要点:
- 教师模型和学生模型:
1 查看原模型
DistillationModel是PaddlePaddle框架中用于知识蒸馏的模型。它可以帮助我们在训练一个大模型时,将其知识传递给一个小模型,从而使小模型具有大模型相近的性能。
具体来说,DistillationModel需要两个模型作为输入:一个教师模型和一个学生模型。教师模型通常比学生模型要大,更复杂。在训练过程中,我们将输入数据传递给教师模型和学生模型,然后使用教师模型的输出作为目标标签,使用交叉熵损失函数来计算学生模型的损失。这样,学生模型就会尽可能地学习教师模型的知识。除了交叉熵损失函数之外,我们还可以使用其他损失函数来指导知识蒸馏,例如MSE(均方误差)损失函数和KLD(KL散度)损失函数。
使用DistillationModel的代码示例如下:
import paddle
from paddle.static import InputSpec
from paddlenlp.transformers import DistilBERT
from paddle.incubate.hapi.text import DistillationModel
# 定义教师模型
teacher_model = DistilBERT.from_pretrained('distilbert-base-uncased')
# 定义学生模型
student_model = DistilBERT.from_pretrained('distilbert-base-uncased')
# 定义输入数据
input_spec = [InputSpec(shape=[None, None], dtype='int64', name='input_ids'),
InputSpec(shape=[None, None], dtype='int64', name='position_ids'),
InputSpec(shape=[None, None], dtype='int64', name='segment_ids'),
InputSpec(shape=[None], dtype='int64', name='input_mask')]
# 定义DistillationModel
distill_model = DistillationModel(teacher=teacher_model, student=student_model, input_spec=input_spec, distill_type='soft_label')
# 定义损失函数和优化器
loss_fn = paddle.nn.loss.CrossEntropyLoss()
optimizer = paddle.optimizer.Adam(learning_rate=1e-5, parameters=distill_model.parameters())
# 训练模型
for epoch in range(10):
for batch in dataloader:
input_ids, position_ids, segment_ids, input_mask, labels = batch
teacher_output = teacher_model(input_ids, position_ids, segment_ids, input_mask)
student_output = distill_model(input_ids, position_ids, segment_ids, input_mask)
loss = loss_fn(student_output, labels)
loss.backward()
optimizer.step()
optimizer.clear_grad()2 加载原模型
加载原模型的代码
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" # 防止报错
def load_config(file_path):
"""
Load config from yml/yaml file.
Args:
file_path (str): Path of the config file to be loaded.
Returns: global config
"""
_, ext = os.path.splitext(file_path)
assert ext in ['.yml', '.yaml'], "only support yaml files for now"
config = yaml.load(open(file_path, 'rb'), Loader=yaml.Loader)
return config
config = load_config('PaddleOCR/digital_infer/rec/config.yml')
global_config = config['Global']
post_process_class = build_post_process(config['PostProcess'], global_config)
char_num = len(getattr(post_process_class, 'character'))
for key in config['Architecture']["Models"]:
# print('key:', key)
out_channels_list = {}
if config['PostProcess'][
'name'] == 'DistillationSARLabelDecode':
char_num = char_num - 2
out_channels_list['CTCLabelDecode'] = char_num
out_channels_list['SARLabelDecode'] = char_num + 2
config['Architecture']['Models'][key]['Head']['out_channels_list'] = out_channels_list
# 查看模型
model = build_model(config['Architecture'])
config['Global']['pretrained_model'] = 'PaddleOCR/digital_infer/rec/best_accuracy'
model_is_float16 = load_model(config, model)
model.eval()2.1 查看原模型结构和参数
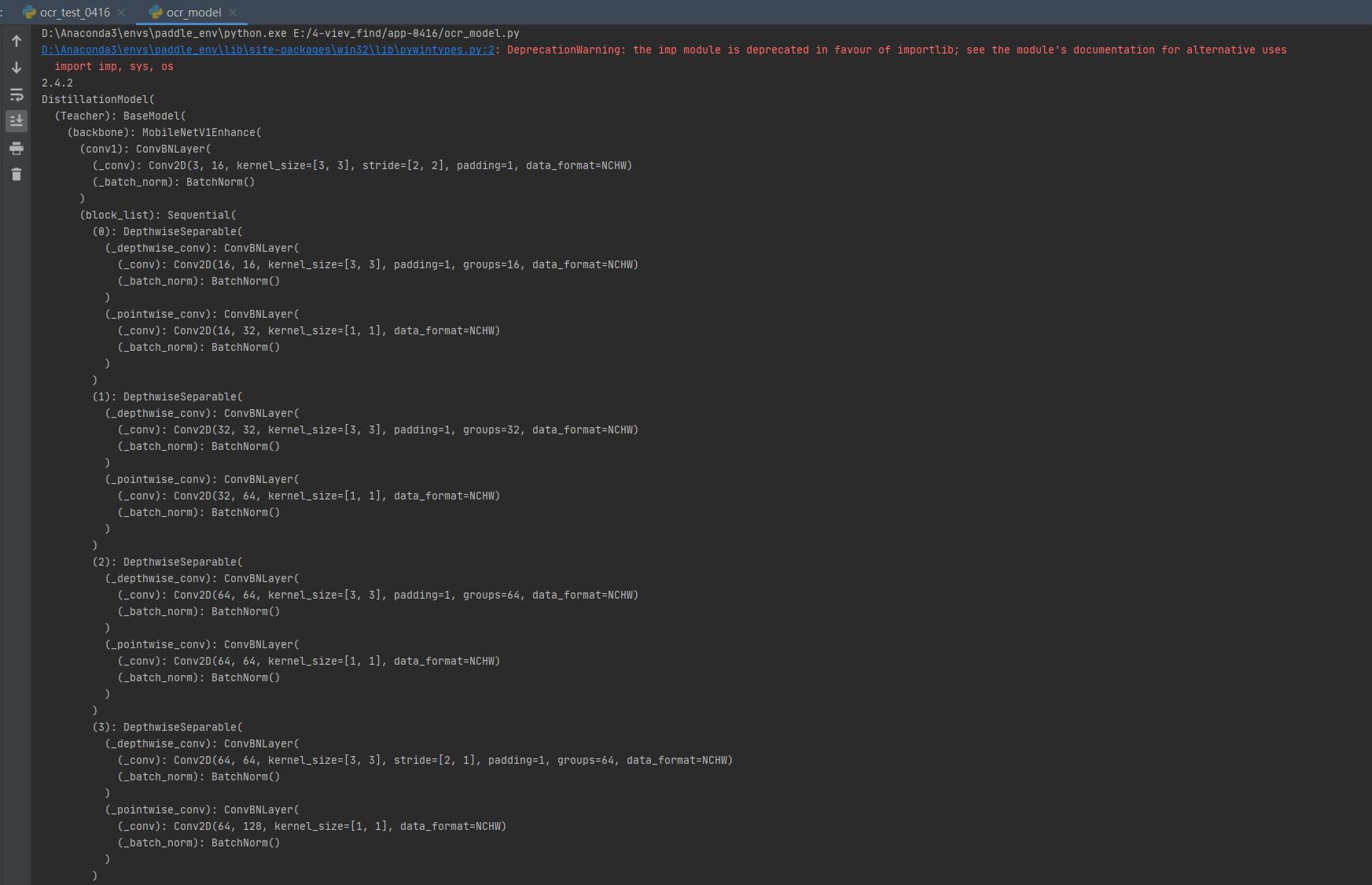
# 打印模型结构
print(model)
# 打印模型参数
for name, param in model.named_parameters():
print(name, param.shape)