循环神经网络介绍
结构介绍
循环神经网络 RNN 的基本结构是 BP 网络的结构,也是有输入层,隐藏层和输出层。只不过在 RNN 中隐藏层的输出不仅可以传到输出层,并且还可以传给下一个时刻的隐藏层,如下图所示: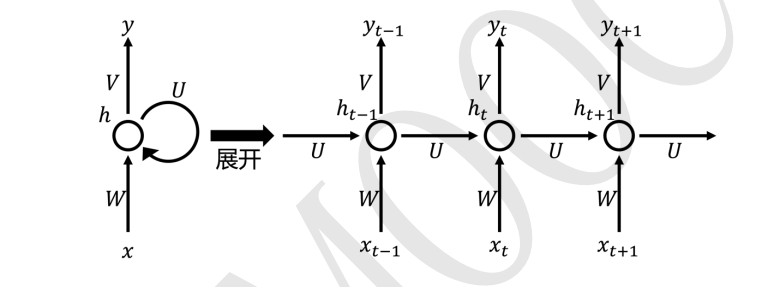
注意:整个RNN结构是共享一组W、U、V、b的,这个RNN结构的一个重要特性。
RNN 的结构可以展开为右边的结构,其中 x x x 为输入信号, x t − 1 x_{t-1} xt−1 为t-1时刻的输入信号, x t x_{t} xt 为 t 时刻的输入信号, x t + 1 x_{t +1} xt+1 为 t + 1 {t+1} t+1 时刻的输入信号。 h t − 1 h_{t-1} ht−1为 t-1 时刻的隐藏层信号, h t h_{t} ht为 t 时刻的隐藏层信号, h t + 1 h_{t+1} ht+1为 t+1 时刻的隐藏层信号。 y t − 1 y_{t-1} yt−1为 t-1 时刻的输出层信号, y t y_{t} yt为 t 时刻的输出层信号, y t + 1 y_{t+1} yt+1为 t+1 时刻的输出层信号。W,U,V 为网络的权值矩阵。h 是隐藏(hidden)的首字母
从结构上可以观察到 RNN 最大的特点是之前序列输入的信息会对模型之后的输出结果造成影响。
公式推导
循环神经网络 RNN 有两种常见的模型,一种是 Elman network 另一种是 Jordan network。Elman network 和 Jordan network 也被称为Simple Recurrent Networks (SRN)或 SimpleRNN,即简单的循环神经网络。
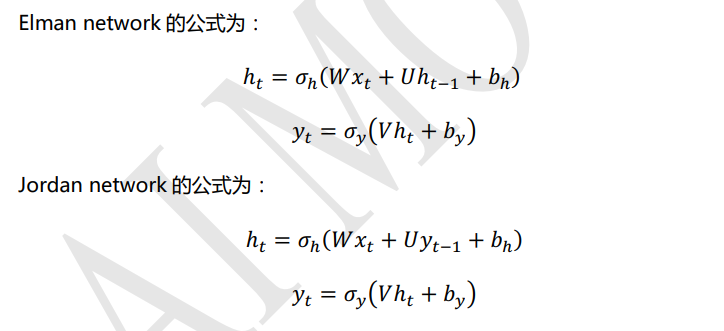
其中 x t x_{t} xt为 t 时刻的输入信号, h t h_t ht为 t 时刻隐藏层的输出信号, y t y_t yt为 t 时刻输出层的输出信号。W,U,V 对应图 9.5 中的权值矩阵,b 为偏置值。 σ h \sigma_h σh 和 σ y \sigma_y σy为激活函数,激活函数可以自行选择。通常情况下 σ h \sigma_h σh 为tanh激活函数, σ y \sigma_y σy 如果做二分类任务可以选择sigmod,多分类任务可以选择softmax。
从上面 Elman network 和 Jordan network 的公式对比中可以看出,Elman network的隐层 h t h_{t} ht 接收的是上时刻的隐层 h t − 1 h_{t-1} ht−1 的信号;而 Jordan network 的隐层 h t h_{t} ht 接收的是上时刻的输出层 y t − 1 y_{t-1} yt−1 的信号。一般 Elman network 的形式会更常用一些。
思考题1:为什么要选择tanh作为隐藏层的激活函数呢?
参考链接:史上最小白之RNN详解

在梯度更新的过程中,由公式推导得最后计算得梯度的时候需要用到隐藏层激活函数的导数的连乘,sigmoid函数的导数介于[0,0.25]之间,tanh函数的导入为[0,1]之间,虽然他们两者都存在梯度消失的问题,但tanh比sigmoid函数的表现要好,梯度消失得没有那么快。
思考题2:那么为什么RNN中不选用ReLU激活函数来彻底解决梯度消失的问题呢?
其实在RNN中使用ReLU函数确实也是能解决梯度消失的问题地,但是又会引入一个新问题梯度爆炸。
激活函数的导数每次需要乘上一个Ws,只要Ws的值大于1的话,经过多次连乘就会发生梯度爆炸的现象。但是这里的梯度爆炸问题也不是不能解决,可以通过设定合适的阈值解决梯度爆炸的问题。
但是目前大家在解决梯度消失问题地时候一般都会选择使用LSTM这一RNN的变种结构来解决梯度消失问题,而LSTM的激活函数又是选择的tanh,还不会引入梯度爆炸这种新问题,所以可能也就没有必要在基础的RNN上过多的纠结是选用ReLU还是tanh了吧,因为大家实际中用的都是LSTM,只需要理解RNN的思想就行了,于是就选择了一个折中的比sigmoid效果好,又不会引入新的梯度爆炸问题地tanh作为激活函数。
循环神经网络RNN的多种类型任务
one to one
输入的是独立地数据,输出的也是独立地数据,基本上不能算作是RNN,跟全连接神经网络没有什么区别
one to n
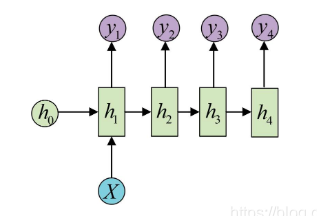
输入的是一个独立数据,需要输出一个序列数据,常见的任务类型有:
- 基于图像生成文字描述
- 基于类别生成一段语言,文字描述
n to n
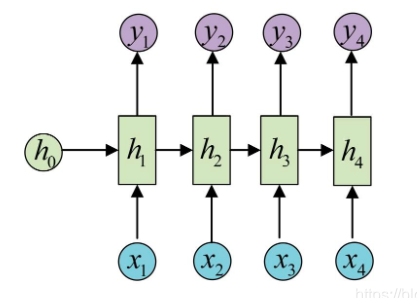
最为经典地RNN任务,输入和输出都是等长地序列,常见的任务有:
- 计算视频中每一帧的分类标签
- 输入一句话,判断一句话中每个词的词性
n to one
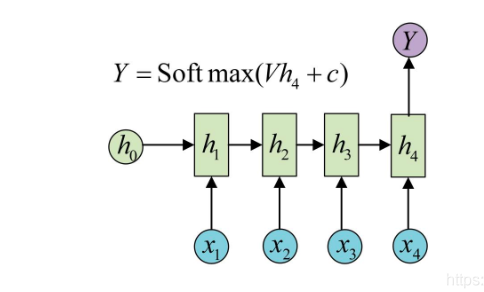
输入一段序列,最后输出一个概率,通常用来处理序列分类问题。常见任务:
- 文本情感分析
- 文本分类
n to m
Seq2Seq 的全称是 Sequence to Sequence,也就是序列到序列模型。seq2seq 也算是多对多架构
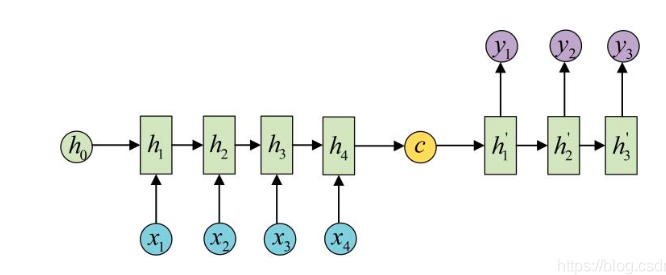
输入序列和输出序列不等长地任务,也就是Encoder-Decoder结构,这种结构有非常多的用法:
- 机器翻译:Encoder-Decoder的最经典应用,事实上这结构就是在机器翻译领域最先提出的
- 文本摘要:输入是一段文本序列,输出是这段文本序列的摘要序列
- 阅读理解:将输入的文章和问题分别编码,再对其进行解码得到问题的答案
- 语音识别:输入是语音信号序列,输出是文字序列
基于Encoder-Decoder的结构后续有改良出了NLP中的大杀器transformer和Bert。
参考链接:seq2seq与attention
小白详解seq2seq、attention、self-attention