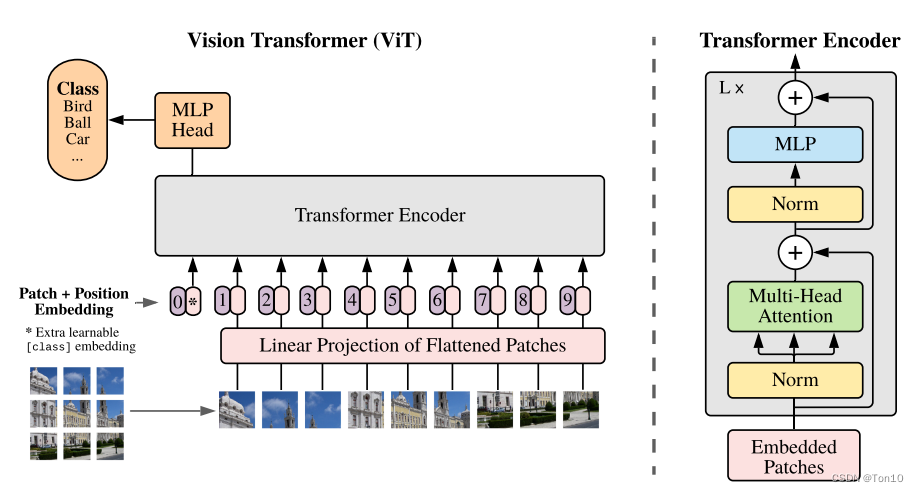
这篇文章的核心是提出了Vision-Transformer结构,将2017年Attention is All you Need在NLP中引入的Transformer结构应用于计算机视觉任务中。Transformer是一种基于自注意力结构的网络,和CNN捕捉卷积窗口内的局部信息不同,它利用注意力来捕获全局上下文信息之间的相关性。文章引入图像块(patch)的概念,patch由 P × P P\times P P×P个像素组成,通过将patch进行flatten,然后通过投影层转换成固定长度的特征向量,最后和NLP中表示1个token(word)的词向量一样输入到Transformer的Encoder结构中。
Note:
- 关于Transformer的详细结构介绍,可参考我的另一篇NLP之Transformer。
- 注意力机制是衡量多个representation之间相关性的常量,本质是一种门机制,也可以把它理解成一种modulation机制,其值通常在 [ 0 , 1 ] [0,1] [0,1]之间,通过元素级相乘的方式和value相结合,从而往原始value中引入了注意力,这样的目的就是为了让网络更加关注value中重要的部分,从而利用value中我们所需要的那部分,而不让我们不需要的那部分value来损害模型的表现力。关于注意力机制,可参考我的另一篇NLP之Seq2Seq。
参考文档:
①Transformer 模型详解
②真香!Vision Transformer快速实现Mnist识别
Vision Transformer
Abstract
- 在以往Transformer在计算机视觉上的应用中,它主要起2种作用:①和CNN一起结合使用;②替换整个CNN框架结构的一部分。
- 本文提出的ViT结构可以切断和CNN的这种依赖关系,可以纯使用Transformer的Encoder结构,通过引入图像分块概念来解决计算机视觉任务,比如图像分类等。
- Vit在大型数据集上训练,在中型或小型数据集种进行微调,在当时可以实现在图像识别中SOTA的水平!
1 Introduction
Transformer in NLP \colorbox{violet}{Transformer in NLP} Transformer in NLP
Transformer是在2017被提出,和传统神经网络基于CNN不同,Transformer主要基于自注意力(虽然attention和CNN没有直接联系,但是整个Transformer结构中还是有CNN的成分的,只是作者刻意规避了CNN),当时是应用于NLP中去取代RNN这种串行递归结构处理语言的低效性,因为Transformer可以并行处理数据以及利用自注意力机制让Decoder部分更加关注在Encoder中相关的部分。主流的方法是在大型语言数据集上训练,然后在小型数据集上微调。
Transformer in Previous Vision \colorbox{lightseagreen}{Transformer in Previous Vision} Transformer in Previous Vision
Transformer结构在NLP中的成功应用,给在计算机视觉任务上的迁移提供了思路。2018年开始,一些将Transformer应用于计算机视觉的论文就出来了,比如:①Non-local Neural Networks、End-to-end object detection with transformers往CNN中引入自注意力机制进行结合;②Stand-Alone Self-Attention in Vision Models、Stand-alone axial-attention for panoptic segmentation将整个Transformer来取代CNN模型中的一部分结构。但是这些方法仍然无法脱离CNN,因此作者提出了一种纯使用Transformer结构的模型,即Vision-Transformer(ViT)结构。
Transformer in ViT \colorbox{dodgerblue}{Transformer in ViT} Transformer in ViT
ViT将标准的Transformer直接迁移到计算机视觉任务中,但是有一点略微的修改:
- 在NLP中,Transformer的直接输入是word-embedding和position-embedding,它是将每个
token(word)通过嵌入层(比如torch.nn.Embedding())转换成词向量,你可以使用word2vec或者一些开源的神经网络库中的一些嵌入层(如Pytorch、Keras、TensorFlow等)将词用稠密向量表示。而在图像中,作者将图像块看成是1个词word,而最终输入进Transformer的patch-embdding就类似于词向量word-embedding。 - 那么如何将patch转换成patch-embedding这种向量形式呢?作者引入图像分块(
patch)概念,先将整幅图像分块,然后将每个图像块(如 4 × 4 4\times 4 4×4)进行flatten,再利用投影变换映射成图像块嵌入形式,即patch-embedding,这样一来每个图像patch就对应了1个固定长度的向量,然后就可以直接送进Transformer了!
2 Vision Transformer Architecture
在正式介绍之前,先对一些符号做介绍:
- H 、 W 、 C H、W、C H、W、C分别表示图片的高、宽、通道数。
- P P P表示图像patch的size。
- N = H W P 2 N = \frac{HW}{P^2} N=P2HW表示一张图片中patch的个数。
- D D D表示patch嵌入之后的向量的固定长度。
- x ∈ R H × W × C x\in \mathbb{R}^{H\times W\times C} x∈RH×W×C表示输入图像。
- x p ∈ R N × ( P 2 ⋅ C ) x_p\in \mathbb{R}^{N\times (P^2\cdot C)} xp∈RN×(P2⋅C)表示将 N N N个patch进行flatten展平之后的矩阵,将它嵌入之后就是固定长度为 D D D的patch向量了,此外 x p i x_p^i xpi就表示第 i i i个patch展平之后的1维向量。关于 x p x_p xp,其大致结构如右图所示:
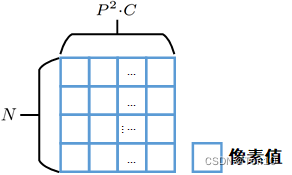
ViT框架结构 \colorbox{tomato}{ViT框架结构} ViT框架结构
下图就是整个ViT的网络结构,接下来我们对它进行详细介绍:
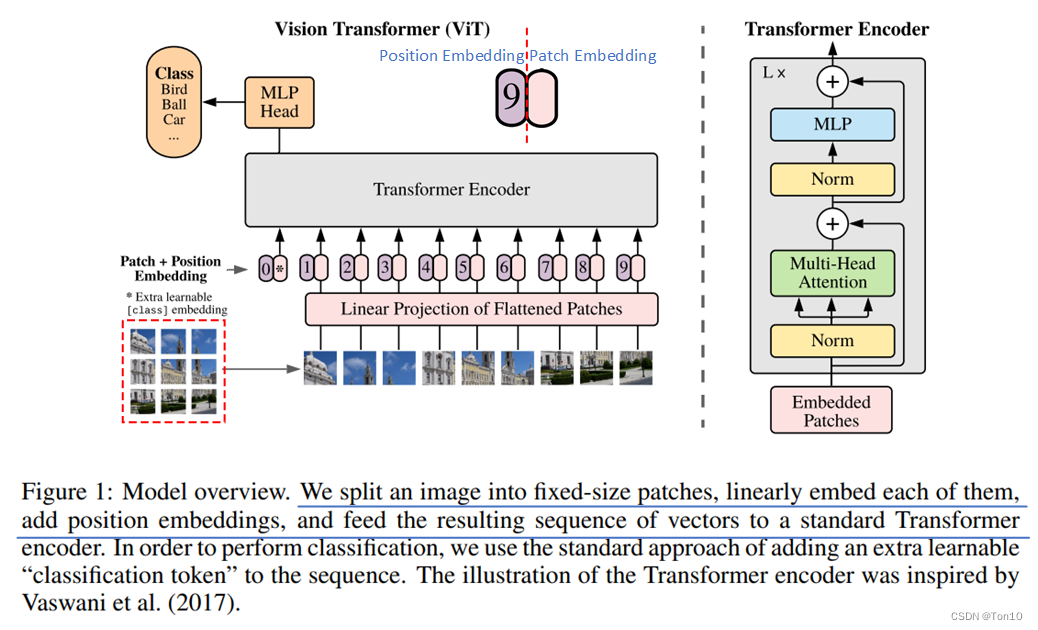
整个模型分为5步:
- 图像分块:将一张通道为 C C C的 H × W H\times W H×W的图片 x ∈ R H × W × C x\in \mathbb{R}^{H\times W\times C} x∈RH×W×C按照 P × P P\times P P×P的patch大小进行分块,如上图所示,产生9张patch。
- 图像展平:然后将每张patch进行flatten展平产生一个 1 D 1D 1D的向量,然后将 N N N个patch堆叠起来,输出 x p ∈ R N × ( P 2 ⋅ C ) x_p\in \mathbb{R}^{N\times (P^2\cdot C)} xp∈RN×(P2⋅C)。
- Patch嵌入(Embedding):每一个 x p i x_p^i xpi和每一个位置 p o s i ∈ R N pos^i \in\mathbb{R}^{N} posi∈RN分别通过线性投影变换 E 、 E p o s \bm{E}、\bm{E_{pos}} E、Epos(其实就是全连接层)产生固定长度的patch向量和位置向量,即
patch-embedding和position-embedding,两者的size都是 R 1 × D \mathbb{R}^{1\times D} R1×D;所以 N N N个patch和 N N N个位置的嵌入结果就是 R N × D \mathbb{R}^{N\times D} RN×D。 - T-Encoder:将patch-embedding和position-embedding一起输入进标准的Transformer内的
Encoder中。 - 分类:这篇文章作者是做在图像识别上的,所以最好是多分类。
Note:
- 第二步图像展平过程是将通道信息 c ∈ C c\in C c∈C一起flatten的。
- 论文中是最后的嵌入结果是 R ( N + 1 ) × D \mathbb{R}^{(N+1)\times D} R(N+1)×D,是因为它还加入了一个分类token,这是为了具体分类任务需要,并不是ViT通用框架内的东西。
- 增加位置信息是因为原本RNN中天然有表示序列顺序的信息,而Transformer的并行化结构无法表示每个patch的位置信息,由于这也是个重要的信息,所以和NLP中加入每个token的位置信息一样,ViT也会加入每个Patch的位置信息。
- Patch嵌入、位置嵌入和词嵌入一样,可以通过word2vec这种无监督方法预先训练好,也可以使用一些嵌入层和Transformer一起做监督训练。
Patch-Embedding、Position-Embedding、Word-Embedding都属于固定长度的向量,是作为Transformer的直接输入信号;且他们都可以通过训练嵌入层(Embedding layer)输出得到。- 1个图像patch对应了1个 1 × D 1\times D 1×D的 D D D维的patch-embedding和1个 D D D维的position-embedding。
- ViT只使用Transformer中的Encoder部分。
标准的Transformer的Encoder结构如下图所示:
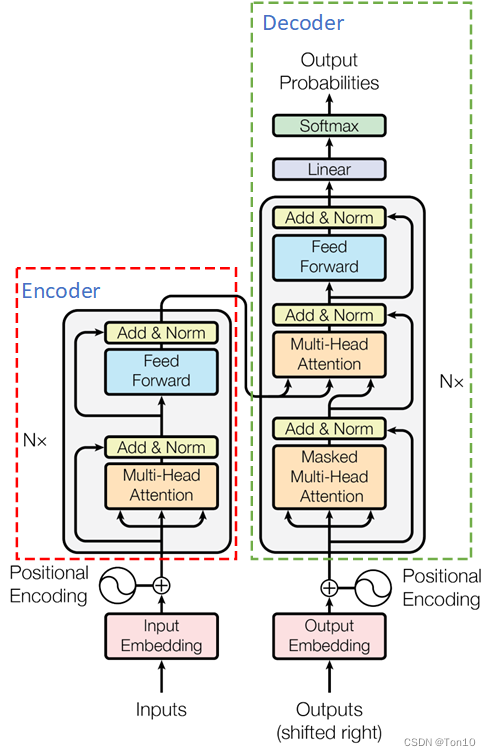
但是ViT中使用了如下结构:
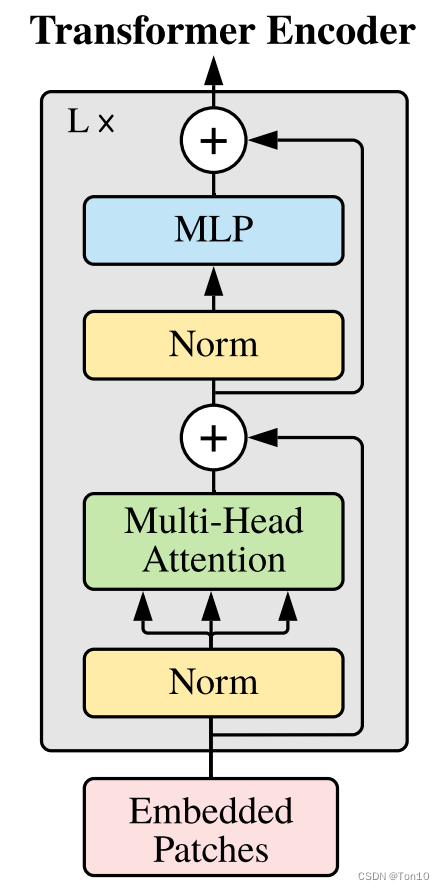
Encoder结构包含LN(LayerNorm,为不是BN),它放置于注意力块的前面;Residual-connection,它被放置于注意力块的后面;MLP,即feed-forward network,使用2个全连接层内接GELU非线性函数;MSA,即多头的自注意力模块,多头multi-head就是通过多个角度去产生注意力。此外Encoder往往会级联 L L L个上图结构。
整个ViT的数学表达式如下:
z 0 = [ x c l a s s ; x p 1 E ⏞ 1 × D ; x p 2 E ; ⋯ ; x p N ] + E p o s , E ∈ R ( P 2 C ) × D , E p o s ∈ R ( N + 1 ) × D . (1) z_0 = [x_{class};\overbrace{x_p^1\bm{E}}^{1\times D};x_p^2\bm{E};\cdots;x_p^N] + \bm{E}_{pos},\\ \bm{E}\in\mathbb{R}^{(P^2C)\times D},\bm{E}_{pos}\in\mathbb{R}^{(N+1)\times D}.\tag{1} z0=[xclass;xp1E
1×D;xp2E;⋯;xpN]+Epos,E∈R(P2C)×D,Epos∈R(N+1)×D.(1)
z l ′ = M S A ( L N ( z l − 1 ) ) + z l − 1 , l = 1 , ⋯ , L . (2) z'_l = {\color{tomato}MSA}(LN(z_{l-1})) + z_{l-1},\\ l = 1,\cdots, L.\tag{2} zl′=MSA(LN(zl−1))+zl−1,l=1,⋯,L.(2)
z l = M L P ( L N ( z l ′ ) ) + z l ′ , l = 1 , ⋯ , L . (3) z_l = {\color{violet}MLP}(LN(z'_l)) + z'_l,\\ l=1,\cdots, L.\tag{3} zl=MLP(LN(zl′))+zl′,l=1,⋯,L.(3)
y = L N ( z L ) . (4) y = LN(z_L).\tag{4} y=LN(zL).(4)
Transformer的核心就是MSA这个多头自注意力模块(Multi-head Self-Attention),接下去我们对它进一步展开介绍:
设 z ∈ R N × D z\in\mathbb{R}^{N\times D} z∈RN×D为经过LN之后的输出,则
[ Q , K , V ] = z U Q K V , U Q K V ∈ R D × 3 D h . (5) [Q,K,V] = z U_{QKV},\\ U_{QKV}\in\mathbb{R}^{D\times 3D_h}.\tag{5} [Q,K,V]=zUQKV,UQKV∈RD×3Dh.(5)其中 Q 、 K 、 V Q、K、V Q、K、V各自通过线性层得到, Q Q Q表示Query, K K K表示Key, V V V表示Value;
Q 、 K Q、K Q、K用于计算注意力权重, V V V是输入 z z z的另一种表达,则注意力权重矩阵 A A A可表示为:
A = s o f t m a x ( Q K T / D h ) , A ∈ R N × N . (6) A = softmax(QK^T/ \sqrt{D_h}),\\ A\in \mathbb{R}^{N\times N}.\tag{6} A=softmax(QKT/Dh),A∈RN×N.(6)因此,单头(single-head)的自注意力就可以总体表示为:
S A ( z ) = A v ∈ R N × D h . (7) SA(z) = Av\in \mathbb{R}^{N\times D_h}.\tag{7} SA(z)=Av∈RN×Dh.(7)
如果说单头是1个人对于图片的注意力,那么多头multi-head就是多个人对于图片的多份注意力,是不同的理解,即multi-head就是同时并行运行 k k k个single-head自注意力,最后将结果concat起来:
M S A ( z ) = [ S A 1 ( z ) ; S A 2 ( Z ) ; ⋯ ; S A k ( z ) ] U m s a , U m s a ∈ R k D h × D . (8) MSA(z) = [SA_1(z);SA_2(Z);\cdots;SA_k(z)]U_{msa},\\ U_{msa} \in \mathbb{R}^{kD_h \times D}.\tag{8} MSA(z)=[SA1(z);SA2(Z);⋯;SAk(z)]Umsa,Umsa∈RkDh×D.(8)为了使得输入的 z z z和输出的注意力保持相同的size,一般会取 D h = D / k D_h = D/k Dh=D/k。
Note:
- z 、 Q 、 K 、 V 、 M S A ( z ) z、Q、K、V、MSA(z) z、Q、K、V、MSA(z)的每一行都代表着1个patch。
3 Conclusion
- 文章推出了一种基于
patch-wise注意力机制的Transformer模型——Vision Transformer(ViT)。 - ViT不需要和CNN相结合,它只用单纯的Transformer模型来实现图像识别。具体而言,ViT使用图像分块patch的思想,将每个patch看成是NLP中的1个token,通过flatten以及嵌入层来产生patch-embedding和position-embedding,它类似于词向量的形式;然后就可以直接输送进Transformer的Encoder模块,从而完成Vision的任务。