自然语言处理:一种能让计算机理解人类语言的技术,换而言之自然语言处理的目标就是让计算机理解人说的话,
单词的含义
让计算机理解语言,首先要理解我们的单词,有三种方法,1.基于同义词词典,2.基于计数方法,3.基于推理的方法(word2vec)。
单词分布式表示
大家都知道颜色的表示是R,G,B,三原色分别存在的数字精准表示出来,有多少种颜色,对应着相同数量的表示颜色的三维向量,将类似颜色的向量表示方法用到单词表示上就是单词分布式表示.
分布式假设
如何构建单词分布式表示呢
方法:分布式假设。某个单词的含义是由它周围单词形成的,单词本身没有含义,是由上下语境生成的,即单词左侧和右侧单词
共现矩阵
分布式假设使用向量表示单词,这种方法是基于计数的方法,实现方法是直接统计目标词周围单词出现的次数
汇总了所有单词的共现单词的表格。这个表格的各行对应相应单词的向量。表格呈矩阵状,所以称为共现矩阵


神经网络预测方法
神经网络进行推理文本,通常是通过小批量文本学习文本,并反复更新权重,这样好处是可以处理大文本数据
基于推理方法概要
给出周围单词(上下文信息),预测中间单词会出现什么单词,这就是推理

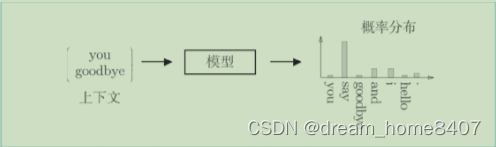
输入上下文信息,模型输出各个单词可能出现的概率,这正是分布式假设
优于计数方法关键是可以小批量送入模型训练,
基于推理的方法我们引入模型,我们将神经网络用于此模型,这个模型接收上下文信息作为输入,并输出(可能出现的)各个单词出现的频率,在这样的框架中,使用语料库来学习模型,使之能做出正确的预测,另外作为模型的产物,我们得到了单词的分布式表示,这就是基于推理方法的全貌。
如何对分布式假设单词共现建模?
神经网络中单词的处理方法
利用神经网络处理单词,但是神经网络无法直接处理you或者say这样的单词,要用神经网络处理单词,先要将单词转化为固定长度的向量,对此,一种方法是将单词转化为one-hot向量,在one-hot向量中,只有一个是1,其余全部是0

用向量表示单词的方法大致有两种,一种是基于计数的方法,一种是基于推理的方法,两者的背景都是分布式假设
word2vec
word2vec 一词最初用来指程序或者工具,但是随着该词的流行,在某些语境下,也指神经网络的模型。正确地说,CBOW 模型和 skip-gram 模型是 word2vec 中使用的两个神经网络。我们将主要讨论 CBOW 模型。关于这两个模型的差异,
CBOW模型 continuous bag-of-words(CBOW)
CBOW模型是根据上下文预测目标词的神经网络(目标词是中间词,它的上下文是周围词)我们通过训练CBOW模型,使其可以尽可能正确预测,我们可以获取单词的分布式表示
CBOW 模型的输入是上下文。这个上下文用 [‘you’, ‘goodbye’]这样的单词列表表示。我们将其转换为 one-hot 表示,以便 CBOW 模型可以进行处理。在此基础上,CBOW 模型的网络可以画成图
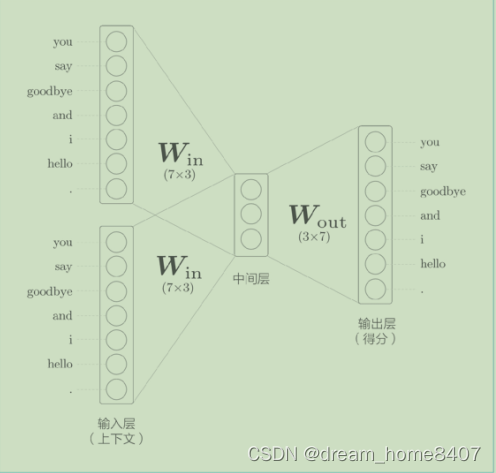
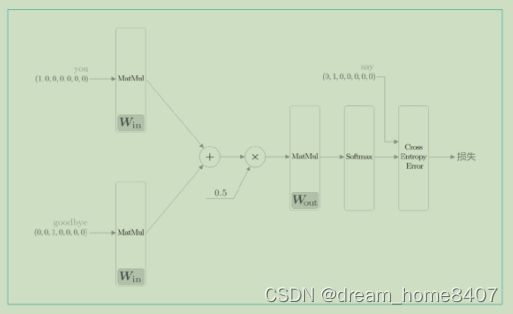
CBOW模型的网络结构,它有两个输入层,到达中间层然后传给输出层,从输入层到中间层的变换由相同的全连接层(权重为Win )完成,从中间层到输出层神经元的变换由另一个全连接层(权重为Wout )完成。
这里我们对上下文仅考虑两个单词,所以输出层有两个,如果对上下文考虑N个单词,那么输入层有N个。中间层的神经元是各个输入层经全连接层变换后得到值的平均,就上面例子而言,经过全连接层变换后,第一个输出转化为h1,第二层输出转化为h2,那么中间层的神经元是1/2(h1+h2),这个输出层有7个神经元,这里最重要的是,这些神经元对应各个单词,输出层神经元是各个层的得分,这个词越大说明对应单词出现的频率就越高,得分是指在被解释为概率之前的值,对这些得分应用softmax函数,就可以得到概率,有时将得分经过softmax层之后的神经元称为输出层,这里我们将输出得分的节点称为输出层,
从输入层到中间层的变换由全连接层完成,此时,全连接层的权重w是一个7*3的矩阵,这个权重矩阵就是我们要的单词分布式表示,
权重的各行对应各个单词的分布式表示
通过反复学习,不断更新各个单词的分布式表示,以正确的从上下文预测出应当出现的单词,,如此获得向量很好的对单词含义进行编码,这就是word2vec,中间层的神经元数量比输入层少一点很重要,中间层需要将预测的单词所需的信息进行压缩保存,从而产生迷局的向量表示,这时中间层被写入我们人类无法理解的代码,这相当于编码工作,而从中间层的信息获得期望结果的过程则被称为解码,这一过程将被编码的信息复原为我们可以理解的形式,
所谓的模型向量化过程,文字传入网络中间层后输出密集向量的表示
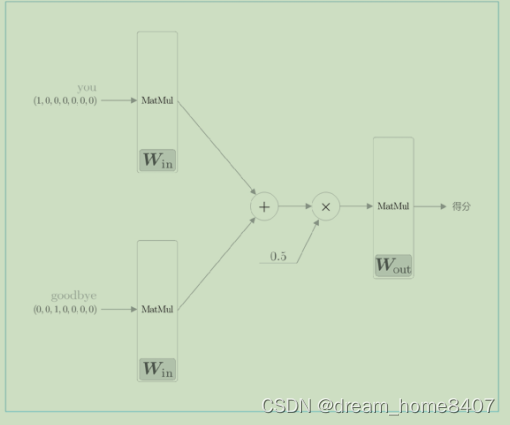
如图所示,模型由两个层输出结果被加在一起,然后这个相加后的值乘以0.5求平均,可以得到中间层的神经元,然后将另一个层应用于中间层的神经元输出得分,
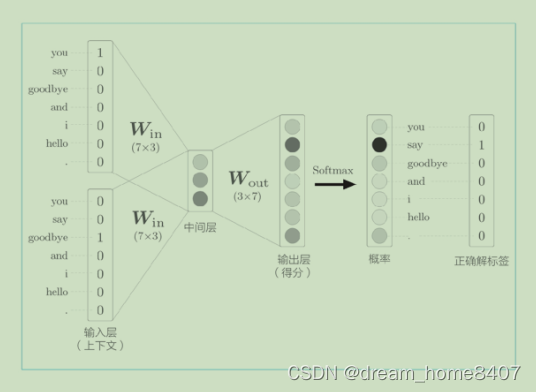
如图上图所示,上下文是由you和goodbay,神经元正确的预测的单词应该是say,这时如果神经元有良好的权重,那么表示概率的神经元中,对应正确解的神经元的得分应该更高,
cbow模型的学习就是调整权重,以使正确预测,其结果是win和wout,学习到单词出现模式的向量,CBOW和skip-gram得到单词的分布式表示,CBOW模型学习到语料库中单词出现的模式,如果语料不一样,即使是同一个单词,不同预料下单词的分布式表示也有很大的不同,
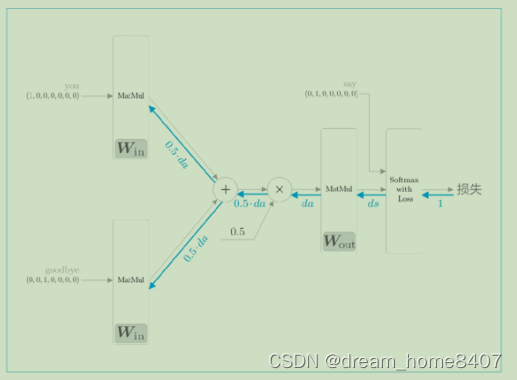
接下来了解神经网络的学习,这里我们处理的模型是一个进行多分类的神经网络,对其进行学习是只是使用一下Softmax函数和交叉熵误差,首先softmax函数将得分转为概率,再求这些概率和监督标签之间的交叉熵误差,并将其作为损失进行学习,对应网络的正向传播。
word2vec的权重和分布式表示
woed2vec的使用网络有两个权重,分别是输入侧的全连接层Win和输出侧Wout,一般而言,输入层的权重的每一行对应各个单词的分布式表示,输出侧的权重同样保存了对单词含义进行编码的向量,
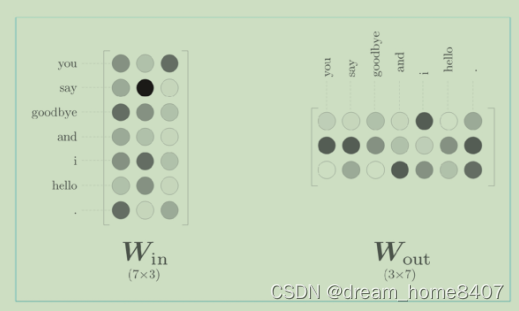
输入层和输出侧的权重都可以视为单词的分布式表示,那么我们应该使用哪侧作为单词的分布式表示呢
A.只使用输入测权重
B.只使用输出侧权重,
C.输入侧和输出侧同时使用权重
方案C两种权重同时使用的方法大都是简单将两者相加。
就word2vec而言,最受欢迎的是只使用输入层权重,遵循这思路我们使用Win作为单词的分布式表示。
学习数据准备
1.word2vec中神经网络的输入是上下文和目标词,,它的正确解标签是被上下文包围的中间词即目标词,也就是说我们要做的事情是,当神经网络输入上下文时,使目标词出现的概率高
实现步骤,先将文本转化为单词ID,实现一个当给定 corpus时返回 contexts和 target的函数。

这样就从语料库生成了上下文和目标词,后面只需将它们赋给 CBOW 模型即可。不过,因为这些上下文和目标词的元素还是单词 ID,所以还需要将它们转化为 one-hot 表示。
转化为one-hot表示

CBOW网络结构
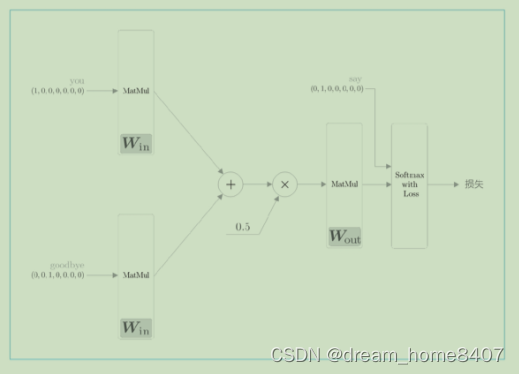
我们创建必要的层。首先,生成两个输入侧的 MatMul 层、一个输出侧的 MatMul 层,以及一个 Softmax with Loss 层。这里,用来处理输入侧上下文的 MatMul 层的数量与上下文的单词数量相同(本例中是两个)。另外,我们使用相同的权重来初始化 MatMul 层。
最后,将该神经网络中使用的权重参数和梯度分别保存在列表类型的成员变量 params和 grads中。
接下来我们实现正向传播
skip-gram 模型
与CBOW完全相反的是,skip-gram则从中间的单词预测周围更多的单词,
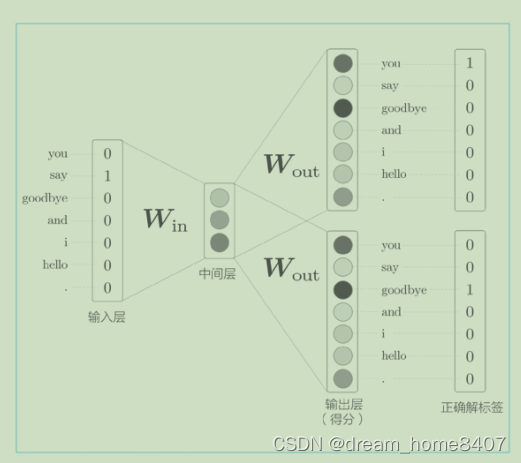
skip-gram 模型的输入层只有一个,输出层的数量则与上下文的单词个数相等。因此,首先要分别求出各个输出层的损失(通过 Softmax with Loss 层等),然后将它们加起来作为最后的损失。
加速word2vec
之前讲到的CBOW接收两个上下文单词,并基于他们预测一个目标单词,,此时通过输入层和输入层侧的权重之间的矩阵乘积计算中间层,通过中间层和中间层侧的权重之间的矩阵乘积计算每个单词的得分,这些得分经过softmax函数转化后,得到每个单词出现的概率,通过这些概率和正解标签进行损失值的计算,得出损失结果,
但是当词汇量有一万个时,one-hot本身需要霸占一万个元素的内存大小,在权重矩阵计算时也需要大量的计算资源,因此我们引入embedding层来解决,
同时中间层的输出结果,对于softmax计算量也会增加,所以我们需要引入新的损失函数,来消除这些计算瓶颈。
Embedding层
由于one-hot编码在词汇量在10万时候,需要大量的计算资源,现在我们创建一个从权重参数层抽取单词ID对应行向量的层,我们称之为Embedding层,例如下图所示,无非是将矩阵的某个特定行取出。
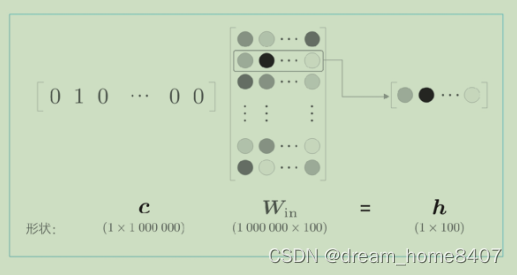
在自然语言处理领域,单词的密集向量表示称之为词嵌入(word embedding)或者单词的分布式表示(distributed representtation)
Embedding层的实现
从矩阵中取出某一行的处理是很容易实现的。利用矩阵索引的方法,这里假设权重 W是 NumPy 的二维数组。如果要从这个权重中取出某个特定的行,只需写 W[2]或者 W[5]
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
for i, word_id in enumerate(self.idx):
dW[word_id] += dout[i]
# np.add.at(dW, self.idx, dout)
return None
Embedding层的正向传播是从权重矩阵W中取出特定的行,并将特征行的神经元传递给下一层,因此在反向传播时,将上一层输出侧传递的权重参数原样的传给下一层输入侧,不过上一层传来的梯度会被应用到权重梯度dw的特定行,
接下来仍然有需要两个地方需要很多的计算时间
1.中间层神经网和权重矩阵的的乘积,
2.softmax层的计算
中间层向量的大小是100,权重矩阵的大小是100*10万,如此巨大的乘积需要大量的计算时间,此外反向传播也需要同样多的时间,所以很有必要将矩阵计算轻量化.
其次softmax也会出现同样的问题,
负采样:用二分类来拟合多分类
二分类处理的是答案为“Yes/No”的问题。诸如,“这个数字是 7 吗?”“这是猫吗?”“目标词是 say吗?”等,这些问题都可以用“Yes/No”来回答,
cbow模型负采样示例图如下:
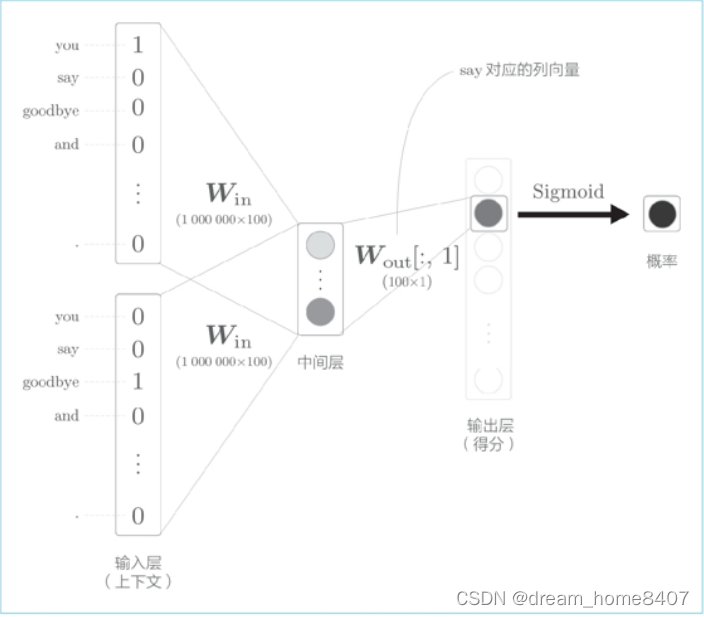
最后仅仅计算目标单词和中间层权重矩阵的内积,现在只需要提取出对应列单词的单词向量,并用他与中间层的神经元计算内积,
输出侧的权重中保存了各个单词的ID对应的单词向量,此处我们提取的单词向量,再求这个向量和中间层神经元的内积,这就是我们的得分,然后使用sigmoid函数将其转化为概率,要使用神经网络处理二分类,需要将sigmoid函数将其转化为概率,为求损失,我们使用交叉熵函数作为损失函数,这些都是神经网络二分类的老套路。在多分类神经网络中使用softmax将多分类转化为概率,同样也使用交叉熵作为损失函数,
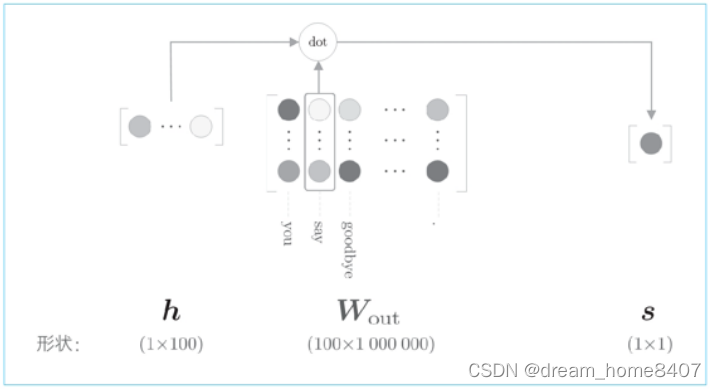
下图为cbow模型二分类的全过程
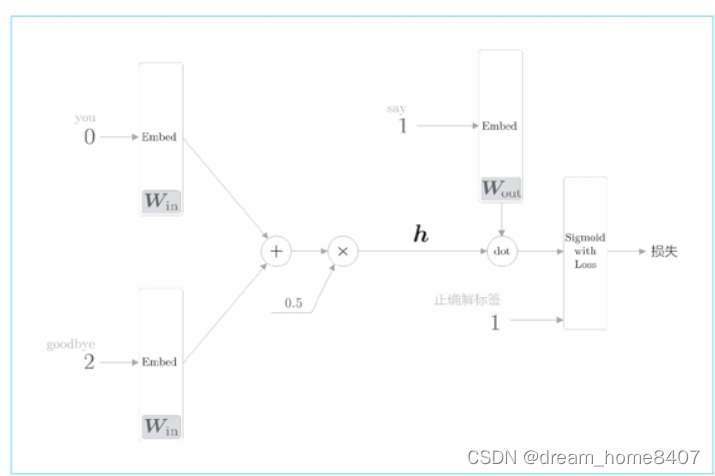
这里将神经元记作h,并与say的单词向量计算内积,最后将结果输入到损失函数计算损失结果,
负样本采样,我们希望正样本预测的概率无限接近与1,同时我们也希望负样本的数量无限接近于0,但是负样本过多,我们需要收集些数据作为采样,这就是负样本采样,
为了把多分类问题处理为二分类问题,对于正确答案(正例)和错误答案(负例),都需要正确的进行二分类,那么我门需要对二分类进行学习吗,答案当然是no,我们将选择若干个负例子,
总而言之.负样本既可以求将正例作为目标词的损失,同时也可以采样若干负例,对这些负例求损失,然后将这些数据的损失加起来,将其结果作为最终的损失,