简单地说,k-NN算法就是根据测量不同特征值之间的距离来进行分类的。
输入没有标签的数据后,将新数据的每个特征值的和样本集的数据进行比较,然后提取样本集中特征最相似的数据,通常选取前k个最相似的数据,所有称为k-邻近算法。
K-NN算法的一般流程:
(1)收集数据:可以使用任何方法。
(2)准备数据:计算所需要的数值。
(3)分析数据:可以使用任何方法。
(4)训练数据:不适用于k-NN算法。
(5)测试算法:计算准确率。
(6)使用算法:首先处理数据,输入样本数据输出结构化数据。
接着使用算法进行分类,对数据进行后续处理。
最常见的两点之间或多点之间的距离表示法,又称之为欧几里得度量,它定义于欧几里得空间中,如点 x = (x1,…,xn) 和 y = (y1,…,yn) 之间的距离为:
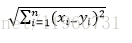
k-NN算法的核心代码如下:
def classify0(inX, dataSet, labels, k): #inX输入测试数据,dataSet数据集,labels数据集的标签,k的大小
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0](代码来自《机器学习实战 Peter Harrington》)