*免责声明:
1此方法仅提供参考
2搬了其他博主的操作方法,以贴上路径.
3*
场景一:Anconda环境基本操作
场景二:yolov5的使用
场景三:yolo v5训练自己的数据集
场景四:yolov5源码解读
…
场景一:Anconda环境基本操作
1:基本命令
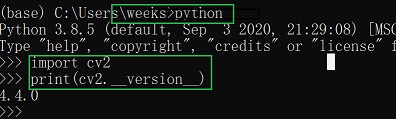
查看Anaconda的版本信息 conda -V
查看python版本信息 python
打开Jupyter Notebook命令 jupyter notebook 或者 ipython notebook
退出python输入环境: ctrl+z
命令行终止正在运行的程序命令 : ctrl + c
查看 opencv版本信息:
2:创建使用自己的虚拟环境
生成一个名叫 jiance的环境,用来进行做识别任务:
conda create -n jiance python=3.7
进入这个环境,也就是激活这个环境
source activate jiance windows下: activate jiance
接下来就是 在这个环境中可以下载你所需要的包 pip insatll numpy 或者是conda install numpy=1.10
退出这个环境 :source deactivate
查看创建了哪些环境:conda info --envs
查看创建了包:conda list
退出这个jiance环境: linux 下source deactivate windows下 deactivate
3:删除包 、删除环境 或者更新包
删除numpy 包:conda remove numpy 或者指定 conda remove numpy=1.10
更新numpy包: conda update numpy
更新jiance里面所有包: conda update - -all
搜索numpy包: conda search numpy
删除jiance这个环境的命令: conda env remove -n jiance
4: 共享环境
例如我现在的jiance这个环境好多包我下载了,配好了识别的环境,别人想用我的环境或者是我想快速把项目从我的电脑上移植到其他电脑上:
首先进入我的环境: activate jiance 执行这条语句conda env export > 名字.yaml
例如 conda env export > environment.yaml
命令的第一部分 conda env export 用于输出环境中的所有包的名称
通过后半部分environment.yaml将其保存到并命名为“environment.yaml”

别人需要做的是拿到这个yaml文件: conda env create -f environment.yaml
场景二:yolov5的使用
1:安装pytorch (windows无GPU)环境
切换到上面的jiance的环境中
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly
2:下载yolo v5
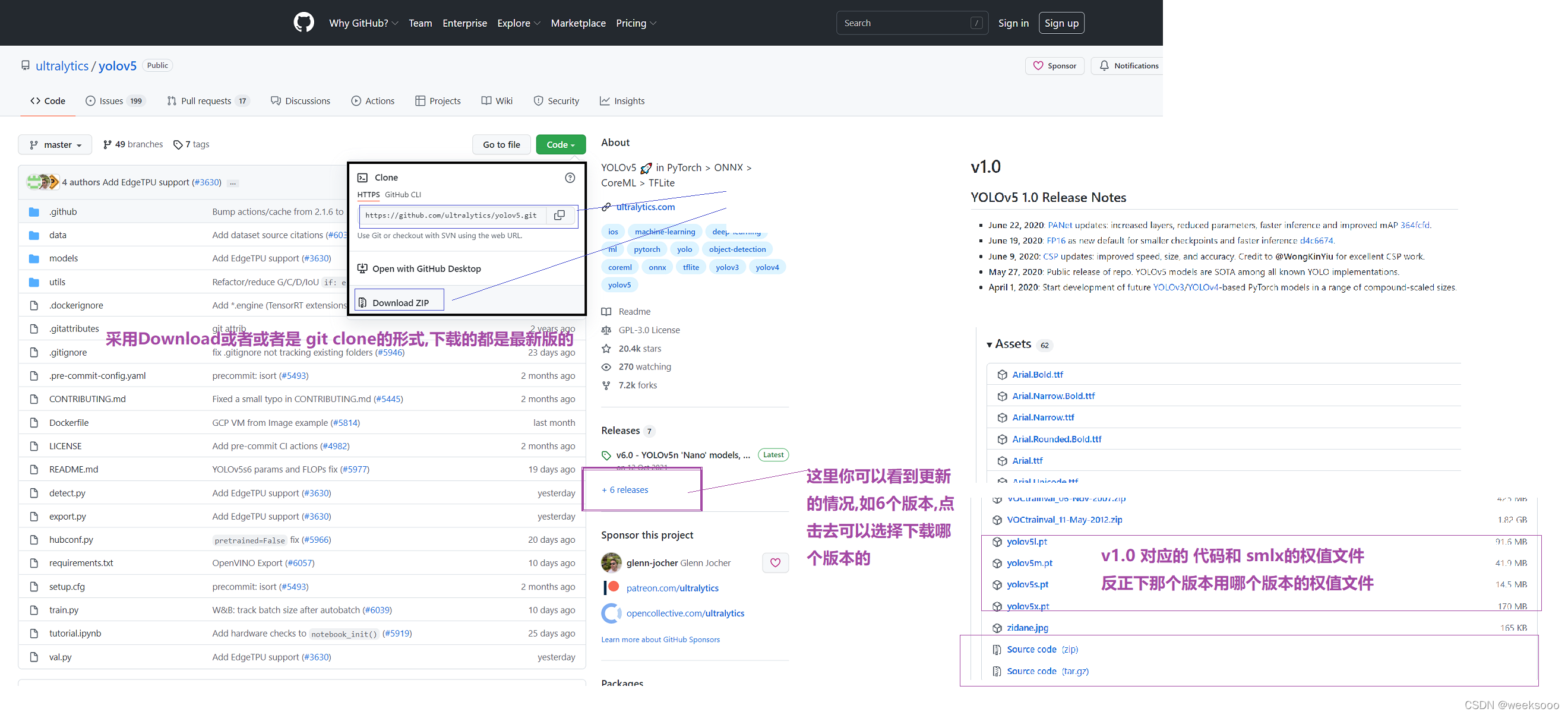
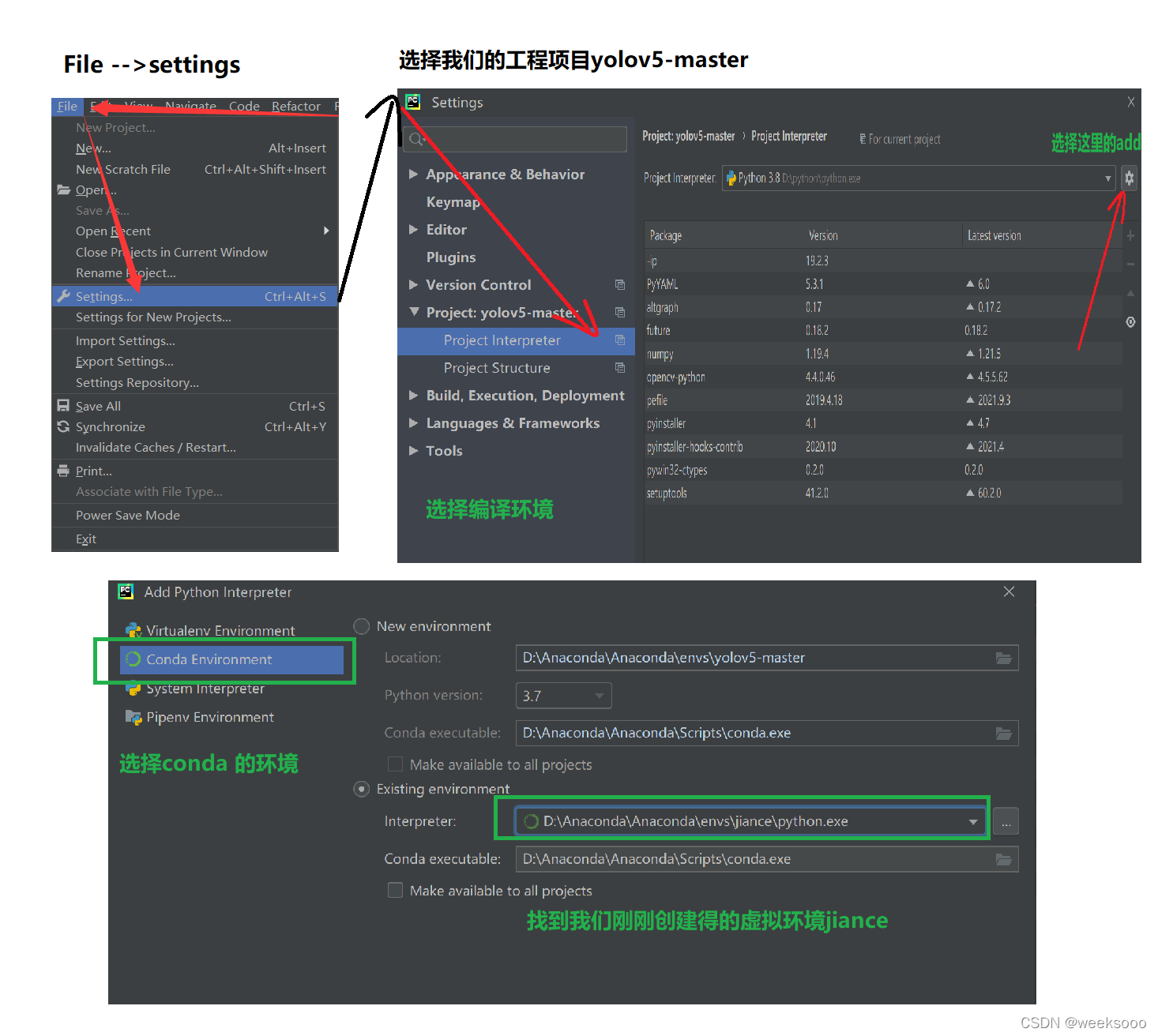
3: 将下载好的项目进行解压,用pycharm打开,然后将项目关联我们在Anconda中创建好的虚拟环境
4.下载依赖
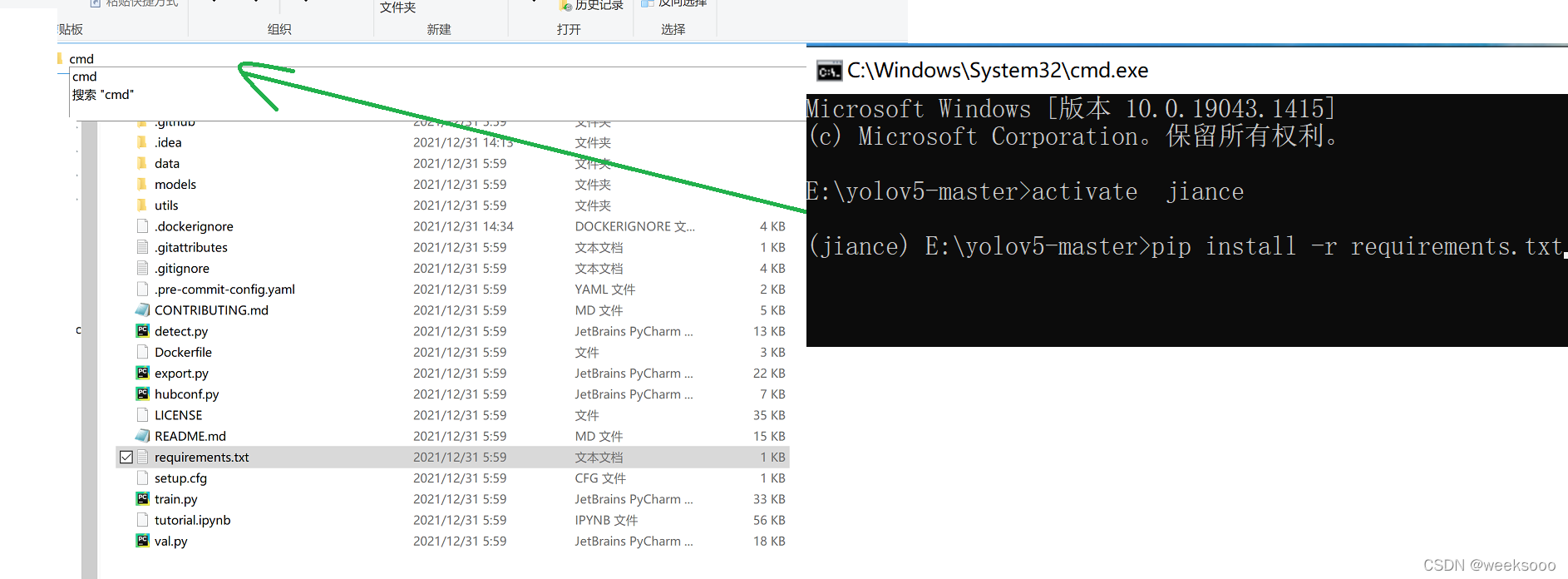
方式一:在pycharm终端中执行 pip install -r requirements.txt
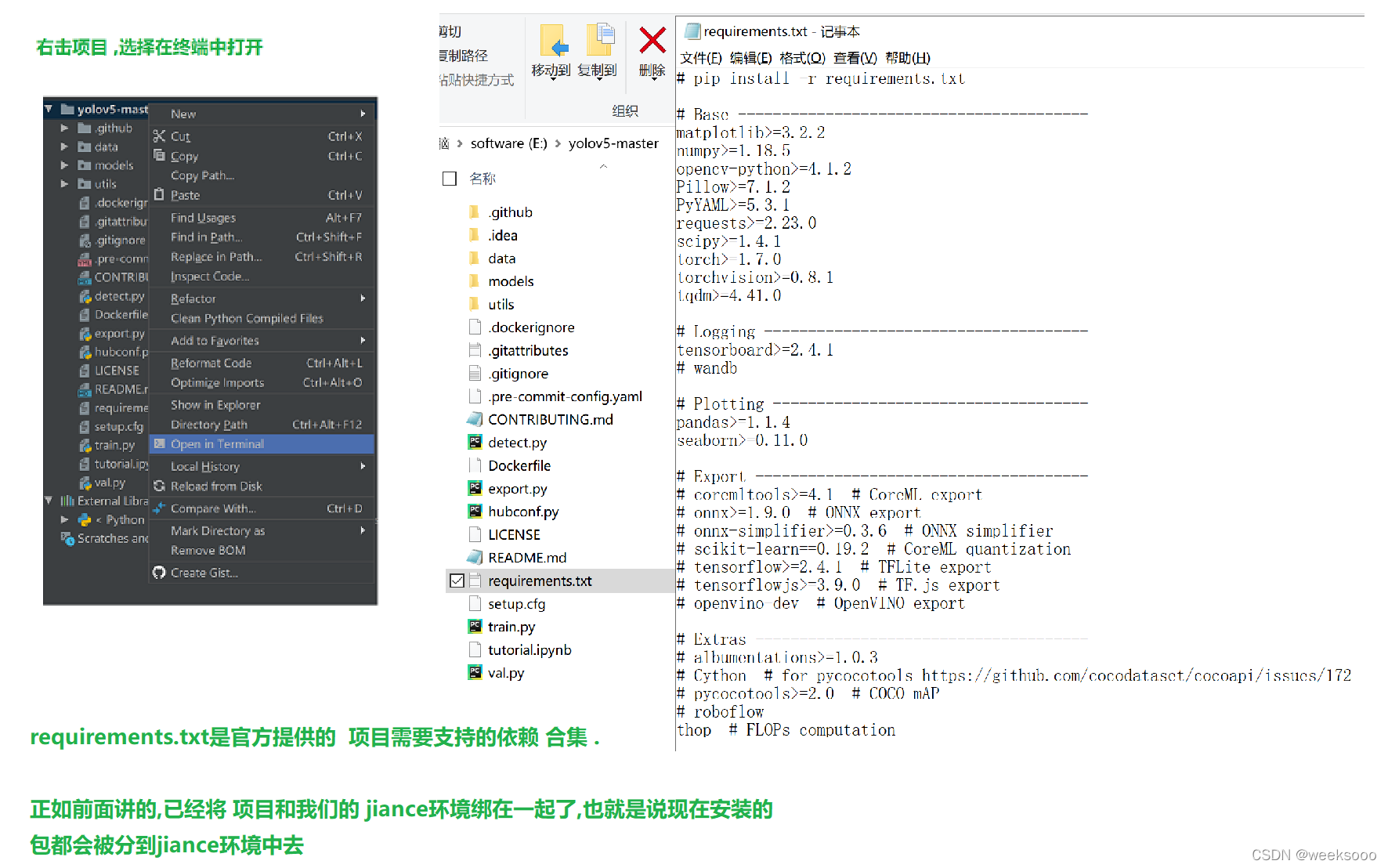
方式二:在项目文件夹中的最上方输入cmd 就可以在windows终端打开到该项目文件夹下 ,切换到虚拟环境 activate jiance 然后再输入命令 pip install -r requirements.txt
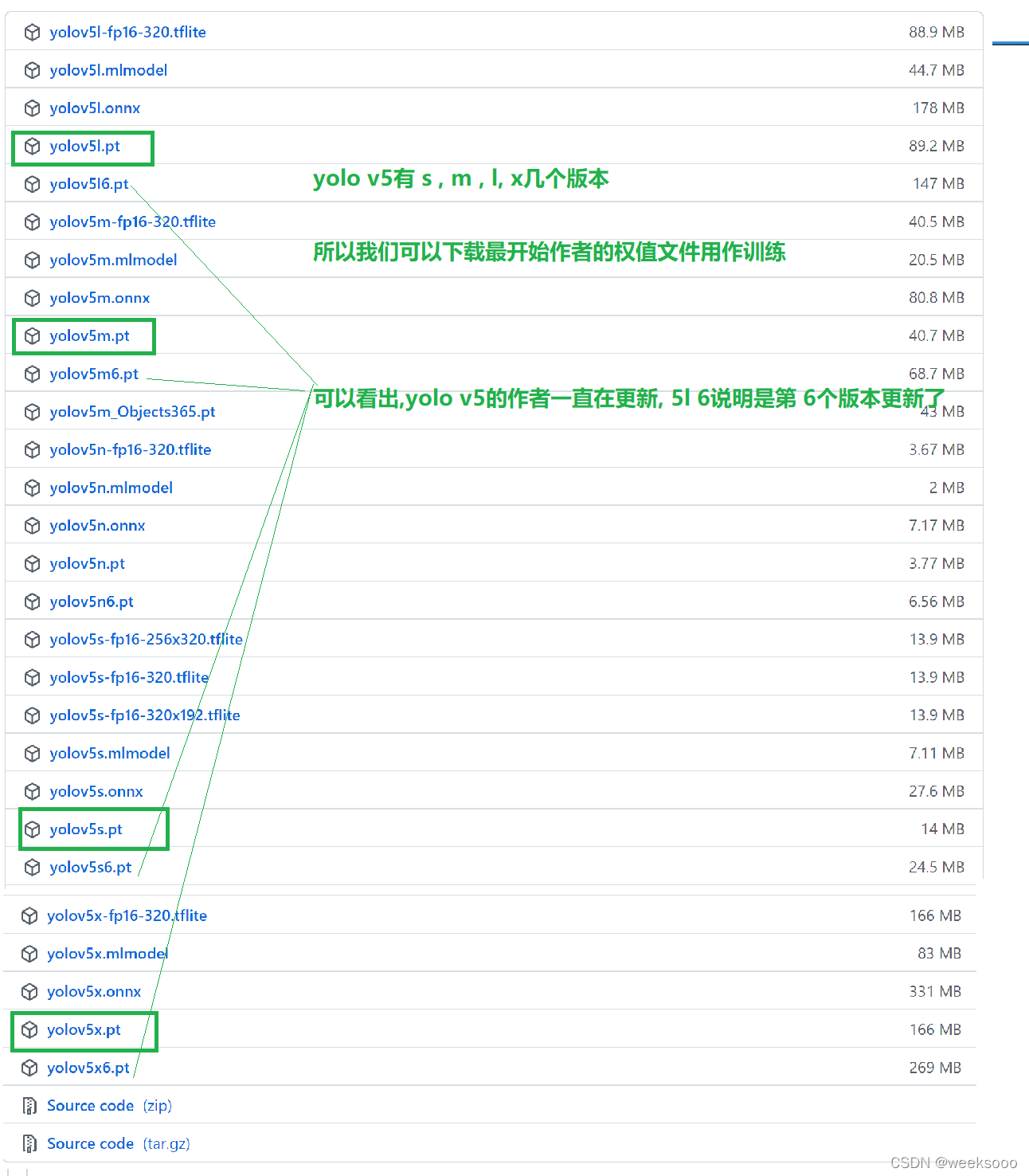
5: 下载权值文件

测试
命令中的路径 可以灵活改动,yolo v5的版本现在有6个版本的更新,每个版本的目录结构可能不一样,例如bus.jpg在v1版本是inference文件夹下,在v6版本是在data文件夹下,下面的命令是v6版本的(只不过是路径不一样而已)

测试图片
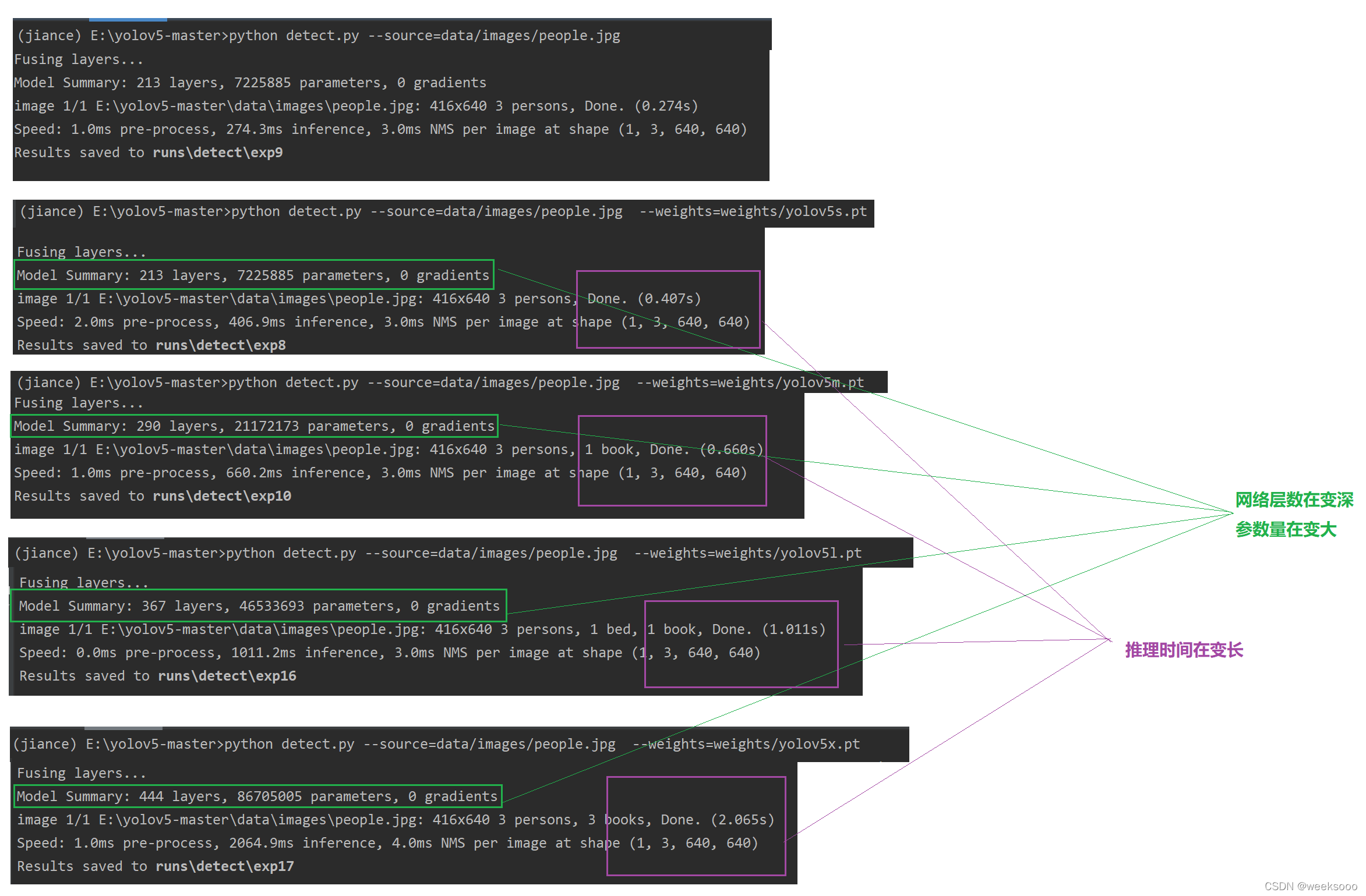
python detect.py --source=data/images/bus.jpg
python detect.py --source=data/images/people.jpg --weights=weights/yolov5s.pt
置信度超过0.4显示出来
python detect.py --source=data/images/people.jpg --weights=weights/yolov5s.pt --conf 0.4

测试视频
python detect.py --source=data/images/1.mp4 --weights=weights/yolov5s.pt
摄像头
python detect.py --source 0
python detect.py --source 0 --weights=weights/yolov5s.pt
模型集成检测
python detect.py --source=data/images/people.jpg --weights=weights/yolov5s.pt yolov5l.pt
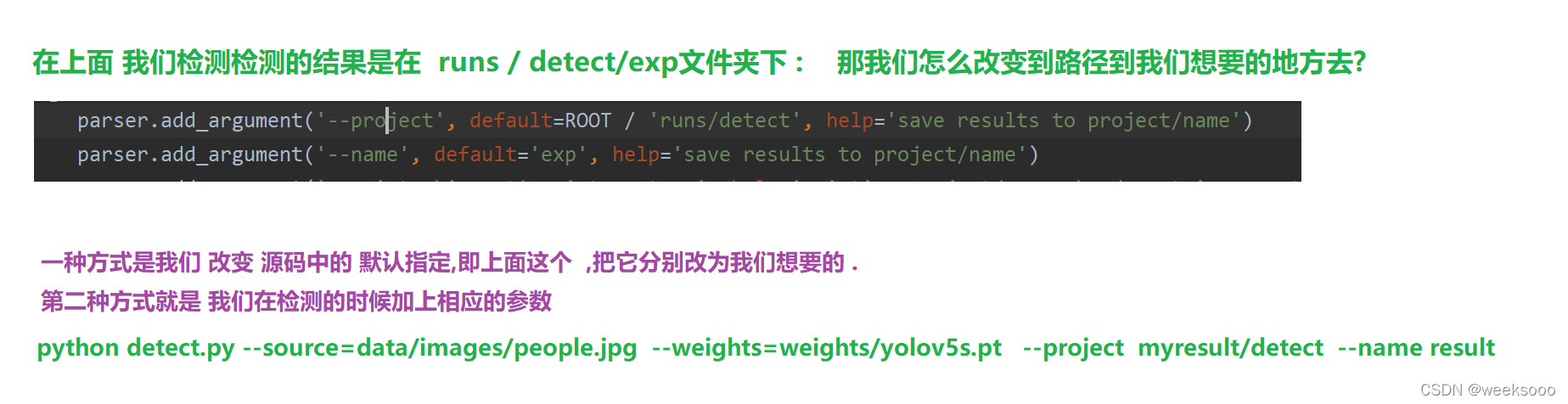
更改测试保存路径
…
场景三:yolo v5训练自己的数据集


1.1 训练技巧
目标检测 YOLOv5 anchor设置
yolov5 anchors设置详解
【Python】计算VOC格式XML文件中目标面积和长宽比并生成直方图


记得放在jyputer上计算方便保存和看结果
# -*- coding: utf-8 -*-
"""
Created on Sun Jan 10 21:48:48 2021
@author: YaoYee
"""
import os
import xml.etree.cElementTree as et
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import cv2
path = ".......................Annotations" #你的路径
files = os.listdir(path)
area_list = []
ratio_list = []
def file_extension(path):
return os.path.splitext(path)[1]
for xmlFile in tqdm(files, desc='Processing'):
if not os.path.isdir(xmlFile):
if file_extension(xmlFile) == '.xml':
tree = et.parse(os.path.join(path, xmlFile))
root = tree.getroot()
filename = root.find('filename').text
# print("--Filename is", xmlFile)
for Object in root.findall('object'):
bndbox = Object.find('bndbox')
xmin = bndbox.find('xmin').text
ymin = bndbox.find('ymin').text
xmax = bndbox.find('xmax').text
ymax = bndbox.find('ymax').text
area = (int(ymax) - int(ymin)) * (int(xmax) - int(xmin))
area_list.append(area)
# print("Area is", area)
ratio = (int(ymax) - int(ymin)) / (int(xmax) - int(xmin))
ratio_list.append(ratio)
# print("Ratio is", round(ratio,2))
square_array = np.array(area_list)
square_max = np.max(square_array)
square_min = np.min(square_array)
square_mean = np.mean(square_array)
square_var = np.var(square_array)
plt.figure(1)
plt.hist(square_array, 20)
plt.xlabel('Area in pixel')
plt.ylabel('Frequency of area')
plt.title('Area
'
+ 'max=' + str(square_max) + ', min=' + str(square_min) + '
'
+ 'mean=' + str(int(square_mean)) + ', var=' + str(int(square_var))
)
plt.savefig('aabb1.jpg')
ratio_array = np.array(ratio_list)
ratio_max = np.max(ratio_array)
ratio_min = np.min(ratio_array)
ratio_mean = np.mean(ratio_array)
ratio_var = np.var(ratio_array)
plt.figure(2)
plt.hist(ratio_array, 20)
plt.xlabel('Ratio of length / width')
plt.ylabel('Frequency of ratio')
plt.title('Ratio
'
+ 'max=' + str(round(ratio_max, 2)) + ', min=' + str(round(ratio_min, 2)) + '
'
+ 'mean=' + str(round(ratio_mean, 2)) + ', var=' + str(round(ratio_var, 2))
)
plt.savefig('aabb.jpg')
先统计宽高比 , 然后在 yolov5 程序中创建一个新的 python 文件 test.py, 手动计算锚定框:
import utils.autoanchor as autoAC
# 对数据集重新计算 anchors
new_anchors = autoAC.kmean_anchors('./data/mydata.yaml', 9, 640, 5.0, 1000, True)
print(new_anchors)
输出的 9 组新的锚定框即是根据自己的数据集来计算的,可以按照顺序替换到你所使用的配置文件*.yaml中(比如 yolov5s.yaml) , 就可以重新训练了。
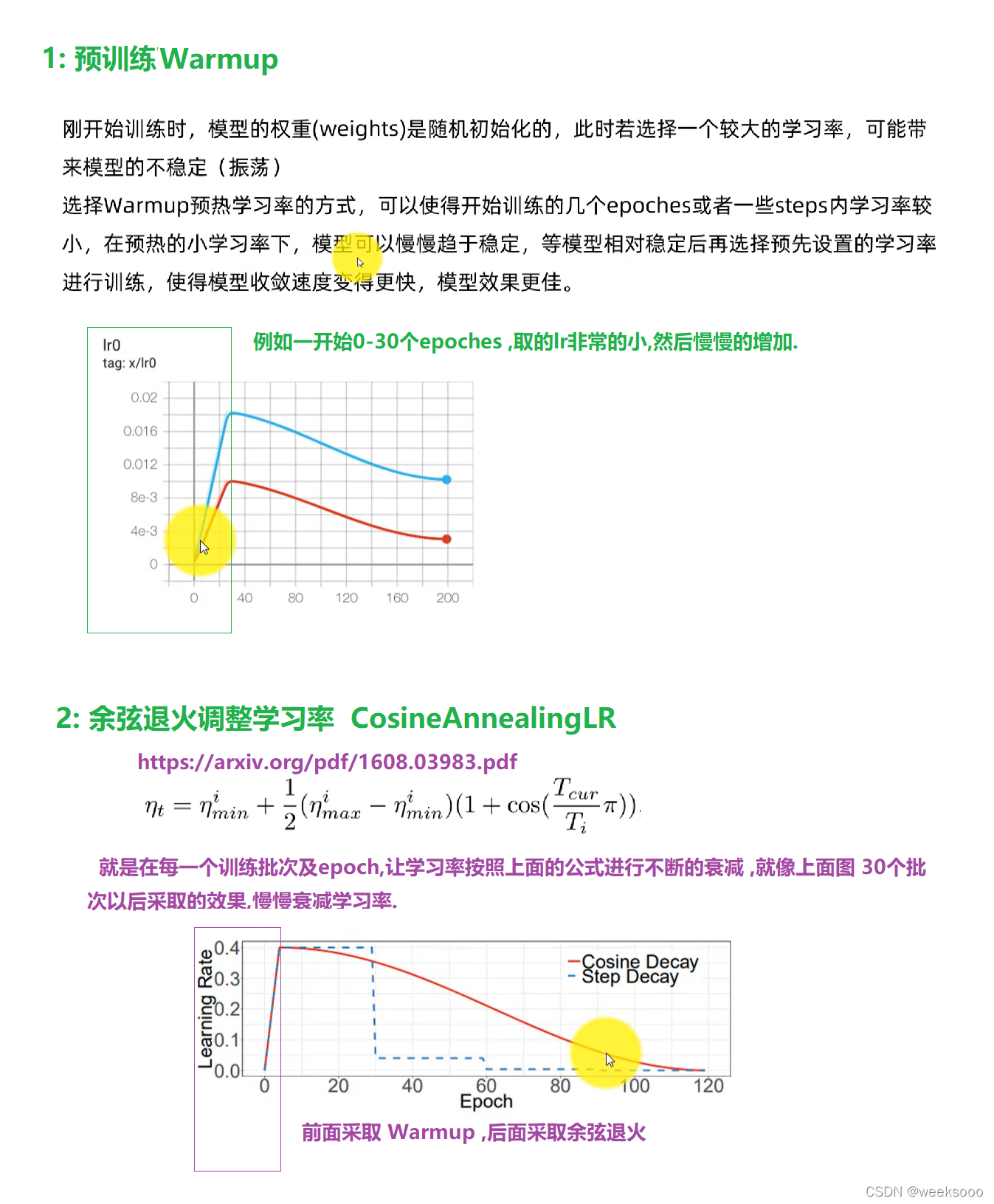


超参数进化 Hyperparameter Evolution

python train.py --resume
在训练时 , 当你的图片的尺寸假如是 320x256,你想让模型的输入也是 320x256.那么你只需要加
--img 320 --rect
1.2训练自己的数据集
第一步:使用labelImg标注自己的数据集
不要有中文路径
训练思路: yolov5支持两种训练方式:第一种直接将训练文件的路径写入txt文件传入。第二种直接传入训练文件所在文件夹。训练v1.0的代码(其他版本一样,只不过v1.0代码可能比较容易出问题)
第二步:划分训练集/测试集
我们按照第二种方式:
.
新建如下几个文件夹,在yolov5下创建mydata文件夹,然后在mydata文件夹下.
all_images文件夹放图片
all_xml文件夹放xml文件
make_txt.py 文件用来划分数据集
train_val.py 文件夹用来转换 labels
注意两个py文件要建在mydata文件夹下

make_txt.py
import os
import random
#什么都不用改 ,只需要改下面的划分比例
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'all_images'
txtsavepath = 'ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv) #从所有list中返回tv个数量的项目
train = random.sample(trainval, tr)
if not os.path.exists('ImageSets/'):
os.makedirs('ImageSets/')
ftrainval = open('ImageSets/trainval.txt', 'w')
ftest = open('ImageSets/test.txt', 'w')
ftrain = open('ImageSets/train.txt', 'w')
fval = open('ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '
'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
第三步: 接下来准备labels,也就是将voc格式转换为yolo格式
运行train_val.py,该文件一方面将all_xml中xml文件转为txt文件存于all_labels文件夹中,另一方面生成训练所需数据存放架构。(这里如果你的数据直接是txt的标签的话将标签转化的功能注释掉即可)代码如下:
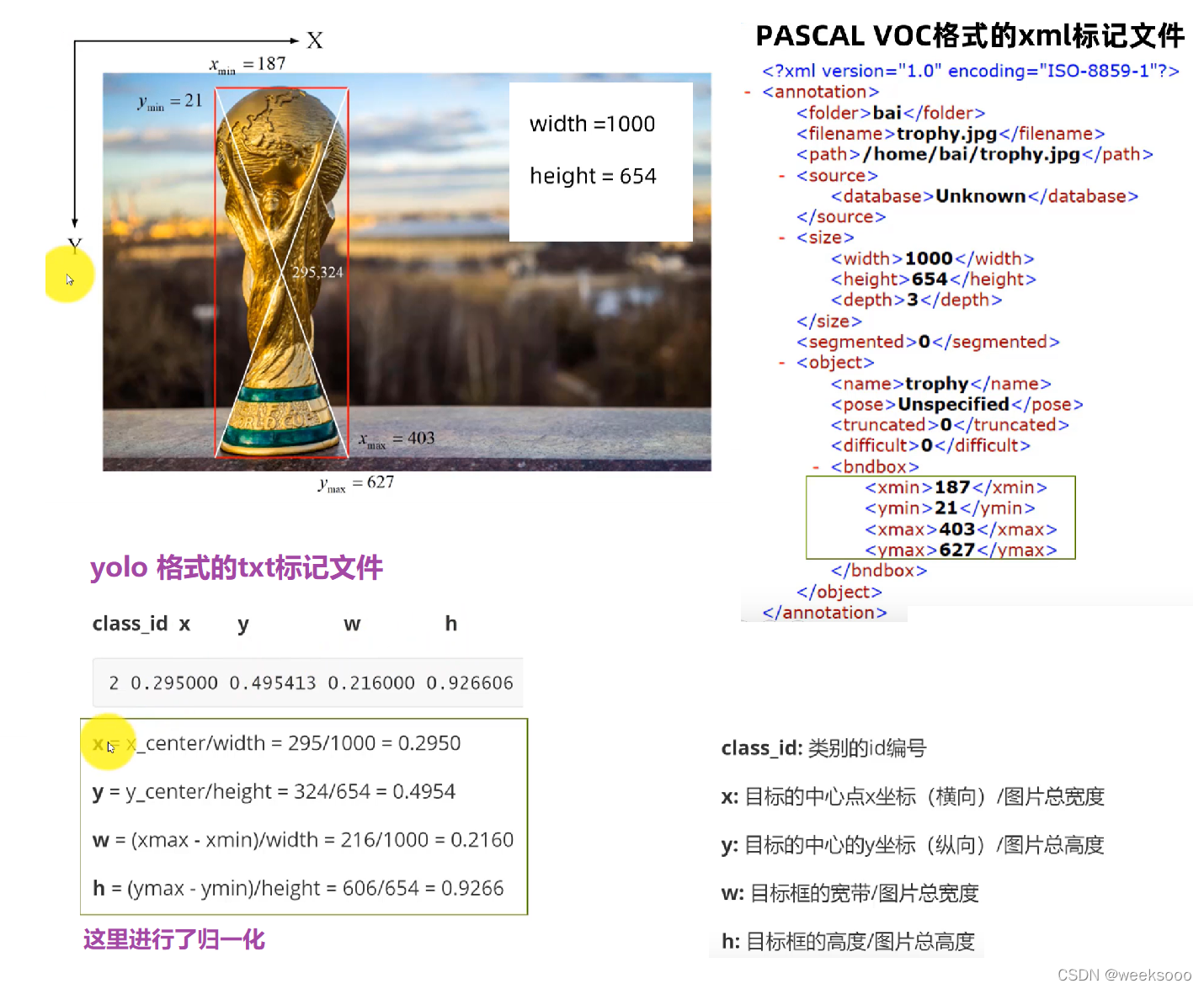
train_val.py
import xml.etree.ElementTree as ET
import pickle
import os
import shutil
from os import listdir, getcwd
from os.path import join
sets = ['train', 'trainval']
#改这里...............
classes = ['dog' , 'cat']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('all_xml/%s.xml' % (image_id))
out_file = open('all_labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '
')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('all_labels/'):
os.makedirs('all_labels/')
image_ids = open('ImageSets/%s.txt' % (image_set)).read().strip().split()
image_list_file = open('images_%s.txt' % (image_set), 'w')
labels_list_file=open('labels_%s.txt'%(image_set),'w')
for image_id in image_ids:
image_list_file.write('%s.jpg
' % (image_id))
labels_list_file.write('%s.txt
'%(image_id))
convert_annotation(image_id) #如果标签已经是txt格式,将此行注释掉,所有的txt存放到all_labels文件夹。
image_list_file.close()
labels_list_file.close()
def copy_file(new_path,path_txt,search_path):#参数1:存放新文件的位置 参数2:为上一步建立好的train,val训练数据的路径txt文件 参数3:为搜索的文件位置
if not os.path.exists(new_path):
os.makedirs(new_path)
with open(path_txt, 'r') as lines:
filenames_to_copy = set(line.rstrip() for line in lines)
# print('filenames_to_copy:',filenames_to_copy)
# print(len(filenames_to_copy))
for root, _, filenames in os.walk(search_path):
# print('root',root)
# print(_)
# print(filenames)
for filename in filenames:
if filename in filenames_to_copy:
shutil.copy(os.path.join(root, filename), new_path)
#按照划分好的训练文件的路径搜索目标,并将其复制到yolo格式下的新路径
copy_file('./images/train/','./images_train.txt','./all_images')
copy_file('./images/val/','./images_trainval.txt','./all_images')
copy_file('./labels/train/','./labels_train.txt','./all_labels')
copy_file('./labels/val/','./labels_trainval.txt','./all_labels')
第四步: 创建自己的yaml文件,可以copy一下 yolov5中data下的coco128.yaml
train: ./mydata/images/train/
val: ./mydata/images/val/
nc: 2
names: ['dog' ,'cat']
第五步: 修改网络模型的配置文件,修改models/yolov5s.yaml的内容,根据自己实际运行模型的参数需要选择一个.yaml进行修改,我选择的是yolov5s.yaml。
主要修改类别数nc的值 当然你也可以修改为自己的网络结构.
第六步: 训练
训练技巧在上面,当然也可以去train.py中修改对应属性的默认值.
python train.py --data coco.yaml(数据信息,一般也是指定我们自己的) --cfg yolov5s.yaml (网络结构信息,可以使用yolov5s的 ,也可以使用自己的) --weights '' (这里的weights就是指定要不要在别人的基础之上训练) --batch-size 64
训练v1存在的问题:
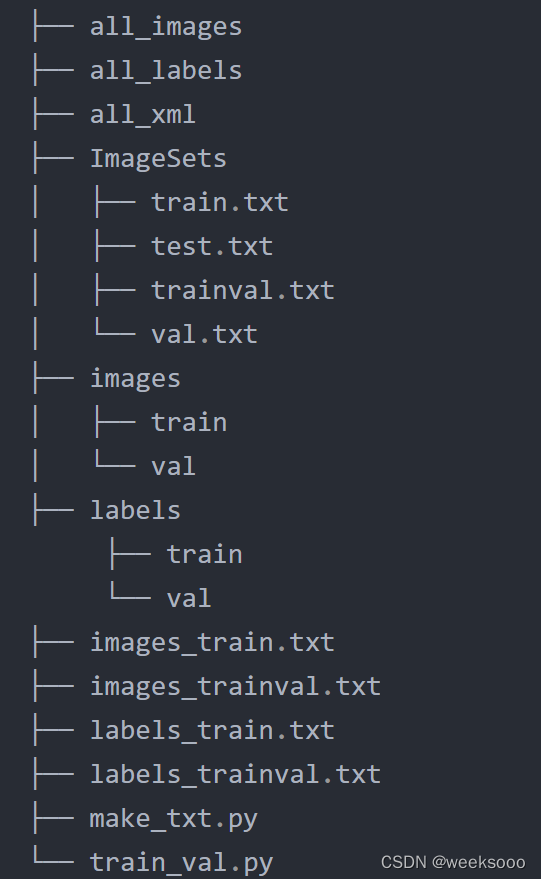
TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.直接点击报错提示文件
第二个问题: 找不到对应的label
No labels found in D:.B_yolov5_weeksyolov5_1.0mydataImages.
.
其实这个问题是因为我们制作labels的问题,也就是你去mydata文件夹下的lables文件夹去看有train和val文件夹来放对应的label,但是我的是空的.
.
其实我们生成了相应的lables,在mydata的同级目录会有多余的lables文件夹,
这个labels文件夹下的train和val文件夹是不为空的 , 替换掉mydata文件夹里面的labels文件夹
1.3 性能评估

验证模型
python val.py --data data/coco128.yaml --weights weighs/myyolo.pt --batch-size 6
训练过程可视化:
tensorboard --logdir ./runs
然后在浏览器端输入 http://localhsot:6006/#scalars 具体还是看上面的命令返回什么
…
场景四:yolov5源码解读

辅助文件
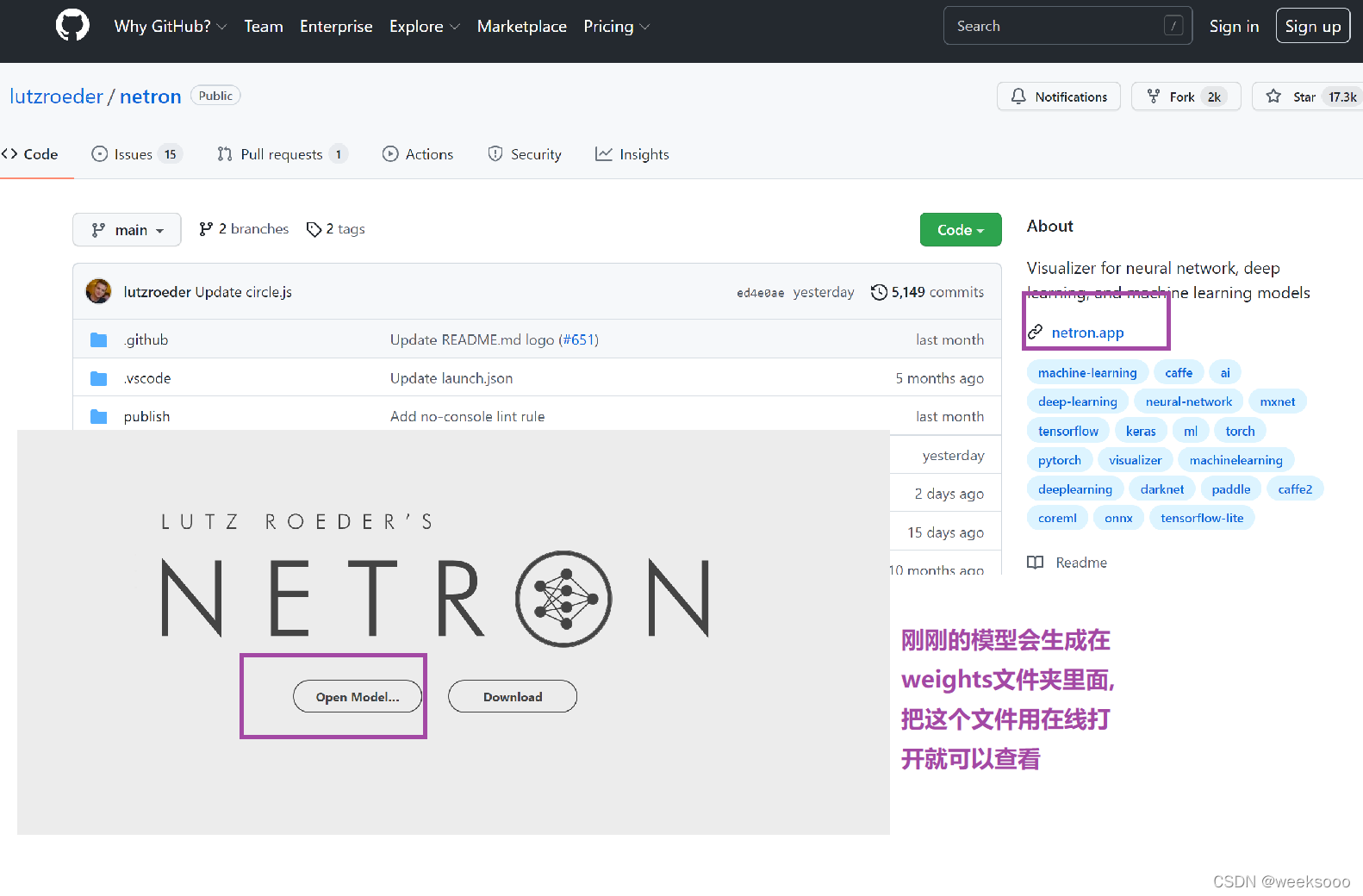
1: export.py —>模型转换为onnx文件

# netron对pt文件兼容性不好 , 这个文件的作用是把pt的权重文件转换为 onnx格式,方便在netron等工具中查看
#后面 -i 加网址是为了从清华镜像获取,更快
# 命令 pip install onnx>=1.7.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install coremltools==4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 转换命令: python export.py --weights weights/yolov5s.pt --img 640 --batch 1
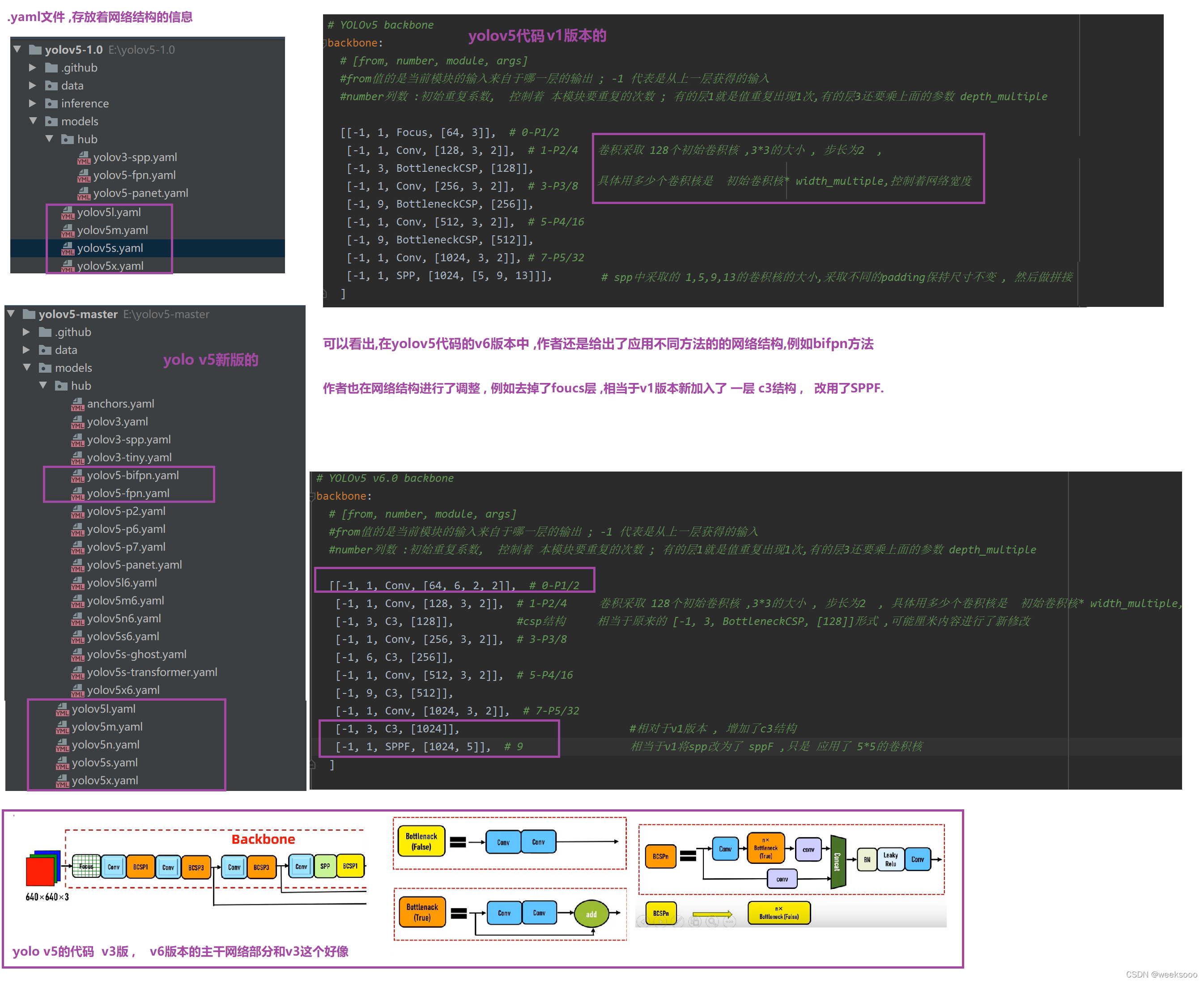
2.yolov5s.yaml—>网络结构文件

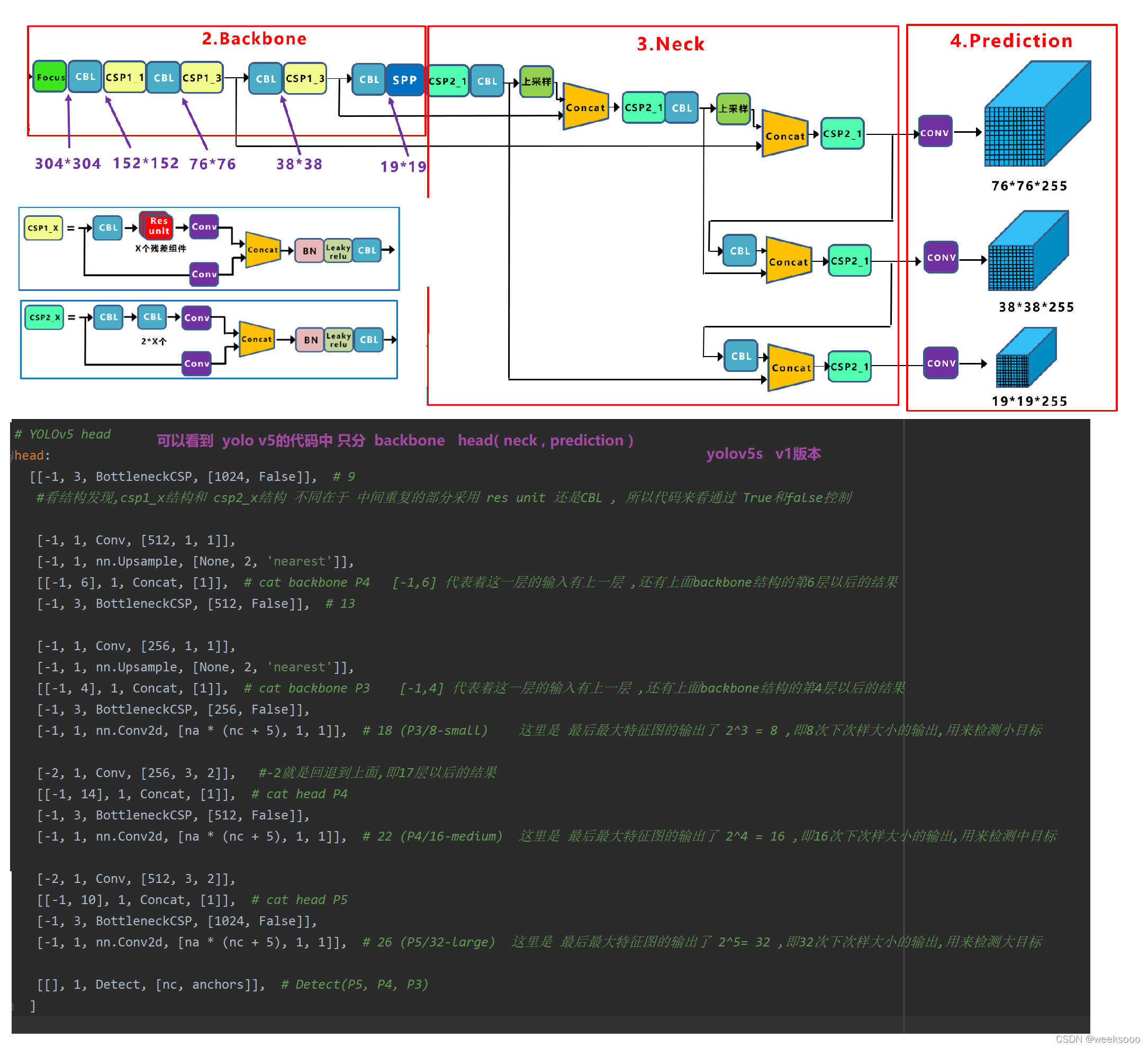

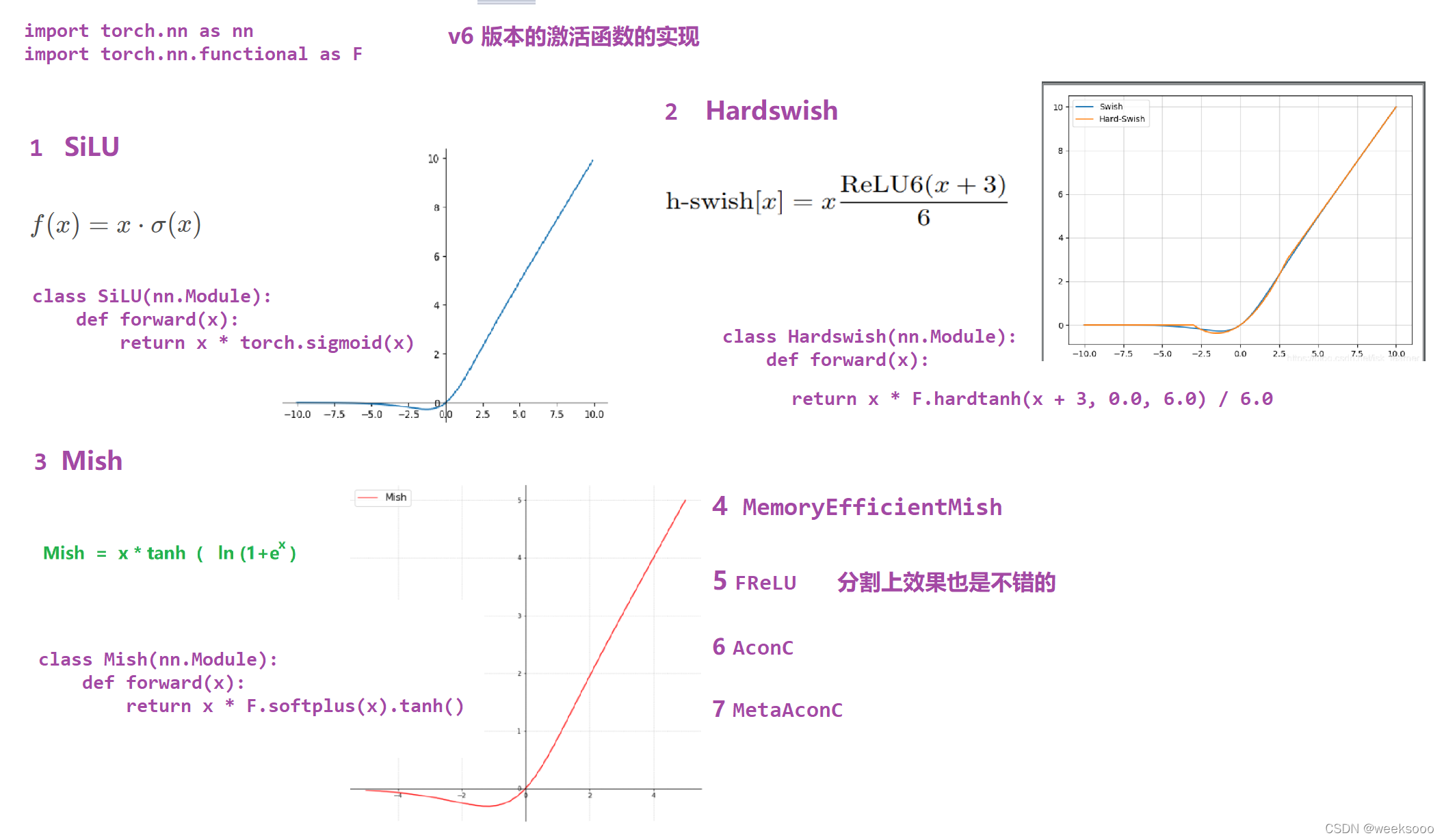
3. 模型构建代码 activations.py–>激活函数定义文件
激活函数定义代码
4 模型构建代码 common.py—>网络组件代码
这个文件定义好多网络组件的实现形式,有的如下。
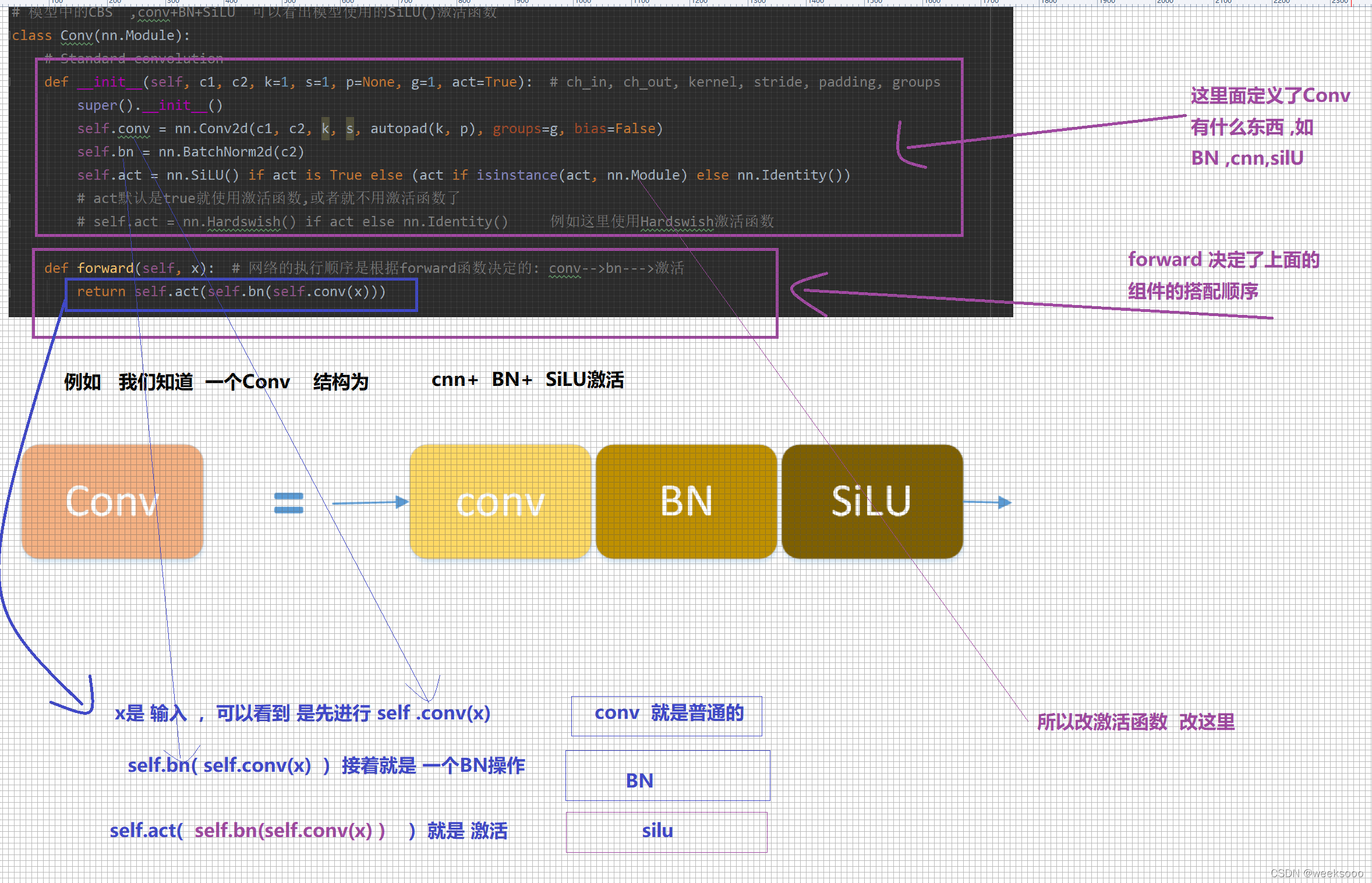
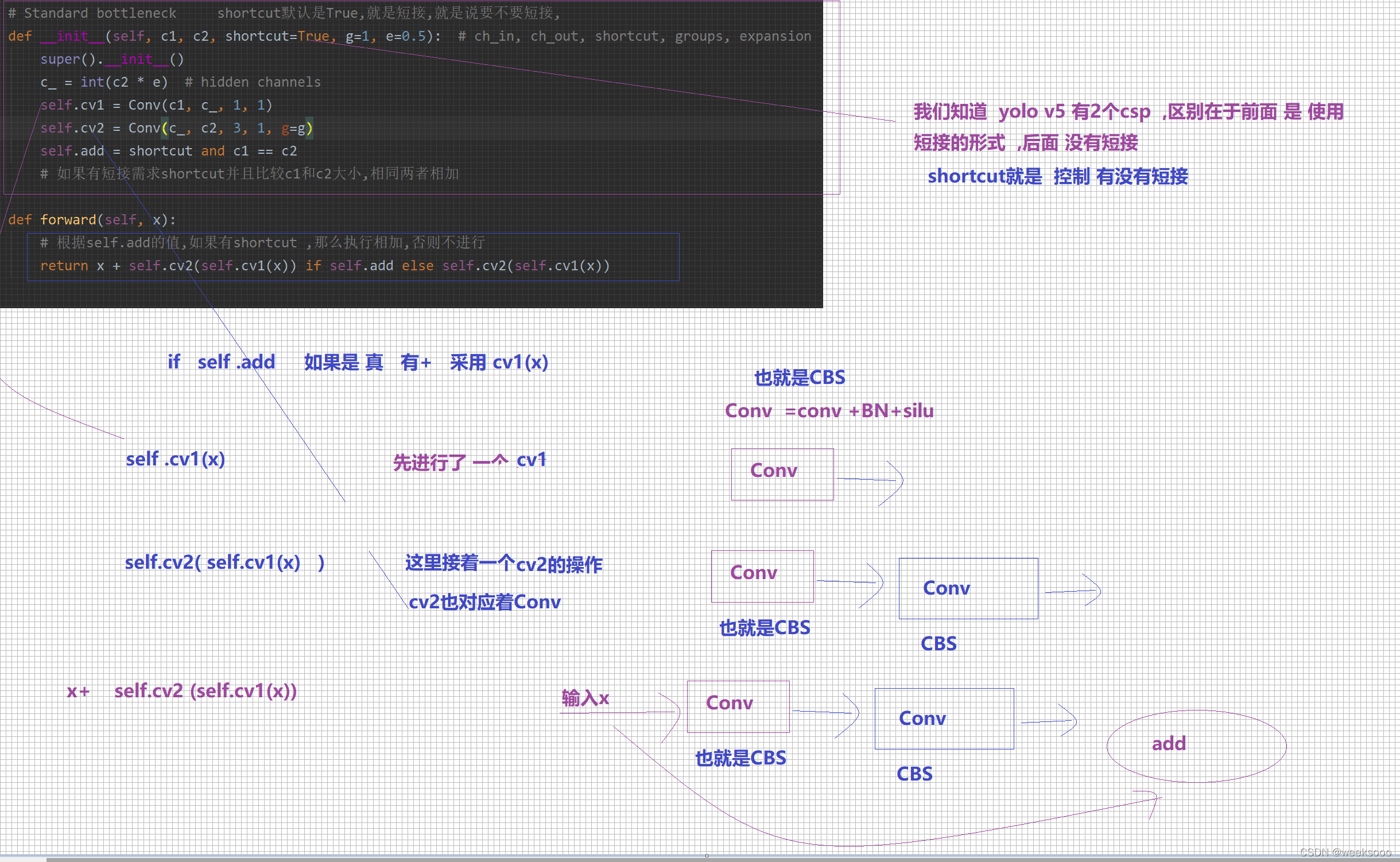
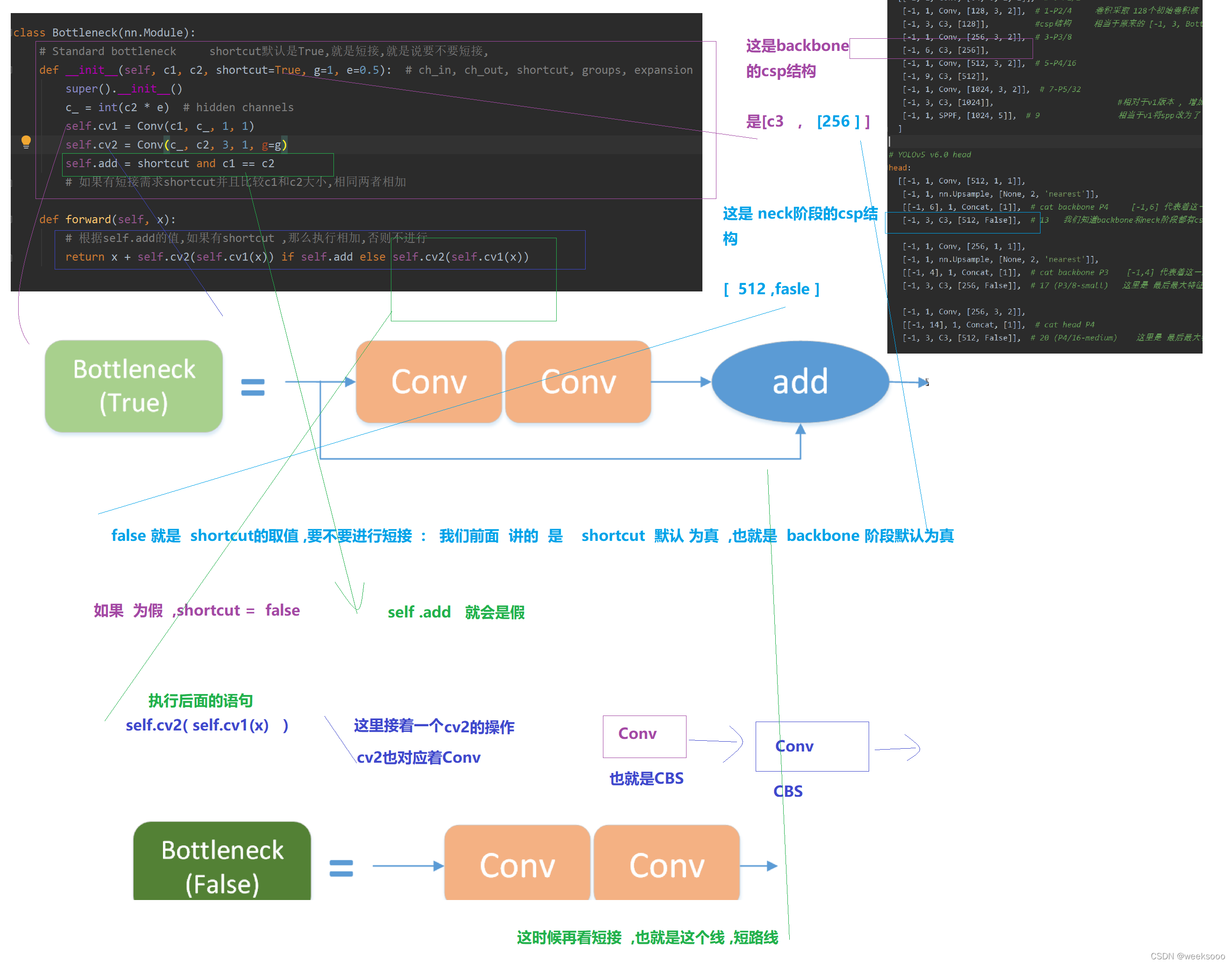
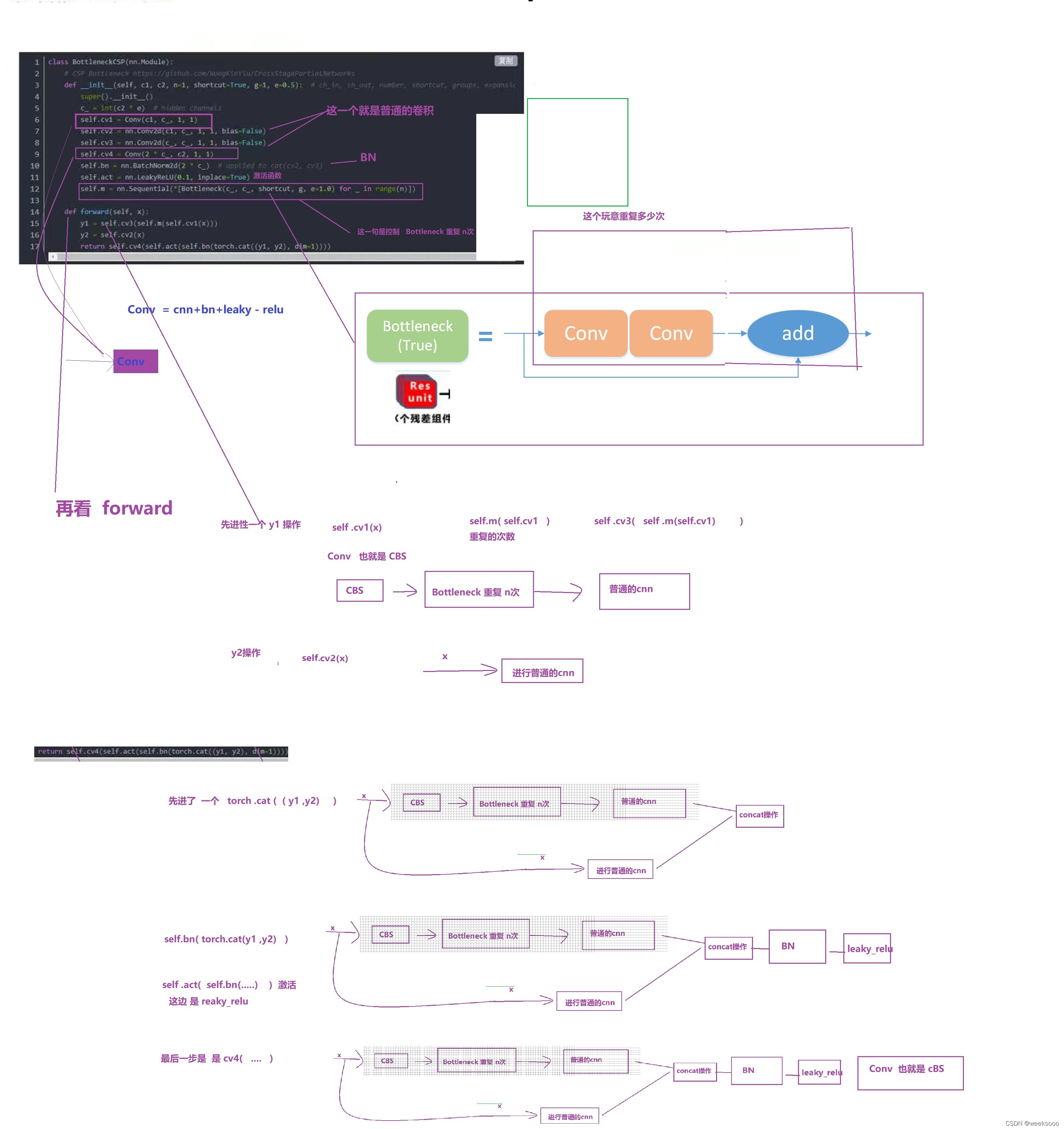
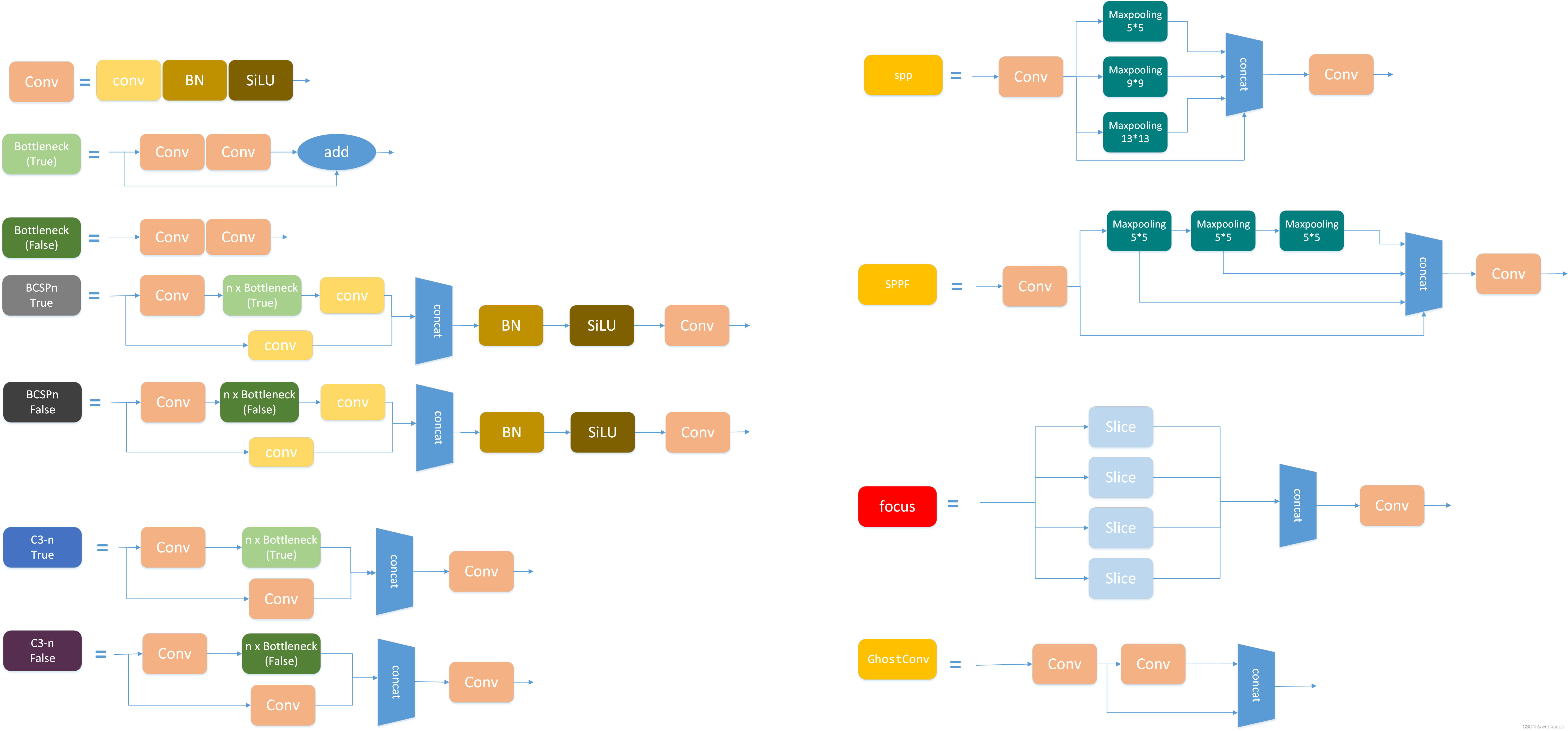
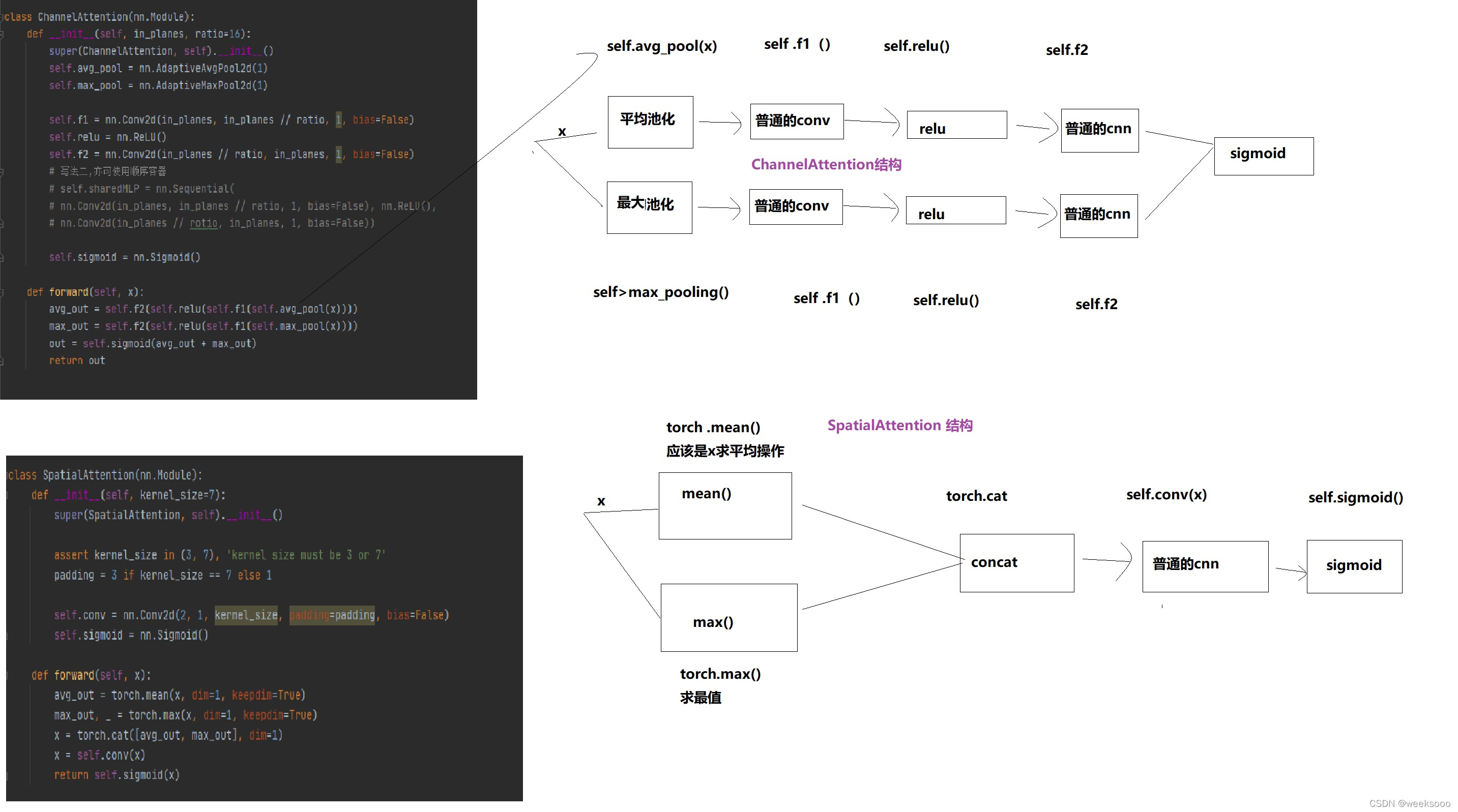
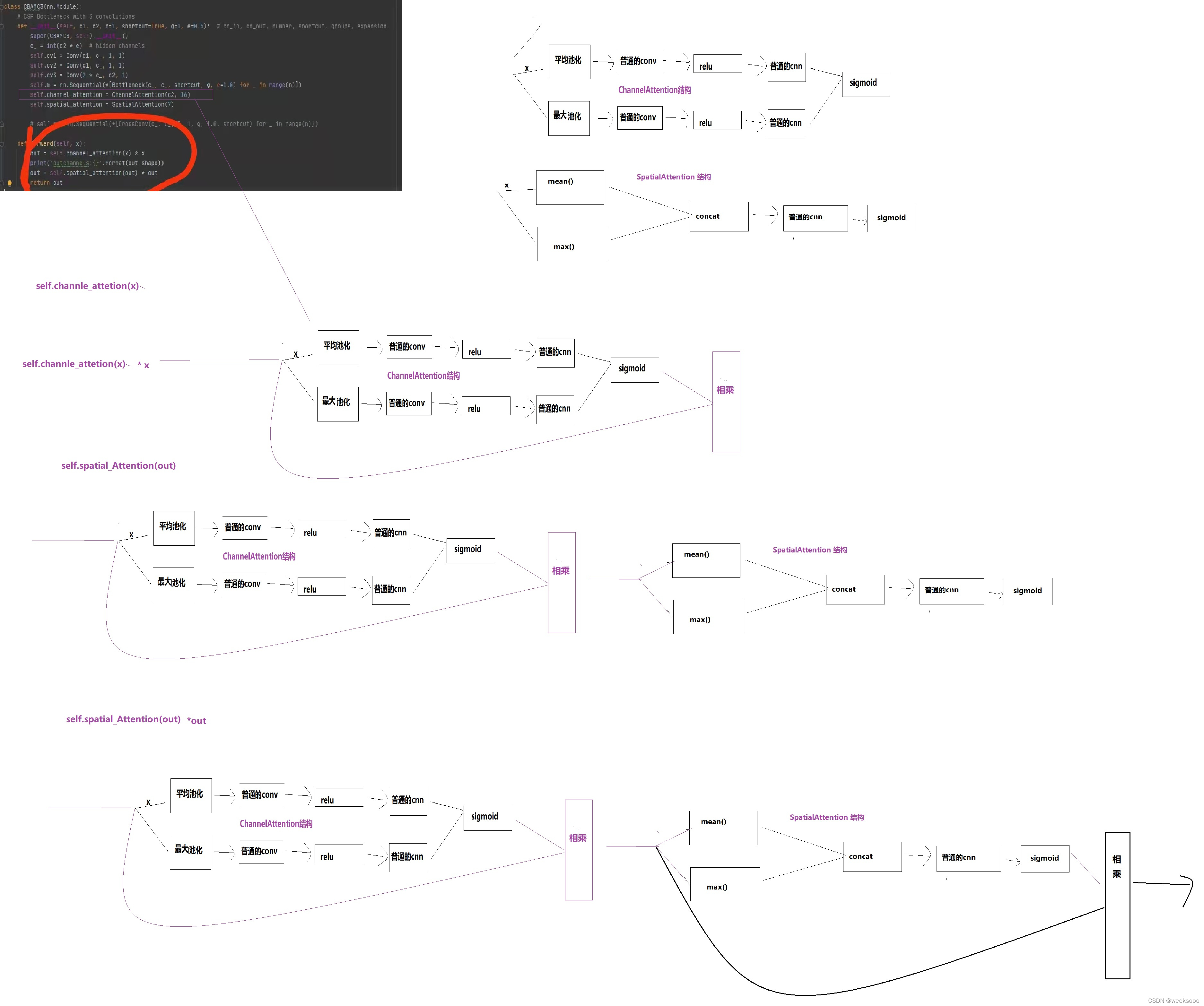
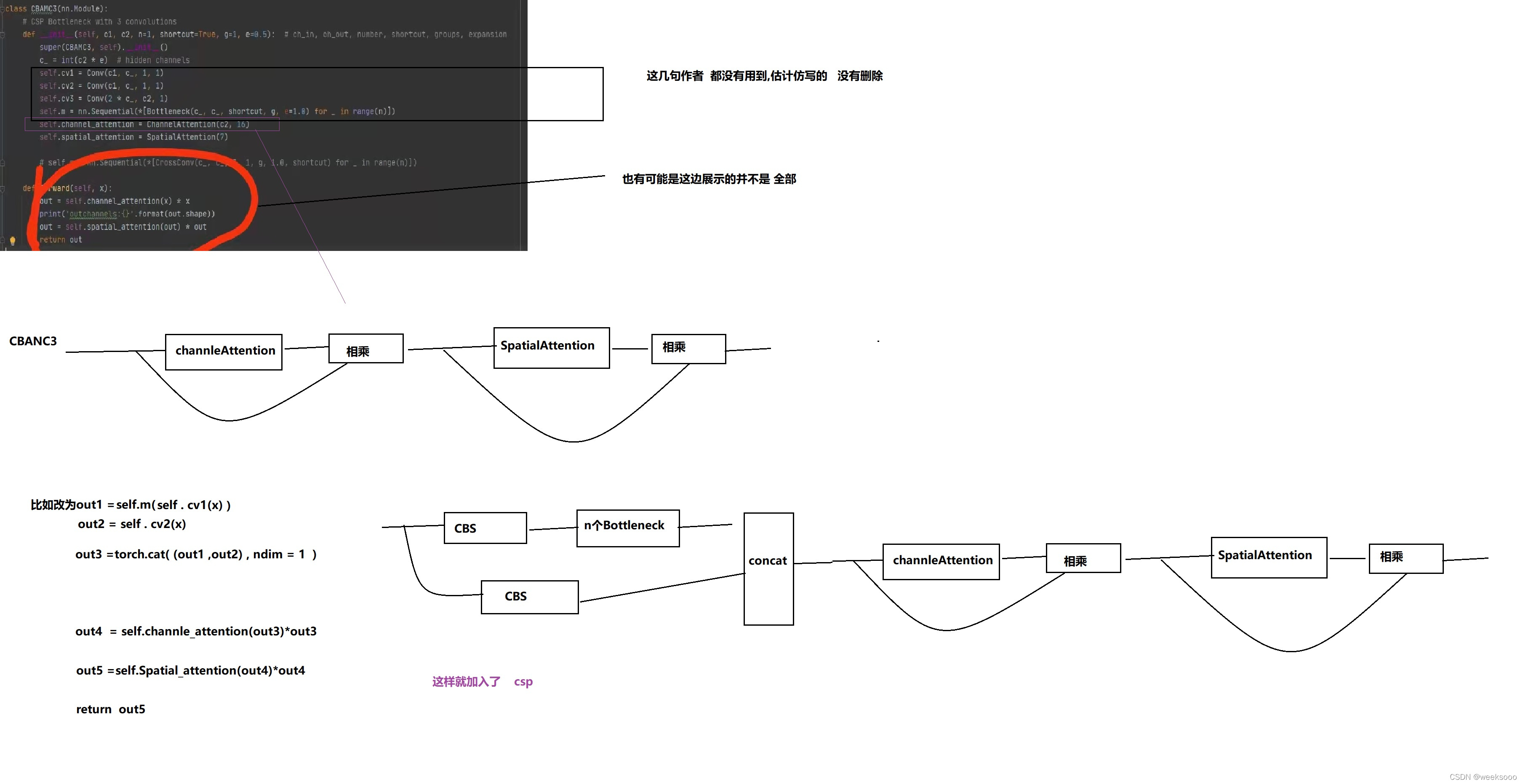
5:数据集预处理以加载代码解析—>Augmentations.py与Datasets.py

6:指标相关代码与损失Loss代码—>metrics.py 与 Loss.py

7: autoanchor.py 与 torch_utils.py 与general.py

8: detect.py



9: val.py

10: train.py


11: yolov5 - v6版本 detect.py注释代码
# YOLOv5 ?? by Ultralytics, GPL-3.0 license
# 检测脚本
"""
Run inference on images, videos, directories, streams, etc.
Usage:
$ python path/to/detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
"""
import argparse
import os
import sys
from pathlib import Path
import cv2
import torch
import torch.backends.cudnn as cudnn
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import DetectMultiBackend
from utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr,
increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import select_device, time_sync
@torch.no_grad()
def run(weights=ROOT / 'yolov5s.pt', # model.pt path(s)
source=ROOT / 'data/images', # file/dir/URL/glob, 0 for webcam
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project=ROOT / 'runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
source = str(source)
# 如果带有参数--nosave 就是不保存 , not nosave 就是 保存 ,也就是 我们 没有设定 参数nosave的值的时候,nosave 的值就是False
save_img = not nosave and not source.endswith('.txt') # save images ,这里没有接到参数命令就保存
# 判断我们传入的是否是文件, 即 source检测的 是图片视频 还是 开启的摄像头
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
# 看看source是不是指定的 rtsp:// ,rtmp://等形式 ,如果是 说明我们采用的是 摄像头
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
# 看看是不是 使用了摄像头
webcam = source.isnumeric() or source.endswith('.txt') or (is_url and not is_file)
if is_url and is_file:
# 判断source是否存在,不存在就下载
source = check_file(source) # download
# Directories 如果输入的命令行带有 --exist_ok ,则上面的参数属性exist_ok的值为 true
# project在前面的参数定义中,默认是ROOT / 'runs/detect' name的默认是 exp ,所以参数的作用 就是在你的工程下 创建一个 目录 runs / detect / exp
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok)
# 如果是传入参数--save-txt ,也就是将检测的框的坐标以txt保存起来 , 就会在 save_dir即 runs / detect / exp/下创建一个 labels文件夹
# 如果 不传入参入,就是 默认 是false ,就不会创建
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model,使用torch_utils中 select_device() 函数 来根据 device的值 进行设备选择
device = select_device(device)
# 加载模型
model = DetectMultiBackend(weights, device=device, dnn=dnn)
stride, names, pt, jit, onnx, engine = model.stride, model.names, model.pt, model.jit, model.onnx, model.engine
# 检查图像尺寸是否是 s(默认是32)的整数倍,如果不是 就调整为 32的整数倍
imgsz = check_img_size(imgsz, s=stride) # check image size
# Half 如果设备为 cpu ,就使用Float 16 , 如果是Gpu 就使用float32
half &= (pt or jit or engine) and device.type != 'cpu' # half precision only supported by PyTorch on CUDA
if pt or jit:
model.model.half() if half else model.model.float()
# Dataloader 通过不同的输入源来设置不同的数据加载方式
if webcam:
# 检查环境是否支持 图片显示
view_img = check_imshow() # 支持 True
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt)
bs = len(dataset) # batch_size
else:
# 加载图片或视频 ,dataset就成为LoadImages这个类的一个实例化对象
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs
# wramup是common.py中 DetectMultiBackend类中的 一个方法, 预热训练 这个方法的作用就让学习率在前面很小,慢慢增加到我们设定的值
# Run inference
model.warmup(imgsz=(1, 3, *imgsz), half=half) # warmup
dt, seen = [0.0, 0.0, 0.0], 0
'''
path 图片 /视频 路径
im 进行resize +pad 在之后的图片 , 如(3, 640 ,512 ) 格式是(c, h ,w)
img0s 原size图片 例如 ( 1080 , 810 ,3 )
vid_cap 当前图片为None , 读取视频是 为视频源
'''
for path, im, im0s, vid_cap, s in dataset:
# torch_utils 里面 time_sync() 函数, 作用是 时间同步 (等待GPU操作完成) ,返回当前时间
t1 = time_sync()
# 把nparray数组的格式转换为pytorch格式
im = torch.from_numpy(im).to(device)
# uint8 to fp16/32 如果 half为true的话,也进行半精度,即16位精度
im = im.half() if half else im.float()
# 0 - 255 to 0.0 - 1.0 把resize以后的im每一个像素点的值 /255 ,让其在0-1之间,为了更好的适应模型
im /= 255
# im 在前面我们知道的shapes是 ( 3, 640 ,512 ) 的形式 ,所以shape长度为3
if len(im.shape) == 3:
im = im[None] # expand for batch dim 这里进行了一个扩充shape的操作变为 (batch-size , 3 ,640 ,512)的形式
# torch_utils 里面 time_sync() 函数, 作用是 时间同步 (等待GPU操作完成) ,返回当前时间
t2 = time_sync()
# dt 前面指定的是 [ 0.0 , 0.0 , 0.0] dt[0] = dt[0]+ t2 - t1 这样就更新了dt的第一个值
dt[0] += t2 - t1
# Inference 可视化 , 这个参数比较 奇葩 ,比如你检测bus.jpg ,一般 会在exp{id}的文件夹下生成 检测以后的图片 ,如果带入这个参数
# 那么生成的不再是 检测完的图片而是 一个 空文件夹 ,名字叫bus
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
# 将 处理后的 图形带入模型中进行预测
'''
一共有多少个预测框 , 一共进行了32倍下采样, 16倍下采样 , 8倍下采样
( h/32 * w/32 + h/16 * w/16 + h/8 * w/8 ) * 3
因为 前面的输入不在是以前规定的等宽高的尺寸: 416, 640,而是采用的是 自适应缩放的形式,所以不在是等宽高
例如可以是 输入的 是 (640 , 608 ) ,那么就转变了 ( 640/32 * 608/32 + .... ) =23940
pred 就是model输出的结果,它的的shape是([1, 23940, 85]) 也就是 有23940个框, 85就是 5+80 , 1是batch-size的值
85的维度上
pred[ ..., 0:4 ] 为预测坐标信息 ,坐标框的信息以 xywh 格式
pred[ ... , 4 ] 为置信度c
pred[ ... , 5:-1 ] 从index 5 -结尾 是 80个分类信息
'''
pred = model(im, augment=augment, visualize=visualize)
# torch_utils 里面 time_sync() 函数, 作用是 时间同步 (等待GPU操作完成) ,返回当前时间
t3 = time_sync()
# dt 前面指定的是 [ dt[0]+ t2 - t1 , 0.0 , 0.0] dt[1] = dt[1] + t3 -t2 这样就更新了dt的第二个值
dt[1] += t3 - t2
# 根据 你在检测命令中传入的 --conf-thres --iou-thres , --classes , --agnostic-nms --max-det等值
# 调用general.py中non_max_suppression( ) # 非极大值抑制算法 ,筛选框
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
''''
pred : 前向传播的输出,也就是结果模型model的输出 ,框的格式为 xywh
conf_thres : 置信度阈值
iou_thres : 是进行nms运算时候的iou阈值
classes : 是否指定保留指定的类别
agnostic_nums : 进行nms是否也去除不同类别之间的框
max_det : 一张图上最大的检测数
经过nms运算 预测框的格式 xywh----> x1y1 x2y2 即左上角右下角的格式
'''
# dt 前面指定的是 [ dt[0]+ t2 - t1 , dt[1] + t3 -t2 , 0.0] dt[2] = dt[2] + time_sync() - t3 这样就更新了dt的第三个值
dt[2] += time_sync() - t3
'''
所以此时的 dt的值 是 [ dt[0]+ t2 - t1 , dt[1] + t3 -t2 , dt[2] + time_sync() - t3]
分别 代表着 一张图片在送入模型前的 图片操作的 一个处理时间 (包括转换为torch格式, 像素点/255, 和 shape维度从3 到4的转换 )
这张图片送入 模型以后 ,经过处理 的 时间端
以及经过模型以后 ,送入 后处理阶段的 nms 里面进行 非极大值抑制的 时间段
这样就可以计算在每一阶段的
'''
# Second-stage classifier (optional)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# Process predictions
# 每一个图片上产生的框进行处理
for i, det in enumerate(pred): # per image i是框的id ,例如nms过滤以后只有7个框 ,det就是框的信息
seen += 1 # 前面设置了为0
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path 获取图片的路径 ,
# save_dir 我们知道前面就是 runs / detect / exp p.name就是 我们指定检测文件的名字
# 例如people.jpg 那么 save_path指的是 runs/detect/exp/people.jpg
# 例如是1.mp4 , 那么 就是 runs/detect/exp/1.mp4
save_path = str(save_dir / p.name) # im.jpg
# 如果是图片 ,labels信息 runs / detect / exp /labels/people.txt
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
# 设置图片的shape打印信息s ,用于下面的打印 , 384 x 640 的形式
s += '%gx%g ' % im.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh 归一化的增益whwh
# 假如我们命令行加上 --save-crop ,这句话的作用就是保留裁剪后的预测框,也就是如果save_crop为真,我们就在img0的拷贝上做操作,否则就是im0上操作
imc = im0.copy() if save_crop else im0 # for save_crop
# 调用plots.py中的class Annotator类来实例化
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size x1y1 x2y2
# 调整预测框的坐标: 基于resize+ pad的图片的坐标----> 基于原size图片的坐标 ,
# 使用general中的scale_coords() 函数
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
# 打印检测到的类别信息 . 也就是 det[:, -1]
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class 作用就是检测每个类别的数目
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# s前面 是定义了 为 384 X 640 的打印格式,也就是说 这里进行+ 类别信息的操作
# s 是 string 类型 , 假如 最后 是 3个狗 ,2个猫
# s 的最终结果是 384x640 3 dog 2 cat
# Write results 保存预测结果
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
# 写入
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '
')
# 是否在原图上画框 , 例如 我们假如传入--view-img,也就是是否显示之后的图片或者视频
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
# 如果传入的参数 是 --hide_labels 就是 隐藏label的信息,那么取None ,
# 如果隐藏置信度的话 那就说是 只是展示 类别信息 ,names是在前面依据model获取的, names[c]指向类别信息
# conf 指向该该类别的置信度
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
# Print time (inference-only)
# 所以 这里打印的信息
# 例如下面控制台信息打印 416x640 3 persons, Done. (0.255s) 0.255s就是在模型中推理的时间
LOGGER.info(f'{s}Done. ({t3 - t2:.3f}s)')
# Stream results
im0 = annotator.result()
# 如果是 --view-img ,就显示,
if view_img:
cv2.imshow(str(p), im0) # str(p) 是上面的图片的路径
cv2.waitKey(3000) # 1 millisecond
# Save results (image with detections)
# 保存图片/视频的操作
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path[i] != save_path: # new video
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path += '.mp4'
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer[i].write(im0)
# Print results
# dt = [ 送入模型前的处理 , 模型中的检测 , nms处理 ]
t = tuple(x / seen * 1E3 for x in dt) # speeds per image
# 比如t经过计算是 t= [ 1.00012 , 236.41212 , 2.00011 ]
# 向控制台打印 Speed: 1.0 ms pre-process , 236.4 ms inference, 2.0 ms NMS per image at shape (1, 3, 640, 640)
LOGGER.info(f'Speed: %.1f ms pre-process, %.1f ms inference, %.1f ms NMS per image at shape {(1, 3, *imgsz)}' % t)
# 打印保存的结果到哪了
if save_txt or save_img:
s = f"
{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
if update:
strip_optimizer(weights) # update model (to fix SourceChangeWarning)
def parse_opt():
# 建立 参数解析对象parser()
parser = argparse.ArgumentParser()
# add_argument() 就是给谁添加 一个 什么属性
# nargs 指的是 ---> 应该读取 的命令行参数的个数, * 表示 0或者多 , +表示 1或多
# action -- 命令行那个 遇到参数时候的动作, action='store_true' ,表示只要运行时该变量有传参就设置为True
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
# 采用parse_args() 函数来解析获取的参数
# 也就是说这一句 获取了 我们从命令行中输入的 内容并进行了 解析,其他的属性进行了默认
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(FILE.stem, opt)
return opt
def main(opt):
# 在进行最终的检测之前,看一看在requirements.txt要求中 本运行环境有没有没有装的 ,没有的话就更新下载
check_requirements(exclude=('tensorboard', 'thop'))
run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
main(opt)
"""
weights :训练的权重
source :测试数据: 可以是图片/视频 路径 ,也可以是0 ,就是 电脑摄像头 ,也可以是 rtsp 等视频流
img-size : 网络输入图片大小
conf-thresh : 置信度阈值
iou-thresh: 做nums的iou阈值
device: 设备型号
view-img: 是否展示之后的图片/视频 ,默认是False
save-txt: 是否将预测的框坐标以txt文件形式保存,默认False
save-conf: 是否将预测的框坐标以txt文件形式保存,默认False
save-dir: 网络预测之后的图片/视频的保存路径
classes: 设置只保留一部分类别 ,形如0 ,2 ,3
agnostic-nms: 进行nms是否也去除不同类别之间的框 , 默认是 False
augment : 推理的时候进行多 尺度 ,翻转(TTA)推理
update: 如果为True ,就对所有模型进行strip_optimizer操作,取出pt文件中的优化器信息,默认为false
"""
12: yolov5 - v6版本 val.py注释代码
# YOLOv5 ?? by Ultralytics, GPL-3.0 license
# 模型验证脚本
"""
Validate a trained YOLOv5 model accuracy on a custom dataset
Usage:
$ python path/to/val.py --data coco128.yaml --weights yolov5s.pt --img 640
"""
import argparse
import json
import os
import sys
from pathlib import Path
from threading import Thread
import numpy as np
import torch
from tqdm import tqdm
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import DetectMultiBackend
from utils.callbacks import Callbacks
from utils.datasets import create_dataloader
from utils.general import (LOGGER, box_iou, check_dataset, check_img_size, check_requirements, check_yaml,
coco80_to_coco91_class, colorstr, increment_path, non_max_suppression, print_args,
scale_coords, xywh2xyxy, xyxy2xywh)
from utils.metrics import ConfusionMatrix, ap_per_class
from utils.plots import output_to_target, plot_images, plot_val_study
from utils.torch_utils import select_device, time_sync
def save_one_txt(predn, save_conf, shape, file):
# Save one txt result
gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
for *xyxy, conf, cls in predn.tolist():
# 将xyxy格式---->xywh ,并进行归一化处理
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
# 如果我们传入 --save-conf 就将置信度也写入到txt中去
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(file, 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '
')
def save_one_json(predn, jdict, path, class_map):
# Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
# 获取图片的id
image_id = int(path.stem) if path.stem.isnumeric() else path.stem
# 获取坐标信息,转换为xywh
box = xyxy2xywh(predn[:, :4]) # xywh
'''
值得注意的是,之前我们说的 xywh是 中心点坐标和宽高
x1y1x2y2是左上角 右下角的坐标
而coco的json格式中的框的坐标格式为 ,x1y1wh ,即左上角 和宽高
'''
# 所以将中心点的坐标信息转为 左上角的信息
box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
for p, b in zip(predn.tolist(), box.tolist()):
jdict.append({'image_id': image_id,
'category_id': class_map[int(p[5])],
'bbox': [round(x, 3) for x in b],
'score': round(p[4], 5)})
'''
jdit 就是json字典,用来存放信息
image_id : 图片id ,即信息来至于哪张图片
category_id : 类别信息 ,coco91 claass() ,从索引映射到索引0-90
所以: p[5] 获取的是类别信息 , int转换以后 ,利用class_map 来获取在coco91中的信息
bbox: 框的坐标
scorce : 置信度得分
'''
# 返回正确的预测矩阵 ,每个框都是 采用的是 x1y1 x2y2的格式
def process_batch(detections, labels, iouv):
"""
Return correct predictions matrix. Both sets of boxes are in (x1, y1, x2, y2) format.
Arguments:
detections (Array[N, 6]), x1, y1, x2, y2, conf, class
labels (Array[M, 5]), class, x1, y1, x2, y2
Returns:
correct (Array[N, 10]), for 10 IoU levels
"""
# 初始化预测评定
correct = torch.zeros(detections.shape[0], iouv.shape[0], dtype=torch.bool, device=iouv.device)
# 如果调用box_iou()函数计算 两个框的iou , 即 labels是[ 类别 ,x1y1x2y2 ] detections x1 ,y1 ,x2,y2 ,conf ,class
iou = box_iou(labels[:, 1:], detections[:, :4])
# 挑选iou大于 阈值 且 类别匹配的 , iouv[0] 也就是一开始的阈值设定为0.5
x = torch.where((iou >= iouv[0]) & (labels[:, 0:1] == detections[:, 5])) # IoU above threshold and classes match
if x[0].shape[0]:
matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detection, iou]
if x[0].shape[0] > 1:
matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
# matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
matches = torch.Tensor(matches).to(iouv.device)
correct[matches[:, 1].long()] = matches[:, 2:3] >= iouv
return correct
@torch.no_grad()
def run(data,
weights=None, # model.pt path(s)
batch_size=32, # batch size
imgsz=640, # inference size (pixels)
conf_thres=0.001, # confidence threshold
iou_thres=0.6, # NMS IoU threshold
task='val', # train, val, test, speed or study
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
workers=8, # max dataloader workers (per RANK in DDP mode)
single_cls=False, # treat as single-class dataset
augment=False, # augmented inference
verbose=False, # verbose output
save_txt=False, # save results to *.txt
save_hybrid=False, # save label+prediction hybrid results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_json=False, # save a COCO-JSON results file
project=ROOT / 'runs/val', # save to project/name
name='exp', # save to project/name
exist_ok=False, # existing project/name ok, do not increment
half=True, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
model=None,
dataloader=None,
save_dir=Path(''),
plots=True,
callbacks=Callbacks(),
compute_loss=None,
):
# Initialize/load model and set device
# 初始化并加载模型,并且进行 设备设置
# 判断是否在训练时 调用val , 如果是则获取训练时的设备
training = model is not None # 如果model存在,相当于训练时的 model , training = true
if training: # called by train.py 被train.py召唤
device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
half &= device.type != 'cpu' # half precision only supported on CUDA
model.half() if half else model.float()
else: # called directly ,否则的话 就是正常的我们的 参数 传递的调用 ,也就是我们命令行传入的调用
# 使用torch_utils中 select_device() 函数 来根据 device的值 进行设备选择
device = select_device(device, batch_size=batch_size)
# Directories 如果输入的命令行带有 --exist_ok ,则上面的参数属性exist_ok的值为 true
# project在前面的参数定义中,默认是ROOT / 'runs/detect' name的默认是 exp ,所以参数的作用 就是在你的工程下 创建一个 目录 runs /val / exp
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
# 如果是传入参数--save-txt ,也就是将检测的框的坐标以txt保存起来 , 就会在 save_dir即 runs / detect / exp/下创建一个 labels文件夹
# 如果 不传入参入,就是 默认 是false ,就不会创建
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model # 加载模型,利用common.py中的DetectMultiBackend类来加载 模型
model = DetectMultiBackend(weights, device=device, dnn=dnn)
stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
# stride 就是模型下采样的大小
# 检查图像尺寸是否是 s(默认是32)的整数倍,如果不是 就调整为 32的整数倍
imgsz = check_img_size(imgsz, s=stride) # check image size
# 如果设备不是cpu并且gpu数目为1 ,将模型由float32 转为 float16,提升前向传播的速度
# half是 半精度预测,也就是float16, 这里可以看到 是 半精度预测仅仅被 CUDA支持
half &= (pt or jit or engine) and device.type != 'cpu' # half precision only supported by PyTorch on CUDA
if pt or jit:
# 如果half真,模型就取半精度预测,否则就是 float32预测
model.model.half() if half else model.model.float()
elif engine:
batch_size = model.batch_size
else:
half = False
batch_size = 1 # export.py models default to batch-size 1 #模型默认的批处理大小为1
device = torch.device('cpu')
LOGGER.info(f'Forcing --batch-size 1 square inference shape(1,3,{imgsz},{imgsz}) for non-PyTorch backends')
# 使用general.平移中的check_dataset()函数,检查传入的 data是否存在
data = check_dataset(data) # check
# Configure
# eval()时 , 框架会自动的把BN 和Dropout固定住,用训练好的值,不启用 BN和Dropout
model.eval()
# 判断是否是 coco数据集,也就是是否采用的是 coco数据集去验证模型
is_coco = isinstance(data.get('val'), str) and data['val'].endswith('coco/val2017.txt') # COCO dataset
# 如果传入的参数是--single-cls , 也是就数据集只有一个类别,nc置为1
nc = 1 if single_cls else int(data['nc']) # number of classes
# 设置IOU阈值,从0.5 - 0.95 ,每隔 0.05取一次
iouv = torch.linspace(0.5, 0.95, 10).to(device) # iou vector for [email protected]:0.95
# niou指的就是上面的iou个数
niou = iouv.numel()
# Dataloader
if not training:
# 如果 不是在训练的时候被召唤,也就是 说 这是我们命令启动的
# wramup是common.py中 DetectMultiBackend类中的 一个方法, 预热训练 这个方法的作用就让学习率在前面很小,慢慢增加到我们设定的值
model.warmup(imgsz=(1, 3, imgsz, imgsz), half=half) # warmup
# 如果task也就是 验证方式是speed ,那么就 pad设置为0 ,即不填充 , 如果不是,是采用正常的val ,test ,train 或study
pad = 0.0 if task == 'speed' else 0.5
# 如果是 train ,val ,test的一种 ,那就是是task 本身 , 如果 是 study或者是speed一种,这里就开始 转换为val的形式
# 指向 图片的位置,也就是要做操作的 图片的路径
task = task if task in ('train', 'val', 'test') else 'val' # path to train/val/test images
# 调用datasets.py中的create_dataloader()函数来创建dataloader
# 注意这里的rect参数为true ,yolov5的测试评估是基于矩形推理的
# data[task] 指向的就是图片路径
dataloader = create_dataloader(data[task], imgsz, batch_size, stride, single_cls, pad=pad, rect=pt,
workers=workers, prefix=colorstr(f'{task}: '))[0]
# 初始化测试图片的数量
seen = 0
# 调用metrics.py的ConfusionMatrix 混淆矩阵类 实例化 一个 混淆矩阵
confusion_matrix = ConfusionMatrix(nc=nc)
# 获取类别的名字
names = {k: v for k, v in enumerate(model.names if hasattr(model, 'names') else model.module.names)}
# 如果是coco数据集 ,就采用 general.py中的coco80_to_coco91_class() ,也就是将80个分类转为在paper中出现的91分类长度,
# 创建一个list[ range(1 ,90)] , 如果不是 就是list(range(1000))
# 作用是获取coco数据集的类别的索引 , 输入coco 数据集的类别是80 ,理论上索引是0-79 ,但是其索引却属于1-90
class_map = coco80_to_coco91_class() if is_coco else list(range(1000))
# 设置s,也就是像屏幕中显示的字符串
s = ('%20s' + '%11s' * 6) % ('Class', 'Images', 'Labels', 'P', 'R', '[email protected]', '[email protected]:.95')
# 初始化各种评价指标
dt, p, r, f1, mp, mr, map50, map = [0.0, 0.0, 0.0], 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0
# dt 依然是 [0.0 , 0.0 , 0.0 ]用来记录运行时间 ,p就是 精度, r是召回率
# 初始化 测试集的损失
loss = torch.zeros(3, device=device)
# 初始化json文件的字典 ,统计信息 ,ap
jdict, stats, ap, ap_class = [], [], [], []
pbar = tqdm(dataloader, desc=s, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
# 对dataloader进行遍历
for batch_i, (im, targets, paths, shapes) in enumerate(pbar):
# torch_utils 里面 time_sync() 函数, 作用是 时间同步 (等待GPU操作完成) ,返回当前时间
t1 = time_sync()
# 第一阶段: 送入模型前将图片进行预处理操作................................................................
if pt or jit or engine:
# 加载图片以后放在相应的设备上去处理
im = im.to(device, non_blocking=True)
targets = targets.to(device)
# uint8 to fp16/32 如果 half为true的话,也进行半精度,即16位精度
im = im.half() if half else im.float() # uint8 to fp16/32
# 0 - 255 to 0.0 - 1.0 把resize以后的im每一个像素点的值 /255 ,让其在0-1之间,为了更好的适应模型
im /= 255
# 获得处理以后的shape
nb, _, height, width = im.shape # batch size, channels, height, width
# torch_utils 里面 time_sync() 函数, 作用是 时间同步 (等待GPU操作完成) ,返回当前时间
t2 = time_sync()
dt[0] += t2 - t1 # dt为[ dt[0]+t2-t1 , 0 , 0 ]
# Inference...........................................................................................
# 第二阶段 将处理以后的图片送入模型 , 可以看到如果是 training时候调用val.py那么就是model(im)
# 否则就是 model(im, augment=augment, val=True) , out是 预测结果 ,train_out为训练结果
# 如果我们采用的 命令行中调用的val.py ,就是没有训练,那么这时候 out才是有意义的, train_out没有意义
out, train_out = model(im) if training else model(im, augment=augment, val=True) # inference, loss outputs
# torch_utils 里面 time_sync() 函数, 作用是 时间同步 (等待GPU操作完成) ,返回当前时间
dt[1] += time_sync() - t2 # dt为[ dt[0]+t2-t1 , dt[1]+time_sync()-t2 , 0 ]
'''
out 就是model输出的结果,它的的shape是([1, 23940, 85]) 也就是假如 有23940个框, 85就是 5+80 , 1是batch-size的值
85的维度上
out[ ..., 0:4 ] 为预测坐标信息 ,坐标框的信息以 xywh 格式
out[ ... , 4 ] 为置信度c
out[ ... , 5:-1 ] 从index 5 -结尾 是 80个分类信息
'''
# Loss
if compute_loss: # 默认是None ,也就是说 只有在训练时调用val.py , 然后传入computer_loss为true
# 这时候会提通过train_out结果计算并返回测试集的 box-loss , obj-loss 与cls-loss
loss += compute_loss([x.float() for x in train_out], targets)[1] # box, obj, cls
# 构造一个tensor
targets[:, 2:] *= torch.Tensor([width, height, width, height]).to(device) # to pixels
# 如果我们 传入的 --save-hybrid ,就会保存标签和预测的 混合结果
# 也就是save_hybird 为false的话 ,也就是 lb = []
lb = [targets[targets[:, 0] == i, 1:] for i in range(nb)] if save_hybrid else [] # for autolabelling
# NMS.................................................................................................................
# torch_utils 里面 time_sync() 函数, 作用是 时间同步 (等待GPU操作完成) ,返回当前时间
t3 = time_sync()
# 根据 你在检测命令中传入的 --conf-thres --iou-thres , --classes , --agnostic-nms --max-det等值
# 调用general.py中non_max_suppression( ) # 非极大值抑制算法 ,筛选框
out = non_max_suppression(out, conf_thres, iou_thres, labels=lb, multi_label=True, agnostic=single_cls)
''''
out : 前向传播的输出,也就是结果模型model的输出 ,框的格式为 xywh
conf_thres : 置信度阈值
iou_thres : 是进行nms运算时候的iou阈值
agnostic_nums : 进行nms是否也去除不同类别之间的框
经过nms运算 预测框的格式 xywh----> x1y1 x2y2 即左上角右下角的格式
'''
# torch_utils 里面 time_sync() 函数, 作用是 时间同步 (等待GPU操作完成) ,返回当前时间
dt[2] += time_sync() - t3
# dt为[ dt[0]+t2-t1 , dt[1]+time_sync()-t2 , dt[2]+time_sync() - t3 ] 这样就可以计算在每一阶段的时间
# Metrics指标
# 对每一张图片产生的信息进行处理,包括统计,写入信息到txt文件夹中去 ,生成json文件字典,统计tp等 ,
for si, pred in enumerate(out):
# per image si是框的id ,例如nms过滤以后只有7个框 ,pred就是预测框的信息
# targets[ :, 0] 就是标签属于哪一张图片的编号 ,也就是说最后的labels会得到原始标注的lables信息
labels = targets[targets[:, 0] == si, 1:]
nl = len(labels) # 就是原始标注上有n个检测目标
# 获取标签的类别 , 比如说原始图片是有3个 狗 ,2个猫 ,也就是上面的 nl 为 5 ,
# 说明原始图片上有物体,于是统计这5个物体的类别, 类别数为2 ,如果nl为0 ,说明原始图片上就没有物体,于是类别数就是0
tcls = labels[:, 0].tolist() if nl else [] # target class
# Path( paths[i] ) , 获取index为si的图片的路径 , shapes[si][0] 就是获取这张图片的shape
path, shape = Path(paths[si]), shapes[si][0]
# seen 用于统计多少张图片
seen += 1
# 判断 预测框的信息是否空
if len(pred) == 0:
if nl: # 如果是空 ,就看是不是因为原始图片上本来就没有检测目标
stats.append((torch.zeros(0, niou, dtype=torch.bool), torch.Tensor(), torch.Tensor(), tcls))
continue
# Predictions ,看看有没有传入 --single-cls pred 带着85维信息 ,前面 是 处理以后的 xywhc ,80个分类信息
# 不过经过nms ,应该收 xywh--> x1y1x2y2 左上角 ,右下角的形式了 ,所以是 x1 y1 x2 y2 c + 80
if single_cls:
pred[:, 5] = 0
predn = pred.clone()
# 调用 general.py进行相应的转换
scale_coords(im[si].shape[1:], predn[:, :4], shape, shapes[si][1]) # native-space pred
# Evaluate
if nl:
# 将 目标框 转换为 x1y1x2y2的形式 调用 general.py进行相应的转换
tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
scale_coords(im[si].shape[1:], tbox, shape, shapes[si][1]) # native-space labels
labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels,固有标签
correct = process_batch(predn, labelsn, iouv)
'''
上面定义的process_batch()返回正确的预测矩阵
predn 是 (Array[N, 6]), x1, y1, x2, y2, conf, class
labels (Array[M, 5]), class, x1, y1, x2, y2
'''
if plots: # 默认是true
confusion_matrix.process_batch(predn, labelsn)
else:
correct = torch.zeros(pred.shape[0], niou, dtype=torch.bool)
# 在 stats [] 中添加 每一张图片的正确的预测矩阵 , 置信度 预测的类别信息 , 目标类别信息
stats.append((correct.cpu(), pred[:, 4].cpu(), pred[:, 5].cpu(), tcls)) # (correct, conf, pcls, tcls)
# Save/log
# 如果传入 --save-txt ,就是 将 预测框的信息以txt的形式保存下来,
if save_txt:
# 保存在上面save_one_txt()函数定义的目录下 , 即 runs / val / labels/ + .txt
save_one_txt(predn, save_conf, shape, file=save_dir / 'labels' / (path.stem + '.txt'))
# 如果传入的是 --save-json ; 保存coco格式额度json文件字典
if save_json:
# 调用上面定义的save_one_json()
save_one_json(predn, jdict, path, class_map) # append to COCO-JSON dictionary
callbacks.run('on_val_image_end', pred, predn, path, names, im[si])
# Plot images
# 画出第1 ,2 个batch的图片的ground truth和 预测框并保存
# 保存在 runs / val / exp / va1-batch1_labels.jpg
if plots and batch_i < 3:
f = save_dir / f'val_batch{batch_i}_labels.jpg' # labels
Thread(target=plot_images, args=(im, targets, paths, f, names), daemon=True).start()
# 保存在 runs / val / exp / val-batch1_pred.jpg
f = save_dir / f'val_batch{batch_i}_pred.jpg' # predictions
Thread(target=plot_images, args=(im, output_to_target(out), paths, f, names), daemon=True).start()
# Compute metrics,图片全部处理完 ,开始计算指标
# 将stats列表的信息拼接到一起
stats = [np.concatenate(x, 0) for x in zip(*stats)] # to numpy
if len(stats) and stats[0].any():
# 调用metrics.py总的 ap_per_class 计算每一个类别的指标 ,精度p = tp/tp +fp 召回率 = tp/p , map
tp, fp, p, r, f1, ap, ap_class = ap_per_class(*stats, plot=plots, save_dir=save_dir, names=names)
# 所以ap50就是 iou阈值为 0.5时候的ap , 每一个类别的 ap [ iou>0.5时的准确率 , iou>0.55是的准确性, .... ]
ap50, ap = ap[:, 0], ap.mean(1) # [email protected], [email protected]:0.95 ap就相当于AP (iou阈值为0.5 - 0.95)的平均值 ,这是每一个类别
mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean() # 这里就是所有的类别性能
# nt是一个列表 ,测试集 每个类别有多少个目标框,也就是测试集上这个类别标注了多少个
nt = np.bincount(stats[3].astype(np.int64), minlength=nc) # number of targets per class
else:
nt = torch.zeros(1)
# Print results,打印结果
pf = '%20s' + '%11i' * 2 + '%11.3g' * 4 # print format
LOGGER.info(pf % ('all', seen, nt.sum(), mp, mr, map50, map))
# Print results per class ,打印类别信息
if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):
for i, c in enumerate(ap_class):
LOGGER.info(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))
# Print speeds,打印速度信息
t = tuple(x / seen * 1E3 for x in dt) # speeds per image
if not training:
shape = (batch_size, 3, imgsz, imgsz)
# 比如t经过计算是 t= [ 1.00012 , 236.41212 , 2.00011 ]
# 向控制台打印 Speed: 1.0 ms pre-process (预处理) , 236.4 ms inference(推理), 2.0 ms NMS per image at shape (1,3,640, 640)
LOGGER.info(f'Speed: %.1f ms pre-process, %.1f ms inference, %.1f ms NMS per image at shape {shape}' % t)
# Plots
if plots:
confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
callbacks.run('on_val_end')
# Save JSON
# 采用之前保存的json格式预测结果 ,通过cocoapi评估指标
# 需要注意的是 测试集的标签页需要转换为coco的json格式
if save_json and len(jdict):
w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weights
anno_json = str(Path(data.get('path', '../coco')) / 'annotations/instances_val2017.json') # annotations json
pred_json = str(save_dir / f"{w}_predictions.json") # predictions json
LOGGER.info(f'
Evaluating pycocotools mAP... saving {pred_json}...')
with open(pred_json, 'w') as f:
json.dump(jdict, f)
try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
check_requirements(['pycocotools'])
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
anno = COCO(anno_json) # init annotations api
pred = anno.loadRes(pred_json) # init predictions api
eval = COCOeval(anno, pred, 'bbox')
if is_coco:
eval.params.imgIds = [int(Path(x).stem) for x in dataloader.dataset.img_files] # image IDs to evaluate
eval.evaluate()
eval.accumulate()
eval.summarize()
map, map50 = eval.stats[:2] # update results ([email protected]:0.95, [email protected])
except Exception as e:
LOGGER.info(f'pycocotools unable to run: {e}')
# Return results ,打印保存结果信息的位置
model.float() # for training
if not training:
s = f"
{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
maps = np.zeros(nc) + map
for i, c in enumerate(ap_class):
maps[c] = ap[i]
return (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()), maps, t
def parse_opt():
# 建立 参数解析对象parser()
parser = argparse.ArgumentParser()
# add_argument() 就是给谁添加 一个 什么属性
# nargs 指的是 ---> 应该读取 的命令行参数的个数, * 表示 0或者多 , +表示 1或多
# action -- 命令行那个 遇到参数时候的动作, action='store_true' ,表示只要运行时该变量有传参就设置为True
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--batch-size', type=int, default=32, help='batch size')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')
parser.add_argument('--task', default='val', help='train, val, test, speed or study')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--verbose', action='store_true', help='report mAP by class')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-json', action='store_true', help='save a COCO-JSON results file')
parser.add_argument('--project', default=ROOT / 'runs/val', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
# 采用parse_args() 函数来解析获取的参数
# 也就是说这一句 获取了 我们从命令行中输入的 内容并进行了 解析,其他的属性进行了默认
opt = parser.parse_args()
# 使用general.py中的def check_yaml() 函数来查看命令传入的data是否存在
opt.data = check_yaml(opt.data) # check YAML
opt.save_json |= opt.data.endswith('coco.yaml')
opt.save_txt |= opt.save_hybrid
print_args(FILE.stem, opt) # 打印opt的信息
return opt
def main(opt):
# 在进行最终的检测之前,看一看在requirements.txt要求中 本运行环境有没有没有装的 ,没有的话就更新下载
check_requirements(requirements=ROOT / 'requirements.txt', exclude=('tensorboard', 'thop'))
# 如果opt的属性task在 train ,val test中,就正常测试验证集,测试集
if opt.task in ('train', 'val', 'test'): # run normally
if opt.conf_thres > 0.001: # https://github.com/ultralytics/yolov5/issues/1466
# 打印信息: 警告: 置信度的阈值 如 0.20 远大于 0.001 将会产生无效的 map值
LOGGER.info(f'WARNING: confidence threshold {opt.conf_thres} >> 0.001 will produce invalid mAP values.')
run(**vars(opt))
else:
# 判断 opt.weights 是 一个列表,如果是 一个列表 赋值给weights ,如果不是一个列表,进行列表转换
weights = opt.weights if isinstance(opt.weights, list) else [opt.weights]
# half为True就是 说精度减半,转换为 float 32
opt.half = True # FP16 for fastest results
# 如果task的值是 speed ,就是相当于采用快速校验的形式
if opt.task == 'speed': # speed benchmarks
# python val.py --task speed --data coco.yaml --batch 1 --weights yolov5n.pt yolov5s.pt...
# 设置相关属性
opt.conf_thres, opt.iou_thres, opt.save_json = 0.25, 0.45, False
for opt.weights in weights:
run(**vars(opt), plots=False)
# 如果传入的是 study的形式,就评估yolov5系列和yolov3-spp各个尺度下的指标并可视化
elif opt.task == 'study': # speed vs mAP benchmarks
# python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n.pt yolov5s.pt...
for opt.weights in weights:
f = f'study_{Path(opt.data).stem}_{Path(opt.weights).stem}.txt' # filename to save to
x, y = list(range(256, 1536 + 128, 128)), [] # x axis (image sizes), y axis
for opt.imgsz in x: # img-size
LOGGER.info(f'
Running {f} --imgsz {opt.imgsz}...')
r, _, t = run(**vars(opt), plots=False)
y.append(r + t) # results and times
np.savetxt(f, y, fmt='%10.4g') # save
os.system('zip -r study.zip study_*.txt')
plot_val_study(x=x) # plot
if __name__ == "__main__":
opt = parse_opt()
main(opt)
"""
data : 数据集配置文件 默认是 data/coco128.yaml
weights : 测试模型权重文件 默认是 yolov5s.pt
batch-size : 前向传播时的批次 默认是 32,
imgsz : 图片输入分辨率的大小 默认是 640
conf-thres : 筛选框时候的置信度阈值 默认是 0.001
iou-thres : 进行NMS的时候的IOU阈值 默认是 0.6,
device : 测试的设备 cpu 或者是0 代表GPU
save-txt : 是否以txt文件的形式保存模型预测的框坐标 默认是 False
save-conf : 是否将置信度的信息保存到上面的save—txt中去 默认是 False
save-json : 是否按照coco的josn格式保存预测框,并且使用cocoapi做评估 默认是 Fasle
single-cls : 数据集是否只有一个类别 默认是 False
augment : 测试时是否使用TTA 默认是 False
verbose : 是否打印每个类别的mAP 默认是 False
project : 默认是 ROOT / 'runs/val' 也就是会在runs文件下创建val文件夹
name : 默认是 exp 也就是会在val文件夹下创建exp文件夹来存放结果
task : 默认是val 设置测试的形式
"""
13: yolov5 - v6版本 train.py注释代码
# YOLOv5 ?? by Ultralytics, GPL-3.0 license
# 模型训练脚本
"""
Train a YOLOv5 model on a custom dataset
Usage:
$ python path/to/train.py --data coco128.yaml --weights yolov5s.pt --img 640
"""
import argparse
import math
import os
import random
import sys
import time
from copy import deepcopy
from datetime import datetime
from pathlib import Path
import numpy as np
import torch
import torch.distributed as dist
import torch.nn as nn
import yaml
from torch.cuda import amp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.optim import SGD, Adam, lr_scheduler
from tqdm import tqdm
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
import val # for end-of-epoch mAP
from models.experimental import attempt_load
from models.yolo import Model
from utils.autoanchor import check_anchors
from utils.autobatch import check_train_batch_size
from utils.callbacks import Callbacks
from utils.datasets import create_dataloader
from utils.downloads import attempt_download
from utils.general import (LOGGER, check_dataset, check_file, check_git_status, check_img_size, check_requirements,
check_suffix, check_yaml, colorstr, get_latest_run, increment_path, init_seeds,
intersect_dicts, labels_to_class_weights, labels_to_image_weights, methods, one_cycle,
print_args, print_mutation, strip_optimizer)
from utils.loggers import Loggers
from utils.loggers.wandb.wandb_utils import check_wandb_resume
from utils.loss import ComputeLoss
from utils.metrics import fitness
from utils.plots import plot_evolve, plot_labels
from utils.torch_utils import EarlyStopping, ModelEMA, de_parallel, select_device, torch_distributed_zero_first
'''
例如我们在自己的电脑的环境变量中 起了 一个叫key的值 ,它假如指向了一个编译器的地址: home/jdk
os.getenv(key )的作用 就是获取这个指向的值: 即 home/jdk ;
如果没有指明 key的指向 是 一个值 , 那么os.getenv(key ) 就返回一个None
如果我们没有指定key的指向 , os.getenv(Key , 'value does not exist ' ) 找不到就返回了 value does not exist
所以这里 使用 os.getenv('LOCAL_RANK', -1) ,如果找不到 LOCAL_RANK指向的值 ,就 是返回指定的-1, 那么LOCAL_RANK = int(-1)=-1
所以这里 使用 os.getenv('RANK', -1) ,如果找不到 RANK指向的值 ,就 是返回指定的-1, 那么RANK = int(-1)=-1
所以这里 使用 os.getenv('WORLD_SIZE', 1) ,如果找不到 WORLD_SIZE指向的值 ,就 是返回指定的1, 那么RANK = int(1)=1
RANK为进程编号
LOCAL_RANK为GPU编号
'''
LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
RANK = int(os.getenv('RANK', -1))
WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
def train(hyp, # path/to/hyp.yaml or hyp dictionary
opt,
device,
callbacks
):
# 获取 opt的各种属性
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze =
Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg,
opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
# .............................................设置训练生成的模型的存放路径....................................
# 如果没有指明超参数进化 ,那么下面的语句opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
# opt.project ----> runs/tarin opt.name----->exp 于是相当于save_dir 为 runs/train/exp
# 如果使用了超参数进化 , opt.project ----> runs/evolve save_dir 就是 runs/evolve /exp了
# 设置训练模型的保存位置 ,也就是 runs / train/exp/weights
w = save_dir / 'weights' # weights dir
# 创建相应的 路径
(w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
# 在weights下创建 last.pt 和 best.pt
last, best = w / 'last.pt', w / 'best.pt'
# ..........................................加载超参数配置文件..........................................
# Hyperparameters ,判断 hyp是否是字符串 ,如果是字符串,说明程序也并没有开启进化,要不然再下面main()函数里面,已经变为对应的字典了
if isinstance(hyp, str):
# 如果是字符串的话 , 就调用safe_load() 函数加载相应的hyp超参数配置文件给 hyp,这时候hyp为字典
with open(hyp, errors='ignore') as f:
hyp = yaml.safe_load(f) # load hyps dict
# 调用general.py中的 colorstr( )函数 打印 出不同的 颜色 来修饰 超参数,输出 : 超参数的 参数: key = value , 学习率这些
LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
# Save run settings , 如果没有进行超参数进化 ,那么就是 写的方式打开 runs/train/exp下的 hyp.yaml,就写进去hyp
if not evolve:
with open(save_dir / 'hyp.yaml', 'w') as f:
yaml.safe_dump(hyp, f, sort_keys=False)
# 保存opt的配置 ,也就是你输入命令以后改变以后的opt信息
with open(save_dir / 'opt.yaml', 'w') as f:
yaml.safe_dump(vars(opt), f, sort_keys=False)
# Loggers
data_dict = None
if RANK in [-1, 0]:
loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
if loggers.wandb:
data_dict = loggers.wandb.data_dict
if resume:
weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp
# Register actions
for k in methods(loggers):
callbacks.register_action(k, callback=getattr(loggers, k))
# Config , 如果没有进化 , plots为true
plots = not evolve # create plots
# 查看的设备是不是cpu , 如果是cpu ,cuda为 false , 如果不是cpu ,那么就是cuda 为true ,那就是 GPU
cuda = device.type != 'cpu'
init_seeds(1 + RANK) # 设置随机种子
# ...................................................获取data指定的训练集信息..................................
with torch_distributed_zero_first(LOCAL_RANK):
# 调用general中的check_dataset()函数来 检查 检查传入的 data是否存在 ,返回的是一个字典
data_dict = data_dict or check_dataset(data) # check if None
# 以 训练默认的 文件夹data下的 coco128.yaml为例 ,里面存放了
'''
path: ../datasets/coco128 路径信息
train: images/train2017 训练图片的路径信息
val: images/train2017 验证图片的路径信息
test: 可选项 测试的严重信息
nc: 1 种类数量信息
names: ['person'] 相应种类的名称信息
download: https://ultralytics.com/assets/coco128.zip 如果不存在的下载地址 ,不过我们一般指定我们的训练集
'''
# .............................................获取训练集数据集的路径.............................................................
# 从 data指定的 文件中 获取 训练集的 路径 train_path , 获取验证集的路径 val_path
train_path, val_path = data_dict['train'], data_dict['val']
# 如果我们命令中传入 --single_cls ,就相当于我们指定了数据集只有一个类 , nc为1 , 否则就从data_dict里面获取nc的数量
nc = 1 if single_cls else int(data_dict['nc']) # number of classes
# 如果 传入的指定是单类别 但是 在 data指定的yaml文件中的类别名字并不是 一个类别 , 那么names=[ 'item' ]
# 否则的话 ,就是 页面你传入指定单类别且正好 yaml文件中的类别名字也是一个 , 那么 names= data_dict['names'] ,就是 那个类别名字
names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
# 如果 名字数不等于 指定的类别数 , 打印: 3个名字找到了 , 但是在数据中的类别数量是 4
assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check
# 查看 验证集的路径是否是str ,也就是说指定了验证集路径 , 并且如果是以coco/val2017.txt结尾 ,那么就是coco数据集,否则就不是
is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
# ....................................................看看是否采用预训练...........................................
# Model weights就是我们是否采用别人的训练模型作为自己的预训练 , # 检查文件是否是 以指定的后缀结尾 检查文件是否是 以指定的后缀结尾
check_suffix(weights, '.pt') # check weights
pretrained = weights.endswith('.pt') # 假如我们指定了 --weight '' , 默认不指定就是 yolov5s.pt
if pretrained: # 如果为真,也就是采用预训练
with torch_distributed_zero_first(LOCAL_RANK):
# 如果在本地没有找到相应的文件,那么就尝试去下载,从google云盘上自动下载模型
# 不过由于网络原因,极可能是下载失败的,所以, 用的话还是自己先下载好
weights = attempt_download(weights) # download if not found locally
# 加载模型及参数
ckpt = torch.load(weights, map_location=device) # ckpt就是 checkpoint
# 就调用common.py类Model,实例化一个model ,加载模型
# 模型的创建,可通过opt.cfg 来创建 ,也可以 通过ckpt['model'].yaml来创建
# 区别在于是否是reusme ,resume会将opt.cfg设置为空 ,那么则按照ckpt['model'].yaml来创建模型
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
# hyp.get('achors') 就是生成几个预选框的超参数 , cfg 就是模型的结构 ,使所以 exclude=['anchor']
# 这也影响着下面是否除去anchor的key,也就是(不加载anchor ) ,如果resume则不加载anchor
# 主要是因为保存的模型会保存anchors ,有时候用户自定义了anchor之后,再resume,则原来基于coco数据集的anchor就会覆盖自己设定的anchor
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(csd, strict=False) # load
# 显示加载预训练权重的键值对和创建模型的键值对
LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
else:
# 也就是我们不使用其他人的预训练模型 ,就调用common.py中的类Model,实例化一个model
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
# ........................................................冻结模型层..........................................
# 冻结模型层 ,设置冻结层名字即可
# 具体可以查看 https://github.com/ultralytics/yolov5/issues/679
# Freeze , 也就是有没有冻结需求 ,默认是[0] , 如果传入--freeze 就是冻结一些层的需求
freeze = [f'model.{x}.' for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
LOGGER.info(f'freezing {k}')
v.requires_grad = False # 通过将requires_gard 设置为false ,也就是不进行梯度计算
# .....................................输入图片的大小设定和batch-size设定.................................................
# 如果你在你的网络结构当中添加了一些结构,让你的输出最小的特征值不再是32倍的下采样,记得来改这里的内容......................
# Image size , 如果不是32的下采样,例如128倍,要改 好多 关于下采样的设定,例如图片最好是128的倍数等 . ..... ......
gs = max(int(model.stride.max()), 32) # grid size (max stride)
# 调用 general.py文件中的 check_img_size( ) 函数来检查图像尺寸是否是 s(默认是32)的整数倍,如果不是 就调整为 32的整数倍
imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
# Batch size , 默认是 16
if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
# 调用 autobatch.py中的 check_train_batch_size , 主要检查的是训练集的batch_size是否符合规范
batch_size = check_train_batch_size(model, imgsz)
loggers.on_params_update({"batch_size": batch_size})
# Optimizer .................................... 优化器设置 ,默认优化器是SGD..........................................
# nbs为标称的batc_size:
# 比如默认的话上面设置的opt.batch_size为16 , nbs=64
# 则模型梯度累计 64/16= 4 (accumulate)次之后 ,在更新一次模型,变相的扩大batch_size
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
# 根据accumlate设置权重衰减系数 , weight_decay 在hyp中采用的是 0.00036
# 新的衰减系数为 = 0.00036 * batch_size * 有上面的规则限制(nbs /batch_size ) /nbs
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay权重衰变
LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}")
g0, g1, g2 = [], [], [] # optimizer parameter groups
# 设置优化器列表,也就是将模型分为3组 , (weight , bias ,其他所有参数) 进行优化
for v in model.modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
g2.append(v.bias)
# bias 加载在 g2的优化列表里
if isinstance(v, nn.BatchNorm2d): # weight (no decay)
g0.append(v.weight) # 如果是bn层 , 将没有衰减的权重加入到g0中 ,也就是BN层不进行权重衰减
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay 衰减)
g1.append(v.weight) # 将衰减的层的权重加入到g1中
# 如果我们传入的参数 是 --adam ,也就是说opt.adam为true ,于是 我们采用的是Adam优化器
if opt.adam:
optimizer = Adam(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
# 否则默认的就是采用SGD 优化器
else:
optimizer = SGD(g0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
# 设置weight的优化方法
optimizer.add_param_group({'params': g1, 'weight_decay': hyp['weight_decay']}) # 衰减操作
# 设置biases的优化方法
optimizer.add_param_group({'params': g2}) # add g2 (biases)
# 打印信息: optimizer : Adam with parameter groups , 有多少个weight权重没有衰减 ,有多少个weight权重衰减 ,有多少个bias
LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__} with parameter groups "
f"{len(g0)} weight (no decay), {len(g1)} weight , {len(g2)} bias")
del g0, g1, g2
# ................................................设置学习率的衰减 ,这里为余弦退火的方式进行衰减..............................
# Scheduler 设置学习率衰减 ,这里为余弦退火方式进行衰减
if opt.linear_lr:
lf = lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear 退火公式
else:
lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
# ...................................................................................................................
# EMA 调用torch_utils.py文件中的 ModelEMA类 模型EMA ,就是对网络模型中的参数做一个指数 滑动平均 ,对权重进行平滑操作 ,对一些训练有更好的效果
ema = ModelEMA(model) if RANK in [-1, 0] else None
# Resume
# 初始化开始训练的epoch和最好的结果
# best_fitness 是以[ 0.0 , 0.0 , 0.1 , 0.9 ] 为系数并乘以 [ 精确度p , 召回率, [email protected] , [email protected]:0.95 ]再求和所得
# best_fitness来保存best.pt
start_epoch, best_fitness = 0, 0.0
if pretrained: # pretrained = weights.endswith('.pt') 也就是是否采用预训练
# Optimizer
if ckpt['optimizer'] is not None: # 如果ckpt中的optimizer 有东西 , is not None ,就是true
optimizer.load_state_dict(ckpt['optimizer'])
best_fitness = ckpt['best_fitness']
# EMA
# 为模型创建EMA指数滑动平均 ,如果GPU进程数大于1 ,则不创建
# EMA(指数移动平均): 一种给与近期数据更高权重的平均方法
# 用EMA方法对模型的参数做平均 ,以提高测试指标并增加模型的老百姓,减少模型权重抖动
if ema and ckpt.get('ema'):
ema.ema.load_state_dict(ckpt['ema'].float().state_dict())
ema.updates = ckpt['updates']
# Epochs
start_epoch = ckpt['epoch'] + 1
if resume:
assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.'
'''
如果新设置epochs小于加载的epoch
则视新设置的epochs为需要再训练的轮次数而不再是总的轮次数
'''
if epochs < start_epoch:
LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
epochs += ckpt['epoch'] # finetune additional epochs
del ckpt, csd
'''
DP训练:参考 https://github.com/ultralytics/yolov5/issues/679
DataParallel模式,仅支持单机多卡
RANK为进程编号 , 如果设置了rank=-1并且有多块GPU ,则使用DataParallel模型
rank =-1 且GPU数量为1 ,也不会进行分布式训练
'''
# DP mode
if cuda and RANK == -1 and torch.cuda.device_count() > 1:
# 你单机多卡 警告:不建议使用DP训练 ,为了得到更好的分布式多块GPU训练结果 ,使用 torch.distributed.run 方法
# 请参阅https://github.com/ultralytics/yolov5/issues/475上的多gpu教程开始学习
LOGGER.warning('WARNING: DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.
'
'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
model = torch.nn.DataParallel(model)
# SyncBatchNorm sync_bn表示是否使用跨卡同步
if opt.sync_bn and cuda and RANK != -1:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
LOGGER.info('Using SyncBatchNorm()')
# ................................................根据训练集路径创建训练集的train_loader..................................
# Trainloader,使用datasets.py中的create_datalaoder() 方法
train_loader, dataset = create_dataloader(train_path, imgsz, batch_size // WORLD_SIZE, gs, single_cls,
hyp=hyp, augment=True, cache=opt.cache, rect=opt.rect, rank=LOCAL_RANK,
workers=workers, image_weights=opt.image_weights, quad=opt.quad,
prefix=colorstr('train: '), shuffle=True)
# 获取标签中的最大的类别值 并与类别数nc 做比较
mlc = int(np.concatenate(dataset.labels, 0)[:, 0].max()) # max label class ,最大的标签的类别数
nb = len(train_loader) # number of batches
# mlc如果大于nc 打印: 标签类别数mlc 超过在 数据集中定义的nc值 , 允许的标签的 类别值在 0 -- nc-1之间
assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
# ................................................根据验证集路径创建训练集的val_loader..................................
# Process 0
if RANK in [-1, 0]:
# 使用datasets.py中的create_datalaoder() 方法创建验证集的val_loader
val_loader = create_dataloader(val_path, imgsz, batch_size // WORLD_SIZE * 2, gs, single_cls,
hyp=hyp, cache=None if noval else opt.cache, rect=True, rank=-1,
workers=workers, pad=0.5,
prefix=colorstr('val: '))[0]
# ..............................画出所有的lables1的种类信息 ,中心点分布信息,以及长宽信息..................................
if not resume: # 如果不是 断点训练
labels = np.concatenate(dataset.labels, 0) # 拿到dataset的标签值
# c = torch.tensor(labels[:, 0]) # classes
# cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
# model._initialize_biases(cf.to(device))
if plots: # plots = not evolve 也就是说如果不开启超参数进化 ,也就是plots为true ,那么就打印相关的信息
# 调用plots.py中的plot_lables 信息 , save_dir的路径指向 runs/train/exp/下 ,
plot_labels(labels, names, save_dir)
# Anchors ,如果我们传入的参数是 --noautoanchor 那么就是去true , 就是关闭自动计算瞄框 ,
# 此时 not ot opt.noautoanchor 就为 flase ,就不执行里面的 语句, 否则默认的话, 就会开启自动瞄框计算
# ........ .............. .............是否开启自动瞄框计算........................................................
if not opt.noautoanchor:
# 默认开启自动瞄框计算,调用autoanchor.py中的check_anchors开启 自动计算最佳瞄框,也就是计算最佳的瞄框
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
model.half().float() # pre-reduce anchor precision
# 也就是 断点训练 不会开启自动瞄框计算
callbacks.run('on_pretrain_routine_end')
# DDP mode
# 如果 rank不等于-1,则使用DistributedDataParallel模式
# local__rank为GPU编号 ,rank为进程 ,例如rank =3 ,local_rank= 0 表示第3个进程内的第一块GPU
if cuda and RANK != -1:
model = DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
# Model attributes................................模型的属性设置.........................................
nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
# 根据自己数据集的类别数设置分类损失的系数 定位损失和置信度损失系数
hyp['box'] *= 3 / nl # scale to layers
hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
hyp['label_smoothing'] = opt.label_smoothing # 向hyp中置入label_smoothing的属性 ,如果传入--label-smoothing 就是开启类平衡标签
model.nc = nc # attach number of classes to model 关联类别数
model.hyp = hyp # attach hyperparameters to model ,关联超参数
# 从训练样本标签得到类别权重( 和类别中的目标数 --- 即类别频率 --成反比 )
model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
# 获取类别的名字
model.names = names
# Start training........................................开始训练.......................................................
t0 = time.time()
# 获取热身训练的迭代次数,也就是预热训练的次数
nw = max(round(hyp['warmup_epochs'] * nb), 1000) # number of warmup iterations, max(3 epochs, 1k iterations)
# nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
last_opt_step = -1
# 初始化mAP和results的值
maps = np.zeros(nc) # mAP per class
results = (0, 0, 0, 0, 0, 0, 0) # P, R, [email protected], [email protected], val_loss(box, obj, cls)
'''
设置学习率衰减所进行到的轮次
目的是打断训练后 .--resume接着训练也能正常的衔接之前的训练进行学习率的衰减
'''
scheduler.last_epoch = start_epoch - 1 # do not move
# 通过torch1.6以上自带的api设置混合精度训练
scaler = amp.GradScaler(enabled=cuda)
# 如果传入--patience参数,执行train.py中的 EarlyStopping函数 训练次数不在提升性能超过多少个epochs时,停止训练
stopper = EarlyStopping(patience=opt.patience)
compute_loss: ComputeLoss = ComputeLoss(model) # 初始化 model的 loss
# 对应图片的size是 640训练 ,640验证
# 正在使用 多少多少线程数
# 打印结果在 runs/train/exp下
# 正在训练 那个epochs
LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val
'
f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers
'
f"Logging results to {colorstr('bold', save_dir)}
"
f'Starting training for {epochs} epochs...')
# ----------------------------------------------开始迭代epoch -------------------------------------------------------
for epoch in range(start_epoch, epochs):
model.train() # 开始训练
# Update image weights (optional, single-GPU only)
if opt.image_weights:
'''
如果设置进行图片进行采样策略
则根据前面初始化的图片采样权重model.class_weights以及 maps 配合 每张图片包含的类别数
通过random.choice生成图片索引indices从而进行采样
这样真正的数据集使用什么样的图片 ,可以设置侧重点, 假如原来的maps比较大 ,1-maps就变小
这样大的maps的权重就被设置 为小的了, 例如 数据集中标注的比较多的classese 这样操作以后的weights也会小一点
'''
cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # 得到图片采样的权重
dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
# Update mosaic border (optional)
# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
# dataset.mosaic_border = [b - imgsz, -b] # height, width borders
# 初始化训练时打印的平均损失信息
mloss = torch.zeros(3, device=device) # mean losses
if RANK != -1:
'''
DDP模型下打乱数据,ddp.sampler的随机采样数据基于epoch+ seed作为随机种子
每次epoch不同,随机种子不同
'''
train_loader.sampler.set_epoch(epoch)
pbar = enumerate(train_loader)
LOGGER.info(('
' + '%10s' * 7) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'labels', 'img_size'))
if RANK in [-1, 0]:
# tqdm 创建进度条,方便训练时信息的展示
pbar = tqdm(pbar, total=nb, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
optimizer.zero_grad() # 清零
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
# 计算迭代的次数 iteration
ni = i + nb * epoch # number integrated batches (since train start)
imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
# Warmup
'''
做热身训练(前 nw次迭代)
在 前nw次迭代中,根据以下方式选取accumulate和学习率
'''
if ni <= nw:
xi = [0, nw] # x interp nw = max(round(hyp['warmup_epochs'] * nb), 1000) 前面已经定义了要热身多少次
# compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
for j, x in enumerate(optimizer.param_groups):
'''
bias的学习率从0.1下降到基准学习率lr*lf(epoch)
其他的参数学习率从0增加到lr* lf(epoch)
lf为上面设置的余弦退火的衰减函数
'''
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
# 栋梁 momentum也从0.9 慢慢变到 hyp['momentum']
if 'momentum' in x:
x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
# Multi-scale
# 设置多尺度训练,从 imgsz* 0.5 , imgsz* 1.5 + gs 随机选取尺寸
if opt.multi_scale:
sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
sf = sz / max(imgs.shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
# Forward
# 混合精度训练
with amp.autocast(enabled=cuda): # autocast上下文应该只包含网络的前向过程(包括loss的计算) ,而不要包含反向传播
pred = model(imgs) # forward 前向运算
# 在前面的 437行左右的位置, compute_loss: ComputeLoss = ComputeLoss(model) 进行了初始化 model的 loss
# 主要应用的是 loss.py中的ComputeLoss类实例化了一个ComputerLoss,
# 利用通过超参数的 fl_gamma: 大于0的设置,启用 Focallost ,focallost主要解决的是 目标检测阶段one-stage 正负样本不平衡的问题
# 与此同时 , ComputeLoss中的 调用的是 metrics.py中的 bbox_iou , 默认启用的是 Ciou=True ,也就是 默认使用Ciou来考察框的定位损失问题
loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
if RANK != -1:
loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
if opt.quad:
loss *= 4.
# Backward 后向传播
scaler.scale(loss).backward()
# Optimize ,优化 : 模型反向传播accumulate次之后再根据累计的梯度更新一次参数
if ni - last_opt_step >= accumulate:
'''
scaler.step() 首先把梯度的值 unscale回来
如果梯度的值不是 infs 或者NaNs , 那么调用optimizer.step()来更新权重.
否则,忽略step调用 ,从而保证权重不更新(不被破坏)
'''
scaler.step(optimizer) # optimizer.step 进行参数更新
# 准备着 ,看是否要增大scaler
scaler.update()
optimizer.zero_grad() # 梯度清零
# 用EMA方法对模型的参数做平均 ,以提高测试指标并增加模型的老百姓,减少模型权重抖动
if ema:
ema.update(model)
last_opt_step = ni
# 记录一下 一些信息,展示一些信息
if RANK in [-1, 0]:
# 打印显存 ,进行的轮次 ,损失 ,target的数量和 图片的size等信息
mloss = (mloss * i + loss_items) / (i + 1) # update mean losses,计算 训练多少次的 平均loss
mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
pbar.set_description(('%10s' * 2 + '%10.4g' * 5) % (
f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
callbacks.run('on_train_batch_end', ni, model, imgs, targets, paths, plots, opt.sync_bn)
# end batch ------------------------------------------------------------------------------------------------
# 每个batch完成以后,会进行学习率的调整
# Scheduler
lr = [x['lr'] for x in optimizer.param_groups] # for loggers
scheduler.step() # 对学习率进行调整
# ....................................................判断是不是最后一轮的训练,如果是就启动验证集.........................
if RANK in [-1, 0]:
# mAP
callbacks.run('on_train_epoch_end', epoch=epoch)
# 添加include的属性
ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
# 判断该epoch是否是最后一轮
final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
# 对测试集进行测试,并计算mAP等指标
# 测试时使用的是EMA模型 ,如果传入 --noval参数 , noval就是 true, not noval就是 false ,也就是 不会启动验证集验证
if not noval or final_epoch: # Calculate mAP
results, maps, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=ema.ema,
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
plots=False,
callbacks=callbacks,
compute_loss=compute_loss)
# Update best mAP ,更新最好的mAP
fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, [email protected], [email protected]]
if fi > best_fitness:
best_fitness = fi
log_vals = list(mloss) + list(results) + lr
callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
# Save model.................................................保存模型...................................
# 保存&加载带checkpoint的模型用于inference或resuming training
# 保存模型,还保存了epoch,results,optimizer等信息
# optimizer将不会在最后一轮完成保存
# model保存的是EMA的模型
if (not nosave) or (final_epoch and not evolve): # if save
ckpt = {'epoch': epoch,
'best_fitness': best_fitness,
'model': deepcopy(de_parallel(model)).half(),
'ema': deepcopy(ema.ema).half(),
'updates': ema.updates,
'optimizer': optimizer.state_dict(),
'wandb_id': loggers.wandb.wandb_run.id if loggers.wandb else None,
'date': datetime.now().isoformat()}
# Save last, best and delete,保存最新的权重到 last.pt中
torch.save(ckpt, last)
# 看是否是组好的fitness,是的话保存权重到 best.pt中
if best_fitness == fi:
torch.save(ckpt, best)
if (epoch > 0) and (opt.save_period > 0) and (epoch % opt.save_period == 0):
torch.save(ckpt, w / f'epoch{epoch}.pt')
del ckpt
callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
# Stop Single-GPU
if RANK == -1 and stopper(epoch=epoch, fitness=fi):
break
# Stop DDP TODO: known issues shttps://github.com/ultralytics/yolov5/pull/4576
# stop = stopper(epoch=epoch, fitness=fi)
# if RANK == 0:
# dist.broadcast_object_list([stop], 0) # broadcast 'stop' to all ranks
# Stop DPP
# with torch_distributed_zero_first(RANK):
# if stop:
# break # must break all DDP ranks
# end epoch ----------------------------------------------------------------------------------------------------
# end training -----------------------------------------------------------------------------------------------------
if RANK in [-1, 0]:
# 打印epoch一共的时间
LOGGER.info(f'
{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
for f in last, best:
if f.exists():
# 调用general.py中的 strip_optimizer( ) 函数.............................剥离权重文件里面的优化器信息...............
strip_optimizer(f) # strip optimizers
# 如果是最好的,再次调用 验证集去验证模型
if f is best:
LOGGER.info(f'
Validating {f}...')
results, _, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=attempt_load(f, device).half(),
iou_thres=0.65 if is_coco else 0.60, # best pycocotools results at 0.65
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
save_json=is_coco,
verbose=True,
plots=True,
callbacks=callbacks,
compute_loss=compute_loss) # val best model with plots
if is_coco:
callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
callbacks.run('on_train_end', last, best, plots, epoch, results)
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
# 显存释放
torch.cuda.empty_cache()
return results
def parse_opt(known=False):
# 建立 参数解析对象parser()
parser = argparse.ArgumentParser()
# add_argument() 就是给谁添加 一个 什么属性
# nargs 指的是 ---> 应该读取 的命令行参数的个数, * 表示 0或者多 , +表示 1或多
# action -- 命令行那个 遇到参数时候的动作, action='store_true' ,表示只要运行时该变量有传参就设置为True
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
# 采用parse_args() 函数来解析获取的参数
# 也就是说这一句 获取了 我们从命令行中输入的 内容并进行了 解析,其他的属性进行了默认
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt
def main(opt, callbacks=Callbacks()):
# Checks, RANK的值在开头有定义
if RANK in [-1, 0]:
# 调用 general.py文件中的 print_args() 函数打印相关信息
print_args(FILE.stem, opt)
# 调用 general.py文件中的 check_git_status()函数, # 这个函数的作用就是检查当前分支版本是否是git上面版本一样,如果不是,
# 落后版本的话就会提醒用户,这个函数在trian.py函数中被使用
check_git_status()
# 在进行最终的检测之前,看一看在requirements.txt要求中 本运行环境有没有没有装的 ,没有的话就更新下载
check_requirements(exclude=['thop'])
# Resume ,如果我们键盘输入的命令中带有 --resume ,也就是断点训练 ,并且没有指定超参数进化
if opt.resume and not check_wandb_resume(opt) and not opt.evolve: # resume an interrupted run
# 如果传入--resume 就是true , isinstance(opt.resume, str) 就错
# 调用general.py中的 get_latest_run() 获取最近训练的权重文件 last.pt 给ckpt
ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # 指定最近跑的模型的路径
# 判断ckpt是不是文件 , 如果不是文件就报错
assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist' # 警告: 检查的恢复点不存在
# 如果是文件,就去上级目录下找opt.yaml来恢复训练
with open(Path(ckpt).parent.parent / 'opt.yaml', errors='ignore') as f:
opt = argparse.Namespace(**yaml.safe_load(f)) # replace
opt.cfg, opt.weights, opt.resume = '', ckpt, True # reinstate
LOGGER.info(f'Resuming training from {ckpt}') # 打印信息: 正在从 ckpt (即最新的last.pt文件处)处断点训练
else:
# 否则就是 没有resume ,或者传入了 --evolve ,于是超参数进化 ,上面not opt.evolve就是false,于是执行下面语句
opt.data, opt.cfg, opt.hyp, opt.weights, opt.project =
check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
# 如果出错, len(opt.cfg) or len(opt.weights), 就打印必须指定——cfg或——weights
if opt.evolve:
opt.project = str(ROOT / 'runs/evolve')
opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
# 也就是超参数进化不能与 断点训练同用 , 如果 开启超参数进化,必须要先指定一个 cfg或者weights
# opt.save_dir =runs/evolve/exp
# 使用torch_utils中 select_device() 函数 来根据 device的值 进行设备选择
device = select_device(opt.device, batch_size=opt.batch_size)
# DDP mode
"""
分布式训练相关设置
设置DDP模式的参数
world_size : 表示全局进程的个数
global_rank: 进程编号
"""
if LOCAL_RANK != -1:
assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
assert opt.batch_size % WORLD_SIZE == 0, '--batch-size must be multiple of CUDA device count'
# 批大小必须是CUDA设备的整数倍
assert not opt.image_weights, '--image-weights argument is not compatible with DDP training'
# --image-weights参数与DDP训练不兼容
assert not opt.evolve, '--evolve argument is not compatible with DDP training' # -evolve参数与DDP训练不兼容
torch.cuda.set_device(LOCAL_RANK)
device = torch.device('cuda', LOCAL_RANK) # 根据 Gpu的编号选择设备
# 初始化进程数组
dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo")
# Train opt.evole 如果是false ,也就是没有超参数进化
if not opt.evolve:
# 就开启训练...................................................
train(opt.hyp, opt, device, callbacks)
if WORLD_SIZE > 1 and RANK == 0:
LOGGER.info('Destroying process group... ') # 正在销毁过程组,开头WORLD_SIZE =1 ,RANK为-1 ,所以不会执行这一句
dist.destroy_process_group()
# 也就是超参数进化不能与 断点训练同用 , 如果 开启超参数进化,必学要先指定一个 cfg或者weights
# Evolve hyperparameters (optional), 就开始进化hyp中的参数
'''
yolov5提供了一种超参数优化的方法–Hyperparameter Evolution,即超参数进化。超参数进化是一种利用 遗传算法(GA)
进行超参数优化的方法,我们可以通过该方法选择更加合适自己的超参数。提供的默认参数也是通过在COCO数据集上使用超参数进化得来的。
由于超参数进化会耗费大量的资源和时间,如果默认参数训练出来的结果能满足你的使用,使用默认参数也是不错的选择。
'''
else: # evolve为真的话就开启超参数进化
# hyp中的参数进化 的进化列表meta ( 突变规模 , 最小值 , 最大值限制 )
meta = {'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
'box': (1, 0.02, 0.2), # box loss gain
'cls': (1, 0.2, 4.0), # cls loss gain
'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
'iou_t': (0, 0.1, 0.7), # IoU training threshold
'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
'scale': (1, 0.0, 0.9), # image scale (+/- gain)
'shear': (1, 0.0, 10.0), # image shear (+/- deg)
'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
'mosaic': (1, 0.0, 1.0), # image mosaic (probability)
'mixup': (1, 0.0, 1.0), # image mixup (probability)
'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
# 打开超参数的文件
with open(opt.hyp, errors='ignore') as f:
hyp = yaml.safe_load(f) # load hyps dict , 也就是将 hyp文件给hyp
if 'anchors' not in hyp: # anchors commented in hyp.yaml ,也就是每一个特征图的生成几个先验框 , 如果anchors不在,设置为3
hyp['anchors'] = 3
opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
# ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
# 就是说 . 进化以后的evolve_yaml, evolve_csv存放在, opt.save_dir =runs/evolve/exp 下
evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
if opt.bucket: # 如果传入的是 --bucket ,就是云盘谷歌
os.system(f'gsutil cp gs://{opt.bucket}/evolve.csv {save_dir}') # download evolve.csv if exists
# 这时候我们已经知道了原始的超参数 hyp 和 一个 超参数进化规则的列表 meta
'''
这里的进化算法是 : 根据之前训练时的hyp来确定一个base hyp再进化突变:
具体方法:
通过之前每次进化的得到的results来确定之前每个 hyp权重
有了 每个 hyp和每个hyp的权重之后 有两种进化方式
第一种 single: 根据每个hyp的权重随机选择一个之前的hyp作为 base hyp , random.choice(range(n)) , weights=w
第二种 weighted: 根据每个hyp的权重 对之前所有的hyp进行融合 获得一个base hyp (x*w.reeshape(n,1) ) .sum(0) / w.sum()
evolve.csv会记录每次进化之后的results+hyp
每次进化时,hyp会根据之前的result从大到小的排序;
再根据fitness函数计算之前每次进化得到hyp的权重
在确定哪一种进化方法single 还是weighted ,从而进化
'''
# for _ in range(300) : 进化多少次
for _ in range(opt.evolve): # generations to evolve
if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate ,进化以后的保存结果路径存在
# Select parent(s) 遗传算法中的父辈
# 选择进化方式 ,如果是 选择第一种的single
parent = 'single' # parent selection method: 'single' or 'weighted'
x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1) # 加载evolve_csv文件
# x的值是(p, R, mAP, F1, test_lossese=(box, obj, cls) ), 之后才是hyp的值
# 选取至多前5次的进化的结果
n = min(5, len(x)) # number of previous results to consider
x = x[np.argsort(-fitness(x))][:n] # top n mutations
# 根据results计算hyp的权重,调用metrics.py中的fitness()
w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
# 如果是选择第一种方式 single就是 random.choice(range(n)) , weights=w.............................
if parent == 'single' or len(x) == 1:
x = x[random.choices(range(n), weights=w)[0]] # weighted selection
# 如果选择第二种方式 weighted 就是 (x*w.reeshape(n,1) ) .sum(0) / w.sum() ..................
elif parent == 'weighted':
x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
# Mutate,超参数进化
mp, s = 0.8, 0.2 # mp 指的的是mutation probability 变异概率 , s指的是sigma
npr = np.random
npr.seed(int(time.time()))
# 获取突变初始值 meta是一个字典 , meta[k][0]就是选择 什么样的参数
g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
ng = len(meta)
v = np.ones(ng)
# 设置突变
while all(v == 1): # mutate until a change occurs (prevent duplicates)
v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
# 将突变添加到 base hyp上
# [i+7] 是因为x中前7个数字为results的指标( p , R , mAP ,F1 , test_lossese=(box , obj ,cls) ),之后才是超参数hyp
for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
hyp[k] = float(x[i + 7] * v[i]) # mutate
# 修剪hyp在规定的范围内
# Constrain to limits
for k, v in meta.items():
hyp[k] = max(hyp[k], v[1]) # lower limit
hyp[k] = min(hyp[k], v[2]) # upper limit
hyp[k] = round(hyp[k], 5) # significant digits
# Train mutation.训练
results = train(hyp.copy(), opt, device, callbacks)
# Write mutation results
# 写入results的对应的hyp到evolve.csv中 , evolve.csv文件每一行为一次进化的结果
# 一行中的前 7个数字 为( p , R , mAP ,F1 , test_lossese=(box , obj ,cls) ) ,之后是hyp
# 保存hyp到yaml文件中去
print_mutation(results, hyp.copy(), save_dir, opt.bucket)
# Plot results,调用 plots.py中的plot_evolve()函数画出 进化结果
plot_evolve(evolve_csv)
# 超参数进化完成 , 结果保存在哪里哪里 , 使用最好的超参数 ,也就是你进化的结果, 例如: python train.py --hyp {evolve_yaml}')
LOGGER.info(f'Hyperparameter evolution finished
'
f"Results saved to {colorstr('bold', save_dir)}
"
f'Use best hyperparameters example: $ python train.py --hyp {evolve_yaml}')
def run(**kwargs):
# Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt')
opt = parse_opt(True)
for k, v in kwargs.items():
setattr(opt, k, v)
main(opt)
if __name__ == "__main__":
opt = parse_opt()
main(opt)
'''
python train.py --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --data data/ab.yaml --img 640 --batch 16 --epoch 300
opt
weights : 加载的权重文件 默认是 yolov5s.pt
cfg : 存储模型结构的配置文件 默认是 ''
data : 存储训练、测试数据的文件 默认是 data/coco128.yaml
hyp : 训练的超参数配置文件 默认是 data/hyps/hyp.scratch.yaml
epochs : 训练总次数 默认是 300
batch-size : 每批次大小, 一个epochs= 总训练量/batch-size 默认是 16
imgsz : 输入图片大小 默认是 640
noval : 不进行验证,默认是False ,也就是一般不指定这个参数的话 会进行验证 ,不过验证发生在最后一个epoch
rect : 是否采用矩形推理 默认是 False
resume : 断点训练(从上次打断训练的结果接着训练) 默认是 False
nosave : 不保存模型 默认是 False
noautoanchor 不主动调整anchor 默认是 False
evolve : 是否进行超参数进化 默认是 False
cache : 是否提前缓存图片到内存,以加快训练速度 默认是 False
device : 训练的设备,cpu / 0 / 0,1,2,3 默认是 ' '
multi-scale 是否进行多尺度训练 默认是 False
single-cls : 数据集是否只有一个类别 默认是 False
adam : 是否使用adam优化器 默认是 False
sync-bn : 是否使用跨卡同步BN,仅在DDP模式中使用
workers : dataloader的最大worker数量 默认是 8
label-smoothing 标签平滑操作 默认是 0.0
patience : 训练次数不在提升性能超过指定次数,提前停止训练 默认是100
project : 默认是 ROOT / 'runs/train' 也就是会在runs文件下创建train文件夹
name : 默认是 exp 也就是会在val文件夹下创建exp文件夹来存放结果
bucket : 谷歌云盘bucket 默认是 False
exist-ok : 默认是 False help='existing project/name ok, do not increment'
quad : 默认是 False help='quad dataloader'
linear-lr : 默认是 False help='linear LR'
freeze : 默认是 [0] help='Freeze layers: backbone=10, first3=0 1 2'
save-period 默认是 -1, help='Save checkpoint every x epochs (disabled if < 1)'
local_rank : 默认是 -1, help='DDP parameter, do not modify'
image-weights 默认是 False help='use weighted image selection for training'
Weights & Biases arguments
entity : 默认是 None, help='W&B: Entity'
upload_dataset : 默认是 False help='W&B: Upload data, "val" option'
bbox_interval : 默认是 -1 help='W&B: Set bounding-box image logging interval'
artifact_alias : 默认是 latest help='W&B: Version of dataset artifact to use'
'''
…
you did it