学习深度学习有些时间了,相信很多小伙伴都已经接触 图像分类、目标检测甚至图像分割(语义分割)等算法了,相信大部分小伙伴都是从分类入门,接触各式各样的 Backbone算法开启自己的炼丹之路。
但是炼丹并非全是 Backbone,更多的是各种辅助代码,而这部分公开的并不多,特别是对于刚接触/入门的人来说就更难了,博主当时就苦于没有完善的辅助代码,走了很多弯路,好在YOLOv5提供了分类、目标检测的完整代码,不同于目标检测,因数据集不同,对应的数据辅助代码也不兼容,图像分类就不会有这方面的影响,只需要更换下模型,设置下输出类即可。可谓相当的成熟,学者必备!!!
官方代码:https://github.com/ultralytics/yolov5
分类任务有四部分组成:tutorial说明,train、val、predict 脚本
对于有一定基础的小伙伴可以直接查看 tutorial 自行运行,如果遇到一些暂无解决的问题时再往下阅读!
小插曲
对于调用官方库的模型时,不同数据集对应不同类别数,如果不想修改官方库的话,可以在创建好模型后,再修改最后的类别数
import torchvison.models as models
model = models.__dict__["resnet50"]() # 加载官方模型库,默认是 imagesnet1000类
dataset_class = len(dataset.classes) # 计算训练数据集的类别数
num_feature = model.fc.in_features
model.fc = nn.Sequential(nn.Linear(num_feature, dataset_class),
nn.LogSofmax(dim=1))
model.load_state_dict(torch.load"model_parmas.pt")
train任务
整个 图像分类任务还是较为复杂的,内容略微庞大,一篇讲解不完,讲解不清的可以下方留言,较难问题博主再出新博文解释。
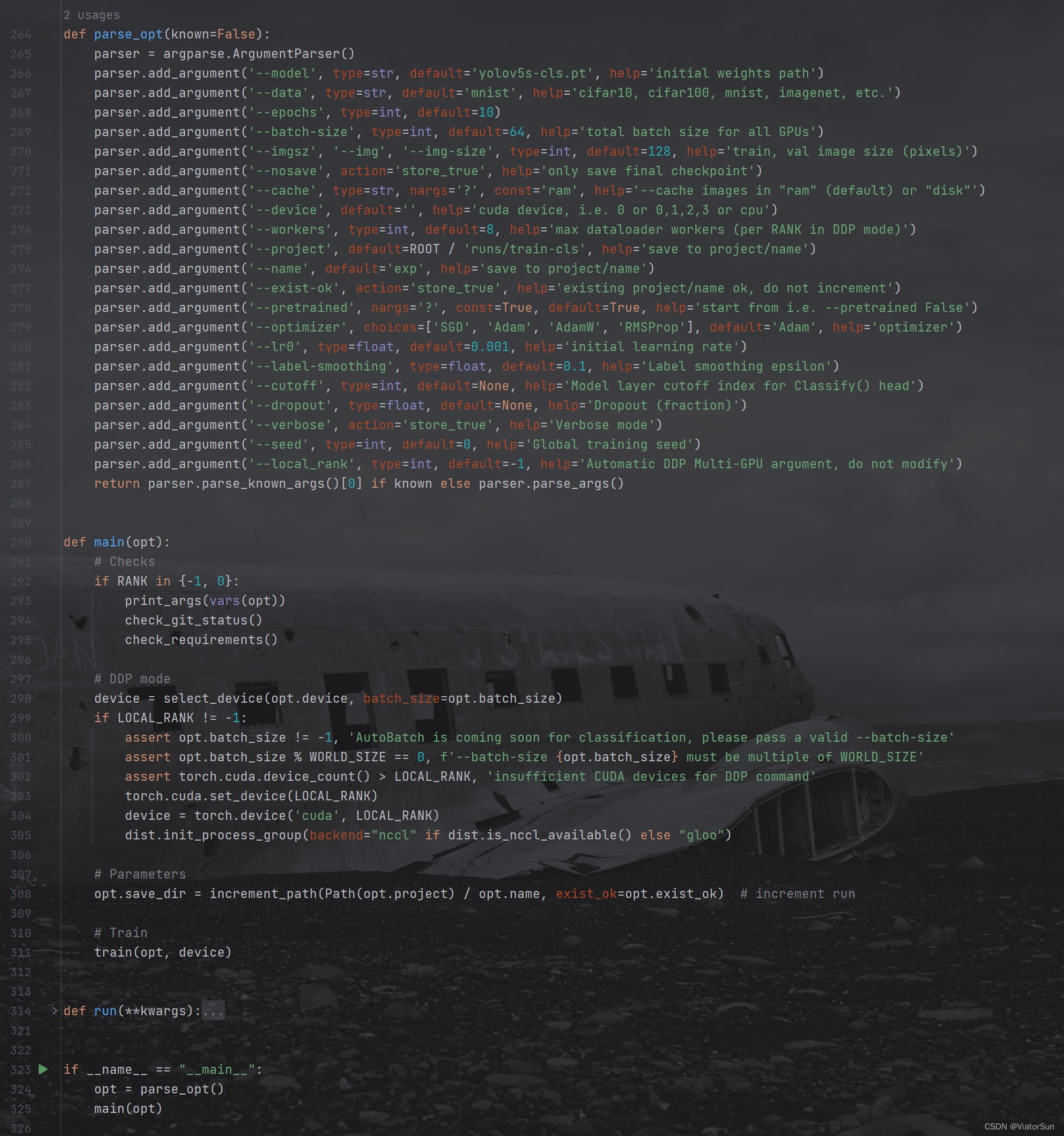
parse_opt() 函数
首先大家在学习代码时,一定要学会 debug 模型,这样才知道代码是如何运行的,一般从 if __name__ == "__main__": 开始进行。
首先是 def parse_opt(known=False): 解析配置参数
-
parser.add_argument('--model', type=str, default='yolov5s-cls.pt', help='initial weights path')
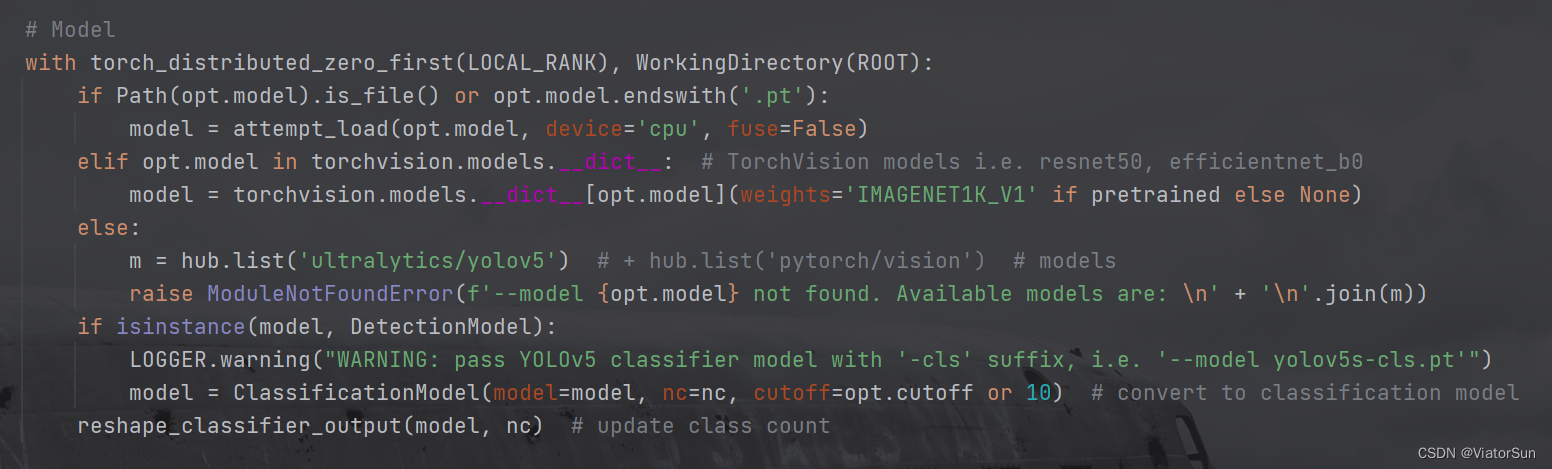
–model 参数是配置模型类型,从下面的解析 --model参数可以看出,如果 --model的值是模型权重名称/路径的话,直接加载到模型model,如果–model是torchvision模型库的,将从torchvision库中读取, 如果都没有的话,将以错误输出。
所以 --model 一定要是 模型权重名称/路径,并且需要能够读取得到才可以。亦可以是torchvision模型库中的模型名称也可以(可以通过torchvision.models.__dict_查看安装的torchvision封装了哪些模型库)
此外torchvision.models.__dict__[opt.model](weights='IMAGENET1K_V1' if pretrained else None)代码并不适用于所有版本的 torchvision模型,还是需要进入 torchvision.model下的具体模型代码中查看 调用方法,否则会出现错误。
-
parser.add_argument('--data', type=str, default='mnist', help='cifar10, cifar100, mnist, imagenet, etc.')
–data 可以是数据集的路径,也可以是数据集而名称, 只是数据集名称必须是 ultralytics 公开的数据集才可以,比如:Classification:Caltech 101、Caltech 256、CIFAR-10、CIFAR-100、Fashion-MNIST、ImageNet、ImageNet-10、Imagenette、Imagewoof、MNIST
如果是自定义的数据集,需要注意的是每一类的所有数据需要放到同一个文件夹下面,如同 cifar10 数据集一样,在 train/val/test 文件夹下分别建立每一类的子文件夹,其中可以存放全部图片,也可以有多层嵌套路径,注意:train/val/test下的文件夹名称和数量 要保持一致,否则训练出来的指标会很差

-
parser.add_argument('--epochs', type=int, default=10)
就是训练的迭代轮数 -
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=128, help='train, val image size (pixels)')
训练时 图片的尺寸大小 -
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
不保存中间每个epoch的权重,如果需要保存的话,将其设置为 False -
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
选择数据的读取方式,ram方式为一次性将所有的数据读取到内存里,以为内存与显存的传输速度高,因此训练市场可以极大降低,前提是内存够大,如果没有足够大的内存的话,可以算法disk硬盘读取,效率略低 -
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
选择训练设备,可以选择:“cup, mps, cuda”(MPS:Apple Metal Performance Shaders) -
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
数据集加载时的线程数 -
parser.add_argument('--project', default=ROOT / 'runs/train-cls', help='save to project/name')
项目保存路径及名称 -
parser.add_argument('--name', default='exp', help='save to project/name')
每次训练的子文件名 -
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
如果已经存在保存文件名/路径,可以覆盖保存 -
parser.add_argument('--pretrained', nargs='?', const=True, default=True, help='start from i.e. --pretrained False')
是否使用预训练权重(前提是必须是torchvision中的模型,官方提供预训练接口的模型才有用) -
parser.add_argument('--optimizer', choices=['SGD', 'Adam', 'AdamW', 'RMSProp'], default='Adam', help='optimizer')
优化器选择,此处官方配置好了 [‘SGD’, ‘Adam’, ‘AdamW’, ‘RMSProp’] 优化器,如果需要其他优化器,需用小伙伴自行配置 -
parser.add_argument('--lr0', type=float, default=0.001, help='initial learning rate')
优化器的初始学习率 -
parser.add_argument('--label-smoothing', type=float, default=0.1, help='Label smoothing epsilon')
label-smoothing 方法,对 label进行 smoothing 处理 -
parser.add_argument('--cutoff', type=int, default=None, help='Model layer cutoff index for Classify() head')
裁切模型的 classify分支 的层数,model.model = model.model[:cutoff] -
parser.add_argument('--dropout', type=float, default=None, help='Dropout (fraction)')
随机失效部分神经元,dropout处理 -
parser.add_argument('--verbose', action='store_true', help='Verbose mode')
冗余模式,记录中间的模型日志 -
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
全局随机种子 -
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
如果小伙伴有多卡,可以采用,此方法可以自动调用多个显卡的资源,即DDP 模式,-1 为不采用
train() 函数
train() 函数前面都是一些模型配置
- 模型训练保存路径,以及配置训练日志,默认情况下,模型训练保存 一个 last.pt 和 best.pt

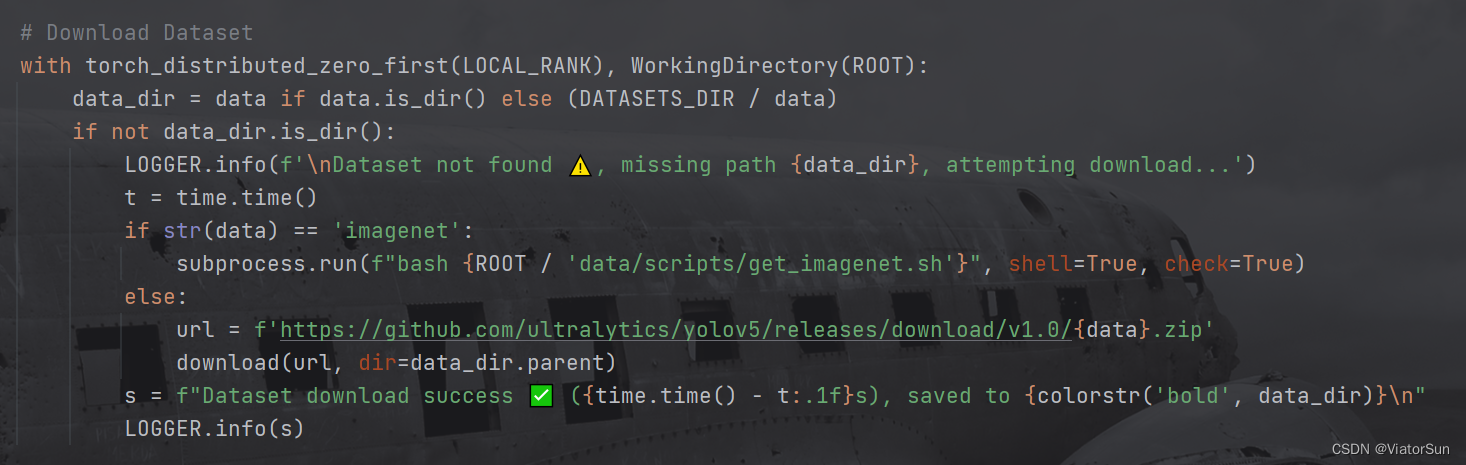
- 数据集下载,如果是官方的数据集,直接 对
--data设置数据集名称即可(完成路径也是可以的),如果是自己的数据集,需要设置数据集路径,只需要给到 train 的上一级目录即可
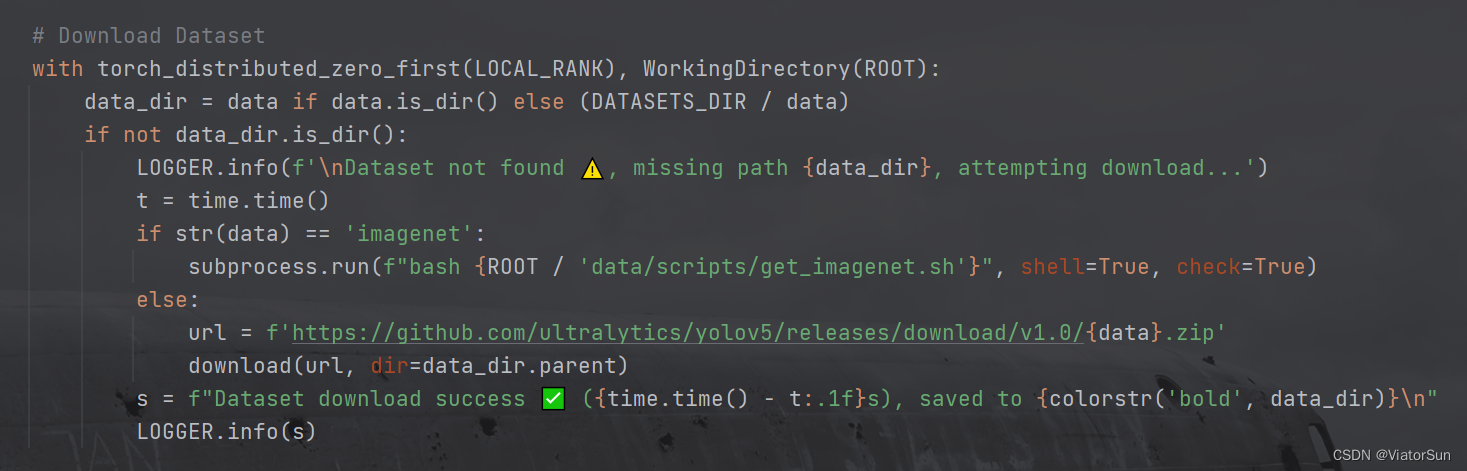
- 数据集构建,此处将读取数据集的类别数以及加载数据集,此处默认是以 test 为验证集的,如果没有test 备份选择 val。如果需要用 val 当验证集,手动改为 val即可。再次提示:train 下的文件夹名称和数量需要和 验证集下的保持一致,否则模型性能很低,且无法提升(惨痛的教训!)
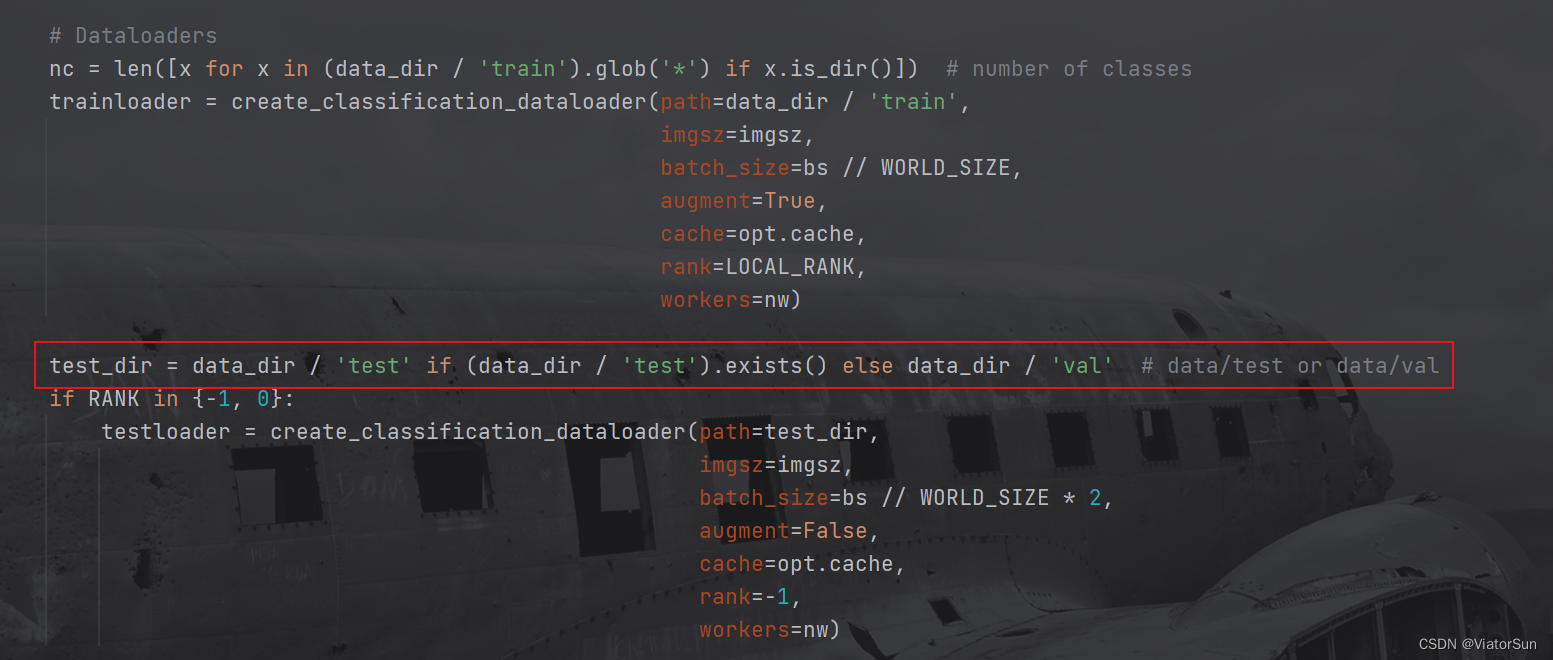
- 构建模型,此处需要注意一点,作为分类模型,模型的输出层必须和数据集的类别数量保持一致,必须!!!
如果不使用 torchvision中的模型,只需要将 model 赋值为自己的模型即可
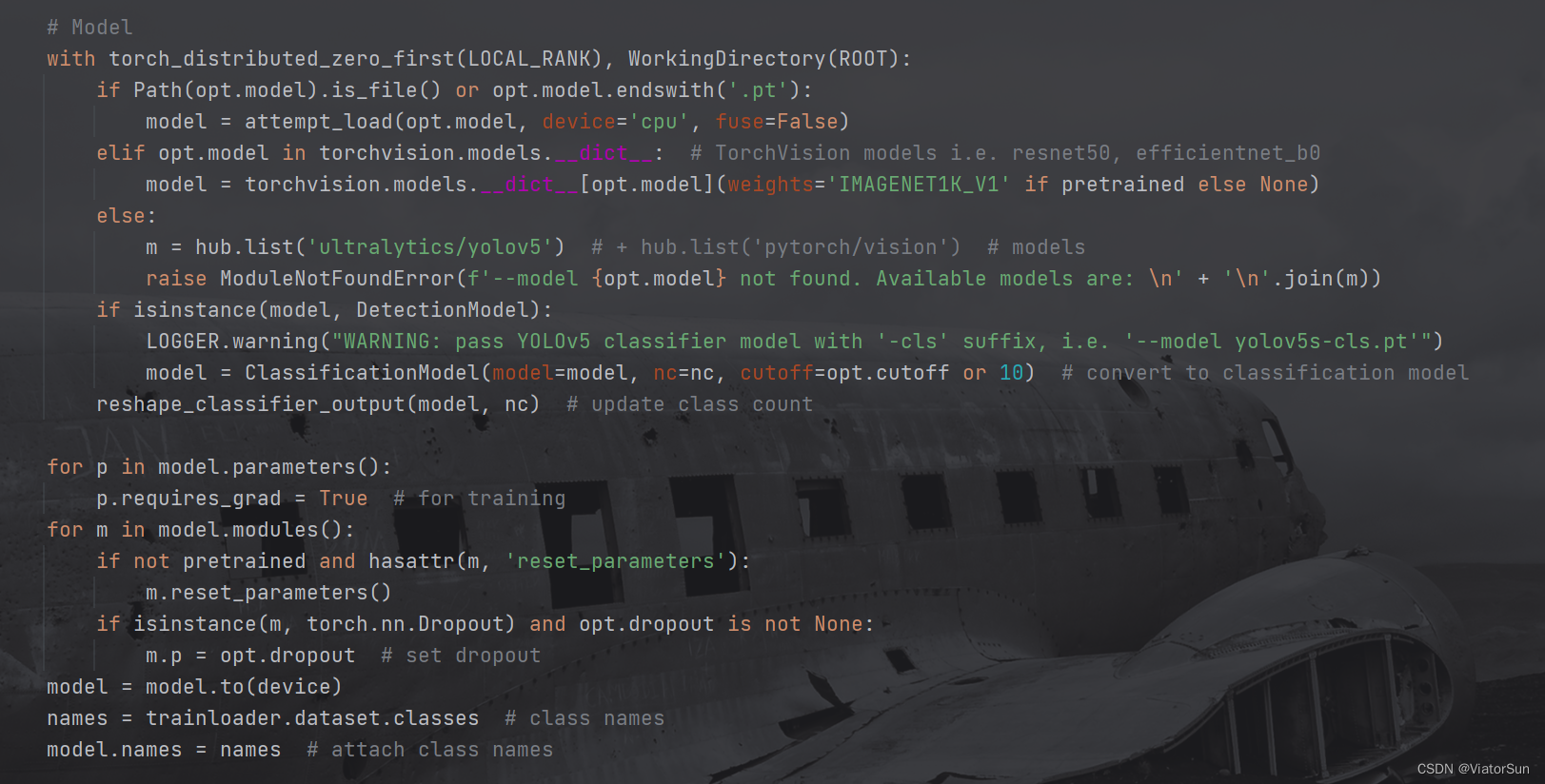
- 日志保存模型等信息,以及加载 数据和标签,此处的数据加载器采用的是迭代器方式,因此采用 nest(iter());然后是优化器设置,学习率、调度器(scheduler)设置 和 EMA配置;最后是损失函数criterion。
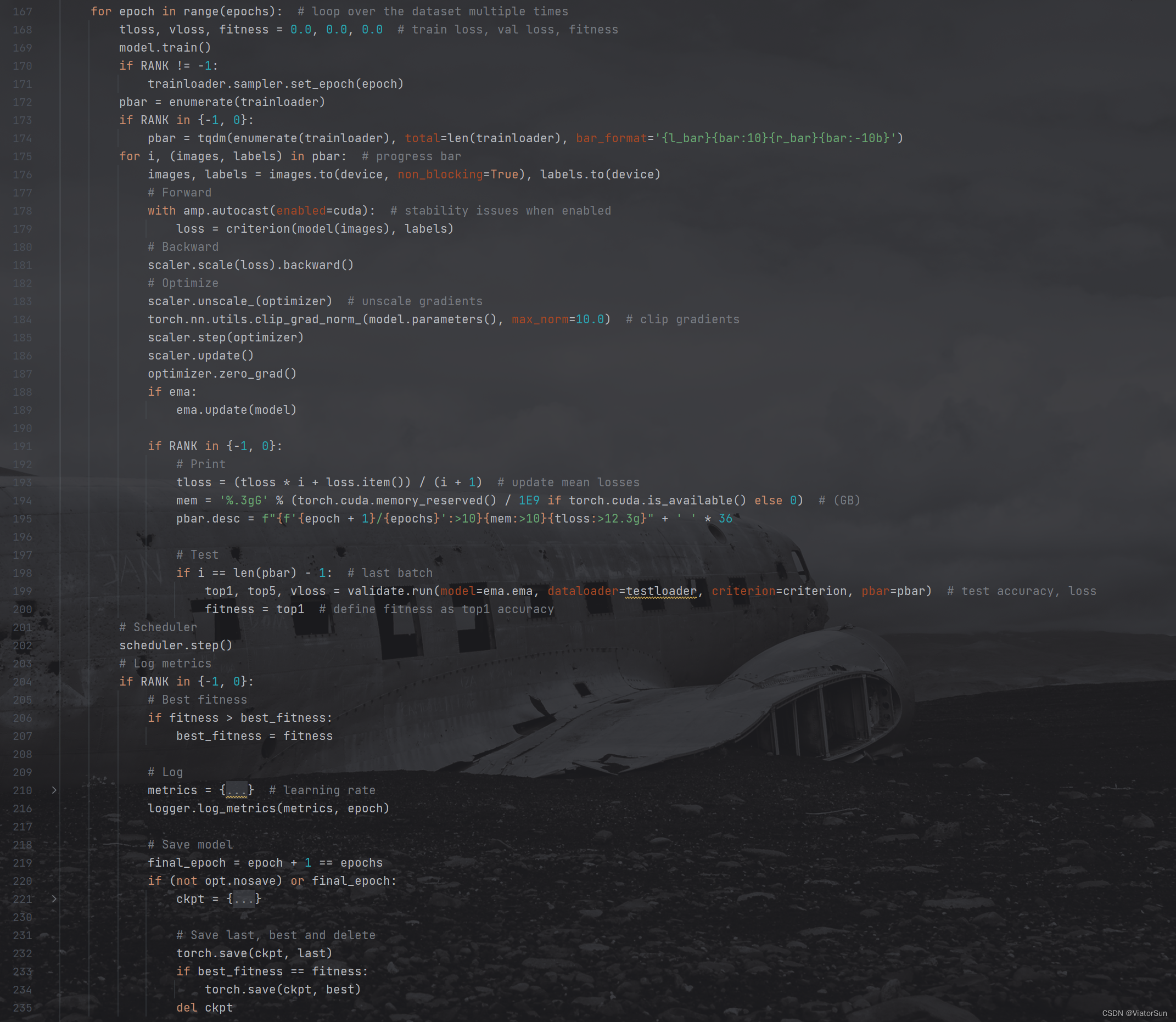
- 进行完上面所有的参数配置,真正的模型训练还在下面这个循环里