mmdetection实战,训练扑克牌数据集(VOC格式)并测试计算mAP
一、数据集准备
我这次用到的数据集来自这里:扑克牌数据集,下载下整个zip文件再从中复制出来。划重点:但是,我不建议你直接从他那下载,慢不说,后来我遇到了一个问题,就是会出现下面这样的报错:
FileNotFoundError: img file does not exist: /home/ymz/lsm/mmdetection/data/VOCdevkit/VOC2007/JPEGImages/IMG_2608.jpg
后来我发现确实数据集里面有IMG_2608.JPG,唯一的区别就是文件格式大写了,后来证实确实mmcv.imread读不了大写的.JPG,所以我这里把所有文件格式小写之后的数据集链接放这里,提取码:vmsy
这个数据集并没有收集全部的扑克牌类别,里面只有6类:nine,ten,jack,queen,king,ace。一共364张,所以之后训练不会耗时很久,基本20个epoch半个小时就完事了。解压之后的文件目录是这样的:
├── poker
│ ├── VOC2007
│ │ ├── Annotations
│ │ ├── JPEGImages
│ │ ├── ImageSets
│ │ │ ├── Main
│ │ │ │ ├── val.txt
│ │ │ │ ├── train.txt
二、mmdetection的安装
mmdetection是一个基于pytorch的目标检测框架,非常好用,支持模型也比较全,Github上目前star已有8k,而且commit也非常活跃。这次就想熟悉一下怎么使用这个框架,故用了自己找的数据集跑一遍。
安装的话基本照着官网的说明文档就行,不过似乎最近经常会有一些小改动,这个https://mmdetection.readthedocs.io/en/latest/上面也可以看。我在这里放一下全部整合的命令(这个最好及时去官网看更新):
我用的代码版本,因为最新的代码版本更新了一些评价文件
# 注意官方的Requirements
conda create -n open-mmlab python=3.7 -y
conda activate open-mmlab
# 安装pytorch和torchvision自己来也行
conda install -c pytorch pytorch torchvision -y
# cython一定要安装,编译需要
conda install cython -y
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
# 若自己离线安装pytorch和torchvision,可注释requirements.txt对应行
# 还有也可以把pycocotools那行注释了,官方建议通过下面那句安装
pip install -r requirements.txt
pip install "git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI"
pip install -v -e .
# 官方建议创建软连接,节省硬盘空间,在mmdetection目录下运行下面的命令
mkdir data
ln -s $COCO_ROOT data
当然我们这里是自己VOC格式的数据集,最后一个软链接就不能是上面最后一行,根据上面的数据集目录结构应该是:
mkdir data
cd data
ln -s /home/你的存放路径/poker VOCdevkit
这样就符合官方的推荐结构了。
三、修改相关文件
1. 修改class_names.py文件
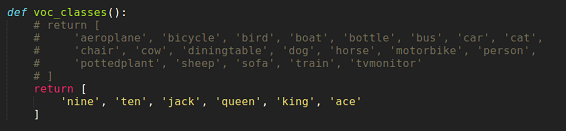
修改mmdetection/mmdet/core/evaluation下的class_names.py中的voc_classes,将其改为要训练的数据集的类别名称,否则测试的结果的名称还会是aeroplane, bicycle, bird, boat,…这些。改完后如图:
2. 修改voc.py文件
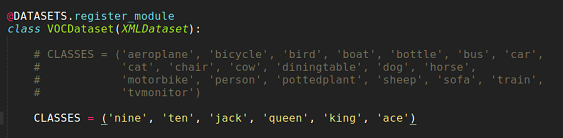
修改mmdetection/mmdet/datasets/voc.py 下的类别,如果只有一个类,因为CLASSES是一个元组,所以要加上一个逗号,否则将会报错,改完后如图:
3. 修改配置文件
配置文件就是mmdetection/configs下一堆的名称诸如cascade_rcnn_r50_fpn_1x.py的文件,因为我们使用的是VOC格式,这些默认是COCO格式(除了mmdetection/configs/pascal_voc文件夹下的几个),所以我就挑了cascade_rcnn_r50_fpn_1x.py,将它复制重命名为cascade_rcnn_r50_fpn_1x_poker.py,有下面几个地方需要修改:
1、修改num_classes变量,就是背景类加上要分类的数量,所以我们这里为7:

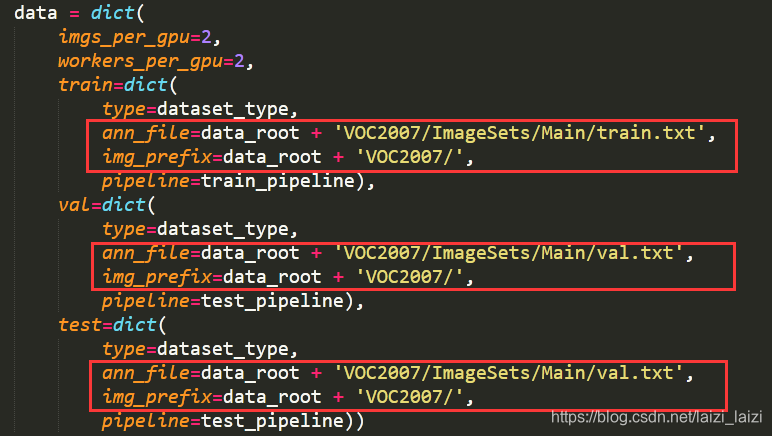
2、修改data settings部分,主要是了dataset_type、data_root、img_scale、ann_file、img_prefix变量的值:
最后的runtime settings也可以修改一下,比如total_epochs和workflow【[(‘train’, 1)]表示只训练,不验证;[(‘train’, 2), (‘val’, 1)] 表示2个epoch训练,1个epoch验证】,我将total_epochs设置成20,所以学习率设置为step=[8, 15],checkpoint_config = dict(interval=2),其他都保持默认。
四、开始训练
到现在就可以开始训练了,在mmdetection目录下:
python tools/train.py configs/cascade_rcnn_r50_fpn_1x_poker.py
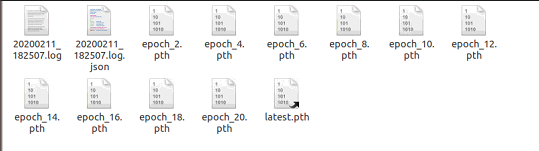
这样就能成功训练了,屏幕上会打印很多log日志,当然训练完成之后会在work_dirs目录下出现如下图的东西:有.log日志和.log.json,还有每隔一定epoch(我这里是每隔2个epoch)保存模型,为了方便后面的测试,还有最后的模型latest.pth。
五、测试并计算mAP
1. 测试一张图片的效果
我模仿demo/webcam_demo.py文件写了试用于一张图片的demo脚本image_demo.py:
import argparse
import torch
from mmdet.apis import inference_detector, init_detector, show_result
def parse_args():
parser = argparse.ArgumentParser(description='MMDetection image demo')
parser.add_argument('config', help='test config file path')
parser.add_argument('checkpoint', help='checkpoint file')
parser.add_argument('imagepath', help='the path of image to test')
parser.add_argument('--device', type=int, default=0, help='CUDA device id')
parser.add_argument(
'--score-thr', type=float, default=0.5, help='bbox score threshold')
args = parser.parse_args()
return args
def main():
args = parse_args()
model = init_detector(
args.config, args.checkpoint, device=torch.device('cuda', args.device))
result = inference_detector(model, args.imagepath)
# 这里的result是一个列表,长度为类别数,例如我这里就是6
# 其中每个元素就是对一类的预测出来的bbox,是一个np.ndarray
# shape为(N,5),N可能大于测试图中实际的该类的数量
# 5是4个坐标值,加1个置信度
show_result(
args.imagepath, result, model.CLASSES, score_thr=args.score_thr, wait_time=0)
if __name__ == '__main__':
main()
然后运行下面的命令:
python demo/image_demo.py configs/cascade_rcnn_r50_fpn_1x_poker.py work_dirs/cascade_rcnn_r50_fpn_1x_poker/latest.pth demo/poker_test.jpg
得到下面的结果,可以看到bbox框得非常tight,分类也都正确了:

2. 计算mAP
计算mAP之前需要修改mmdetection/tools/voc_eval.py文件中的voc_eval函数,改完后的图:
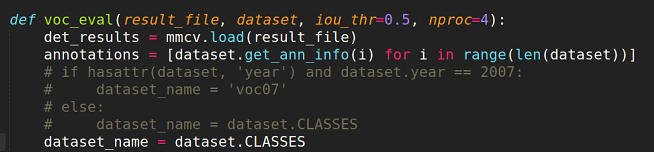
然后通过下面命令产生poker_results.pkl文件:
python tools/test.py configs/cascade_rcnn_r50_fpn_1x_poker.py work_dirs/cascade_rcnn_r50_fpn_1x_poker/latest.pth --out poker_results.pkl
然后执行如下命令,采用voc标准计算mAP:
python tools/voc_eval.py poker_results.pkl configs/cascade_rcnn_r50_fpn_1x_poker.py
便得到了下面的结果,可以看到mAP高达0.977,这当然因为扑克牌方方正正很容易检测的缘故啦:
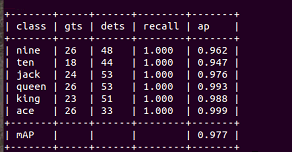
好,算是玩了一下mmdetection吧。以后会常碰到它的~~
温馨提示
2020年3月1日更新
- 这里提示一下,在work_dirs/…/latest.pth的latest.pth不是一个真正的.pth模型文件,而是一个symlink(符号链接),它指向epoch_20.pth(假设你的最大epoch是20),所以你想删除多余的生成的模型文件时,一定要保留一个最后的epoch_20.pth(除了latest.pth之外),否则你就可能看到这样的错误:
OSError: work_dirs/.../latest.pth is not a checkpoint file - 由于mmdetection经常更新,修复bug什么的,所以他的说明文档也会经常更新,例如tools下已经没有voc_eval.py,换成了统一的robustness_eval.py#2074,当然如果想复现我这个结果,可到之前的release下载使用tools/voc_eval.py