本文介绍第一个机器学习算法:k-近邻算法,它非常有效而且易于掌握。
1.概述
简单地说,k-近邻算法采用测量不同特征值之间的距离方法进行分类。
优点:精度高、对异常值不敏感、无数据输入假定。
缺点:计算复杂度高、空间复杂度高。
适用数据范围:数值型和标称型。
2.约会网站分类示例
我的朋友海伦一直使用在线约会网站寻找适合自己的约会对象。尽管约会网站会推荐不同的
人选,但她并不是喜欢每一个人。经过一番总结,她发现曾交往过三种类型的人:
不喜欢的人
魅力一般的人
极具魅力的人
我们现在有一些样本数据,样本主要包含以下3种特征
每年获得的飞行常客里程数
玩视频游戏所耗时间百分比
每周消费的冰淇淋公升数
因此我们需要根据这些样本数据来推测出相对应的交往类型
1.使用python做出散点图如下
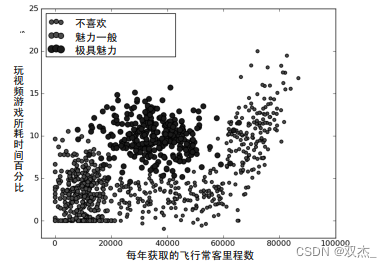

2.根据新数据与推断数据的距离判断类型
如下图为需推测的样本数据
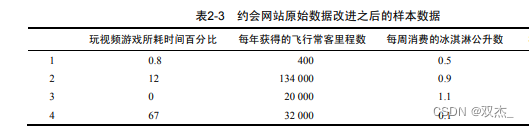
简单计算样本4的距离如下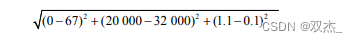
归一化公式
我们可以简单根据归一化后的距离推测样本的分类,如下图

3.数字图像简析

假如我们有一堆样本,那么我们怎么推测新加入的数字是多少呢
我们可以根据每一行的像素作为一个向量,来判断与推测样本的距离
3.延伸思考
上面约会网站的例子,我们将三个因子(每年获得的飞行常客里程数,玩视频游戏所耗时间百分比,每周消费的冰淇淋公升数)均匀分配。实际上我们可以看出飞机历程数的影响会大于其它两个因素的影响,据此我们可以将三个因子采用不同的权重。至于权重的计算可以采用逼近算法来计算。