1、k近邻分类算法
KNN算法(K-Nearest-Neighbour Classification),是一个概念极其简单,而分类效果又很优秀的分类算法
它的核心思想就是,要确定样本属于哪个分类,就寻找所有样本中与该测试样本举例最近的前K个样本,然后看这K个样本大部分属于哪一类,那么就认为这个测试样本也属于哪一类。简单的说就是让最相似的K各样本投票决定。
这里所说的距离,一般最常用的就是多维空间的欧式距离。这里的维度指特征维度,即样本有几个特征就属于几维。
KNN算法示意图如下:
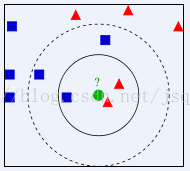
上图中,要确定测试样本绿色属于蓝色还是红色
显然,当k = 3时,将以1:2的投票结果分类于红色;而当K= 5时,将以3:2投票结果分类于蓝色
KNN算法简单有效,但没有优化的暴力法效率最容易达到瓶颈。如样本个数为N,特征为度为D的时候,改算法时间复杂度为O(DN)增长,所以通常KNN算法的实现会把训练数据构建成K-D Tree,构建过程很快,甚至不需要计算d 维欧氏距离,而搜索速度高达O(D*log(N))
2、KNN算法的一般流程:
(1)、收集数据:可以使用任何方法。
(2)、准备数据:距离计算所需要的数值,最好是结构化的数据格式
(3)、分析数据:可以使用任何方法
(4)、训练数据:此步骤不适用于k近邻算法
(5)、测试数据:计算错误率
(6)、使用算法:首先需要输入样本数据和结构化的输出结果,然后运行k近邻算法判定输入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理。
3、步骤:
收集数据,这里我们使用博客上提供的身高体重的数据,如下:
1.5 40 thin 1.5 50 fat 1.5 60 fat 1.6 40 thin 1.6 50 thin 1.6 60 fat 1.6 70 fat 1.7 50 thin 1.7 60 thin 1.7 70 fat 1.7 80 fat 1.8 60 thin 1.8 70 thin 1.8 80 fat 1.8 90 fat 1.9 80 thin 1.9 90 fat
4、实施K近邻分类算法
这里首先给出K近邻算法的伪代码和实际的Python代码,然后详细讲解。伪代码如下:
对未知类别属性的数据集中的每个点依次执行以下操作
(1)计算已知类别数据集中的点与当前点之间的距离
(2)按照距离递增次序排列
(3)选取与当前点距离最小的K个点
(4)确定当前k个点所在类别的出现频率
(5)返回前k个点出现频率最高的类别作为当前点的预测分类
python代码如下:
def classify0(inX,dataSet,labels,k):
dataSetSize = dataSet.shape[0] #求矩阵dataSet第一维的长度
diffMat = tile(inX,(dataSetSize,1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis = 1) # sum(axis = 1):将矩阵每行相加,sum(axis = 0):将矩阵每列相加
distances = sqDistances **0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(),key = operator.itemgetter(1),reverse = True)
return sortedClassCount[0][0]
classify0()函数有四个输入参数:用于分类的输入向量是inX,输入的训练样本集为dataSet,标签向量为labels,最后的参数k表示用于选择最近邻居的数目,其中标签向量的数目和矩阵dataSet的行数相同。
为了预测分类器的效果,我们可以构造出dataSet数据和labels数据,用于测试程序的运行效果
>> dataSet = array([[1.5,40],[1.5,50],[1.5,60],[1.6,40],[1.6,50],[1.6,60],[1.6,70],[1.7,50],[1.7,60],[1.7,70],[1.7,80],[1.8,60],[1.8,70],[1.8,80],[1.8,90],[1.9,80],[1.9,90]])
>>labels = labels = ['thin','fat','fat','thin','thin','fat','fat','thin','thin','fat','fat','thin','thin','fat','fat','thin','fat']
>>kNN.classify0([1.57,47],dataSet,labels,3)
输出结果为thin。
5、归一化数据
上面给出的数据,求欧式距离的时候,很容易会发现,方程式中数字差值最大的属性对计算结果的影响最大,也就是说,体重特征对方程式的结果影响最大。因此要对两种特征数据进行归一化处理。
在处理这种不同取值范围的特征值时,我们通常采用的方法是将数值归一化,如将取值范围处理为0到1或者-1到1之间,下面的公式可以将任意范围的特征值转化为0到1区间内的指:
newValue = (oldvalue-min)/(max-min)
其中min和max分别是数据集中的最小特征值和最大特征值。最然改变数值取值范围增加了分类器的复杂度,但为了得到准确的结果,我们必须这样做。
python实现归一化处理的代码:
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals,(m,1))
normDataSet = normDataSet/tile(ranges,(m,1))
return normDataSet,ranges,minVals
在函数autoNorm()中,我们将每列的最小值放在变量minVals中,将最大值放在变量maxVals中,其中dataSet.min(0)中的参数0使得函数可以从列中选择最小值,而不是选取当前行的最小值。然后,函数计算可能的取值范围,并创建新的返回矩阵。
对于上面给出的身高体重,没有归一化处理,这里就不再具体操作。
不理解的可以跟帖回复。。。
打赏看侧边栏