1.目标分析:
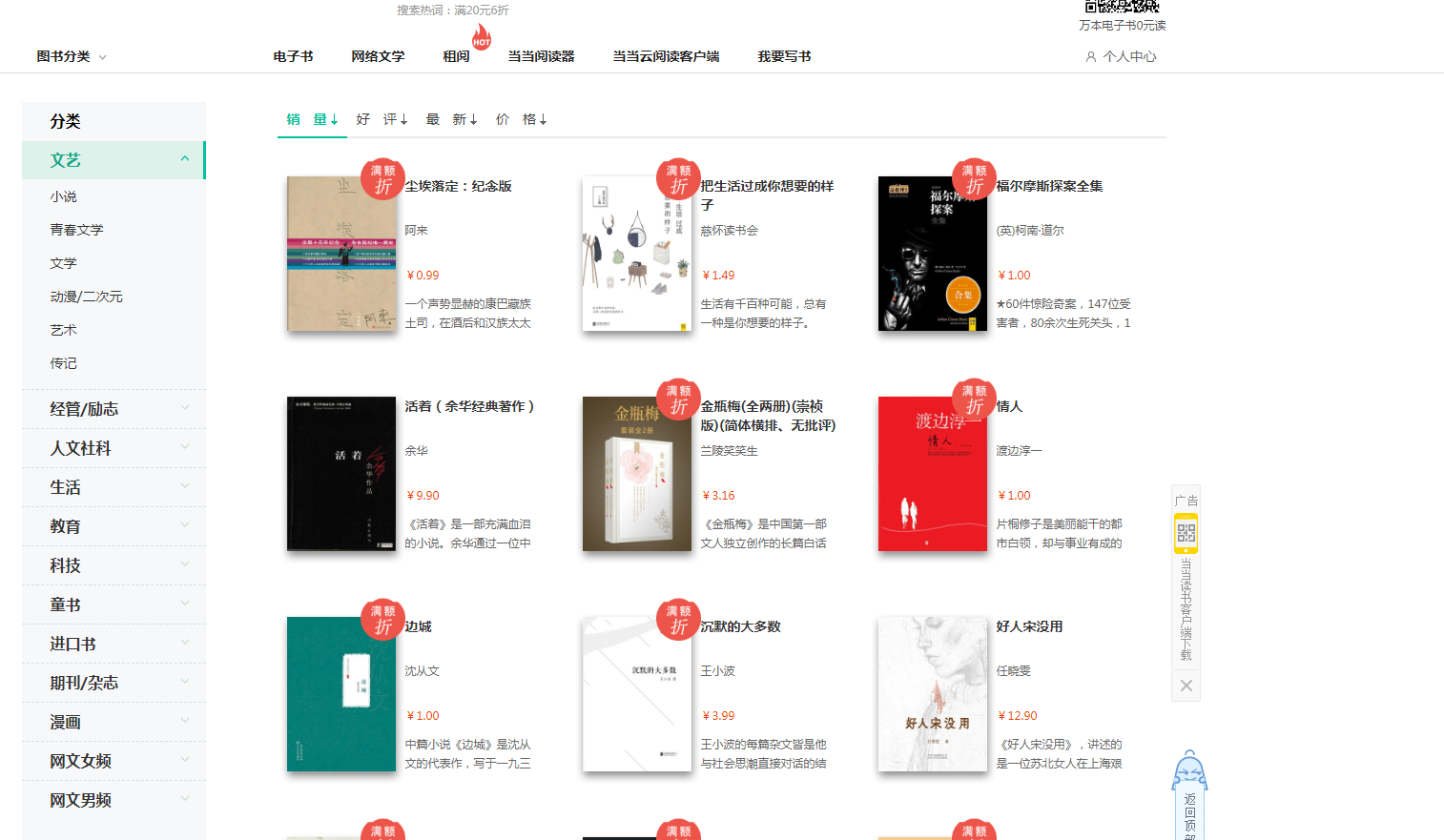
我们想要获取的数据为如下图:
1).每本书的名称
2).每本书的价格
3).每本书的简介

2.网页分析:
网站url:http://e.dangdang.com/list-WY1-dd_sale-0-1.html
如下图所示,每当我们将滚动条滚动到页面底部是,会自动加载数据,并且url不发生变化,诸如此种加载方式即为ajax方式加载的数据
第一步:通过Fiddler抓取加载过程中的数据,并观察规律:
图一:如下图:滚动鼠标让数据加载3次,下图是三次数据加载过程中Fiddler抓取的数据信息,对三次数据加载过程中的抓包信息中的 三个聚焦点进行关注并对比分析
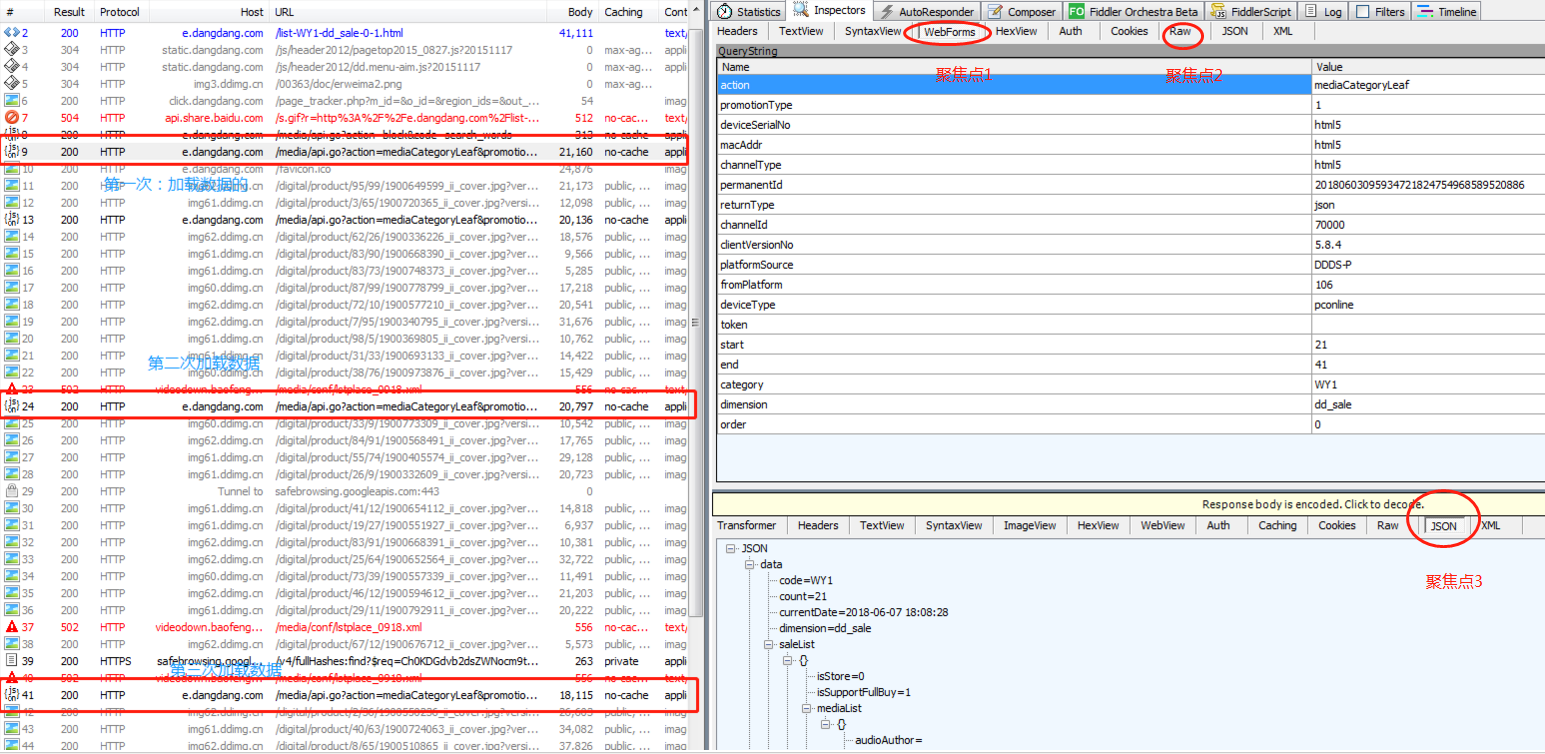
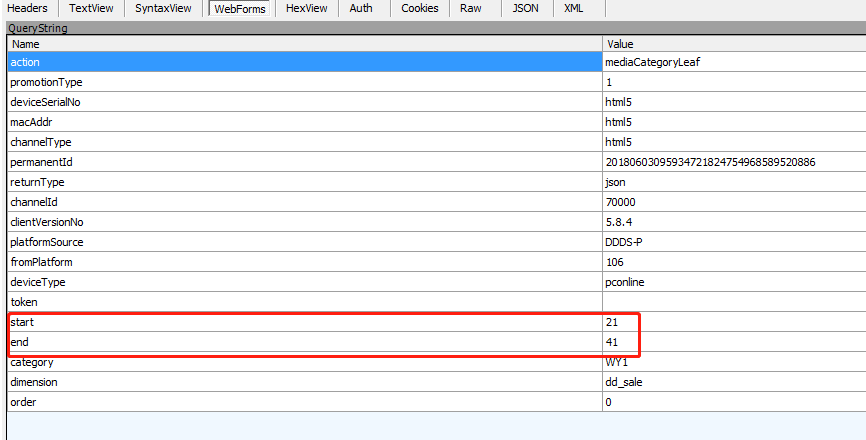
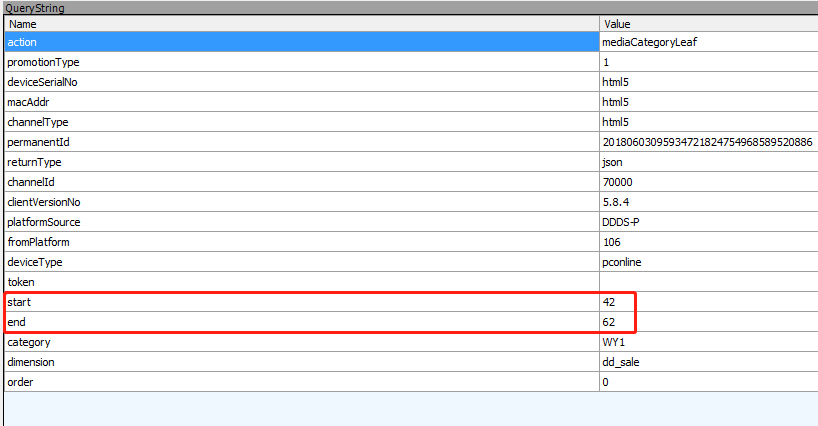
聚焦点1:规律,通过如下两幅图,可以看出,在数据加载过程中,只有start和end在变化,并且end-start=20,两次相连的的数据加载的start满足,后一个是在前一个的基础上加21
第一次加载数据:
第二次加载数据:
聚焦点2:(第一次加载)下图中红框中的url第一个问好后的参数就是聚焦点1中的Querystring中的数据,
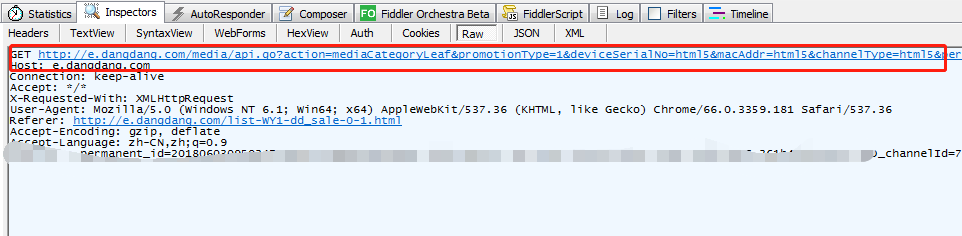
将上图中红色url复制在下方
将上述url复制到谷歌浏览器(带有xpath插件),我们就会得到如下的json数据(即为焦点三种相同的数据),这样的话我们想上述抓包获取的url发请求就能够拿到对应的json数据,我们要爬取的目标在图中用红框标出
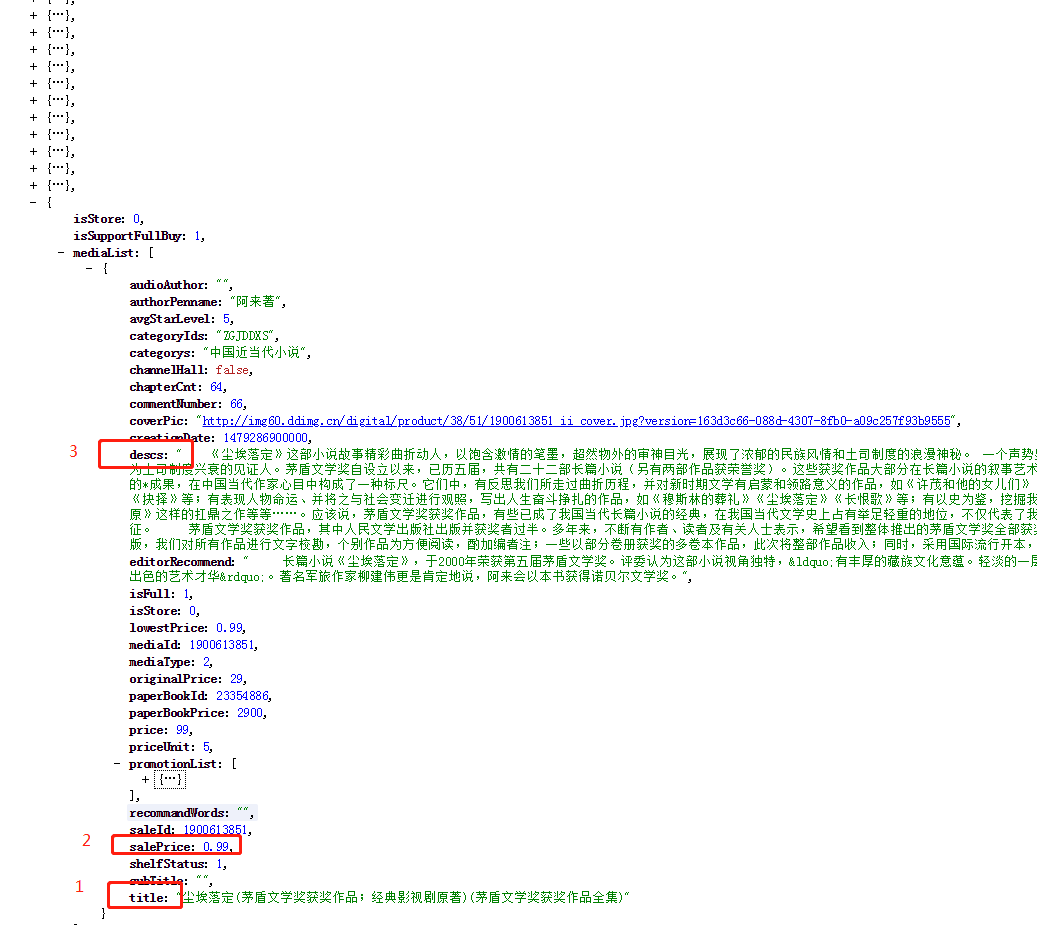
3 scrapy代码如下:
1).框架结构:

2).book.py文件


1 # -*- coding: utf-8 -*- 2 import scrapy 3 from Ebook.items import EbookItem 4 import json 5 class BookSpider(scrapy.Spider): 6 name = "book" 7 allowed_domains = ["dangdang.com"] 8 # start_urls = ['http://e.dangdang.com/media/api.go?'] 9 # 重写start_requests方法 10 def start_requests(self): 11 # 通过Fiddler抓包获取的不含参数信息的url 12 url = 'http://e.dangdang.com/media/api.go?' 13 # 请求头信息User-Agent 14 headers = { 15 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0', 16 } 17 # QueryString中start参数的初始值为21,在此处用start_num表示 18 start_num = 21 19 20 while True: 21 # QueryString中end参数为start+20,在此处用end_num表示 22 end_num = start_num + 20 23 # 构造QueryString查询字符串 24 formdata = { 25 'action':'mediaCategoryLeaf', 26 'promotionType':'1', 27 'deviceSerialNo':'html5', 28 'macAddr':'html5', 29 'channelType':'html5', 30 'permanentId':'20180603095934721824754968589520886', 31 'returnType':'json', 32 'channelId':'70000', 33 'clientVersionNo':'5.8.4', 34 'platformSource':'DDDS-P', 35 'fromPlatform':'106', 36 'deviceType':'pconline', 37 'token':'', 38 'start':str(start_num), 39 'end':str(end_num), 40 'category':'SK', 41 'dimension':'dd_sale', 42 'order':'0', 43 } 44 # 发送请求 45 yield scrapy.FormRequest(url=url,formdata=formdata,headers=headers,callback = self.parse) 46 # 给start加21获取下一页的数据,如此规律循环直到所有数据抓取完毕 47 start_num += 21 48 # parse用来解析相应数据,即我们爬取到的json数据 49 def parse(self, response): 50 data = json.loads(response.text)['data']['saleList'] 51 for each in data: 52 item = EbookItem() 53 info_dict = each['mediaList'][0] 54 # 书的标题 55 item['book_title'] = info_dict['title'] 56 # 书的价格 57 item['book_price'] = info_dict['salePrice'] 58 # 书的简介 59 item['book_desc'] = info_dict['descs'] 60 # 书的封面图片链接 61 item['book_coverPic'] = info_dict['coverPic'] 62 yield item 63 64 65 66 67
3).items.py文件
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # http://doc.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 class EbookItem(scrapy.Item): 10 # define the fields for your item here like: 11 # name = scrapy.Field() 12 # 标题 13 book_title = scrapy.Field() 14 # 价格 15 book_price = scrapy.Field() 16 # 简介 17 book_desc = scrapy.Field() 18 # 封面图片链接 19 book_coverPic = scrapy.Field()
4).pipelines.py文件 ImagesPipeline类的学习文档http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/media-pipeline.html#scrapy.pipeline.images.ImagesPipeline.item_completed
1 # -*- coding: utf-8 -*- 2 # Define your item pipelines here 3 # 4 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 5 # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html 6 7 import json 8 from scrapy.pipelines.images import ImagesPipeline 9 import scrapy 10 from scrapy.utils.project import get_project_settings 11 import os 12 # EbookImagesPipeline是用来下载书的封面图片并的自定义类,继承于ImagesPipeline类 13 class EbookImagesPipeline(ImagesPipeline): 14 # settings.py文件中设置的下载下来的图片存贮的路径 15 IMAGES_STORE = get_project_settings().get('IMAGES_STORE') 16 # 发送url请求的方法 17 def get_media_requests(self,item,info): 18 # 从item中获取图片链接 19 image_url = item['book_coverPic'] 20 headers = { 21 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Mobile Safari/537.36' 22 } 23 # 发送请求下载图片 24 yield scrapy.Request(image_url,headers=headers) 25 # 当所有图片被下载完成后,item_completed方法被调用 26 def item_completed(self,result,item,info): 27 # result的结构为:(success, file_info_or_error) 28 # success:布尔型,表示图片是否下载成功 29 # file_info_or_error:是一个包含下列关键字的字典 30 # -->url:图片下载的url 31 # -->path:图片的存贮路径 32 # -->checksum:图片内容的MD5 hash 33 image_path = [x['path'] for ok,x in result if ok] 34 # 对下载下来的图片重命名 35 os.rename(self.IMAGES_STORE + '/' + image_path[0], self.IMAGES_STORE + '/'+ item['book_title'].encode('utf-8') + '.jpg') 36 return item 37 # 将数据保存到本地 38 class EbookPipeline(object): 39 def __init__(self): 40 # 定义文件 41 self.filename = open('bookinfo.json','w') 42 def process_item(self, item, spider): 43 # 将item中数据转化为json 44 text = json.dumps(dict(item),ensure_ascii=False) + '\n' 45 # 将内容写入到文件中 46 self.filename.write(text.encode('utf-8')) 47 return item 48 def close_spider(self,spider): 49 # 关闭文件 50 self.filename.close()
5).settings.py文件:根据项目需求进行配置即可
1 # -*- coding: utf-8 -*- 2 3 # Scrapy settings for Ebook project 4 # 5 # For simplicity, this file contains only settings considered important or 6 # commonly used. You can find more settings consulting the documentation: 7 # 8 # http://doc.scrapy.org/en/latest/topics/settings.html 9 # http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html 10 # http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html 11 12 BOT_NAME = 'Ebook' 13 SPIDER_MODULES = ['Ebook.spiders'] 14 NEWSPIDER_MODULE = 'Ebook.spiders' 15 # 图片存储路径--新增 16 IMAGES_STORE = '/home/python/Desktop/01-爬虫/01-爬虫0530/ajax形式加载/Ebook/Ebook/spiders/bookimage' 17 # Crawl responsibly by identifying yourself (and your website) on the user-agent 18 USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0' 19 # log日志存放文件 20 LOG_FILE = '123.log' 21 LOG_LEVEL = 'INFO' 22 # Obey robots.txt rules 23 # ROBOTSTXT_OBEY = True 24 25 # Configure maximum concurrent requests performed by Scrapy (default: 16) 26 #CONCURRENT_REQUESTS = 32 27 28 # Configure a delay for requests for the same website (default: 0) 29 # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay 30 # See also autothrottle settings and docs 31 # 下载延迟 32 DOWNLOAD_DELAY = 2.5 33 # The download delay setting will honor only one of: 34 #CONCURRENT_REQUESTS_PER_DOMAIN = 16 35 #CONCURRENT_REQUESTS_PER_IP = 16 36 37 # Disable cookies (enabled by default) 38 # 关闭cookies 39 COOKIES_ENABLED = False 40 41 # Disable Telnet Console (enabled by default) 42 #TELNETCONSOLE_ENABLED = False 43 44 # Override the default request headers: 45 #DEFAULT_REQUEST_HEADERS = { 46 # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 47 # 'Accept-Language': 'en', 48 #} 49 50 # Enable or disable spider middlewares 51 # See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html 52 #SPIDER_MIDDLEWARES = { 53 # 'Ebook.middlewares.MyCustomSpiderMiddleware': 543, 54 #} 55 56 # Enable or disable downloader middlewares 57 # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html 58 #DOWNLOADER_MIDDLEWARES = { 59 # 'Ebook.middlewares.MyCustomDownloaderMiddleware': 543, 60 #} 61 62 # Enable or disable extensions 63 # See http://scrapy.readthedocs.org/en/latest/topics/extensions.html 64 #EXTENSIONS = { 65 # 'scrapy.extensions.telnet.TelnetConsole': None, 66 #} 67 68 # Configure item pipelines 69 # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html 70 # 配置管道文件 71 ITEM_PIPELINES = { 72 'Ebook.pipelines.EbookPipeline': 300, 73 'Ebook.pipelines.EbookImagesPipeline':350, 74 } 75 76 # Enable and configure the AutoThrottle extension (disabled by default) 77 # See http://doc.scrapy.org/en/latest/topics/autothrottle.html 78 #AUTOTHROTTLE_ENABLED = True 79 # The initial download delay 80 #AUTOTHROTTLE_START_DELAY = 5 81 # The maximum download delay to be set in case of high latencies 82 #AUTOTHROTTLE_MAX_DELAY = 60 83 # The average number of requests Scrapy should be sending in parallel to 84 # each remote server 85 #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 86 # Enable showing throttling stats for every response received: 87 #AUTOTHROTTLE_DEBUG = False 88 89 # Enable and configure HTTP caching (disabled by default) 90 # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings 91 #HTTPCACHE_ENABLED = True 92 #HTTPCACHE_EXPIRATION_SECS = 0 93 #HTTPCACHE_DIR = 'httpcache' 94 #HTTPCACHE_IGNORE_HTTP_CODES = [] 95 #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
4.结果:
1).bookinfo.json文件
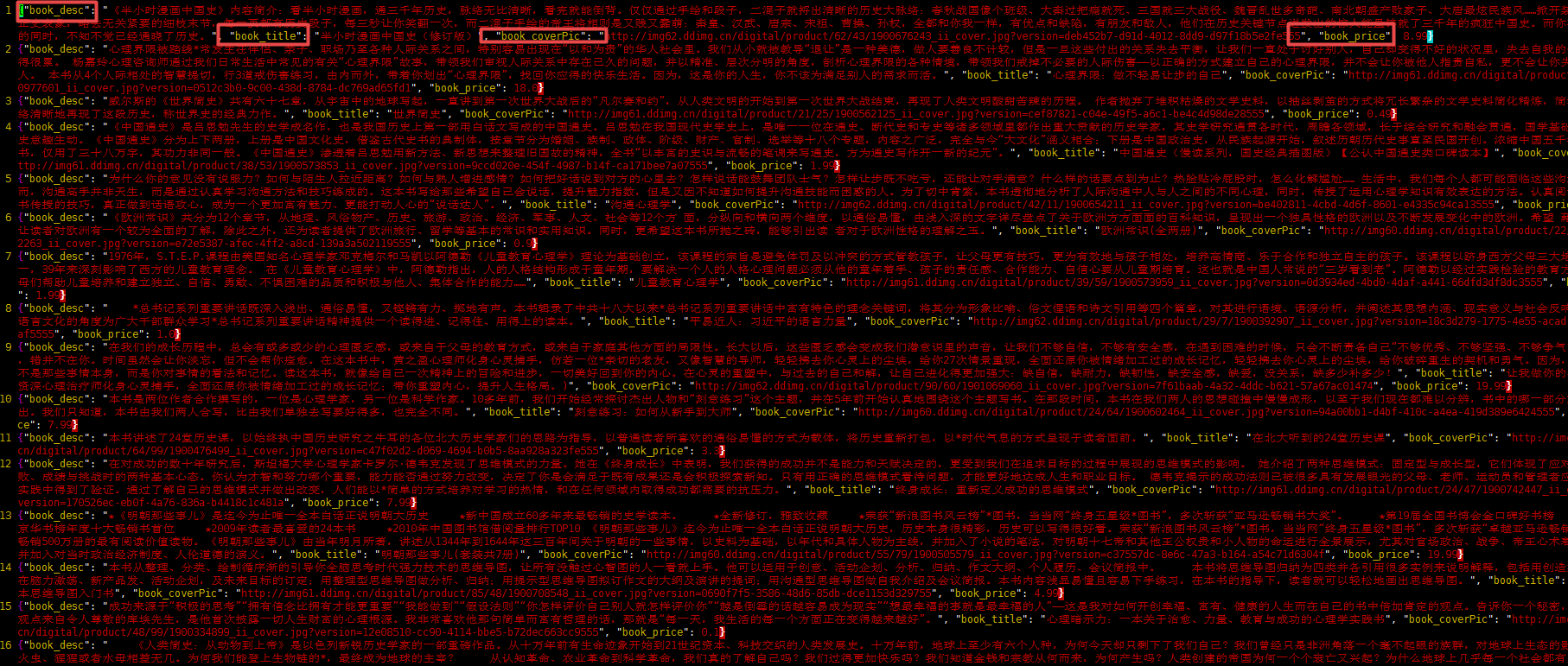
2).书的封面图片
