背景
GPT-3没有被完全激活发挥出实力,主要限制有两点:
1.GPT-3应该摒弃一些无用信息,关注问题本身所关注的信息。“一群人在城市广场上行走”对回答“这些树结出什么果实”这个问题毫无帮助。在这种情况下,GPT-3不得不做出一个漫无目的和有偏见的猜测来回答这个问题。”
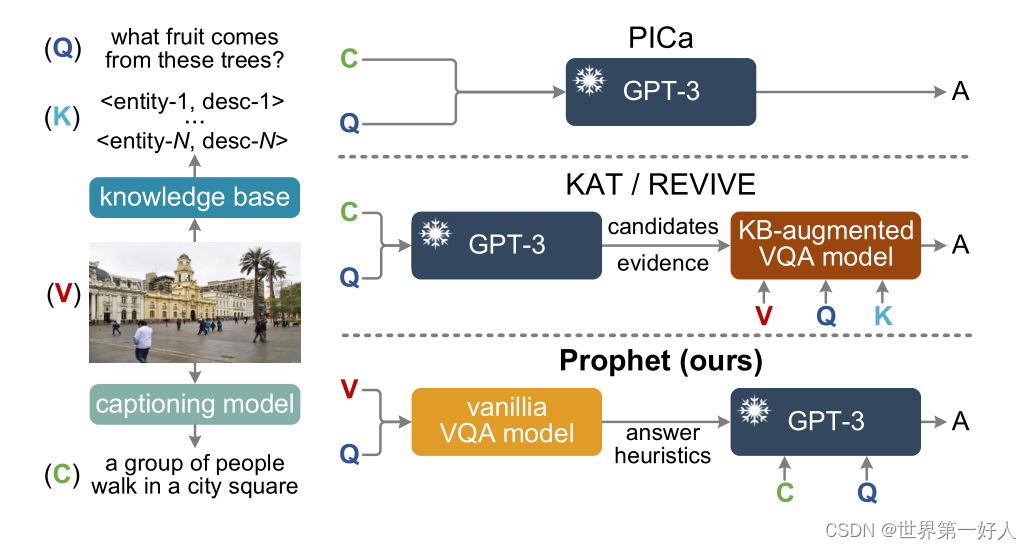
2.GPT-3采用了少量的学习范式,需要一些上下文中的例子来适应新的任务。因此,这些示例的选择对于模型性能至关重要。
{few-shot:GPT-3只需要在推理时将任务的几个例子与作为提示的输入连接起来,并且不需要参数更新。}
本文思路
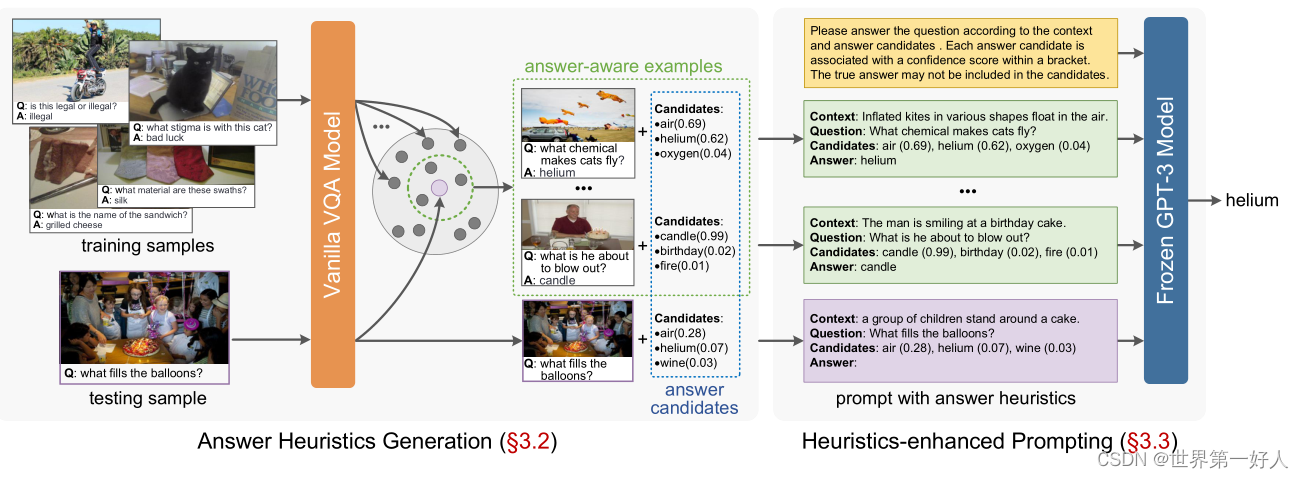
1.首先将一组示例传入VQA模型,得到一组案例。
如:图片是一个老人面前一个生日蛋糕,问题是老人在吹什么?然后VQA生成的答案有蜡烛、生日、火。
问题、语义、候选答案都作为提示输入gpt-3,最终得出想要的答案。
依据上图,最终结果用公式表示为:
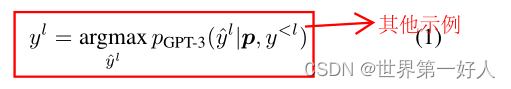
由于GPT-3本质上不理解图像,因此需要使用现成的off-the-shelf captioning模型将图像转换为文字提示(PICa):

PICa的完整提示由一个固定的提示头、几个上下文中的示例和一个测试输入组成。此提示被输入GPT-3以进行答案预测。
阶段一:答案启发式生成
首先解释一下VQA模型一般包含两个子模型,一个作用是embeding生成融合特征z,一个是分类头,用于生成答案词汇y。
首先第一个子模型,用于生成融合特征:

第二个子模型:生成候选词汇答案:
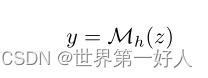
作者将以上模型作为对比的方案,加入GPT-3的指引,验证有效性。
下面是作者初步操作:
制作e集合,其实就是few-shot中的support set。
生成的example首先肯定需要候选答案词汇,作者选择y中TopK得分的:

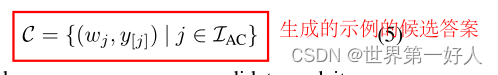
这就是生成的提示示例(w为词汇,y为得分),但是还有一点,是选择哪些图片来当作示例呐?
作者说:
“我们推测这些融合特征位于一个潜在的答案空间中,该空间包含给定图像-问题对的答案的丰富语义。”
“如果z和zi在潜在空间中接近,他们更有可能共享相似的答案和图像问题输入。”

于是作者计算了test(测试案例,也就是few-shot中的query)同其他vq对的融合特征的余弦距离,选取TopN最接近的。

当然,作者提到,这些z特征是可以被提前计算好的。
阶段二:启发式增强提示
向上面图二中展示的,下一个流程就是生成提示增强gpt-3预测。
也就是这一部分:
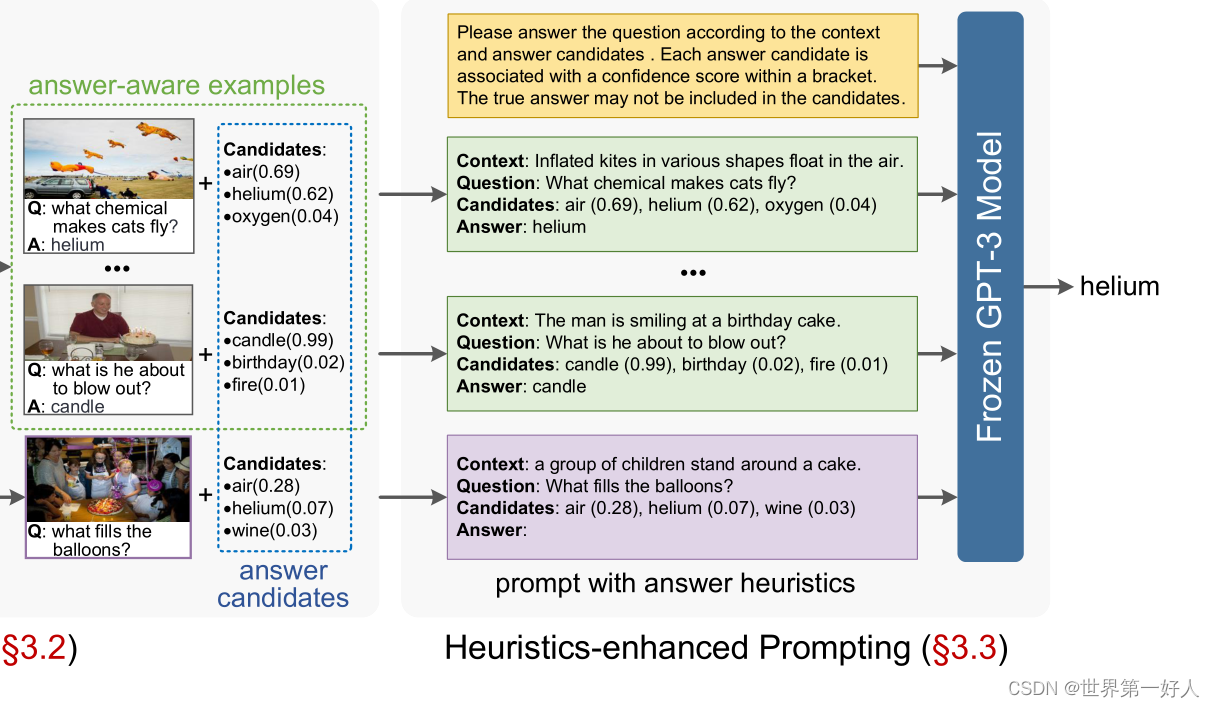
虽然可以看到给gpt-3提供了候选答案,但是gpt3同样可以选择生成新答案。

最后不管是e集合还是test,输入gpt-3的格式是这样的:

其中confidence会帮助gpt-3关注更有利的候选答案, 作者会进行多次操作输入gpt-3,投票选出结果:
