文章目录
YOLOR出自论文You Only Learn One Representation: Unified Network for Multiple Tasks,受人类学习方式(使用五官,通过常规和潜意识学习,总结丰富的经验并编码存储,进而处理已知或未知的信息)的启发,论文提出了一个统一的网络来同时编码显式知识和隐式知识,在网络中执行了kernel space alignment(核空间对齐)、prediction refinement(预测细化)和 multi-task learning(多任务学习),同时对多个任务形成统一的表示。结果表明神经网络中引入隐式知识有助于所有任务的性能提升,进一步的分析发现隐式表示之所以能带来性能提升,是因为其具备了捕获不同任务的物理意义的能力。
1、论文介绍
paper: https://arxiv.org/abs/2105.04206
code: https://github.com/WongKinYiu/yolor
1.1、YOLOR思想动机

如图1所示,人可以从多个角度来分析同一个目标,然而通常训练CNN时只给予了一个角度,也就是说针对某一个任务得到的CNN特征很难适用于其他问题。作者认为造成上述问题的原因主要是模型只提取了神经元特征而丢弃了隐式知识的学习运用,然而就像人脑一样隐式知识对分析各种各样的任务是非常有用的。
人类对隐式知识的学习通常通过潜意识,然而并没有系统的定义怎样学习和获得隐式知识。对于神经网络而言,一般将浅层特征定义为显式知识,深层特征定义为隐式知识。本文将直接可观察的知识定义为显式知识,隐藏在神经网络中且无法观察的知识定义为隐式知识。
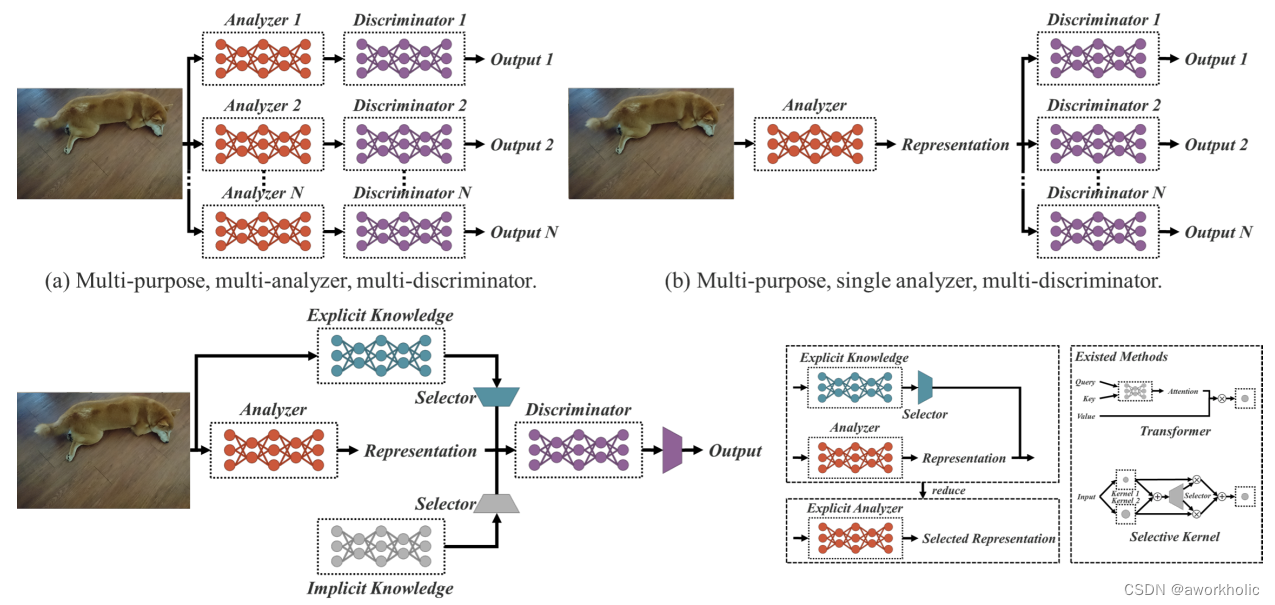
如图2所示,提出了一个统一的网络来集成显式知识和隐式知识,通过学习统一的表达,使得各个子表示能够适用于不同任务。基于前人工作的理论基础,本文结合压缩感知和深度学习来构建统一网络。
本文主要贡献如下:
-
提出了一个可同时完成多种任务的统一网络,它通过融合显式知识和隐式知识学习一个可以完成多个任务的统一表征,提出的网络可以有效的提升模型的表现,仅增加千分之一不到的计算成本;
-
通过 kernel space alignment(核空间对齐)、prediction refinement(预测细化)和 multi-task learning(多任务学习)来完成隐式知识的学习,并验证了其有效性;
-
分别讨论了隐式知识的建模方式,包括向量、神经网络、矩阵分解,并验证了这些方式的有效性;
-
证实了所提出的内隐表征学习方法能够准确地对应于特定的物理特征,并以视觉的方式进行了呈现;还证实了如果算子符合目标的物理意义,它可以用来整合隐式知识和显式知识,并会产生乘数效应;
-
与SOTA比较,YOLOR能够实现和目标检测Scaled-YOLOv4-P7一样的精度,但是推理速度快了88%。
1.2、隐式知识学习
1.2.1、隐式知识如何工作
流形空间约简
核空间对齐
更多功能和处理方式
1.2.2、隐式知识统一网络建模
隐式知识的表示
Unified Networks:
隐式知识的建模
向量/矩阵/张量
矩阵分解
训练
推理
1.3、实验
3.1 实验设置
3.2 FPN特征对齐
3.3 目标检测预测细化
3.4 多任务规范表征
3.5 隐式知识建模不同算子比较
3.6 隐式知识建模不同方式比较
3.7 隐式知识模型分析
3.8 隐式知识提升目标检测
1.4、总结
2、测试
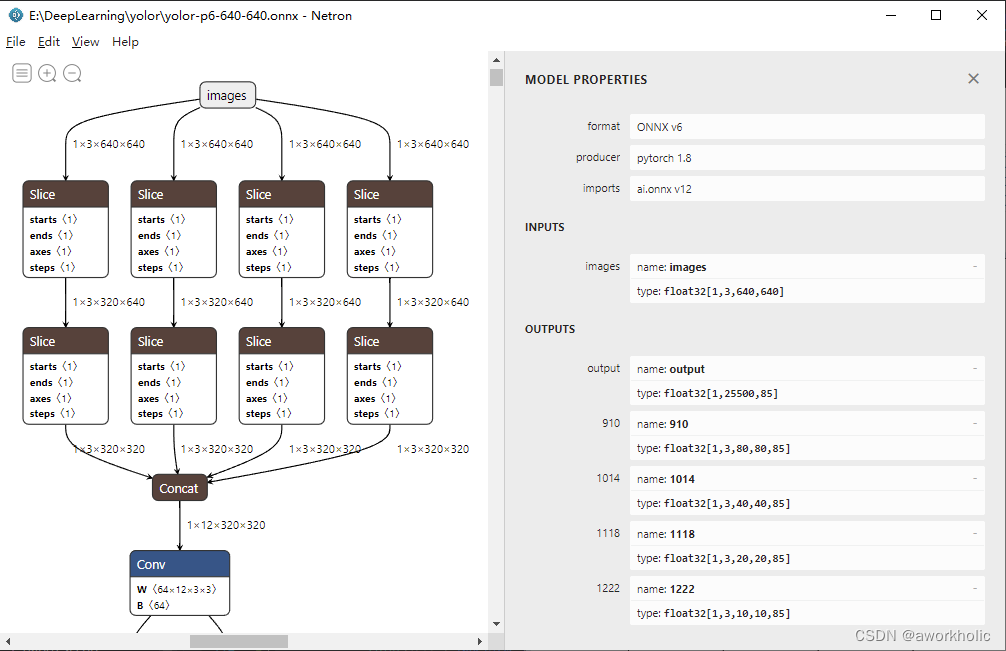
这里以 yolor-p6-640-640 进行测试。网络模型可以看到,输出一共有4个,实际是4个尺度上的结果,最终通过reshape和concat合并成一个输出(输出格式与yolov5一致)。
2.1、opencv dnn
2.1.1、代码
使用和yolov5相同的测试代码。
#pragma once
#include "opencv2/opencv.hpp"
#include <fstream>
#include <sstream>
#include <random>
using namespace cv;
using namespace dnn;
float inpWidth;
float inpHeight;
float confThreshold, scoreThreshold, nmsThreshold;
std::vector<std::string> classes;
std::vector<cv::Scalar> colors;
bool letterBoxForSquare = true;
cv::Mat formatToSquare(const cv::Mat &source);
void postprocess(Mat& frame, cv::Size inputSz, const std::vector<Mat>& out, Net& net);
void drawPred(int classId, float conf, int left, int top, int right, int bottom, Mat& frame);
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<int> dis(100, 255);
int testYoloR()
{
// 根据选择的检测模型文件进行配置
confThreshold = 0.25;
scoreThreshold = 0.45;
nmsThreshold = 0.5;
float scale = 1 / 255.0; //0.00392
Scalar mean = {
0,0,0};
bool swapRB = true;
inpWidth = 640;
inpHeight = 640;
String modelPath = R"(E:\DeepLearning\yolor\yolor-p6-640-640.onnx)";
String configPath;
String framework = "";
//int backendId = cv::dnn::DNN_BACKEND_OPENCV;
//int targetId = cv::dnn::DNN_TARGET_CPU;
int backendId = cv::dnn::DNN_BACKEND_CUDA;
int targetId = cv::dnn::DNN_TARGET_CUDA;
String classesFile = std::string(R"(\data\coco.names)");
// Open file with classes names.
if(!classesFile.empty()) {
const std::string& file = classesFile;
std::ifstream ifs(file.c_str());
if(!ifs.is_open())
CV_Error(Error::StsError, "File " + file + " not found");
std::string line;
while(std::getline(ifs, line)) {
classes.push_back(line);
colors.push_back(cv::Scalar(dis(gen), dis(gen), dis(gen)));
}
}
// Load a model.
Net net = readNet(modelPath, configPath, framework);
net.setPreferableBackend(backendId);
net.setPreferableTarget(targetId);
//std::vector<String> outNames = net.getUnconnectedOutLayersNames();
std::vector<String> outNames{
"output"};
{
int dims[] = {
1,3,inpHeight,inpWidth};
cv::Mat tmp = cv::Mat::zeros(4, dims, CV_32F);
std::vector<cv::Mat> outs;
net.setInput(tmp);
for(int i = 0; i<10; i++)
net.forward(outs, outNames); // warmup
}
// Create a window
static const std::string kWinName = "Deep learning object detection in OpenCV";
cv::namedWindow(kWinName, 0);
// Open a video file or an image file or a camera stream.
VideoCapture cap;
cap.open(R"(E:\DeepLearning\yolov5\data\images\bus.jpg)");
cv::TickMeter tk;
// Process frames.
Mat frame, blob;
while(waitKey(1) < 0) {
//tk.reset();
//tk.start();
cap >> frame;
if(frame.empty()) {
waitKey();
break;
}
// Create a 4D blob from a frame.
cv::Mat modelInput = frame;
if(letterBoxForSquare && inpWidth == inpHeight)
modelInput = formatToSquare(modelInput);
blobFromImage(modelInput, blob, scale, cv::Size2f(inpWidth, inpHeight), mean, swapRB, false);
// Run a model.
net.setInput(blob);
std::vector<Mat> outs;
//tk.reset();
//tk.start();
auto tt1 = cv::getTickCount();
net.forward(outs, outNames);
auto tt2 = cv::getTickCount();
tk.stop();
postprocess(frame, modelInput.size(), outs, net);
//tk.stop();
Put efficiency information.
//std::vector<double> layersTimes;
//double freq = getTickFrequency() / 1000;
//double t = net.getPerfProfile(layersTimes) / freq;
//std::string label = format("Inference time: %.2f ms (%.2f ms)", t, /*tk.getTimeMilli()*/ (tt2 - tt1) / cv::getTickFrequency() * 1000);
std::string label = format("Inference time: %.2f ms", (tt2 - tt1) / cv::getTickFrequency() * 1000);
cv::putText(frame, label, Point(0, 15), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 255, 0));
cv::imshow(kWinName, frame);
}
return 0;
}
cv::Mat formatToSquare(const cv::Mat &source)
{
int col = source.cols;
int row = source.rows;
int _max = MAX(col, row);
cv::Mat result = cv::Mat::zeros(_max, _max, CV_8UC3);
source.copyTo(result(cv::Rect(0, 0, col, row)));
return result;
}
void postprocess(Mat& frame, cv::Size inputSz, const std::vector<Mat>& outs, Net& net)
{
// yolov5 has an output of shape (batchSize, 25200, 85) (Num classes + box[x,y,w,h] + confidence[c])
auto tt1 = cv::getTickCount();
float x_factor = inputSz.width / inpWidth;
float y_factor = inputSz.height / inpHeight;
std::vector<int> class_ids;
std::vector<float> confidences;
std::vector<cv::Rect> boxes;
int rows = outs[0].size[1];
int dimensions = outs[0].size[2];
float *data = (float *)outs[0].data;
for(int i = 0; i < rows; ++i) {
float confidence = data[4];
if(confidence >= confThreshold) {
float *classes_scores = data + 5;
cv::Mat scores(1, classes.size(), CV_32FC1, classes_scores);
cv::Point class_id;
double max_class_score;
minMaxLoc(scores, 0, &max_class_score, 0, &class_id);
if(max_class_score > scoreThreshold) {
confidences.push_back(confidence);
class_ids.push_back(class_id.x);
float x = data[0];
float y = data[1];
float w = data[2];
float h = data[3];
int left = int((x - 0.5 * w) * x_factor);
int top = int((y - 0.5 * h) * y_factor);
int width = int(w * x_factor);
int height = int(h * y_factor);
boxes.push_back(cv::Rect(left, top, width, height));
}
}
data += dimensions;
}
std::vector<int> indices;
NMSBoxes(boxes, confidences, scoreThreshold, nmsThreshold, indices);
auto tt2 = cv::getTickCount();
std::string label = format("NMS time: %.2f ms", (tt2 - tt1) / cv::getTickFrequency() * 1000);
cv::putText(frame, label, Point(0, 30), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 255, 0));
for(size_t i = 0; i < indices.size(); ++i) {
int idx = indices[i];
Rect box = boxes[idx];
drawPred(class_ids[idx], confidences[idx], box.x, box.y,
box.x + box.width, box.y + box.height, frame);
}
}
void drawPred(int classId, float conf, int left, int top, int right, int bottom, Mat& frame)
{
rectangle(frame, Point(left, top), Point(right, bottom), Scalar(0, 255, 0));
std::string label = format("%.2f", conf);
Scalar color = Scalar::all(255);
if(!classes.empty()) {
CV_Assert(classId < (int)classes.size());
label = classes[classId] + ": " + label;
color = colors[classId];
}
int baseLine;
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
top = max(top, labelSize.height);
rectangle(frame, Point(left, top - labelSize.height),
Point(left + labelSize.width, top + baseLine), color, FILLED);
cv::putText(frame, label, Point(left, top), FONT_HERSHEY_SIMPLEX, 0.5, Scalar());
}
2.1.2、结果
测试如图,发现误识别了一个 traffic light。对比源py测试脚本,修改 bool letterBoxForSquare = false; 将等比缩放关闭后检测正常。

2.2、测试效率
RTX-1080ti,i7-7700k
opencv cpu:630ms
opencv gpu :52ms
opencv gpu (fp16):793ms
以下统计时间包含: 预处理+推理+后处理
openvino(cpu):274ms
onnxruntime(gpu):30ms
tensorrt:23ms