目录
主要从yolov5s.yaml 的配置文件来逐一解析其中的模块:Focus、C3、SPP、Conv、Bottleneck模块。
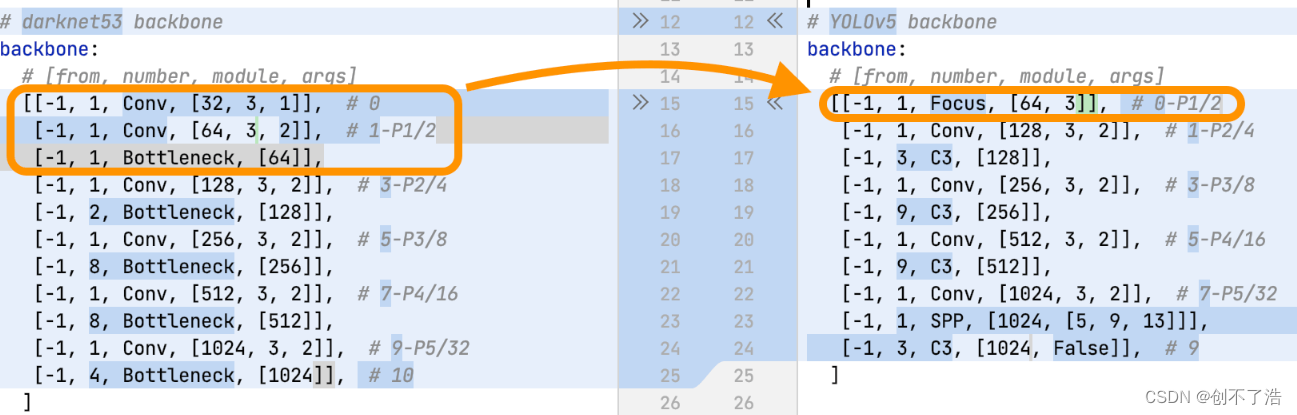
这个是针对最早的v5版本进行讲解,现在2022最新版本是V6.2。有一些细节的差别比如Backbone部分Focus倍替换成6*6的Conv,Neck部分SPP被替换成SPPF等,想要深入学习建议去github学习源码。
yolov5s.yaml
# Parameters
nc: 5 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [24,24,29,84,59,42] # P3/8
- [45,146,75,87,157,49] # P4/16
- [310,167,139,341,127,151] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
yolov5s.yaml基本参数含义
yolov5的各个版本参数的含义是一样的,不同的地方在于网络通道数和模块重复数量,所以只要理解了这个配置文件其他的版本都是差不多意思。
一些基本参数:
nc :数据集中物体的类别数
depth_multiple: 控制网络深度的系数
width_multiple: 控制网络宽度的系数
anchors :给不同尺度特征图分配的anchors,可以看到包含三个列表,表示给三个尺度分配,这三个尺度在**[[17, 20, 23], 1, Detect, [nc, anchors]] 指明**,分别是网络的第17、20和23层。注释P3/8是指输入下采样了23 = 8倍,我们也可以发现网络的第17层特征图为输入的1/8。 根据不同的数据集可以使用K-means聚类算法生成最符合数据集的anchor框。
BackBone:
骨干网络的定义,是一个列表,每一行表示一层。可以看到每一行是有4个元素的列表,[from, number, module, args]说明了这个4个元素的意思。
from: 表示该层的输入从哪来。-1表示输入取自上一层,-2表示上两层,3表示第3层(从0开始数),[-1, 4]表示取自上一层和第4层,依次类推。。。网络层数的数法在注释里已经标出来了,从0开始,每一行表示一层,例如0-P1/2表示第0层,特征图尺寸为输入的1/21。
number: 表示该层模块堆叠的次数,对于C3、BottleneckCSP等模块,表示其子模块的堆叠,具体细节可以查看源代码。当然最终的次数还要乘上depth_multiple系数。
module :表示该层的模块是啥。Conv就是卷积+BN+激活模块。所有的模块在 model/common.py 中都有定义。
args: 表示输入到模块的参数。例如Conv:[128, 3, 2] 表示输出通道128,卷积核尺寸3,strid=2,当然最终的输出通道数还要乘上 width_multiple,对于其他模块,第一个参数值一般都是指输出通道数,具体细节可以看 model/common.py 中的定义。
Head
规则和BackBone一毛一样,这里再解释一些最后一层:
[[17, 20, 23], 1, Detect, [nc, anchors]] 表示把第17、20和23三层作为Detect模块的输入, [nc, anchors]是初始化Detect模块的参数。Detect模块在model/yolo.py中声明,相当于从模型中提出想要的层作为输入,转换为相应的检测头,其输出用来计算loss。
Focus
一、Focus模块的作用
Focus模块在v5中是图片进入backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长的差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
以yolov5s为例,原始的640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。切片操作如下:
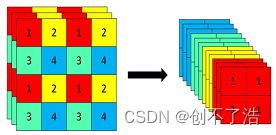
在项目的common.py中有具体代码实现:
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act) # 这里输入通道变成了4倍
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
不太理解张量切片操作的朋友可以具体看看我讲解的切片操作链接: Pytorch 张量操作 Python切片操作
Focus的参数量
参数数量(params):关系到模型大小,单位通常是M,通常参数用float32表示,所以模型大小是参数数量的4倍。
计算量(FLOPs):即浮点运算数,可以用来衡量算法/模型的复杂度,这关系到算法速度,大模型的单位通常为G,小模型单位通常为M;通常只考虑乘加操作的数量,而且只考虑Conv和FC等参数层的计算量,忽略BN和PReLU等,一般情况下,Conv和FC层也会忽略仅纯加操作的计算量,如bias偏置加和shoutcut残差加等,目前技术有BN和CNN可以不加bias。
params计算公式:
Kh × Kw × Cin × Cout
FLOPs计算公式:
Kh × Kw × Cin × Cout × H × W = 即(当前层filter × 输出的feature map)= params × H × W
总所周知,图片在经过Focus模块后,最直观的是起到了下采样的作用,但是和常用的卷积下采样有些不一样,可以对Focus的计算量和普通卷积的下采样计算量进行做个对比:
在yolov5s的网络结构中,可以看到,Focus模块的卷积核是3 × 3,输出通道是32:

那么做个对比:
**普通下采样:**即将一张640 × 640 × 3的图片输入3 × 3的卷积中,步长为2,输出通道32,下采样后得到320 × 320 × 32的特征图,那么普通卷积下采样理论的计算量为:
FLOPs(conv) = 3 × 3 × 3 × 32 × 320 × 320 = 88473600(不考虑bias情况下)
params参数量(conv) = 3 × 3 × 3 × 32 +32 +32 = 928 (后面两个32分别为bias和BN层参数)
**Focus:**将640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过3 × 3的卷积操作,输出通道32,最终变成320 × 320 × 32的特征图,那么Focus理论的计算量为:
FLOPs(Focus) = 3 × 3 × 12 × 32 × 320 × 320 = 353894400(不考虑bias情况下)
params参数量(Focus)= 3 × 3 × 12 × 32 +32 +32 =3520 (为了呼应上图输出的参数量,将后面两个32分别为bias和BN层的参数考虑进去,通常这两个占比比较小可以忽略)
可以明显的看到,Focus的计算量和参数量要比普通卷积要多一些,是普通卷积的4倍,但是下采样时没有信息的丢失。
Yolov3和Yolov5的改进对比
大家可以思考一下,为什么Focus的参数量变大了反而yolov5的推理速度比V3更快精度还更高呢?
对比两者的配置文件可以发现,V5将V3的三层直接用一层Focus替代了,并且Focus不会像下采样那样丢失图片特征信息。所以v5可以又快又准的提升网络性能,Focus做出了不小的功劳,Focus既有下采样的功能,但又在不损失图片信息的前提下下采样。
Focus模块的作用是对图片进行切片,类似于下采样,先将图片变为320×320×12的特征图,再经过3×3的卷积操作,输出通道32,最终变为320×320×32的特征图,是一般卷积计算量的4倍,如此做下采样将无信息丢失。
关于Focus的补充
YOLOv5在v6.0版本后相比之前版本有一个很小的改动,把网络的第一层(原来是Focus模块)换成了一个6x6大小的卷积层。两者在理论上其实等价的,但是对于现有的一些GPU设备(以及相应的优化算法)使用6x6大小的卷积层比使用Focus模块更加高效。详情可以参考这个issue #4825下图是原来的Focus模块(和之前Swin Transformer中的Patch Merging类似),将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map,然后在接上一个3x3大小的卷积层。这和直接使用一个6x6大小的卷积层等效。
网络结构图
具体的网络结构图,可以参考导师画的。在B站也有详细的讲解视频和讲解的博客,导师博客已经获得v5作者Glenn Jocher认可,粉丝太有面子了(都给我哭)。互动现场#6998

C3模块
作用:
1 在新版yolov5中,作者将BottleneckCSP(瓶颈层)模块转变为了C3模块,其结构作用基本相同均为CSP架构,只是在修正单元的选择上有所不同,其包含了3个标准卷积层以及多个Bottleneck模块(数量由配置文件.yaml的n和depth_multiple参数乘积决定)
2 C3相对于BottleneckCSP模块不同的是,经历过残差输出后的Conv模块被去掉了,concat后的标准卷积模块中的激活函数也由LeakyRelu变为了SiLU(同上)。
3 该模块是对残差特征进行学习的主要模块,其结构分为两支,一支使用了上述指定多个Bottleneck堆叠和3个标准卷积层,另一支仅经过一个基本卷积模块,最后将两支进行concat操作。
代码实现:
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
Conv模块
对输入的特征图执行卷积,BN,激活函数操作,在新版的YOLOv5中,作者使用Silu作为激活函数.
代码实现:
class Conv(nn.Module):
# Standard convolution
# ch_in, ch_out, kernel, stride, padding, groups
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
# k为卷积核大小,s为步长
# g即group,当g=1时,相当于普通卷积,当g>1时,进行分组卷积。
# 分组卷积相对与普通卷积减少了参数量,提高训练效率
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.Hardswish() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
Bottleneck模块
作用:
1 先将channel 数减小再扩大(默认减小到一半),具体做法是先进行1×1卷积将channel减小一半,再通过3×3卷积将通道数加倍,并获取特征(共使用两个标准卷积模块),其输入与输出的通道数是不发生改变的。
2 shortcut参数控制是否进行残差连接(使用ResNet)。
3 在yolov5的backbone中的Bottleneck都默认使shortcut为True,在head中的Bottleneck都不使用shortcut。
4 与ResNet对应的,使用add而非concat进行特征融合,使得融合后的特征数不变。
实现:
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
SPP模块
SPP结构
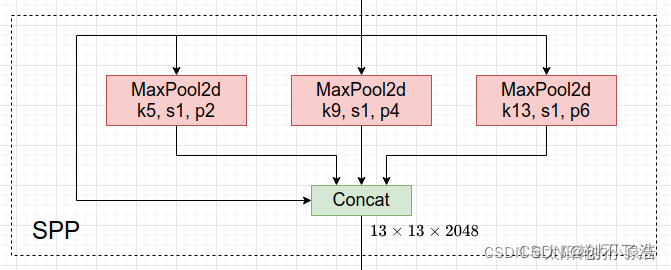
作用:
1 SPP是空间金字塔池化的简称,其先通过一个标准卷积模块将输入通道减半,然后分别做kernel-size为5,9,13的maxpooling(对于不同的核大小,padding是自适应的)。
2 对三次最大池化的结果与未进行池化操作的数据进行concat,最终合并后channel数是原来的2倍。
代码实现:
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
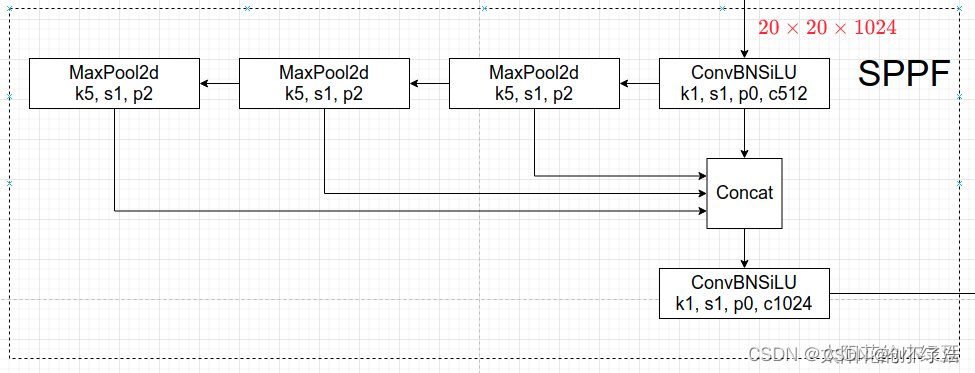
SPPF
V5的6.0版本后Neck部分将SPP换成成了SPPF(Glenn Jocher自己设计的),两者的作用是一样的,但后者效率更高。SPP结构如下图所示,是将输入并行通过多个不同大小的MaxPool,然后做进一步融合,能在一定程度上解决目标多尺度问题。
SPPF结构
SPP和SPPF对比实验
下面做个简单的小实验,对比下SPP和SPPF的计算结果以及速度,代码如下(注意这里将SPPF中最开始和结尾处的1x1卷积层给去掉了,只对比含有MaxPool的部分)。
来自导师代码
import time
import torch
import torch.nn as nn
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3], dim=1)
class SPPF(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
def forward(self, x):
o1 = self.maxpool(x)
o2 = self.maxpool(o1)
o3 = self.maxpool(o2)
return torch.cat([x, o1, o2, o3], dim=1)
def main():
input_tensor = torch.rand(8, 32, 16, 16)
spp = SPP()
sppf = SPPF()
output1 = spp(input_tensor)
output2 = sppf(input_tensor)
print(torch.equal(output1, output2))
t_start = time.time()
for _ in range(100):
spp(input_tensor)
print(f"spp time: {
time.time() - t_start}")
t_start = time.time()
for _ in range(100):
sppf(input_tensor)
print(f"sppf time: {
time.time() - t_start}")
if __name__ == '__main__':
main()
输出
True
spp time: 0.5373051166534424
sppf time: 0.20780706405639648
通过对比可以发现,两者的计算结果是一模一样的,但SPPF比SPP计算速度快了不止两倍,快乐翻倍。
Neck部分另外一个不同点就是New CSP-PAN了,在YOLOv4中,Neck的PAN结构是没有引入CSP结构的,但在YOLOv5中作者在PAN结构中加入了CSP。详情见上面的网络结构图,每个C3模块里都含有CSP结构。在Head部分,YOLOv3, v4, v5都是一样的。
引用
yolov5模型配置yaml文件详解
yolov5中的Focus模块的理解
【YOLOV5】YOLOv5模块解析
YOLOv5网络详解