训练后在runs/train文件下生成了包含这些文件或文件夹:
一、 weights文件:
训练后会得到一个权重文件(weights),weights文件是YOLOv7模型的核心,它保存了模型的训练结果,也就是训练好的模型,是进行目标检测的必要文件。该文件内包括best.pt和last.pt,一般使用best.pt去进行推理。这个文件包含了训练好的神经网络的参数,这些参数描述了神经网络的结构和权重,可以用于对新的图像进行目标检测。
具体来说,YOLOv7的训练过程中,会使用训练集中的图像和标签(bounding box和类别标签)来训练神经网络,使得神经网络能够准确地检测出图像中的目标。训练完成后,得到的权重文件就是包含了这个训练好的神经网络的所有参数,这些参数可以被用来进行接下来的目标检测。在进行目标检测时,我们可以将权重文件加载到YOLOv7模型中,然后对新的图像进行检测,得到目标的位置和类别信息。

(默认25epoch保存一次模型,以及保存最后5个epoch的模型)
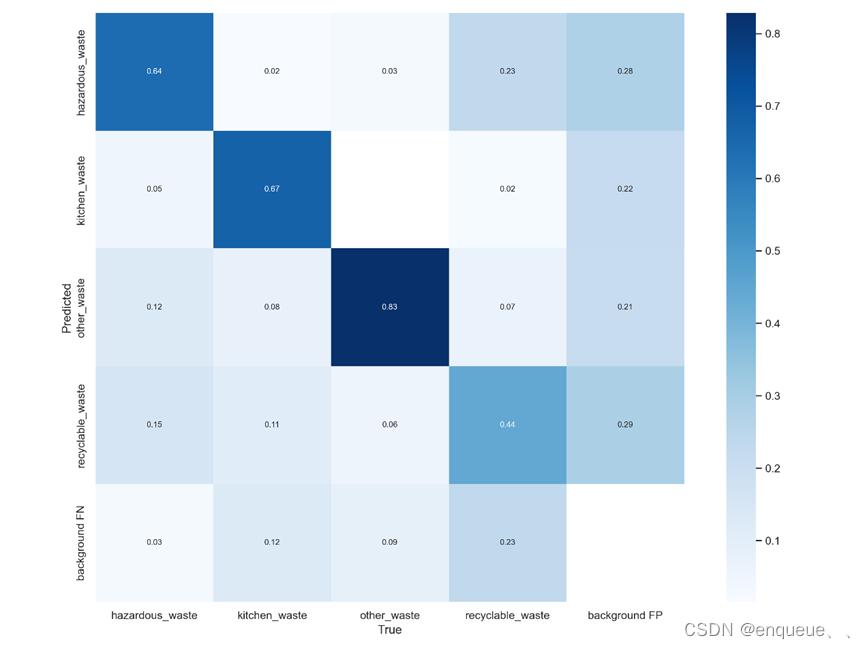
二、 混淆矩阵(confusion_matrix.png)
混淆矩阵(confusion matrix)是用于评估分类模型性能的一种常用方法。
在目标检测中,我们通常会将每个检测结果分配给一个类别,因此可以使用混淆矩阵来评估模型对每个类别的分类准确性。
在YOLOv7的训练过程中,每个图像都被标记为包含哪些目标物体和它们的类别。训练完成后,可以使用测试集来评估模型的性能。在测试集上,YOLOv7会对每个图像进行检测,并将检测结果与真实标签进行比较。如果检测结果正确,则被归类为True Positive(TP);如果检测结果错误,则被归类为False Positive(FP)或False Negative(FN)。这些结果可以用混淆矩阵来表示。
混淆矩阵的行表示真实标签,列表示预测标签。对角线上的元素表示分类正确的样本数,而其他元素表示分类错误的样本数。通过分析混淆矩阵,可以计算出各种分类指标,如准确率、召回率、F1-score等,用于评估模型的性能。
- TP(True Positive): 将正类预测为正类数 即正确预测,真实为0,预测也为0;
- FN (False Negative):将正类预测为负类 即错误预测,真实为0,预测为1;
- FP(False Positive):将负类预测为正类数 即错误预测, 真实为1,预测为0;
- TN (True Negative):将负类预测为负类数,即正确预测,真实为1,预测也为1;
精确率和召回率的计算方法:
- 精确率Precision=TP / (TP+FP), 在预测是Positive所有结果中,预测正确的比重
- 召回率recall=TP / (TP+FN), 在真实值为Positive的所有结果中,预测正确的比重
- 参考了这个博主的文章
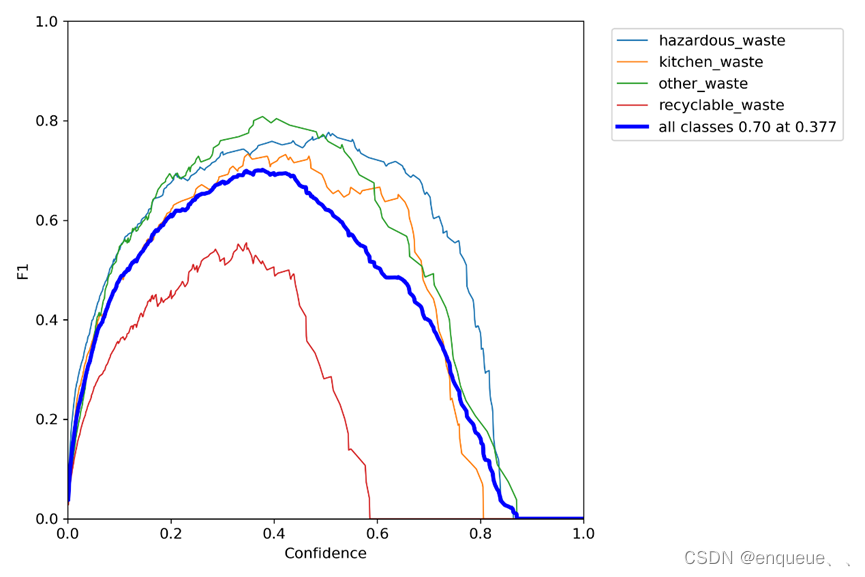
三、 F1_curve.png
F1_curve.png 是 YOLOv7 模型在训练过程中生成的一张图像,用于可视化模型的 F1-score 值随着训练轮次的变化情况。
F1-score 是一种综合考虑了分类模型的准确率和召回率的指标,用于评估模型的分类性能。在目标检测任务中,F1-score 可以用于评估模型在检测出所有目标的情况下的精确性和完整性。
在 YOLOv7 的训练过程中,每个训练轮次结束后,会计算出模型在验证集上的 F1-score 值,并将这些值记录下来。F1_curve.png 就是将这些 F1-score 值绘制成的折线图,横轴表示训练轮次,纵轴表示 F1-score 值。通过观察 F1_curve.png,可以了解模型在训练过程中 F1-score 值的变化情况,以及模型的训练效果。
因此,F1_curve.png 是用于可视化 YOLOv7 模型在训练过程中 F1-score 值随着训练轮次的变化情况的一张图像,可以帮助我们了解模型的训练效果,并为模型的优化提供指导。

四、 hyp.yaml和opt.yaml
hyp.yaml文件包含了训练超参数的设置,包括学习率、动量、权重衰减系数、数据增强等参数。这些超参数的设置直接影响着模型的训练效果,通过对hyp.yaml文件进行调整,可以优化模型的性能。
opt.yaml文件则包含了训练选项的设置,如训练数据路径、测试数据路径、模型保存路径、训练轮次、批次大小等。这些设置会影响训练的整个流程,通过对opt.yaml文件进行调整,可以更好地控制训练过程。
在训练过程中,YOLOv7会读取hyp.yaml和opt.yaml文件中的设置,并根据这些设置进行训练。在训练完成后,这些文件也可以被用于模型的测试和部署。
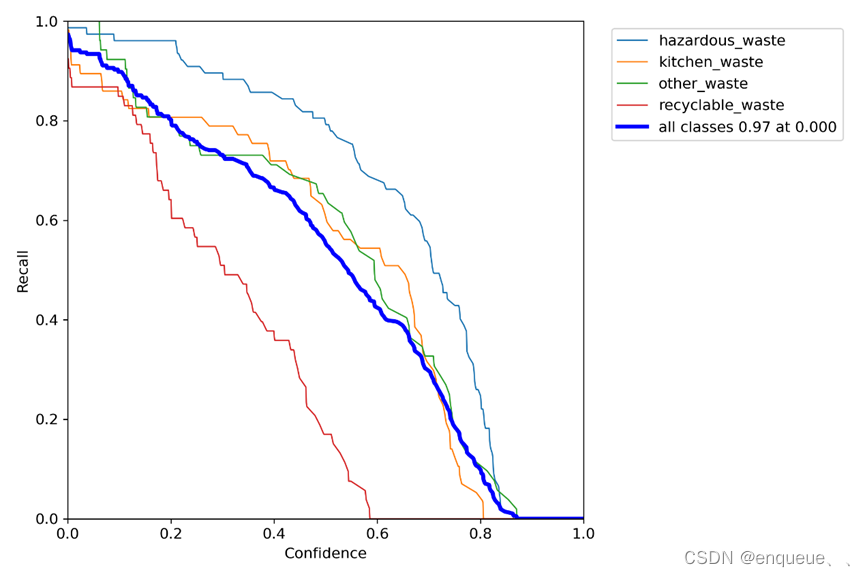
五、 P_curve.png
P_curve.png是YOLOv7模型在训练过程中生成的一张图像,用于可视化模型的精度随着置信度的变化情况。
在目标检测中,置信度是指检测器对于每个检测框预测目标存在的概率。在YOLOv7的训练过程中,每个检测框的置信度都会被计算出来。P_curve.png将检测框的置信度从小到大排序,然后计算出不同置信度下的精度(Precision)值,最后将这些值绘制成一条曲线。
通过观察P_curve.png,我们可以了解到不同置信度下模型的精度表现,以及在何种置信度下模型的精度达到最高。这可以帮助我们优化模型的置信度阈值,以达到更好的检测效果。
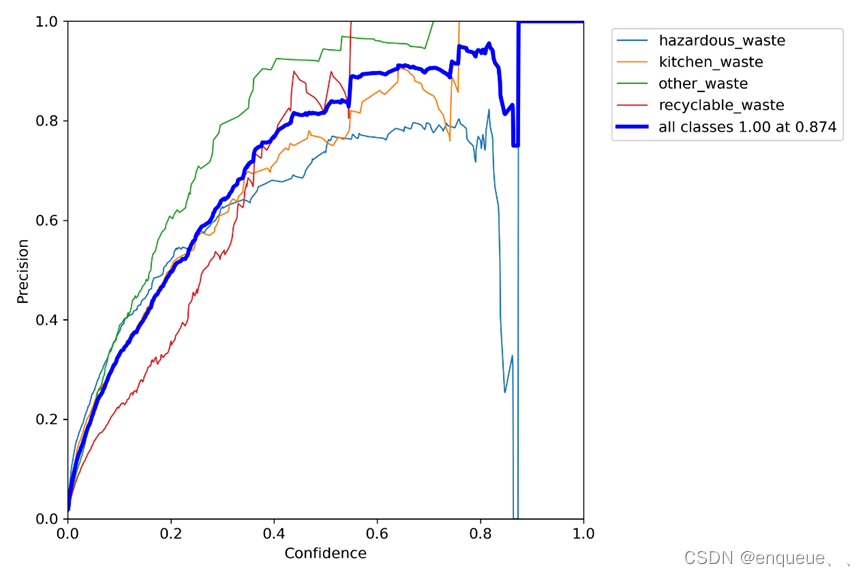
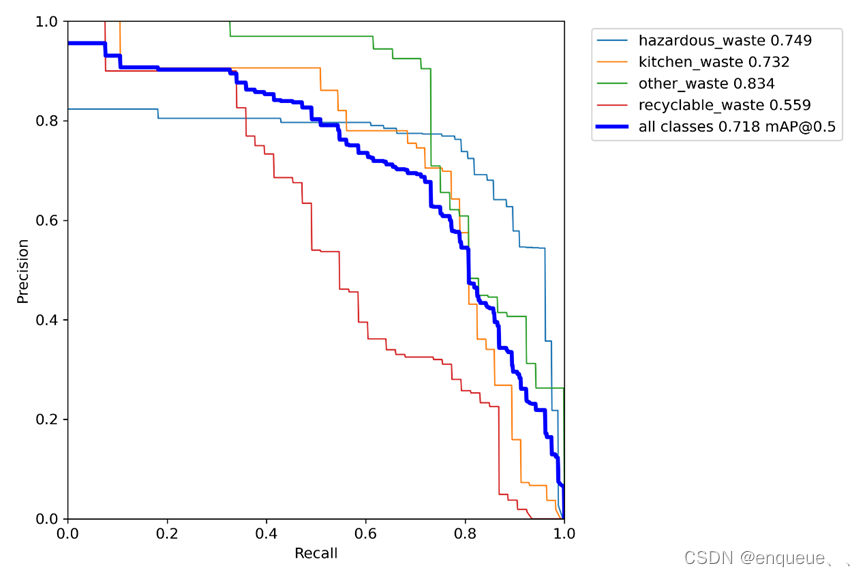
六、 PR_curve.png
PR_curve.png是YOLOv7模型在训练过程中生成的一张图像,用于可视化模型的精确率(Precision)和召回率(Recall)随着置信度的变化情况。
在目标检测中,精确率指的是模型正确检测出目标的检测框数与所有检测框数的比值,而召回率指的是模型正确检测出目标的检测框数与所有目标的数量的比值。在YOLOv7的训练过程中,每个检测框的置信度都会被计算出来。PR_curve.png将检测框的置信度从小到大排序,然后计算出不同置信度下的精确率和召回率值,最后将这些值绘制成一条曲线。
通过观察PR_curve.png,我们可以了解到不同置信度下模型的精确率和召回率表现,以及在何种置信度下模型的精度达到最高。这可以帮助我们优化模型的置信度阈值,以达到更好的检测效果。
七、 R_curve.png
R_ curve.png是YOLOv7模型在训练过程中生成的一张图像,用于可视化模型的召回率(Recall)随着置信度的变化情况。
在目标检测中,召回率指的是模型正确检测出目标的检测框数与所有目标的数量的比值。在YOLOv7的训练过程中,每个检测框的置信度都会被计算出来。R_curve.png将检测框的置信度从小到大排序,然后计算出不同置信度下的召回率值,最后将这些值绘制成一条曲线。
通过观察R_curve.png,我们可以了解到不同置信度下模型的召回率表现,以及在何种置信度下模型的召回率达到最高。这可以帮助我们优化模型的置信度阈值,以达到更好的检测效果。
八、 results.png
results.png是YOLOv7模型在测试集上的检测结果可视化图像。
在目标检测任务中,我们需要对测试集中的图像进行目标检测,并将检测结果输出。results.png就是将模型在测试集上的检测结果进行可视化后得到的图像。对于每张测试图像,results.png会显示原始图像以及检测结果,包括检测出的目标框和目标类别。
通过观察results.png,我们可以直观地了解模型在测试集上的检测效果,以及模型对于不同类别的目标的检测表现。这可以帮助我们评估模型的检测能力,并为模型的优化提供指导。
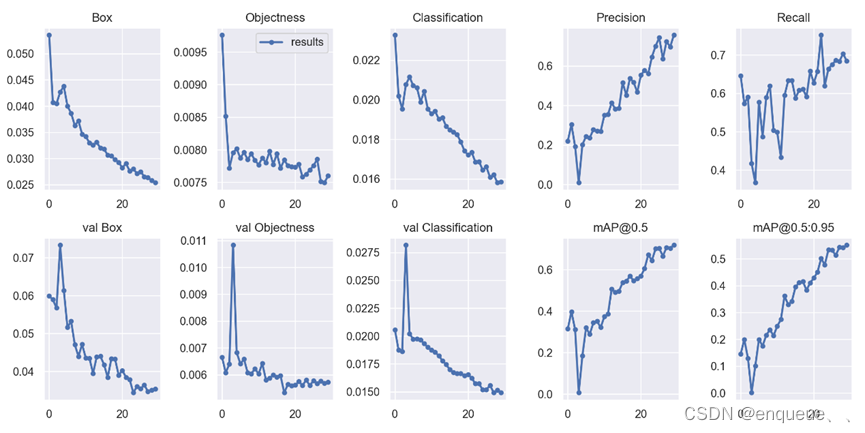
Box:Box推测为GIoU损失函数均值,越小方框越准;
Objectness:推测为目标检测loss均值,越小目标检测越准;
Classification:推测为分类loss均值,越小分类越准,本实验为一类所以为0;
Precision:精度(找对的正类/所有找到的正类);
Recall:真实为positive的准确率,即正样本有多少被找出来了(召回了多少)。
Recall从真实结果角度出发,描述了测试集中的真实正例有多少被二分类器挑选了出来,即真实的正例有多少被该二分类器召回。
-val BOX: 验证集bounding box损失
-val Objectness:验证集目标检测loss均值
-val classification:验证集分类loss均值,本实验为一类所以为0
-mAP是用Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值,@0.5:0.95表示阈值取0.5:0.05:0.95后取均值。
[email protected]:.95(mAP@[.5:.95])
表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
[email protected]:表示阈值大于0.5的平均mAP
参考了这篇文章
九、 results.txt
re sults.txt是YOLOv7模型在测试集上的检测结果文本文件。
在目标检测任务中,我们需要对测试集中的图像进行目标检测,并将检测结果输出。results.txt就是将模型在测试集上的检测结果保存在文本文件中得到的文件。对于每张测试图像,results.txt会记录检测出的目标框的位置坐标、目标类别、以及置信度分数等信息。
通过分析results.txt,我们可以了解模型在测试集上的检测效果,包括检测出的目标数量、目标类别、目标位置等信息。这可以帮助我们评估模型的检测能力,并为模型的优化提供指导。
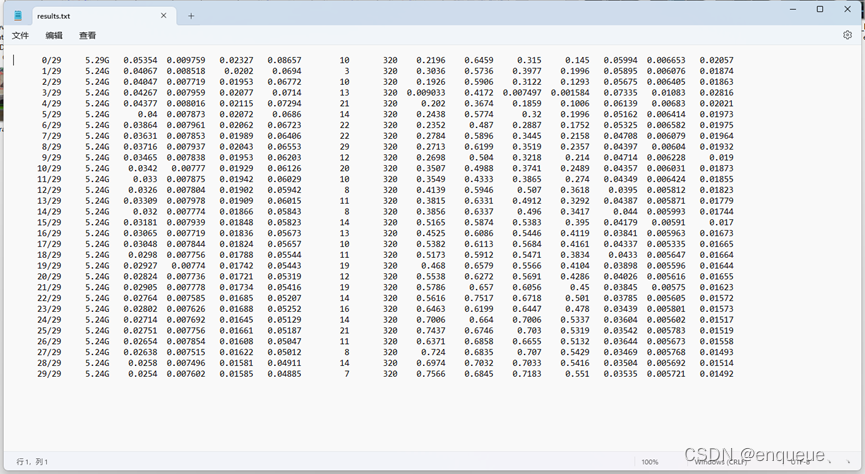
每一行含义分别是:训练次数、GPU消耗、训练集边界框损失、训练集目标检测损失、训练集分类损失、训练集总损失、targets目标、输入图片大小、Precision、Recall、[email protected]、[email protected]:.95、验证集边界框损失、验证集目标检测损失、验证机分类损失。
十、 test_batchx
在YOLOv7的训练过程中,test_batchx是用于测试模型性能的文件夹。
在训练过程中,我们通常会将数据集随机分为训练集和测试集,用训练集来训练模型,用测试集来评估模型的性能。test_batchx文件夹就是用于保存测试集中的图像和标签信息的文件夹,其中x表示测试集的批次编号。
在test_batchx文件夹中,每个图像都有一个对应的标签文件,用于描述图像中目标的位置和类别信息。测试时,我们会将test_batchx文件夹中的图像输入到模型中进行目标检测,然后将检测结果与标签进行比较,计算模型的性能。

十一、 test_batchx_labels
在YOLOv7 目标检测模型中,train.py 脚本会加载用于训练的数据集,并在训练完成后,使用 test.py 脚本对测试集进行预测。对于每个测试样本,test.py 脚本都会生成对应的预测结果,即预测框和类别。
t est_batchx_labels 是指测试集中一个 batch 的真实标签和框的信息,其中 x 为 batch 的编号。这些信息通常包括每个样本的分类标签和相应的边界框坐标(bounding box coordinates)。
具体来说,test_batchx_labels 是一个列表(list)对象,其元素个数等于 batch size。每个元素是一个元组(tuple),长度为 2。第 1 个元素是大小为 N 的 tensor,表示该 batch 中 N 个目标的分类标签;第 2 个元素也是大小为 N 的 tensor,表示该 batch 中 N 个目标的 bounding box 坐标。例如
test_batch0_labels = (tensor([3, 8]), tensor([[348., 181., 429., 299.],
[114., 101., 326., 305.]]))
其中,第 1 个 tensor 表示两个目标的分类标签,分别为 3 和 8,表示属于 dataset.yaml 中第 4 和第 9 个类别(labels)。第 2 个 tensor 则表示两个目标的 bounding box 坐标,由 4 个值组成,分别表示左上角和右下角的横纵坐标。
在测试完成后,test.py 脚本会将 test_batchx_labels 与模型输出的预测结果进行比较,并计算模型的精度。用于评估模型性能。
