## 智能猫狗识别任务,用摄像头识别或者输入图片进行识别,软件界面均通过pyqt完成
**
**代码分析**
1. 数据准备我使用的是kaggle数据集。用来训练的数据集包含600张的彩色图片,2个类别,每个类包含300张。对猫和狗两类进行预测。
2. 网络配置定义了一个较简单的卷积神经网络。显示了其结构:输入的二维图像,先经过三次卷积层、池化层和Batchnorm,再经过全连接层,最后使用softmax分类作为输出层。
3. 模型训练定义运算场所为 fluid.CUDAPlace(0)采用的二分类分类器,学习率为learning_rate=0.001把猫和狗的图片分别放在两个文件夹中,再分别读取,将其保存为list格式,并保存一个json文件# 说明的json文件的class_detail数据
class_detail_list['class_name'] = class_dir
class_detail_list['class_label'] = class_label
class_detail_list['class_test_images'] = test_sum
class_detail_list['class_trainer_images'] = trainer_sum
class_detail.append(class_detail_list)
class_label += 1
每一个Pass训练结束之后,再使用验证集进行验证,并打印出相应的损失值cost和准确率acc。
4. 模型测试在测试之前,要对图像进行预处理。首先将图片大小调整为32*32,接着将图像转换成一维向量,最后再对一维向量进行归一化处理。通过fluid.io.load_inference_model,预测器会从params_dirname中读取已经训练好的模型,来对从未遇见过的数据进行预测。
**运行过程截图主界面**
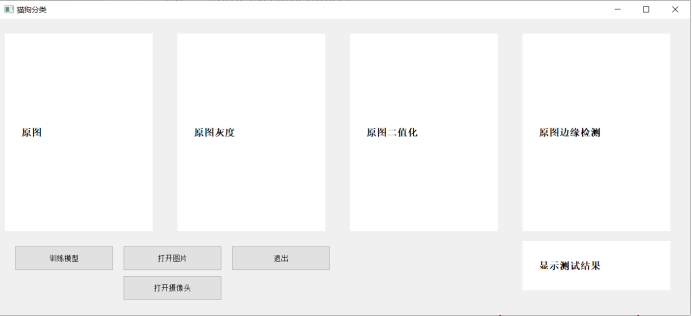
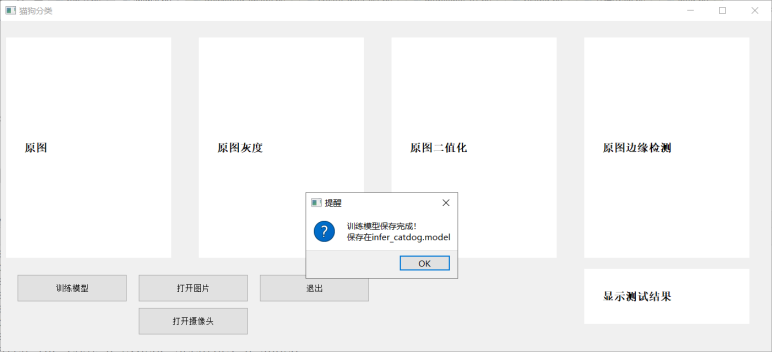
**训练模型**

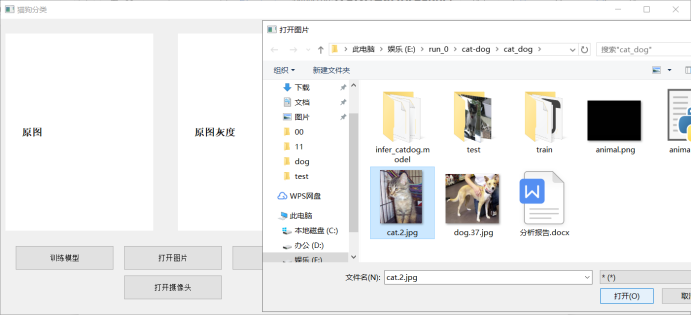
**打开图片**

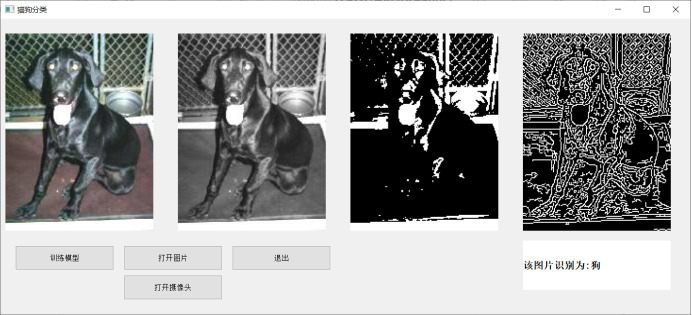
**打开摄像头**
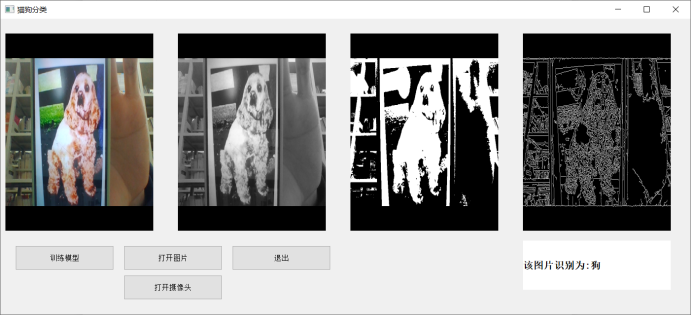
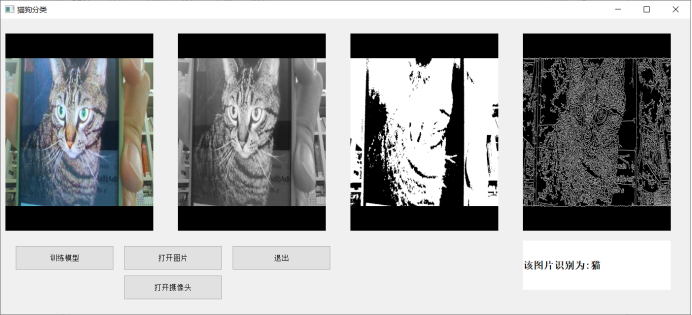
**源代码:**
model_save_dir="infer_catdog.model"
btn_3 = QPushButton(self)
btn_3.setText("退出")
btn_3.move(470, 460)
btn_3.setFixedSize(200, 50)
btn_3.clicked.connect(QCoreApplication.quit)
def readdata(self):
self.xunlian()
def xunlian(self):
def create_data_list(data_root_path):
with open(data_root_path + "test.list", 'w') as f:
pass
with open(data_root_path + "train.list", 'w') as f:
pass
# 所有类别的信息
class_detail = []
# 获取所有类别
class_dirs = os.listdir(data_root_path)
# 类别标签
class_label = 0
# 获取总类别的名称
father_paths = data_root_path.split('/')
while True:
if father_paths[len(father_paths) - 1] == '':
del father_paths[len(father_paths) - 1]
else:
break
father_path = father_paths[len(father_paths) - 1]
data_root_path = "train\\"
def shibie(self,fname):
global model_save_dir
# 创建执行器
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
def readshexiangtou(self):
global fname
global num
if os.path.exists('infer_catdog.model'):
capture = cv2.VideoCapture(0)
while True:
ret, frame = capture.read()
frame = cv2.flip(frame, 1)
# cv2.imshow("video", frame)
cv2.imwrite("animal.png", frame) # 保存图片
fname = "animal.png"
num = self.shibie(fname)
self.yuantu(fname)
self.huidu(fname)
self.erzhihua(fname)
self.bianyuan(fname)
self.jieguo(num)
c = cv2.waitKey(300)
# 如果在这个时间段内, 用户按下ESC(ASCII码为27),则跳出循环,否则,则继续循环
if c == 27:
cv2.destroyAllWindows() # 销毁所有窗口
break
def yuantu(self,fname):
image = cv2.imread(fname)
size = (int(self.label1.width()), int(self.label1.height()))
shrink = cv2.resize(image, size, interpolation=cv2.INTER_AREA)
shrink = cv2.cvtColor(shrink, cv2.COLOR_BGR2RGB)
self.QtImg = QtGui.QImage(shrink.data,
shrink.shape[1],
shrink.shape[0],
QtGui.QImage.Format_RGB888)
self.label1.setPixmap(QtGui.QPixmap.fromImage(self.QtImg))
def erzhihua(self,fname):
image = cv2.imread(fname)
if image is None:
print("未选择图片")
else:
image=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
ret,binary=cv2.threshold(image,0,255,cv2.THRESH_OTSU|cv2.THRESH_BINARY)
print("二值化的阈值为:",ret)
size = (int(self.label3.width()), int(self.label3.height()))
shrink = cv2.resize(binary, size, interpolation=cv2.INTER_AREA)
shrink = cv2.cvtColor(shrink, cv2.COLOR_BGR2RGB)
self.QtImg = QtGui.QImage(shrink.data,
shrink.shape[1],
shrink.shape[0],
QtGui.QImage.Format_RGB888)
self.label3.setPixmap(QtGui.QPixmap.fromImage(self.QtImg))
def jieguo(self,num):
if num!=None:
self.lable5.setText('该图片识别为:{}'.format(num))
else:
self.lable5.setText(' 未进行图片识别')
import cv2
import numpy as np
import paddle as paddle
import paddle.fluid as fluid
from PIL import Image
import matplotlib.pyplot as plt
import os
import json
import random
import shutil
from multiprocessing import cpu_count
import sys
from PyQt5 import QtWidgets, QtCore, QtGui
from PyQt5.QtGui import *
from PyQt5.QtWidgets import *
from PyQt5.QtCore import *
import numpy as np
import paddle as paddle
import paddle.fluid as fluid
from PIL import Image
import matplotlib.pyplot as plt
import os
import json
import random
import shutil
from multiprocessing import cpu_count
import sys
from PyQt5 import QtWidgets, QtCore, QtGui
from PyQt5.QtGui import *
from PyQt5.QtWidgets import *
from PyQt5.QtCore import *
model_save_dir="infer_catdog.model"
class animal(QWidget):
def __init__(self):
super(animal, self).__init__()
def __init__(self):
super(animal, self).__init__()
self.resize(1400,600)
self.center() #使窗口居中
self.setWindowTitle("猫狗分类")
self.setWindowIcon(QIcon('1.jpg'))
self.center() #使窗口居中
self.setWindowTitle("猫狗分类")
self.setWindowIcon(QIcon('1.jpg'))
self.label1 = QLabel(self)
self.label1.setText(" 原图")
self.label1.setFixedSize(300, 400)
self.label1.move(10, 30)
self.label1.setStyleSheet("QLabel{background:white;}"
"QLabel{color:rgb(300,300,300,120);font-size:20px;font-weight:bold;font-family:宋体;}"
)
self.label1.setText(" 原图")
self.label1.setFixedSize(300, 400)
self.label1.move(10, 30)
self.label1.setStyleSheet("QLabel{background:white;}"
"QLabel{color:rgb(300,300,300,120);font-size:20px;font-weight:bold;font-family:宋体;}"
)
self.label2 = QLabel(self)
self.label2.setText(" 原图灰度")
self.label2.setFixedSize(300, 400)
self.label2.move(360, 30)
self.label2.setStyleSheet("QLabel{background:white;}"
"QLabel{color:rgb(300,300,300,120);font-size:20px;font-weight:bold;font-family:宋体;}"
)
self.label2.setText(" 原图灰度")
self.label2.setFixedSize(300, 400)
self.label2.move(360, 30)
self.label2.setStyleSheet("QLabel{background:white;}"
"QLabel{color:rgb(300,300,300,120);font-size:20px;font-weight:bold;font-family:宋体;}"
)
self.label3 = QLabel(self)
self.label3.setText(" 原图二值化")
self.label3.setFixedSize(300, 400)
self.label3.move(710, 30)
self.label3.setStyleSheet("QLabel{background:white;}"
"QLabel{color:rgb(300,300,300,120);font-size:20px;font-weight:bold;font-family:宋体;}"
)
self.label3.setText(" 原图二值化")
self.label3.setFixedSize(300, 400)
self.label3.move(710, 30)
self.label3.setStyleSheet("QLabel{background:white;}"
"QLabel{color:rgb(300,300,300,120);font-size:20px;font-weight:bold;font-family:宋体;}"
)
self.label4 = QLabel(self)
self.label4.setText(" 原图边缘检测")
self.label4.setFixedSize(300, 400)
self.label4.move(1060, 30)
self.label4.setStyleSheet("QLabel{background:white;}"
"QLabel{color:rgb(300,300,300,120);font-size:20px;font-weight:bold;font-family:宋体;}"
)
self.label4.setText(" 原图边缘检测")
self.label4.setFixedSize(300, 400)
self.label4.move(1060, 30)
self.label4.setStyleSheet("QLabel{background:white;}"
"QLabel{color:rgb(300,300,300,120);font-size:20px;font-weight:bold;font-family:宋体;}"
)
self.lable5 = QLabel(self)
self.lable5.setText(" 显示测试结果")
self.lable5.setFixedSize(300, 100)
self.lable5.move(1060, 450)
self.lable5.setStyleSheet("QLabel{background:white;}"
"QLabel{color:rgb(300,300,300,120);font-size:20px;font-weight:bold;font-family:宋体;}"
)
self.lable5.setText(" 显示测试结果")
self.lable5.setFixedSize(300, 100)
self.lable5.move(1060, 450)
self.lable5.setStyleSheet("QLabel{background:white;}"
"QLabel{color:rgb(300,300,300,120);font-size:20px;font-weight:bold;font-family:宋体;}"
)
btn_1 = QPushButton(self)
btn_1.setText("训练模型")
btn_1.move(30, 460)
btn_1.setFixedSize(200,50)
btn_1.clicked.connect(self.readdata)
btn_1.setText("训练模型")
btn_1.move(30, 460)
btn_1.setFixedSize(200,50)
btn_1.clicked.connect(self.readdata)
btn_2 = QPushButton(self)
btn_2.setText("打开图片")
btn_2.move(250, 460)
btn_2.setFixedSize(200, 50)
btn_2.clicked.connect(self.readphoto)
btn_2.setText("打开图片")
btn_2.move(250, 460)
btn_2.setFixedSize(200, 50)
btn_2.clicked.connect(self.readphoto)
btn_4 = QPushButton(self)
btn_4.setText("打开摄像头")
btn_4.move(250, 520)
btn_4.setFixedSize(200, 50)
btn_4.clicked.connect(self.readshexiangtou)
btn_4.setText("打开摄像头")
btn_4.move(250, 520)
btn_4.setFixedSize(200, 50)
btn_4.clicked.connect(self.readshexiangtou)
btn_3 = QPushButton(self)
btn_3.setText("退出")
btn_3.move(470, 460)
btn_3.setFixedSize(200, 50)
btn_3.clicked.connect(QCoreApplication.quit)
def readdata(self):
self.xunlian()
def xunlian(self):
def create_data_list(data_root_path):
with open(data_root_path + "test.list", 'w') as f:
pass
with open(data_root_path + "train.list", 'w') as f:
pass
# 所有类别的信息
class_detail = []
# 获取所有类别
class_dirs = os.listdir(data_root_path)
# 类别标签
class_label = 0
# 获取总类别的名称
father_paths = data_root_path.split('/')
while True:
if father_paths[len(father_paths) - 1] == '':
del father_paths[len(father_paths) - 1]
else:
break
father_path = father_paths[len(father_paths) - 1]
all_class_images = 0
other_file = 0
for class_dir in class_dirs:
if class_dir == 'test.list' or class_dir == "train.list" or class_dir == 'readme.json':
other_file += 1
continue
class_detail_list = {}
test_sum = 0
trainer_sum = 0
# 统计每个类别有多少张图片
class_sum = 0
# 获取类别路径
path = data_root_path + class_dir
# 获取所有图片
img_paths = os.listdir(path)
for img_path in img_paths:
# 每张图片的路径
name_path = class_dir + img_path
# 如果不存在这个文件夹,就创建
if not os.path.exists(data_root_path):
os.makedirs(data_root_path)
# 每10张图片取一个做测试数据
if class_sum % 10 == 0:
test_sum += 1
with open(data_root_path + "test.list", 'a') as f:
f.write(name_path + "\t%d" % class_label + "\n")
else:
trainer_sum += 1
with open(data_root_path + "train.list", 'a') as f:
f.write(name_path + "\t%d" % class_label + "\n")
class_sum += 1
all_class_images += 1
# 说明的json文件的class_detail数据
class_detail_list['class_name'] = class_dir
class_detail_list['class_label'] = class_label
class_detail_list['class_test_images'] = test_sum
class_detail_list['class_trainer_images'] = trainer_sum
class_detail.append(class_detail_list)
class_label += 1
# 获取类别数量
all_class_sum = len(class_dirs) - other_file
# 说明的json文件信息
readjson = {}
readjson['all_class_name'] = father_path
readjson['all_class_sum'] = all_class_sum
readjson['all_class_images'] = all_class_images
readjson['class_detail'] = class_detail
jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))
with open(data_root_path + "readme.json", 'w') as f:
f.write(jsons)
print('图像列表已生成')
other_file = 0
for class_dir in class_dirs:
if class_dir == 'test.list' or class_dir == "train.list" or class_dir == 'readme.json':
other_file += 1
continue
class_detail_list = {}
test_sum = 0
trainer_sum = 0
# 统计每个类别有多少张图片
class_sum = 0
# 获取类别路径
path = data_root_path + class_dir
# 获取所有图片
img_paths = os.listdir(path)
for img_path in img_paths:
# 每张图片的路径
name_path = class_dir + img_path
# 如果不存在这个文件夹,就创建
if not os.path.exists(data_root_path):
os.makedirs(data_root_path)
# 每10张图片取一个做测试数据
if class_sum % 10 == 0:
test_sum += 1
with open(data_root_path + "test.list", 'a') as f:
f.write(name_path + "\t%d" % class_label + "\n")
else:
trainer_sum += 1
with open(data_root_path + "train.list", 'a') as f:
f.write(name_path + "\t%d" % class_label + "\n")
class_sum += 1
all_class_images += 1
# 说明的json文件的class_detail数据
class_detail_list['class_name'] = class_dir
class_detail_list['class_label'] = class_label
class_detail_list['class_test_images'] = test_sum
class_detail_list['class_trainer_images'] = trainer_sum
class_detail.append(class_detail_list)
class_label += 1
# 获取类别数量
all_class_sum = len(class_dirs) - other_file
# 说明的json文件信息
readjson = {}
readjson['all_class_name'] = father_path
readjson['all_class_sum'] = all_class_sum
readjson['all_class_images'] = all_class_images
readjson['class_detail'] = class_detail
jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))
with open(data_root_path + "readme.json", 'w') as f:
f.write(jsons)
print('图像列表已生成')
def net(input, class_dim, scale=1.0):
# conv1: 112x112
input = conv_bn_layer(input=input,
filter_size=3,
channels=3,
num_filters=int(32 * scale),
stride=2,
padding=1)
# conv1: 112x112
input = conv_bn_layer(input=input,
filter_size=3,
channels=3,
num_filters=int(32 * scale),
stride=2,
padding=1)
input = depthwise_separable(input=input,
num_filters1=32,
num_filters2=64,
num_groups=32,
stride=1,
scale=scale)
num_filters1=32,
num_filters2=64,
num_groups=32,
stride=1,
scale=scale)
input = depthwise_separable(input=input,
num_filters1=64,
num_filters2=128,
num_groups=64,
stride=2,
scale=scale)
num_filters1=64,
num_filters2=128,
num_groups=64,
stride=2,
scale=scale)
input = depthwise_separable(input=input,
num_filters1=256,
num_filters2=256,
num_groups=256,
stride=1,
scale=scale)
num_filters1=256,
num_filters2=256,
num_groups=256,
stride=1,
scale=scale)
input = depthwise_separable(input=input,
num_filters1=256,
num_filters2=512,
num_groups=256,
stride=2,
scale=scale)
num_filters1=256,
num_filters2=512,
num_groups=256,
stride=2,
scale=scale)
feature = fluid.layers.pool2d(input=input,
pool_size=0,
pool_stride=1,
pool_type='avg',
global_pooling=True)
pool_size=0,
pool_stride=1,
pool_type='avg',
global_pooling=True)
net = fluid.layers.fc(input=feature,
size=class_dim,
act='softmax')
return net
size=class_dim,
act='softmax')
return net
def conv_bn_layer(input, filter_size, num_filters, stride,
padding, channels=None, num_groups=1, act='relu', use_cudnn=True): # 9个参数
conv = fluid.layers.conv2d(input=input,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=padding,
groups=num_groups,
act=None,
use_cudnn=use_cudnn,
bias_attr=False)
padding, channels=None, num_groups=1, act='relu', use_cudnn=True): # 9个参数
conv = fluid.layers.conv2d(input=input,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=padding,
groups=num_groups,
act=None,
use_cudnn=use_cudnn,
bias_attr=False)
return fluid.layers.batch_norm(input=conv, act=act)
def depthwise_separable(input, num_filters1, num_filters2, num_groups, stride, scale): # 6个参数
depthwise_conv = conv_bn_layer(input=input,
filter_size=3,
num_filters=int(num_filters1 * scale),
stride=stride,
padding=1,
num_groups=int(num_groups * scale),
use_cudnn=False)
depthwise_conv = conv_bn_layer(input=input,
filter_size=3,
num_filters=int(num_filters1 * scale),
stride=stride,
padding=1,
num_groups=int(num_groups * scale),
use_cudnn=False)
pointwise_conv = conv_bn_layer(input=depthwise_conv,
filter_size=1,
num_filters=int(num_filters2 * scale),
stride=1,
padding=0)
return pointwise_conv
filter_size=1,
num_filters=int(num_filters2 * scale),
stride=1,
padding=0)
return pointwise_conv
# 训练图片的预处理
def train_mapper():
img_path, label, crop_size, resize_size = sample
try:
img = Image.open(img_path)
# 统一图片大小
img = img.resize((resize_size, resize_size), Image.ANTIALIAS)
# 随机水平翻转
r1 = random.random()
if r1 > 0.5:
img = img.transpose(Image.FLIP_LEFT_RIGHT)
# 随机垂直翻转
r2 = random.random()
if r2 > 0.5:
img = img.transpose(Image.FLIP_TOP_BOTTOM)
# 随机角度翻转
r3 = random.randint(-3, 3)
img = img.rotate(r3, expand=False)
# 随机裁剪
r4 = random.randint(0, int(resize_size - crop_size))
r5 = random.randint(0, int(resize_size - crop_size))
box = (r4, r5, r4 + crop_size, r5 + crop_size)
img = img.crop(box)
# 把图片转换成numpy值
img = np.array(img).astype(np.float32)
# 转换成CHW
img = img.transpose((2, 0, 1))
# 转换成BGR
img = img[(2, 1, 0), :, :] / 255.0
return img, int(label)
except:
print("%s 该图片错误,请删除该图片并重新创建图像数据列表" % img_path)
def train_mapper():
img_path, label, crop_size, resize_size = sample
try:
img = Image.open(img_path)
# 统一图片大小
img = img.resize((resize_size, resize_size), Image.ANTIALIAS)
# 随机水平翻转
r1 = random.random()
if r1 > 0.5:
img = img.transpose(Image.FLIP_LEFT_RIGHT)
# 随机垂直翻转
r2 = random.random()
if r2 > 0.5:
img = img.transpose(Image.FLIP_TOP_BOTTOM)
# 随机角度翻转
r3 = random.randint(-3, 3)
img = img.rotate(r3, expand=False)
# 随机裁剪
r4 = random.randint(0, int(resize_size - crop_size))
r5 = random.randint(0, int(resize_size - crop_size))
box = (r4, r5, r4 + crop_size, r5 + crop_size)
img = img.crop(box)
# 把图片转换成numpy值
img = np.array(img).astype(np.float32)
# 转换成CHW
img = img.transpose((2, 0, 1))
# 转换成BGR
img = img[(2, 1, 0), :, :] / 255.0
return img, int(label)
except:
print("%s 该图片错误,请删除该图片并重新创建图像数据列表" % img_path)
# 获取训练的reader
def train_reader(train_list_path, crop_size, resize_size):
father_path = os.path.dirname(train_list_path)
def train_reader(train_list_path, crop_size, resize_size):
father_path = os.path.dirname(train_list_path)
def reader():
with open(train_list_path, 'r') as f:
lines = f.readlines()
# 打乱图像列表
np.random.shuffle(lines)
# 开始获取每张图像和标签
for line in lines:
img, label = line.split('\t')
img = os.path.join(father_path, img)
yield img, label, crop_size, resize_size
with open(train_list_path, 'r') as f:
lines = f.readlines()
# 打乱图像列表
np.random.shuffle(lines)
# 开始获取每张图像和标签
for line in lines:
img, label = line.split('\t')
img = os.path.join(father_path, img)
yield img, label, crop_size, resize_size
return paddle.reader.xmap_readers(train_mapper, reader, cpu_count(), 102400)
# 测试图片的预处理
def test_mapper(sample):
img, label, crop_size = sample
img = Image.open(img)
# 统一图像大小
img = img.resize((crop_size, crop_size), Image.ANTIALIAS)
# 转换成numpy值
img = np.array(img).astype(np.float32)
# 转换成CHW
img = img.transpose((2, 0, 1))
# 转换成BGR
img = img[(2, 1, 0), :, :] / 255.0
return img, int(label)
def test_mapper(sample):
img, label, crop_size = sample
img = Image.open(img)
# 统一图像大小
img = img.resize((crop_size, crop_size), Image.ANTIALIAS)
# 转换成numpy值
img = np.array(img).astype(np.float32)
# 转换成CHW
img = img.transpose((2, 0, 1))
# 转换成BGR
img = img[(2, 1, 0), :, :] / 255.0
return img, int(label)
# 测试的图片reader
def test_reader(test_list_path, crop_size):
father_path = os.path.dirname(test_list_path)
def test_reader(test_list_path, crop_size):
father_path = os.path.dirname(test_list_path)
def reader():
with open(test_list_path, 'r') as f:
lines = f.readlines()
for line in lines:
img, label = line.split('\t')
img = os.path.join(father_path, img)
yield img, label, crop_size
with open(test_list_path, 'r') as f:
lines = f.readlines()
for line in lines:
img, label = line.split('\t')
img = os.path.join(father_path, img)
yield img, label, crop_size
return paddle.reader.xmap_readers(test_mapper, reader, cpu_count(), 1024)
data_root_path = "train\\"
crop_size = 100
resize_size = 100
resize_size = 100
# 定义输入层
image = fluid.layers.data(name='image', shape=[3, crop_size, crop_size], dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='float64')
image = fluid.layers.data(name='image', shape=[3, crop_size, crop_size], dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='float64')
# 获取分类器,因为这次只爬取了6个类别的图片,所以分类器的类别大小为6
model = net(image, 2)
model = net(image, 2)
# 获取损失函数和准确率函数
cost = fluid.layers.cross_entropy(input=model, label=label)
avg_cost = fluid.layers.mean(cost)
acc = fluid.layers.accuracy(input=model, label=label)
cost = fluid.layers.cross_entropy(input=model, label=label)
avg_cost = fluid.layers.mean(cost)
acc = fluid.layers.accuracy(input=model, label=label)
# 获取训练和测试程序
test_program = fluid.default_main_program().clone(for_test=True)
test_program = fluid.default_main_program().clone(for_test=True)
# 定义优化方法
optimizer = fluid.optimizer.Adam(learning_rate=0.001)
# optimizer = fluid.optimizer.AdamOptimizer(learning_rate=1e-3,
# regularization=fluid.regularizer.L2DecayRegularizer(1e-4))
opts = optimizer.minimize(avg_cost)
optimizer = fluid.optimizer.Adam(learning_rate=0.001)
# optimizer = fluid.optimizer.AdamOptimizer(learning_rate=1e-3,
# regularization=fluid.regularizer.L2DecayRegularizer(1e-4))
opts = optimizer.minimize(avg_cost)
# 获取自定义数据
train_reader = paddle.batch(
reader=train_reader(r'train\train.list', crop_size, resize_size), batch_size=32)
test_reader = paddle.batch(reader=test_reader(r'train\test.list', crop_size),
batch_size=32)
train_reader = paddle.batch(
reader=train_reader(r'train\train.list', crop_size, resize_size), batch_size=32)
test_reader = paddle.batch(reader=test_reader(r'train\test.list', crop_size),
batch_size=32)
# 定义一个使用GPU的执行器
place = fluid.CUDAPlace(0)
# place = fluid.CPUPlace()
exe = fluid.Executor(place)
# 进行参数初始化
exe.run(fluid.default_startup_program())
place = fluid.CUDAPlace(0)
# place = fluid.CPUPlace()
exe = fluid.Executor(place)
# 进行参数初始化
exe.run(fluid.default_startup_program())
# 定义输入数据维度
feeder = fluid.DataFeeder(place=place, feed_list=[image, label])
feeder = fluid.DataFeeder(place=place, feed_list=[image, label])
# 训练100次
for pass_id in range(100):
# 进行训练
for batch_id, data in enumerate(train_reader()):
train_cost, train_acc = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
for pass_id in range(100):
# 进行训练
for batch_id, data in enumerate(train_reader()):
train_cost, train_acc = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
# 每100个batch打印一次信息
if batch_id % 10 == 0:
print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
(pass_id, batch_id, train_cost[0], train_acc[0]))
if batch_id % 10 == 0:
print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
(pass_id, batch_id, train_cost[0], train_acc[0]))
# 进行测试
test_accs = []
test_costs = []
for batch_id, data in enumerate(test_reader()):
test_cost, test_acc = exe.run(program=test_program,
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
test_accs.append(test_acc[0])
test_costs.append(test_cost[0])
# 求测试结果的平均值
test_cost = (sum(test_costs) / len(test_costs))
test_acc = (sum(test_accs) / len(test_accs))
print('Test:%d, Cost:%0.5f, Accuracy:%0.5f' % (pass_id, test_cost, test_acc))
test_accs = []
test_costs = []
for batch_id, data in enumerate(test_reader()):
test_cost, test_acc = exe.run(program=test_program,
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
test_accs.append(test_acc[0])
test_costs.append(test_cost[0])
# 求测试结果的平均值
test_cost = (sum(test_costs) / len(test_costs))
test_acc = (sum(test_accs) / len(test_accs))
print('Test:%d, Cost:%0.5f, Accuracy:%0.5f' % (pass_id, test_cost, test_acc))
# 保存预测模型
save_path = 'infer_catdog.model'
# 删除旧的模型文件
shutil.rmtree(save_path, ignore_errors=True)
# 创建保持模型文件目录
os.makedirs(save_path)
# 保存预测模型
fluid.io.save_inference_model(save_path, feeded_var_names=[image.name], target_vars=[model], executor=exe)
print('训练模型保存完成!\n保存在%s'%(save_path))
QMessageBox.question(self, '提醒', '训练模型保存完成!\n保存在%s'%(save_path),
QMessageBox.Ok)
save_path = 'infer_catdog.model'
# 删除旧的模型文件
shutil.rmtree(save_path, ignore_errors=True)
# 创建保持模型文件目录
os.makedirs(save_path)
# 保存预测模型
fluid.io.save_inference_model(save_path, feeded_var_names=[image.name], target_vars=[model], executor=exe)
print('训练模型保存完成!\n保存在%s'%(save_path))
QMessageBox.question(self, '提醒', '训练模型保存完成!\n保存在%s'%(save_path),
QMessageBox.Ok)
def shibie(self,fname):
global model_save_dir
# 创建执行器
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
# 保存预测模型路径
save_path = 'infer_catdog.model'
# 从模型中获取预测程序、输入数据名称列表、分类器
[infer_program, feeded_var_names, target_var] = fluid.io.load_inference_model(dirname=save_path, executor=exe)
save_path = 'infer_catdog.model'
# 从模型中获取预测程序、输入数据名称列表、分类器
[infer_program, feeded_var_names, target_var] = fluid.io.load_inference_model(dirname=save_path, executor=exe)
# 预处理图片
def load_image(file):
img = Image.open(file)
# 统一图像大小
img = img.resize((224, 224), Image.ANTIALIAS)
# 转换成numpy值
img = np.array(img).astype(np.float32)
# 转换成CHW
img = img.transpose((2, 0, 1))
# 转换成BGR
img = img[(2, 1, 0), :, :] / 255.0
img = np.expand_dims(img, axis=0)
return img
# 获取图片数据
img = load_image(fname)
# 执行预测
result = exe.run(program=infer_program,
feed={feeded_var_names[0]: img},
fetch_list=target_var)
# 显示图片并输出结果最大的label
lab = np.argsort(result)[0][0][-1]
names = ['猫', '狗']
print('预测结果标签为:%d, 名称为:%s, 概率为:%f' % (lab, names[lab], result[0][0][lab]))
return names[lab]
def load_image(file):
img = Image.open(file)
# 统一图像大小
img = img.resize((224, 224), Image.ANTIALIAS)
# 转换成numpy值
img = np.array(img).astype(np.float32)
# 转换成CHW
img = img.transpose((2, 0, 1))
# 转换成BGR
img = img[(2, 1, 0), :, :] / 255.0
img = np.expand_dims(img, axis=0)
return img
# 获取图片数据
img = load_image(fname)
# 执行预测
result = exe.run(program=infer_program,
feed={feeded_var_names[0]: img},
fetch_list=target_var)
# 显示图片并输出结果最大的label
lab = np.argsort(result)[0][0][-1]
names = ['猫', '狗']
print('预测结果标签为:%d, 名称为:%s, 概率为:%f' % (lab, names[lab], result[0][0][lab]))
return names[lab]
def readphoto(self):
global fname
global num
if os.path.exists("infer_catdog.model"):
fname, imgType = QFileDialog.getOpenFileName(self, "打开图片", "", "*;;*.png;;All Files(*)")
if fname:
self.yuantu(fname)
num = self.shibie(fname)
self.huidu(fname)
self.erzhihua(fname)
self.bianyuan(fname)
self.jieguo(num)
else:
QMessageBox.question(self, '提醒', '未选择图片',
QMessageBox.Ok)
else:
QMessageBox.question(self, '提醒', '未得到训练模型',
QMessageBox.Ok)
global fname
global num
if os.path.exists("infer_catdog.model"):
fname, imgType = QFileDialog.getOpenFileName(self, "打开图片", "", "*;;*.png;;All Files(*)")
if fname:
self.yuantu(fname)
num = self.shibie(fname)
self.huidu(fname)
self.erzhihua(fname)
self.bianyuan(fname)
self.jieguo(num)
else:
QMessageBox.question(self, '提醒', '未选择图片',
QMessageBox.Ok)
else:
QMessageBox.question(self, '提醒', '未得到训练模型',
QMessageBox.Ok)
def readshexiangtou(self):
global fname
global num
if os.path.exists('infer_catdog.model'):
capture = cv2.VideoCapture(0)
while True:
ret, frame = capture.read()
frame = cv2.flip(frame, 1)
# cv2.imshow("video", frame)
cv2.imwrite("animal.png", frame) # 保存图片
fname = "animal.png"
num = self.shibie(fname)
self.yuantu(fname)
self.huidu(fname)
self.erzhihua(fname)
self.bianyuan(fname)
self.jieguo(num)
c = cv2.waitKey(300)
# 如果在这个时间段内, 用户按下ESC(ASCII码为27),则跳出循环,否则,则继续循环
if c == 27:
cv2.destroyAllWindows() # 销毁所有窗口
break
cv2.waitKey(0) # 等待用户操作,里面等待参数是毫秒,我们填写0,代表是永远,等待用户操作
cv2.destroyAllWindows() # 销毁所有窗口
else:
QMessageBox.question(self, '提醒', '未得到训练模型',
QMessageBox.Ok)
cv2.destroyAllWindows() # 销毁所有窗口
else:
QMessageBox.question(self, '提醒', '未得到训练模型',
QMessageBox.Ok)
def yuantu(self,fname):
image = cv2.imread(fname)
size = (int(self.label1.width()), int(self.label1.height()))
shrink = cv2.resize(image, size, interpolation=cv2.INTER_AREA)
shrink = cv2.cvtColor(shrink, cv2.COLOR_BGR2RGB)
self.QtImg = QtGui.QImage(shrink.data,
shrink.shape[1],
shrink.shape[0],
QtGui.QImage.Format_RGB888)
self.label1.setPixmap(QtGui.QPixmap.fromImage(self.QtImg))
def erzhihua(self,fname):
image = cv2.imread(fname)
if image is None:
print("未选择图片")
else:
image=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
ret,binary=cv2.threshold(image,0,255,cv2.THRESH_OTSU|cv2.THRESH_BINARY)
print("二值化的阈值为:",ret)
size = (int(self.label3.width()), int(self.label3.height()))
shrink = cv2.resize(binary, size, interpolation=cv2.INTER_AREA)
shrink = cv2.cvtColor(shrink, cv2.COLOR_BGR2RGB)
self.QtImg = QtGui.QImage(shrink.data,
shrink.shape[1],
shrink.shape[0],
QtGui.QImage.Format_RGB888)
self.label3.setPixmap(QtGui.QPixmap.fromImage(self.QtImg))
def huidu(self,fname):
image = cv2.imread(fname)
if image is None:
print("未选择图片")
else:
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
size = (int(self.label2.width()), int(self.label2.height()))
shrink = cv2.resize(image, size, interpolation=cv2.INTER_AREA)
shrink = cv2.cvtColor(shrink, cv2.COLOR_BGR2RGB)
self.QtImg = QtGui.QImage(shrink.data,
shrink.shape[1],
shrink.shape[0],
QtGui.QImage.Format_RGB888)
self.label2.setPixmap(QtGui.QPixmap.fromImage(self.QtImg))
image = cv2.imread(fname)
if image is None:
print("未选择图片")
else:
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
size = (int(self.label2.width()), int(self.label2.height()))
shrink = cv2.resize(image, size, interpolation=cv2.INTER_AREA)
shrink = cv2.cvtColor(shrink, cv2.COLOR_BGR2RGB)
self.QtImg = QtGui.QImage(shrink.data,
shrink.shape[1],
shrink.shape[0],
QtGui.QImage.Format_RGB888)
self.label2.setPixmap(QtGui.QPixmap.fromImage(self.QtImg))
def bianyuan(self,fname):
image = cv2.imread(fname)
if image is None:
print("未选择图片")
else:
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image1=cv2.Canny(image,10,50)
size = (int(self.label4.width()), int(self.label4.height()))
shrink = cv2.resize(image1, size, interpolation=cv2.INTER_AREA)
shrink = cv2.cvtColor(shrink, cv2.COLOR_BGR2RGB)
self.QtImg = QtGui.QImage(shrink.data,
shrink.shape[1],
shrink.shape[0],
QtGui.QImage.Format_RGB888)
self.label4.setPixmap(QtGui.QPixmap.fromImage(self.QtImg))
image = cv2.imread(fname)
if image is None:
print("未选择图片")
else:
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image1=cv2.Canny(image,10,50)
size = (int(self.label4.width()), int(self.label4.height()))
shrink = cv2.resize(image1, size, interpolation=cv2.INTER_AREA)
shrink = cv2.cvtColor(shrink, cv2.COLOR_BGR2RGB)
self.QtImg = QtGui.QImage(shrink.data,
shrink.shape[1],
shrink.shape[0],
QtGui.QImage.Format_RGB888)
self.label4.setPixmap(QtGui.QPixmap.fromImage(self.QtImg))
def jieguo(self,num):
if num!=None:
self.lable5.setText('该图片识别为:{}'.format(num))
else:
self.lable5.setText(' 未进行图片识别')
def center(self): # 控制窗口显示在屏幕中心的方法
# 获得窗口
qr = self.frameGeometry()
# 获得屏幕中心点
cp = QDesktopWidget().availableGeometry().center()
# 显示到屏幕中心
qr.moveCenter(cp)
self.move(qr.topLeft())
qr = self.frameGeometry()
# 获得屏幕中心点
cp = QDesktopWidget().availableGeometry().center()
# 显示到屏幕中心
qr.moveCenter(cp)
self.move(qr.topLeft())
if __name__ == "__main__":
app = QtWidgets.QApplication(sys.argv)
my = animal()
my.show()
sys.exit(app.exec_())
app = QtWidgets.QApplication(sys.argv)
my = animal()
my.show()
sys.exit(app.exec_())