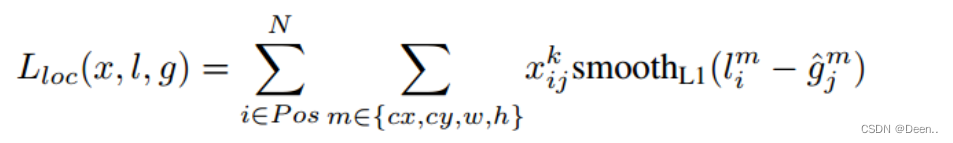
如公式所示,位置损失函数中有 x i , j p x_{i,j}^{p} xi,jp,正样本时候 x i , j p = 1 x_{i,j}^{p}=1 xi,jp=1,负样本时为0。所以位置损失函数仅对正样本存在作用。
这里采用的是l1_smooth_loss:
L 1 = ∑ i = 1 n ∣ l − g ∣ L_1 =\sum_{i=1}^{n} {|l-g|} L1=i=1∑n∣l−g∣
l l l是预测框坐标, g g g是真实框坐标,令 x = ∣ l − g ∣ x=|l-g| x=∣l−g∣, x x x是预测框跟真实框的差值。
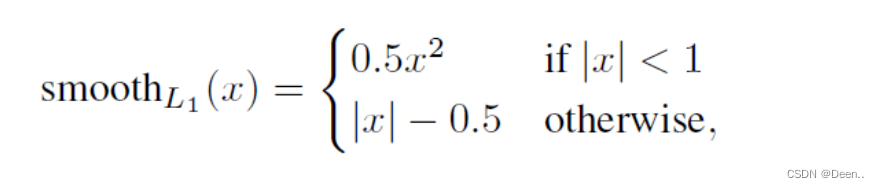
代码中也是先计算所有预测框跟真实框的l1_Smooth_loss,然后再去挑出正样本的计算结果作为SSD模型的位置损失函数值。
计算所有框的位置损失:
loc_loss = self._l1_smooth_loss(y_true[:, :, :4],
y_pred[:, :, :4])
def _l1_smooth_loss(self, y_true, y_pred):
abs_loss = torch.abs(y_true - y_pred)
sq_loss = 0.5 * (y_true - y_pred)**2
l1_loss = torch.where(abs_loss < 1.0, sq_loss, abs_loss - 0.5)
return torch.sum(l1_loss, -1)
挑选全部正样本的的位置损失后加和:
pos_loc_loss = torch.sum(loc_loss * y_true[:, :, -1],
axis=1)
完成位置损失函数计算。
损失函数Loss
将上述计算得到的正负样本的分类损失函数与位置损失函数求和再取平均后,就是SSD模型的损失函数值。
total_loss = torch.sum(pos_conf_loss) + torch.sum(neg_conf_loss) +torch.sum(self.alpha * pos_loc_loss)
total_loss = total_loss / torch.sum(num_pos)