目录
三、依据不同任务的梯度大小来动态修正其loss权重GradNorm
四、根据LOSS变化动态均衡任务权重Dynamic Weight Average(DWA)
一、综述
MTN模型主要用于两个方面,1.将多个模型合为一个显著降低车载芯片负载。2.将多个任务模型合为一个,有助于不同模型在共享层的特征可以进行互补,提高模型泛化性能的同时,也有可能提高指标。传统的方法是直接不同任务loss相加或者人为设置权重,这样很费时,也很难找到最优解。接下来的论文将会为大家介绍一些更优秀的MTN方法。
二、依据任务不确定性加权多任务损失
论文地址: https://arxiv.org/pdf/1705.07115.pdf
文章通过对损失函数求最大似然估计,同时引入不同任务的不确定性(可以理解为噪声),最大似然估计的推理结果如下:
1.两个任务都为回归任务

2.一个任务为回归任务,一个任务为分类任务

可以看到损失是由不确定性估计的倒数来加权的,后面的log(不确定性)是为了防止不确定性变得太大(类似于正则项)。当模型不确定性变小后,任务权重会增大,造成无效学习,所以论文里使用的(annealing the lr with a power law) 不会翻译。。。。。同时论文里也表明这个不确定性的初始化很鲁棒,都可以收敛的很好。
代码:
log_vars = nn.Parameter(torch.zeros((2)))
def criterion(y_pred, y_true, log_vars):
loss = 0
for i in range(len(y_pred)):
weight = torch.exp(-log_vars[i])
diff = (y_pred[i]-y_true[i])**2.
loss += torch.sum(weight * diff + log_vars[i], -1)
return torch.mean(loss)其中diff表示一个任务的loss,log_vars是可学习的参数。权重为weight = torch.exp(-log_vars[i]),后面加个log_vars[i]是一个惩罚项,防止任务不确定性变得太大,导致权重很小不更新。大家跟论文里对比一下会发现,模型学习参数log_vars[i] = log(不确定性**2),使用log是为了让其更加平滑稳定,便于学习。
在实际应用中,训mtn有的时候loss会变负,就是因为log_vars有可能为负的,把loss带成负的了。
所以后续有论文对其进行了改进,论文地址:https://arxiv.org/pdf/1805.06334.pdf

将正则项变为log(1+log_vars**2),这样正则项就不会为负,同时还能起到正则化效果。具体代码如下:
class AutomaticWeightedLoss(nn.Module):
def __init__(self, num=2):
super(AutomaticWeightedLoss, self).__init__()
params = torch.ones(num, requires_grad=True)
self.params = torch.nn.Parameter(params)
def forward(self, *x):
loss_sum = 0
for i, loss in enumerate(x):
loss_sum += 0.5 / (self.params[i] ** 2) * loss + torch.log(1 + self.params[i] ** 2)
return loss_sum三、依据不同任务的梯度大小来动态修正其loss权重GradNorm
论文地址:https://arxiv.org/abs/1711.02257
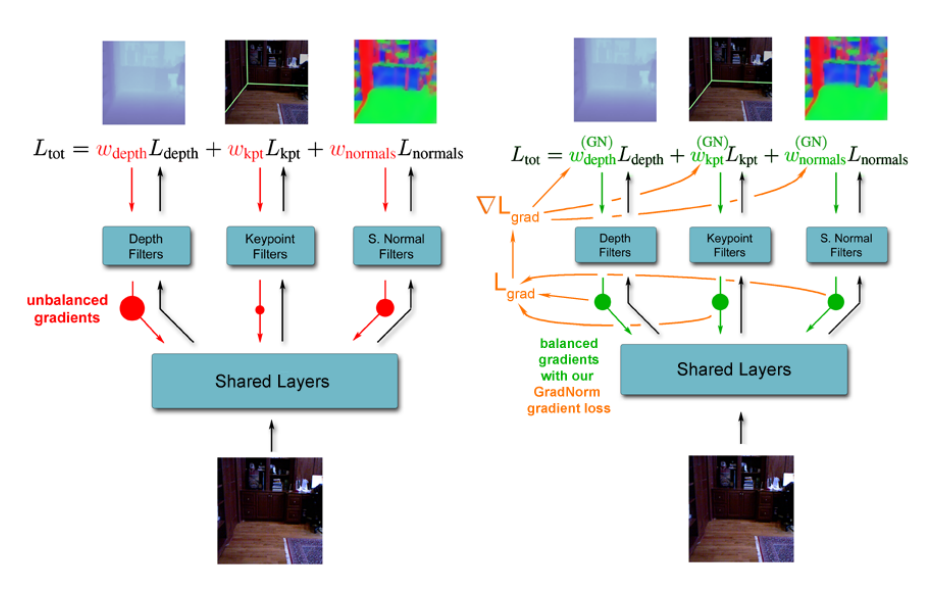
在MTN模型中,不同的任务其反向传播的梯度大小不一,有的大对于权重的影响大,收敛的快,效果好,有些任务则相反。那么是否可以根据其梯度大小对其loss权重动态优化?本文就是。
我们要根据任务梯度来修正loss权重,所以首先要求任务的梯度,也不能求对所有模型W的梯度,论文里只求对共享层最后一层W的梯度,然后再求这些梯度对于loss权重的导数,根据导数对loss权重更新。这样可以使得不同任务的梯度值在一个共同的规模,同时让他们以相似的速度收敛。
首先讲一下算法流程
1.前向传播计算总损失
2.计算每个任务loss对于共享层最后一层权重的梯度
3.计算梯度LOSS(主要是对不同的梯度进行修正,从而达到均衡的效果)
4.计算梯度LOSS对任务权重wi的导数
5.利用第一步的总loss更新模型参数
6.利用第四步的导数更新任务权重,并对任务权重进行归一化操作

上面是论文里求梯度loss的公式,表示第i个任务的梯度二范数,
表示求平均,
表示t时刻i任务的模型输出loss,看最后一个公式,其值越大就表明任务学习的越慢,越小表明学习的越快。由此可知
越大表示学的越慢,越小表示学的越快。学的快的其
梯度就大,后面
小,则第一个式子梯度LOSS就大,这样对任务权重wi求导数,更新就会使wi变小。反之学的慢的,wi就会变大。
在更新完wi后,对其进行归一化操作Σiwi(t)=T,让他们的和为定值,这样就和学习率解耦了,无论怎么变,只是改变他们的比例,其和永远为定值。wi更新的学习率和模型参数的学习率相同。
α是超参数,α 越大,对其梯度均衡效果就越强。梯度loss对wi求导时,减号后面的当作一个常量,尽管他们和wi也有关,这是为了防止wi收敛于0,这一块不太理解,有推导明白的可以交流一下。
代码实现:
#!/usr/bin/env python
# coding: utf-8
"""
Training with GradNorm Algorithm
"""
import numpy as np
import torch
def gradNorm(net, layer, alpha, dataloader, num_epochs, lr1, lr2, log=False):
"""
Args:
net (nn.Module): a multitask network with task loss
layer (nn.Module): a layers of the full network where appling GradNorm on the weights
alpha (float): hyperparameter of restoring force
dataloader (DataLoader): training dataloader
num_epochs (int): number of epochs
lr1(float): learning rate of multitask loss
lr2(float): learning rate of weights
log (bool): flag of result log
"""
# init log
if log:
log_weights = []
log_loss = []
# set optimizer
optimizer1 = torch.optim.Adam(net.parameters(), lr=lr1)
# start traning
iters = 0
net.train()
for epoch in range(num_epochs):
# load data
for data in dataloader:
# cuda
if next(net.parameters()).is_cuda:
data = [d.cuda() for d in data]
# forward pass
loss = net(*data)
# initialization
if iters == 0:
# init weights
weights = torch.ones_like(loss)
weights = torch.nn.Parameter(weights)
#detach生成一个新的张量,从计算图中分离下来,不具有梯度
T = weights.sum().detach() # 权重初始化为1,这个T是所有loss权重的和,是不变的
# 设置loss权重的优化函数,专门针对这个weights
optimizer2 = torch.optim.Adam([weights], lr=lr2)
# 得到一开始的L(0)第0时刻的loss
l0 = loss.detach()
# 计算加权后的loss,矩阵乘法
weighted_loss = weights @ loss
# clear gradients of network
optimizer1.zero_grad()
# backward pass for weigthted task loss
weighted_loss.backward(retain_graph=True)
# compute the L2 norm of the gradients for each task
gw = []
for i in range(len(loss)):
dl = torch.autograd.grad(weights[i]*loss[i], layer.parameters(), retain_graph=True, create_graph=True)[0]
gw.append(torch.norm(dl))
gw = torch.stack(gw)
# compute loss ratio per task
loss_ratio = loss.detach() / l0
# compute the relative inverse training rate per task
rt = loss_ratio / loss_ratio.mean()
# compute the average gradient norm
gw_avg = gw.mean().detach()
# compute the GradNorm loss
constant = (gw_avg * rt ** alpha).detach()
gradnorm_loss = torch.abs(gw - constant).sum()
# clear gradients of weights
optimizer2.zero_grad()
# backward pass for GradNorm
gradnorm_loss.backward()
# log weights and loss
if log:
# weight for each task
log_weights.append(weights.detach().cpu().numpy().copy())
# task normalized loss
log_loss.append(loss_ratio.detach().cpu().numpy().copy())
# update model weights
optimizer1.step()
# update loss weights
optimizer2.step()
# renormalize weights
weights = (weights / weights.sum() * T).detach()
weights = torch.nn.Parameter(weights)
optimizer2 = torch.optim.Adam([weights], lr=lr2)
# update iters
iters += 1
# get logs
if log:
return np.stack(log_weights), np.stack(log_loss)代码里求模型loss的时候没有求和就backward了,我认为应该不对,要求个和。
四、根据LOSS变化动态均衡任务权重Dynamic Weight Average(DWA)
论文地址:1803.10704v1.pdf (arxiv.org)

该文章受到grad norm的启发,做了一个简化版,他单纯考虑每个任务loss的变化率来动态衡量其权重。反应的是任务收敛的速度。T是一个超参,用来调节均衡程度。T特别大时,任务权重都一样。
该方法优点是速度快,不像GN那么耗时,缺点是有些任务的loss变化率虽然一样,但是他们的大小量纲不同,也就是梯度大小不同,对于模型参数的影响还是差很多了。