【Chain-of-Thought 专题】Self-consistency Improves Chain Of Thought Reasoning in Language Models
一、动机
- 虽然大模型在很多NLP任务上表现惊艳,但是他们在推理能力上依然有限。因此最近 Chain-of-Thougth(CoT) 被提出来解决此问题,其通过生成一系列推理路径 Relationales(短文本)来模拟人类一样思考如何解决问题的的过程。
Wei et al. (2022) have proposed chain-of-thought prompting, where a language model is prompted to generate a series of short sentences that mimic the reasoning process a person might employ in solving a task.
例如:
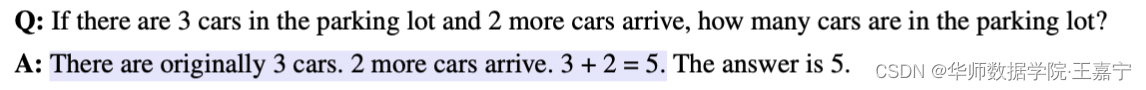
蓝色部分为人工设计的文本,其来模拟解题思考的过程
- Self-consistency(自我一致性)建立在一个直觉基础上:一个复杂的推理任务,其可以有多种推理路径(即解题思路),最终都能够得到正确的答案。即所谓条条大路通罗马。一个问题越需要深思熟虑的思考和分析,那么七可以得出答案的推理路径就越多样化。
Self-consistency leverages the intuition that complex reasoning tasks typically admit multiple reasoning paths that reach a correct answer (Stanovich & West, 2000). The more that deliberate thinking and analysis is required for a problem (Evans, 2010), the greater the diversity of reasoning paths that can recover the answer.
- 具体方法:先从大模型的decoder中采样出一系列个reasoning path,每一个path都能够对应一个最终的答案,我们可以挑选那些能够得到一致答案的较多的path,作为我们的采样得到的reasoning path。基于这个方法,比较符合人类的直觉,即如果很多reasoning path都能得到对应的一个答案,那么这个答案的置信度会比较大。
Such an approach is analogous to the human experience that if multiple different ways of thinking lead to the same answer, one has greater confidence that the final answer is correct.
提炼: 传统的方法是基于greedy decode,即只挑选一个reasoning path。本文的方法是self-consistency,挑选多个reasoning path,并进行类似投票机制选择最佳答案。下面介绍一下具体的方法。
二、方法
本文提出Self-consistency,具体流程如下图所示:
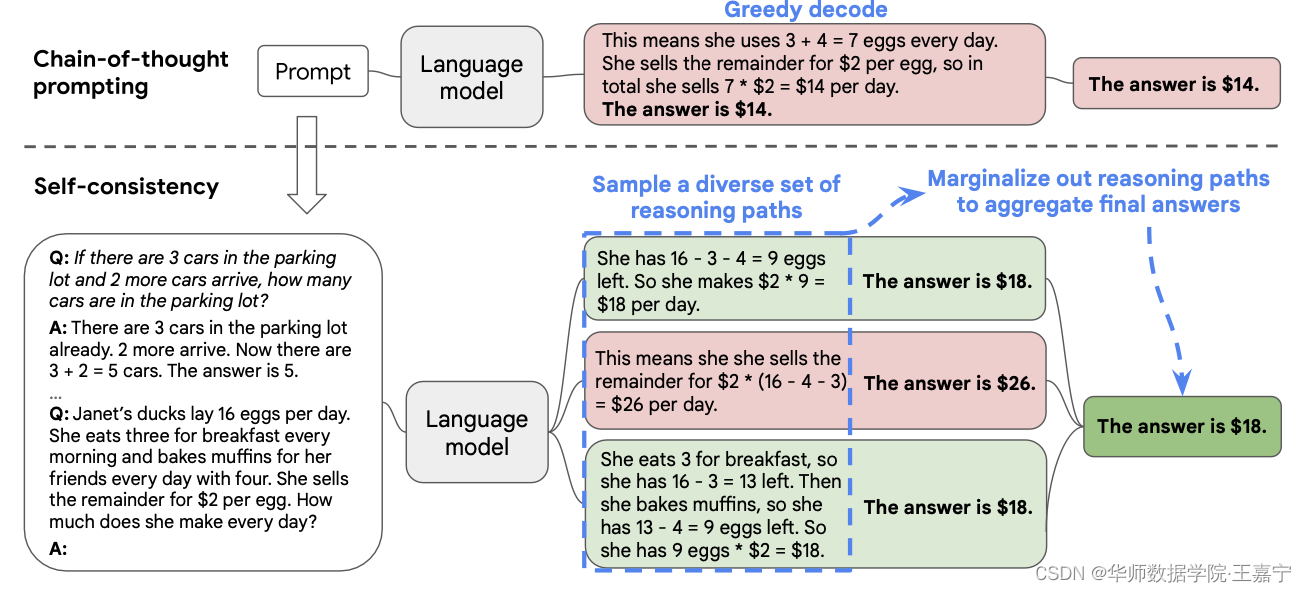
人类的特点是,每个人都有不同的想法。
A salient aspect of humanity is that people think differently
因为大模型并不能很完美地进行推理,所以每次生成答案以及推理路径时,会出现错误。但是我们基于一个假设,即正确的推理过程尽管都不相同,但是都会到达最后正确的答案,且答案是一致的。基于这个想法,本文提出Self-consistency。
具体方法包括如下几个步骤:
- 首先,随机挑选一些样本,并人工标注chain of thought;
- 喂入大模型后,生成多个推理路径 r i \mathbf{r}_i ri,并作为candidate reasoning path集合;
- 最后,对所有的candidate reasoning path进行汇总,得到那些更多一致的答案,即一个投票规则: arg max a ∑ i = 1 m I ( a i = a ) \arg\max_a\sum_{i=1}^{m}\mathbb{I}(\mathbf{a}_i=a) argmaxa∑i=1mI(ai=a)。
除了投票规则外,也可以采用归一化后加权求和的方式,此时需要获得每个token k k k生成的概率,并得到某一个reasoning path对应的概率值:
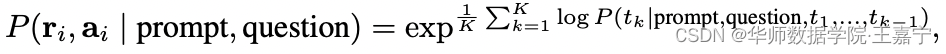
其中 K K K为token的总数。
各种方式获得最终答案的对比情况如下所示:
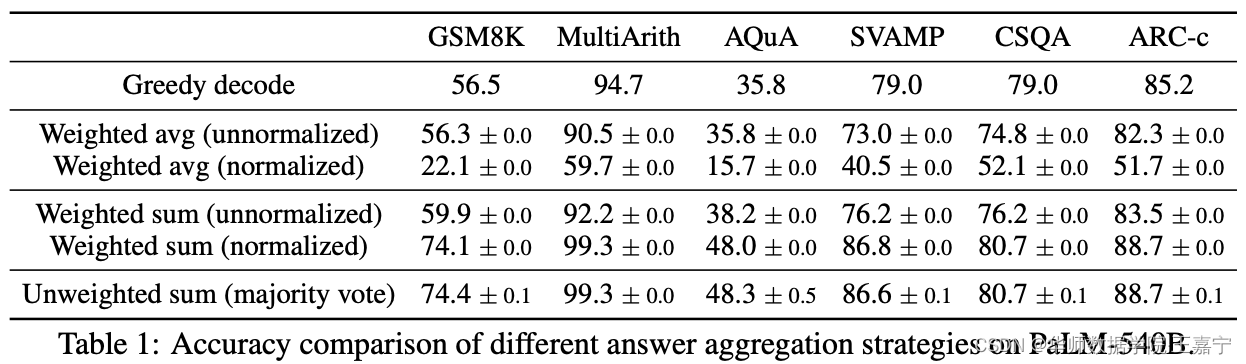
可以发现,直接进行投票表决和归一化后的加权求和两种方式效果较好。
Self-consistency的优势与劣势:
- 优势:探索了一个新的研究领域来寻找较好的答案;
- 劣势:只能适用于固定的答案,即fixed answer。对于开放式的生成,理论上如果能够定义一个评价机制,来衡量两个生成的文本是否一致,则可以拓展到开放生成任务上。
三、实验
数据集

在四个主要的大规模语言模型上进行验证:
● 开源的UL2-20B:https://github.com/google-research/google-research/tree/master/ul2
● GPT3-175B:code-davinci-001 and code-davinci-002
● LaMDA-137B;
● PaLM-540B;
数据集:
● GSM8K;
● SVAMP;
● AQuA;
● StrategyQA
● ARC-challenge
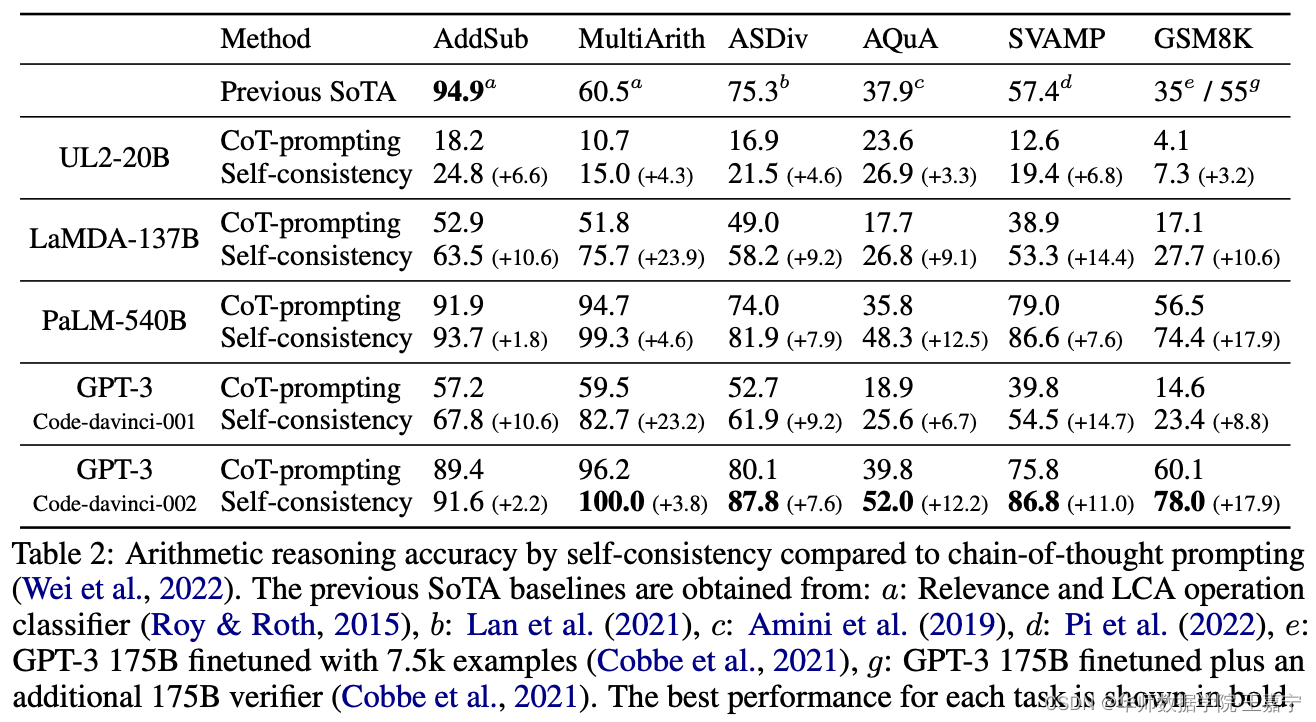
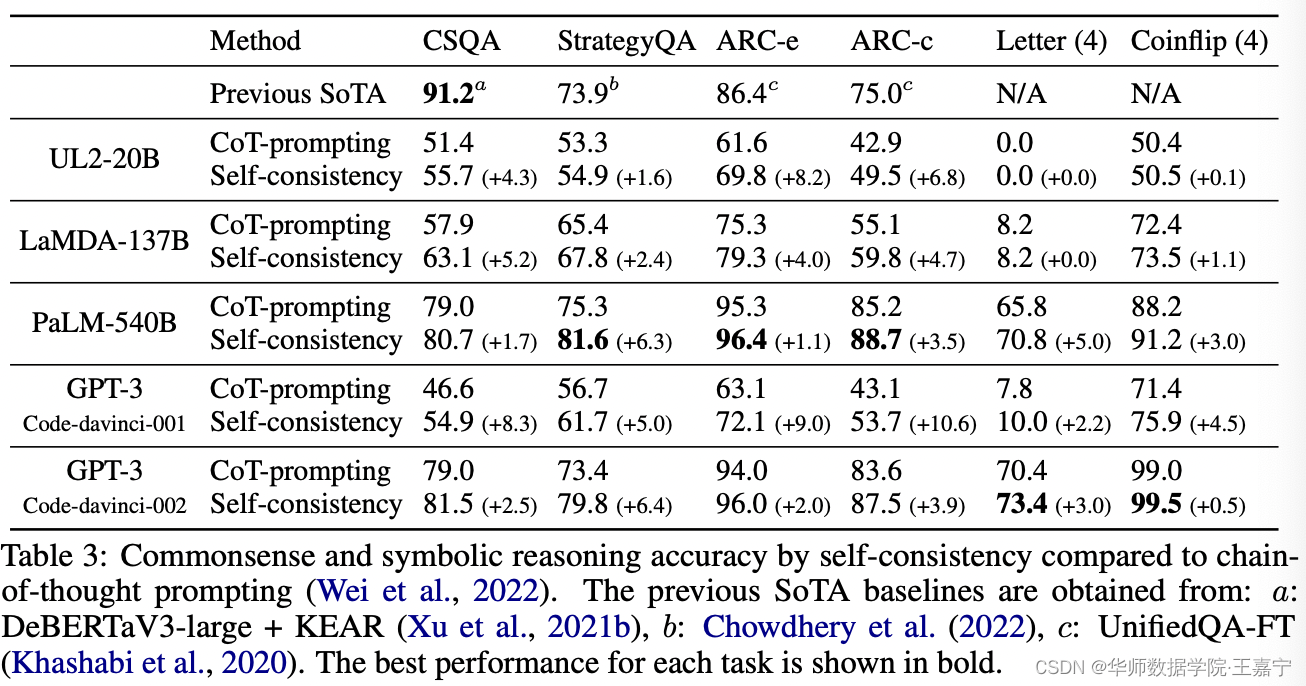
实验结果
四、未来工作
- 可以采用Self-consistency来生成监督数据,提供fine-tuning的数据;
- 思考如何自动生成或构建更靠谱的Rationale。