原理
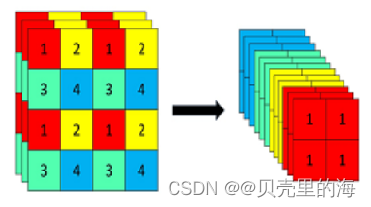
在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长的差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
以yolov5s为例,640 × 640 × 3的图像输入Focus模块,先变成320 × 320 × 12的特征图,再经过一次卷积操作,变成320 × 320 × 32的特征图。
图解如下
Focus模块代码
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act) # 这里输入通道变成了4倍
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
在源码中使用Focus模块配置
# Profile
import torch.nn as nn
from models.common import Focus, Conv, Bottleneck
from utils.torch_utils import profile
m1 = Focus(3, 64, 3) # YOLOv5 Focus layer
m2 = nn.Sequential(Conv(3, 32, 3, 1), Conv(32, 64, 3, 2), Bottleneck(64, 64)) # YOLOv3 first 3 layers
results = profile(input=torch.randn(16, 3, 640, 640), ops=[m1, m2], n=10, device=0) # profile both 10 times at batch-size 16
作者的出发点
YOLOv5的作者创建Focus层的主要目的是减少层数,减少参数,减少FLOPS,减少CUDA内存,增加前进和后退速度,同时最小程度地影响mAP。
作者在YOLOv5上得到的结果

使用一个普通卷积和Focus作为下采样的对比
- 一个普通卷积下采样:即将一张640 × 640 × 3的图片输入3 × 3的卷积中,步长为2,输出通道32,下采样后得到320 × 320 × 32的特征图,那么普通卷积下采样理论的计算量为:
参数数量(params)= 3 × 3 × 3 × 32 +32 +32 = 928 (后面两个32分别为bias和BN层参数)
计算量(FLOPs) = 3 × 3 × 3 × 32 × 320 × 320 = 88473600(不考虑bias情况下) - Focus下采样:将640 × 640 × 3的图像输入Focus结构,先变成320 × 320 × 12的特征图,再经过3 × 3的卷积操作,输出通道32,最终变成320 × 320 × 32的特征图,
参数数量(params)= 3 × 3 × 12 × 32 +32 +32 =3520 (为了呼应上图输出的参数量,将后面两个32分别为bias和BN层的参数考虑进去,通常这两个占比比较小可以忽略)
计算量(FLOPs) = 3 × 3 × 12 × 32 × 320 × 320 = 353894400(不考虑bias情况下)
Focus的计算量和参数量要比一个普通卷积要多一些,是一个普通卷积的4倍,但是下采样时没有信息的丢失。
本文最终结论
如果使用一个Focus层替换一个卷积层,参数量(params)和计算量(FLOPs)是变大了。但是YOLOV5中使用一个Focus代替了原来YOLOV3里的前三层,参数量(params)和计算量(FLOPs)都减少了,所以加速了,对mAP影响极小。
Focus后YOLOv5-6.0版本的大胆改进
YOLOv5-6.0版本中使用了尺寸大小为6 ×6 ,步长为2,padding为2的卷积核代替了Focus模块,便于模型的导出,且效率更高。
名词解释:
- 参数数量(params):指网络模型中需要训练的参数总数。单位通常是M,通常参数用float32表示,所以模型大小是参数数量的4倍。Kh × Kw × Cin × Cout
- 计算量(FLOPs):浮点运算次数,可以用来衡量算法/模型的复杂度,这关系到算法速度。大模型的单位通常为G,小模型单位通常为M;通常只考虑乘加操作的数量,而且只考虑Conv和FC等参数层的计算量,忽略BN和PReLU等,一般情况下,Conv和FC层也会忽略仅纯加操作的计算量,如bias偏置加和shoutcut残差加等,目前技术有BN和CNN可以不加bias。Kh × Kw × Cin × Cout × H × W = 即(当前层filter × 输出的feature map)= params × H × W
参考文章
https://blog.csdn.net/qq_39056987/article/details/112712817
https://github.com/ultralytics/yolov5/discussions/3181