很多介绍yolov5的文章都会讲到focus层,但是如果你去看yolov5的源码(比如yolov5-6.2, yolov5-7.0等较新的版本),你会发现代码里还有focus层,但是没用到它。
比如yolov5-7.0\models\common.py
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act=act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))
# return self.conv(self.contract(x))它原来就是处于整个网络的第一层,现在已经被一个卷积层替换掉了,即箭头处的卷积层把它替换掉了。

上图看的是yolov5s.yaml里的内容,这里要说一下,在yolov5s中这个卷积层的输出通道数并不是64,其它几个yaml文件中这里写的都会是64,但是实际的输出通道数需要乘以上面那个红框里的width_multiple,这个值在几个yaml中是不一样的,它控制了不同规格的模型的通道数。所以在yolov5s中第一个卷积层的输出通道数是64*0.5=32。
一。focus层结构
现在回头看看focus的结构,它的输入通道c1肯定就是3啦,就是输入图像的3通道,输出通道c2跟上面的卷积层的输出通道数是一样的,即在yolov5s中也是32。focus层会先把输入图片进行切片操作,分成4组,每组都是3个通道,所以一共是12个通道,然后接一个3乘3的卷积层,即结构如下:
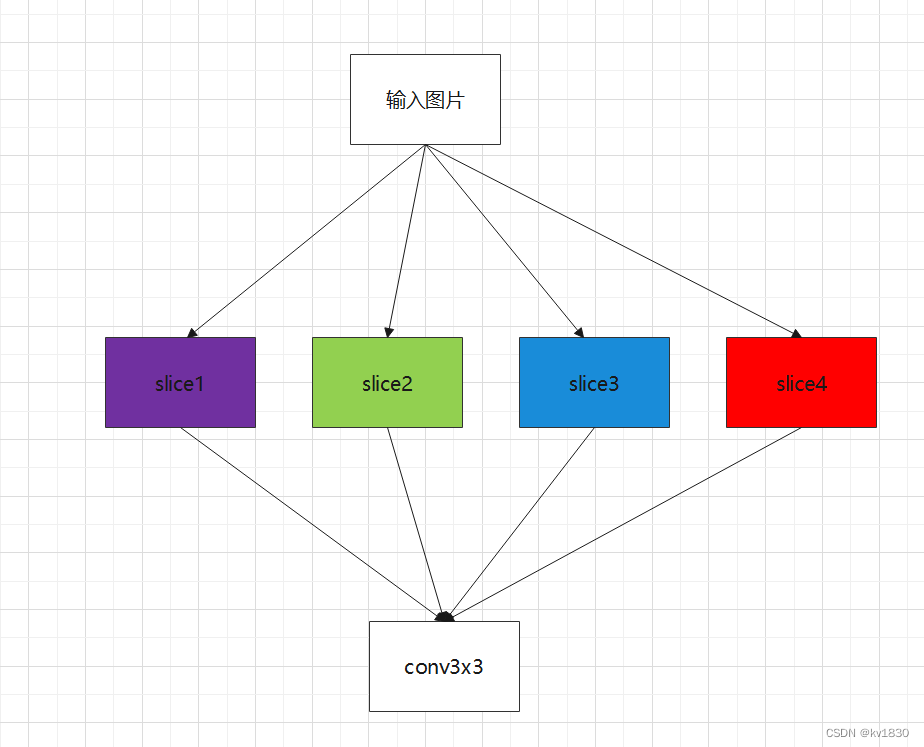
具体4组是怎么分的呢,结合图示来讲比较直观:
下图就是一个3通道图片,每个格子都是一个像素(这里画的肯定不是640乘640啦,你就假设它是640乘640吧)

focus的切片操作就是把粉色的归第1组,绿色的归第2组,蓝色的归第3组,红色的归第4组,每组仍然是3个通道,然后把4组排在一起(按第1个维度合并(从第0维度开始算),每组都是一个(b,3,320,320)的张量,b就是批大小,注意是320了,不是640了哦),就得到了12个通道的输入了,即(b,12,320,320),如下图

然后再经过一个3乘3卷积的运算,输入通道12,输出通道32(按yolov5s算),输出分辨率还是320乘320。所以整个focus的用处是啥呢,我觉得主要就是:
增大感受野的同时降低运算量,如果没有前面的切片操作,直接接一个3乘3的卷积,那感受野肯定就小了一半啦,如果直接接一个6乘6的卷积,同样是输入3通道,输出32通道,那运算量会是前面的4倍。
二。替换
然后一天,一个人突然提出来,这个focus是不是直接等价于一个6乘6步长为2的卷积?
来龙去脉请见这个issue: https://github.com/ultralytics/yolov5/issues/4825
他直接给出了代码,先实例化一个Focus层,然后把Focus层的卷积层的参数拷贝给一个6乘6步长2的卷积层(怎么拷贝的下面再说),然后给两者同样的输入,比较它们的输出。并不是用==来比较的,而是用torch.allclose,精度设为10的负6次方,因为浮点数计算顺序不同,可能结果是有误差的。接下来再比较一下两者的性能。

代码如下,这段代码你可以放在一个test.py里,然后把test.py放在yolov5的目录里,就可以直接运行啦(注意,这里的输入通道数是3,输出通道数写的是64)
import torch
from models.common import Focus, Conv
from utils.torch_utils import profile
focus = Focus(3, 64, k=3).eval()
conv = Conv(3, 64, k=6, s=2, p=2).eval()
# Express focus layer as conv layer
conv.bn = focus.conv.bn
conv.conv.weight.data[:, :, ::2, ::2] = focus.conv.conv.weight.data[:, :3]
conv.conv.weight.data[:, :, 1::2, ::2] = focus.conv.conv.weight.data[:, 3:6]
conv.conv.weight.data[:, :, ::2, 1::2] = focus.conv.conv.weight.data[:, 6:9]
conv.conv.weight.data[:, :, 1::2, 1::2] = focus.conv.conv.weight.data[:, 9:12]
# Compare
x = torch.randn(16, 3, 640, 640)
with torch.no_grad():
# Results are not perfectly identical, errors up to about 1e-7 occur (probably numerical)
assert torch.allclose(focus(x), conv(x), atol=1e-6)
# Profile
results = profile(input=torch.randn(16, 3, 640, 640), ops=[focus, conv, focus, conv], n=10, device=0)相同的输入,输出肯定是相等了。性能的话不同显卡会有点差异,比如下面是Yolov5的作者在V100上的测试结果,分别统计了前向传播和反向传播的时间,4行记录分别是focus,conv,focus,conv。在batch-size为16和1的情况下他都测了一下。
对于前向传播,V100快了一点点,对于反向传播,快了近1/3的速度。
下面是我在笔记本3080上测的情况,前向速度差不多,时快时慢,反向速度明显是conv比focus快。

最终的结论就是:
1。从计算结果上来看,两者确实等价
2。从性能上来看
在比较新的设备上,比如V100(虽然已经是上一代显卡了),30系显卡等(甚至还包括1080ti),conv比focus快,尤其是反向传播(cuda肯定也得用比较新的了)
在比较老的显卡上比如k80、T4,conv比focus慢不少。
本着优先考虑主流设备、新一代设备的原则,并且考虑到focus层对很多端侧设备不友好(比如ncnn就不支持focus层),所以作者就果断把它给换掉了。
三。详解替换
接下来分析一下,两者为啥就等价了呢?focus的卷积层的参数是怎么拷贝给一个普通的6乘6步长为2的卷积的呢?
代码是相当简单,就4行拷贝操作,接下来分步讲解
focus = Focus(3, 64, k=3).eval()
conv = Conv(3, 64, k=6, s=2, p=2).eval()
# Express focus layer as conv layer
conv.bn = focus.conv.bn
conv.conv.weight.data[:, :, ::2, ::2] = focus.conv.conv.weight.data[:, :3]
conv.conv.weight.data[:, :, 1::2, ::2] = focus.conv.conv.weight.data[:, 3:6]
conv.conv.weight.data[:, :, ::2, 1::2] = focus.conv.conv.weight.data[:, 6:9]
conv.conv.weight.data[:, :, 1::2, 1::2] = focus.conv.conv.weight.data[:, 9:12]1.focus的卷积层参数是啥样子的?
先直接print一下
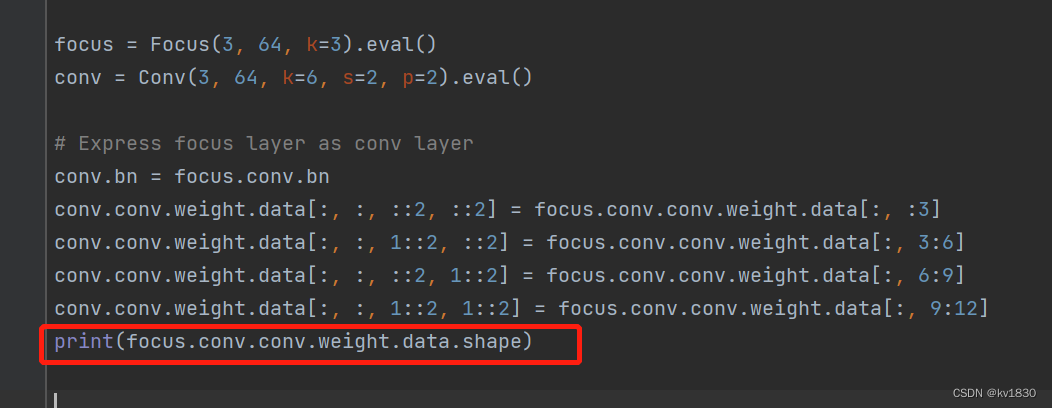
 卷积的原理在这里就不讲的太详细了,只简单复习一下,64对应输出通道数,12对应的是输入通道数,focus的输入输出通道数在前面已经分析过了,这边输出64是因为我们的测试代码写的就是64。输入通道为12。
卷积的原理在这里就不讲的太详细了,只简单复习一下,64对应输出通道数,12对应的是输入通道数,focus的输入输出通道数在前面已经分析过了,这边输出64是因为我们的测试代码写的就是64。输入通道为12。
首先最后面两个3、3,代表3乘3的卷积核,然后输入通道12,所以肯定得有12个卷积核,然后输出通道64,那么你就得有64乘12个卷积核,所以整个卷积层参数的形状就是64,12,3,3了
如果卷积的基本概念不熟悉的话,建议有2:
(1)看<<深度学习入门:基于Python的理论与实现>>里的讲解,非常详细,不过关于卷积的底层实现据李沐大神说已经不再是矩阵乘法了,这个我也得去学习学习~~
(2)看李沐大神的d2l,《动手学深度学习》 — 动手学深度学习 2.0.0 documentation
接下来继续分析,再看一下那个6乘6步长2的卷积,它的参数是啥样的呢

两者的输出通道自然是完全一样的,区别就在于输入通道和卷积层的大小。所以我们需要关心的就是64组卷积核里面的一组就行了,即对于focus来说,一组就是12个3乘3的卷积核,对于6乘6来说就是3个6乘6的卷积核。
2.两者的卷积过程对比
focus的卷积层的输入是12、320、320的图像,把图再贴出如下

12个3乘3的卷积如下,这12个卷积核与输入图像的12个通道是对应的,各卷各的,互不相干哦。这边也按4组分了颜色,下面就知道有啥用了
6乘6步长为2的卷积的输入就是原图,即3、640、640的图,也再贴出如下

3个6乘6的卷积核如下,注意是步长为2的卷积哦。首先这里也是3个卷积核跟图像中3个对应的通道卷,各卷各的,互不相干。其次,由于步长为2,卷积核中粉色部分只会去跟图像中的粉色部分卷,绝对不会跟绿色、蓝色、红色卷。同理绿色只跟绿色卷、蓝只跟蓝、红只跟红。
(这里稍微啰嗦一句,完整地说,是对应通道的粉只跟对应通道的粉。。。,用12种颜色更不容易混淆,但是不易展示,所以这里只用了4种颜色。下面的规则都是有“对应通道”这个前提的哦)

那我们再翻到上面去看一下focus的,它也是粉只跟粉、绿只跟绿、蓝只跟蓝、红只跟红!那如果我把focus的12个卷积核合并成3个,把12个通道的输入图还原成3通道的输入图,并且还是按照“粉只跟粉、绿只跟绿、蓝只跟蓝、红只跟红”的原则来卷的话,那计算过程是不是完全等价?那肯定是等价的。而6乘6步长2的卷积就可以做到这一点,我把它们合到一张图里,就看出来了。

所以两者的卷积过程是等价的!这个卷积参数的拷贝代码跟上图右边的图示是对应的。
四。反向传播也是等价的吗?
上面已经详解了正向传播的计算过程确实是等价的,但我不禁要问一下,它们的反向传播也是等价的吗?
肯定是等价的啦,因为卷积层的梯度就是由它的输入决定的,卷积不就是乘法和加法运算麻,咱乘的东西、加的东西都一样(前面说了运算过程完全等价啊),那梯度当然是一样的,这里就不详述梯度的计算公式了。直接用代码验证一下。
import torch
from models.common import Focus, Conv
from copy import deepcopy
focus = Focus(3, 64, k=3).train()
focus2 = deepcopy(focus).train()
conv = Conv(3, 64, k=6, s=2, p=2).train()
# Express focus layer as conv layer
conv.bn = deepcopy(focus.conv.bn)
conv.conv.weight.data[:, :, ::2, ::2] = deepcopy(focus.conv.conv.weight.data[:, :3])
conv.conv.weight.data[:, :, 1::2, ::2] = deepcopy(focus.conv.conv.weight.data[:, 3:6])
conv.conv.weight.data[:, :, ::2, 1::2] = deepcopy(focus.conv.conv.weight.data[:, 6:9])
conv.conv.weight.data[:, :, 1::2, 1::2] = deepcopy(focus.conv.conv.weight.data[:, 9:12])
# Compare
x = torch.randn(16, 3, 640, 640, requires_grad=False)
with torch.no_grad():
# Results are not perfectly identical, errors up to about 1e-7 occur (probably numerical)
assert torch.allclose(focus(x), conv(x), atol=1e-6)
label = torch.randn(16, 64, 320, 320, requires_grad=False)
optimizer1 = torch.optim.SGD(focus.parameters(), lr=0.001, momentum=0.9, nesterov=True)
# optimizer1 = smart_optimizer(focus, 'SGD')
optimizer1.zero_grad()
loss1 = torch.mean(focus(x) - label) # 要想计算loss,得有个标量输出,所以这里mean了一下。注意,你要是用sum,就会导致误差变大,最终梯度就不等了哦
loss1.backward()
optimizer1.step()
optimizer2 = torch.optim.SGD(conv.parameters(), lr=0.001, momentum=0.9, nesterov=True)
optimizer2.zero_grad()
loss2 = torch.mean(conv(x) - label) # 同上
loss2.backward()
optimizer2.step()
print(f'loss1: {loss1.item():.10f}, loss2: {loss2.item():.10f}')
equivalent_grad = torch.zeros(64, 3, 6, 6, dtype=torch.float32)
equivalent_grad[:, :, ::2, ::2] = deepcopy(focus.conv.conv.weight.grad[:, :3])
equivalent_grad[:, :, 1::2, ::2] = deepcopy(focus.conv.conv.weight.grad[:, 3:6])
equivalent_grad[:, :, ::2, 1::2] = deepcopy(focus.conv.conv.weight.grad[:, 6:9])
equivalent_grad[:, :, 1::2, 1::2] = deepcopy(focus.conv.conv.weight.grad[:, 9:12])
assert torch.allclose(equivalent_grad, conv.conv.weight.grad, atol=1e-6)
print('梯度也是等的哦')
运行结果如下,梯度也是相等的!

注意梯度在比的时候,也得搞成相同的形状才能比,所以跟那个卷积层参数的拷贝方法是一样的,只不过我们这里是把focus卷积层的梯度拷贝到一个跟6乘6卷积的梯度相同形状的张量里,然后跟6乘6卷积的梯度进行比较。
等等,卷积层的梯度是啥形状的?卷积层的参数是啥形状,梯度就是啥形状啊!
五。说这么多有啥用?
1.顺便加深一下对卷积的认识
2.对于一些比较老版本的yolo代码和模型,用到了focus层的,比如yolox就用了focus,而且还一直都没改,你如果想部署端侧模型,比如转为ncnn格式,按照官方的方案,你得自己用c++去注册一个自定义层,在里面实现focus的切片操作,而且要手动修改.param文件,还是很麻烦的。但是看了本贴,你就可以非常自信地用本贴中的方法把focus层直接改为等价的6乘6步长2的卷积层,参数直接拷贝过来,完美!