标准分布的累计分布函数的差分去模拟离散的高斯分布
如何理解图像生成中“标准分布的累积分布函数的差分去模拟离散的高斯分布”?
图像生成需要计算整个图片的似然概率的大小,但是通常来说(比如diffusion中求L0)能获得的通常都是图片对应的连续高斯分布(均值和方差),但是图片的像素值是0-255的离散值,因此计算图片的似然需要离散的高斯分布。如何通过连续的分布获取离散的分布有不同的处理方法,其中一种做法的定义是离散的p(x)=连续高斯分布(PDF)概率密度函数中以x为中心一个单位所占的面积大小,此时计算面积大小就可以通过累积分布函数(CDF)去算,具体为离散的p(x)=CDF(x+半个单位)-CDF(x-半个单位),这就是所谓的差分。值得注意的是,累积分布函数通常都是标准正态分布才能近似,因此如果你有的是一个高斯分布(非标准),需要将其归一化后转变为标准正态分布再进行后续处理
discretized_gaussian_log_likelihood
code
IDDPM官方源码的gaussian_diffusion.py
对于t=0,则要计算的就是 L 0 = − log p θ ( x 0 ∣ x 1 ) L_0=-\log p_{\theta}(x_0|x_1) L0=−logpθ(x0∣x1)
当t=0时,则model出来的均值和方差即为 x 0 x_0 x0的均值和方差
# 对应着L[0]损失函数,负对数似然NLL:Negative Log Likelihood,用累积分布函数的差分去拟合高斯分布
# 一般称之为Decoder NLL L0 = -log p(x0|x1)
# discretized_gaussian_log_likelihood: 这是一个常见的操作:用连续分布的累积分布函数的差分,去模拟离散分布
decoder_nll = -discretized_gaussian_log_likelihood(
x_start, means=out["mean"], log_scales=0.5 * out["log_variance"]
) # x_start:就是我们观测的数据,将之带入分布之中,看其可能性为多大
# mean和log_scales就是分布的均值和标准差
# 离散的高斯分布的似然,传入的是x0, 预测的均值,预测的对数的标准差
assert decoder_nll.shape == x_start.shape
decoder_nll = mean_flat(decoder_nll) / np.log(2.0) # 除以np.log(2.0),得到binary_predimension,做一个归一化
# At the first timestep return the decoder NLL,
# otherwise return KL(q(x_{t-1}|x_t,x_0) || p(x_{t-1}|x_t))
# t=0时刻,用离散的高斯分布去计算似然,此时model输出的正是x0的mu和sigma
# t>0时刻,直接用KL散度
# 当t=0时刻返回decoder——nll; 不等于0时返回kl
output = th.where((t == 0), decoder_nll, kl)
return {
"output": output, "pred_xstart": out["pred_xstart"]}
IDDPM官方源码的loss.py
def approx_standard_normal_cdf(x):
"""
A fast approximation of the cumulative distribution function of the
standard normal.
"""
return 0.5 * (1.0 + th.tanh(np.sqrt(2.0 / np.pi) * (x + 0.044715 * th.pow(x, 3))))
def discretized_gaussian_log_likelihood(x, *, means, log_scales):
"""
这是一个常见的操作:用连续分布的累积分布函数的差分,去模拟离散分布
Compute the log-likelihood of a Gaussian distribution discretizing to a
given image.
:param x: the target images. It is assumed that this was uint8 values,
rescaled to the range [-1, 1].
:param means: the Gaussian mean Tensor.
:param log_scales: the Gaussian log stddev Tensor.
:return: a tensor like x of log probabilities (in nats).
"""
assert x.shape == means.shape == log_scales.shape
# 减去均值 x ∈[-1, 1]
centered_x = x - means # 归一化后转变为标准正态分布
inv_stdv = th.exp(-log_scales) # 1/sigma
# 将[-1,1]分为255个bins,
# 最右边的CDF记为1,最左边的CDF记为0
# 256个槽,对于每个槽取左右两边一个微笑的距离, # 图片的像素值是0-255的离散值
plus_in = inv_stdv * (centered_x + 1.0 / 255.0) # 槽的右边
cdf_plus = approx_standard_normal_cdf(plus_in)
min_in = inv_stdv * (centered_x - 1.0 / 255.0) # 槽的左边
cdf_min = approx_standard_normal_cdf(min_in) # 去算一个标准分布的累计分布函数
# 然后再*inv_stdv,就相当于除以一个标准差,就可以得到一个近似的标准分布
# 把这样一个近似的标准分布的累积分布函数给它算出来
# 稳定性的一个操作:把右边的累计分布函数的对数给计算出来,且需要确保最小值不能为0
log_cdf_plus = th.log(cdf_plus.clamp(min=1e-12))
# 同理:要算出左边的
log_one_minus_cdf_min = th.log((1.0 - cdf_min).clamp(min=1e-12))
# 用小范围的CDF之差来表示PDF
cdf_delta = cdf_plus - cdf_min # 两个累计分布函数的差值就是近似等于概率分布的值
# 考虑到两个极限的地方,这里用到了两个where
log_probs = th.where(
x < -0.999,
log_cdf_plus,
th.where(x > 0.999, log_one_minus_cdf_min, th.log(cdf_delta.clamp(min=1e-12))),
)
'''
x<-0.999, 即x在最左边的时候,我们直接用log_cdf_plus,即最右边的,
当x在最小值的位置时,我们认为x左边的那个cdf,我们把它直接赋为0.
x>0.999,即x在最右边的时候,我们直接用1-cdf_min,在最右边的时候,
我们把其累计分布函数强制写为1.
对于二者之间的,我们直接对cdf_delta取一个对数就好
'''
assert log_probs.shape == x.shape
return log_probs
approx_standard_normal_cdf 和 discretized_gaussian_log_likelihood 函数都是用于图像生成模型中的概率分布建模的工具函数。
approx_standard_normal_cdf 函数是用于计算标准正态分布的累积分布函数的一个近似值,这个近似值可以被用来将一个连续分布离散化为有限数量的值。在图像生成模型中,常常使用离散化的高斯分布来对图像的像素值建模,而 approx_standard_normal_cdf 函数提供了一种近似计算这种离散分布的方法。
discretized_gaussian_log_likelihood 函数则是用于计算高斯分布在离散取值下的概率密度函数的对数值。该函数将目标图像和高斯分布的均值和方差作为输入,计算出每个像素值在该分布下的概率密度函数的对数值。这个函数将图像像素值归一化为 [-1, 1] 的范围,然后将其离散化为 256 个值。对于每个值,它首先计算出对应的概率分布的累积分布函数,然后将相邻的两个累积分布函数之差作为该值的概率密度函数的近似值。最终,函数返回每个像素值在高斯分布下的概率密度函数的对数值。
在 discretized_gaussian_log_likelihood 函数中的第一行,我们可以看到这个注释:
It is assumed that this was uint8 values, rescaled to the range [-1, 1].
这个注释说明了输入的图像 x 是在 8 位无符号整数的范围 [0, 255] 内表示的,然后进行了归一化,使得图像的像素值的范围缩放到 [-1, 1] 之间。实现归一化的代码可能出现在 Dataset 或 DataLoader 中,具体实现取决于数据集的情况。在这里,我们只需要知道输入的图像在 discretized_gaussian_log_likelihood 函数中已经被归一化为 [-1, 1] 的范围了。
kl = mean_flat(kl) / np.log(2.0)
mean_flat(kl)即对c,h,w的数字求平均, 出来的kl.shape=(b,)
信息量
信息量可以用来描述事件的信息,定义一个事件 x = x \mathrm{x}=x x=x, I ( x ) = − log P ( x ) I(x)=-\log P(x) I(x)=−logP(x), 其单位为奈特(nats), 1nats表示以 1 e \frac{1}{e} e1的概率观测到一个事件所获得的信息量。
(这里log是以e为底,也有使用以2为底的对数,其单位为bit或者香农shannons)
approx_standard_normal_cdf
为什么approx_standard_normal_cdf里面的表达式是0.5 * (1.0 + th.tanh(np.sqrt(2.0 / np.pi) * (x + 0.044715 * th.pow(x, 3)))),有什么依据吗
这个表达式是一种近似计算标准正态分布的累积分布函数 (Cumulative Distribution Function, CDF) 的方法,它基于激活函数 tanh \tanh tanh 的形状近似于标准正态分布的 CDF。具体而言,它使用了以下两个性质:
tanh ( x ) \tanh(x) tanh(x) 的范围是 ( − 1 , 1 ) (-1, 1) (−1,1),且当 x x x 趋近于正负无穷时, tanh ( x ) \tanh(x) tanh(x) 趋近于 ± 1 \pm 1 ±1。因此, 0.5 ∗ ( 1 + tanh ( x ) ) 0.5 * (1 + \tanh(x)) 0.5∗(1+tanh(x)) 的范围是 ( 0 , 1 ) (0, 1) (0,1),且当 x x x 趋近于正负无穷时,它趋近于 1 1 1。
当 x x x 的分布为标准正态分布时, 2 / π ⋅ x \sqrt{2/\pi} \cdot x 2/π⋅x 的分布的均值为 0 0 0,方差为 2 π \frac{2}{\pi} π2。因此, 2 / π ⋅ x \sqrt{2/\pi} \cdot x 2/π⋅x 的分布形状与标准正态分布的形状相似。
当 x x x 的分布为标准正态分布时, 2 / π ⋅ x \sqrt{2/\pi} \cdot x 2/π⋅x 的分布的均值和方差为:
均值: E [ 2 / π ⋅ x ] = 2 π ⋅ E [ x ] = 0 E[\sqrt{2/\pi} \cdot x] = \sqrt{\frac{2}{\pi}} \cdot E[x] = 0 E[2/π⋅x]=π2⋅E[x]=0
方差: V a r [ 2 / π ⋅ x ] = ( 2 / π ) 2 ⋅ V a r [ x ] = 2 π Var[\sqrt{2/\pi} \cdot x] = (\sqrt{2/\pi})^2 \cdot Var[x] = \frac{2}{\pi} Var[2/π⋅x]=(2/π)2⋅Var[x]=π2
因为标准正态分布的均值为 0,方差为 1,所以 2 / π ⋅ x \sqrt{2/\pi} \cdot x 2/π⋅x 的分布的均值为 0,方差为 2 π \frac{2}{\pi} π2。
通过将这两个性质结合起来,可以将 2 / π ⋅ x \sqrt{2/\pi} \cdot x 2/π⋅x 的分布形状近似为标准正态分布的 CDF,从而得到了 0.5 ∗ ( 1 + tanh ( 2 / π ⋅ x ) ) 0.5 * (1 + \tanh(\sqrt{2/\pi} \cdot x)) 0.5∗(1+tanh(2/π⋅x)) 的近似式。这个式子可以用于计算标准正态分布的累积分布函数,因为 0.5 ∗ ( 1 + tanh ( 2 / π ⋅ x ) ) 0.5 * (1 + \tanh(\sqrt{2/\pi} \cdot x)) 0.5∗(1+tanh(2/π⋅x)) 的范围是 ( 0 , 1 ) (0, 1) (0,1),且当 x x x 趋近于正负无穷时,它趋近于 1 1 1。
这个多项式的形式是通过使用泰勒级数展开式进行推导得到的。具体来说,我们想要一个三次多项式来近似标准正态分布的累积分布函数。因此,我们可以考虑使用泰勒级数展开式来逼近标准正态分布的累积分布函数。泰勒级数展开式如下所示:
Φ ( x ) ≈ 1 2 + 1 2 π x − 1 6 2 π x 3 + 1 24 2 π x 5 \Phi(x) \approx \frac{1}{2}+\frac{1}{\sqrt{2 \pi}} x-\frac{1}{6 \sqrt{2 \pi}} x^{3}+\frac{1}{24 \sqrt{2 \pi}} x^{5} Φ(x)≈21+2π1x−62π1x3+242π1x5
其中, Φ ( x ) \Phi(x) Φ(x) 表示标准正态分布的累积分布函数。将此展开式与 0.5 ∗ ( 1.0 + tanh ( 2 / π ⋅ x ) ) 0.5 * (1.0 + \tanh(\sqrt{2/\pi} \cdot x)) 0.5∗(1.0+tanh(2/π⋅x)) 进行比较,可以发现它们的形式很相似。我们可以通过调整展开式中的常数项和三次项系数,使得它们的近似程度更好。
经过一些推导和调整,我们可以得到以下多项式:
x + 0.44715 x 3 x+0.44715x^3 x+0.44715x3
这个多项式的形式与上面的泰勒展开式非常相似,但是它们的系数已经经过调整,以使得近似程度更好。
tanh激活函数
Tanh的诞生比Sigmoid晚一些,sigmoid函数我们提到过有一个缺点就是输出不以0为中心,使得收敛变慢的问题。而Tanh则就是解决了这个问题。Tanh就是双曲正切函数。等于双曲余弦除双曲正弦。函数表达式和图像见下图。这个函数是一个奇函数。
tanh ( x ) = sinh ( x ) cosh ( x ) = e x − e − x e x + e − x \tanh (x)=\frac{\sinh (x)}{\cosh (x)}=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} tanh(x)=cosh(x)sinh(x)=ex+e−xex−e−x
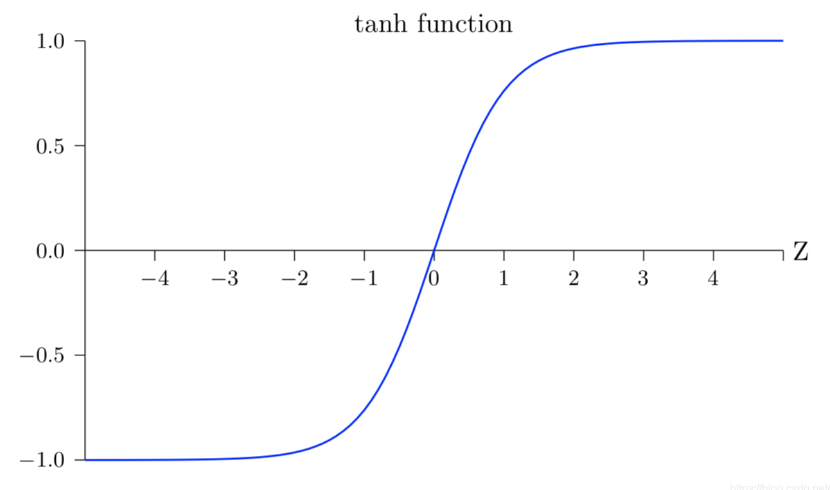
tanh激活函数,写的很好!
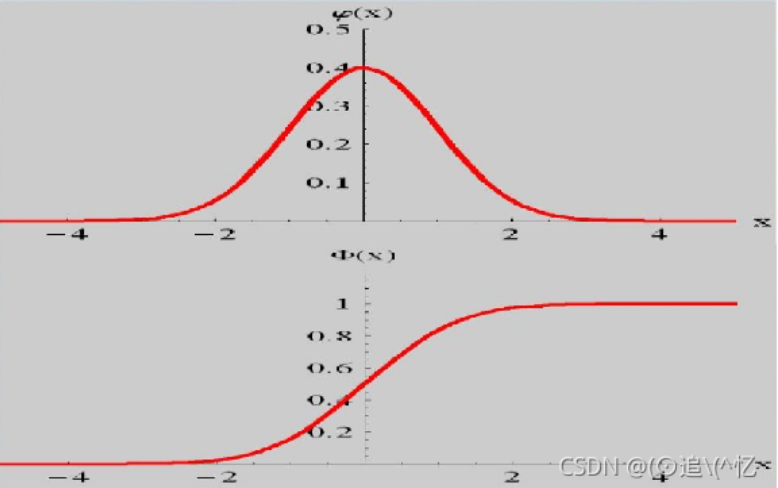
标准正态分布的累积密度函数
标准正态分布的概率密度函数:
φ ( x ) = 1 2 π e − x 2 2 \varphi(x)=\frac{1}{\sqrt{2 \pi}} e^{-\frac{x^{2}}{2}} φ(x)=2π1e−2x2
标准正态分布的累积密度函数:
Φ ( x ) = 1 2 π ∫ − ∞ x e − t 2 2 d t \Phi(x)=\frac{1}{\sqrt{2 \pi}} \int_{-\infty}^{x} e^{-\frac{t^{2}}{2}} d t Φ(x)=2π1∫−∞xe−2t2dt