数据标注方式:
(1)人很少、人很大的时候用bounding box,把人从头到脚都框进长方形方框内,这个方框只用记录三个点的坐标,左下、左上、右下;测试集预测的时候,除了点的坐标还要输出这个框内可能是一个人的置信度
(2)人很多、很密集、人很小的时候,因为人的身体多有重叠occlusion,在人头点一个红点,表示这是一个人。

评估指标Metrics
MAE是预测人数和真实人数的绝对误差,MSE是预测人数和真实人数的均方误差。
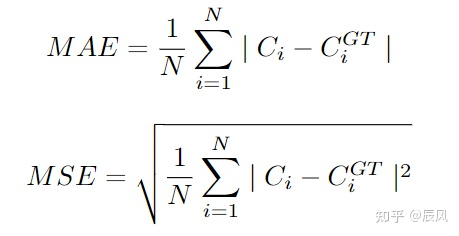
人群计数算法主要分为三大类:detection-based,regression-based,density estimation
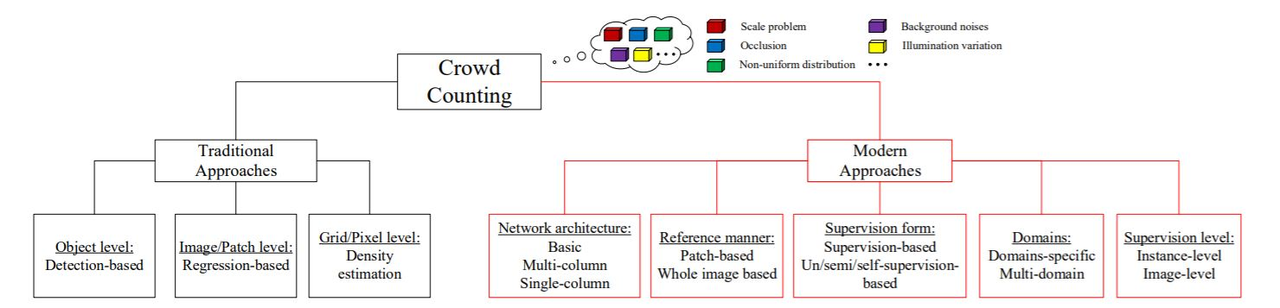
一种模型分类的方法
最古老的方法:Jacobs' method:把整个区域按规定切成很多个单元unit dividing the area occupied by a crowd into sections, 估计每个单元有多少人determining an average number of people in each section, and然后单元数乘以每个单元平均数,得到总人数 multiplying by the number of sections occupied
(1)object detection + object tracking最早
Pedestrian detector
we use a shaped window-like detector to identify people based on different classifiers in an image or video and count the number. W
概览

基于检测的方法。[1]。基于检测的方法主要分为两大类,一种是基于整体的检测,另一种是基于部分身体的检测。(1)基于整体的检测方法,例如 [2,3,4,5],典型的传统方法,用一个滑动窗口来检测场景的人,训练一个分类器,利用从行人全身提取的小波,HOG,边缘等特征去检测行人。学习算法主要有SVM, boosting 和 增量随机森林等方法。基于整体检测的方法主要适用于稀疏的人群计数,随着人群密度的提升,人与人之间的遮挡变得越来越严重。(2)所以基于部分身体检测的方法,被用来处理人群计数问题。对身体的特定部分增加分类器,[6, 7]主要通过检测身体的部分结构,例如头,肩膀等去统计人群的数量。使用形状学习的方法,使用椭圆形的三维图形建模人类,并使用随机过程来估计前文前景mask的数量和形状参数。这种方法比之基于整体的检测,在效果上有略微的提升。
[2] Histograms of oriented gradients for humandetection, [3] Pedestrian detection incrowded scenes [4] Monocular pedestrian detection: Survey and experiments. [5] Pedestrian detection via classification on riemannian manifolds. [6] Object detection with discriminatively trained part-based models. [7] Detection and tracking of multiple, partially occluded humans by bayesian combination of edgelet based part detectors.
(S1)先做目标检测, 使用一个滑动窗口检测器来检测场景中人群,并统计相应的人数,用一个滑动窗口状去照着图片从左上角滑动到右下角(我觉得不对,这个框在不同位置的大小是不同的),把所有的人头都识别出来,给打上方框bouding box,use a moving window-like detector to identify the target objects in an image,然后(S2)通过数方框的个数得出人的数量count how many there are
传统机器学习的方法:HOG-based detector(你这里列出的不全面,不全的话,意义就不大了)
深度学习的方法:YOLOs or RCNNs
这种的方法的要求:
因为要区分这个区域有人头还是没有人头,需要做二分类,所以你提供的分类器要具有提取低层次特征的能力(我觉得不对,分类的基础是提取特征的能力,至于提取什么,不一定是非得着重提取low-level feature)require well-trained classifiers that can extract low-level feature
优点:(1)人群比较稀疏的场景下效果比较好 may perform dramatic detection accuracy in sparse scenes. (1)能够定位person的具体位置;(2)模型泛化性较强,适应多种场景
缺点:
(1)人比较密集dense crowd的场景效果不太好,会存在大量漏检 present unsatisfactory results when encountered the situation of occlusion and background clutter in extremely dense crowds.,超过2000人的拥挤人群无法计数,因为A.这种场景往往遮挡(occlusion,overlap)严重 B.这种场景target的特征features不能够被清晰的识别出来。 The target features are not clearly distinguishable and/or visible while working with a dense crowd. C.图片上的内容比较混乱随机the randomness or clutter in the background is high
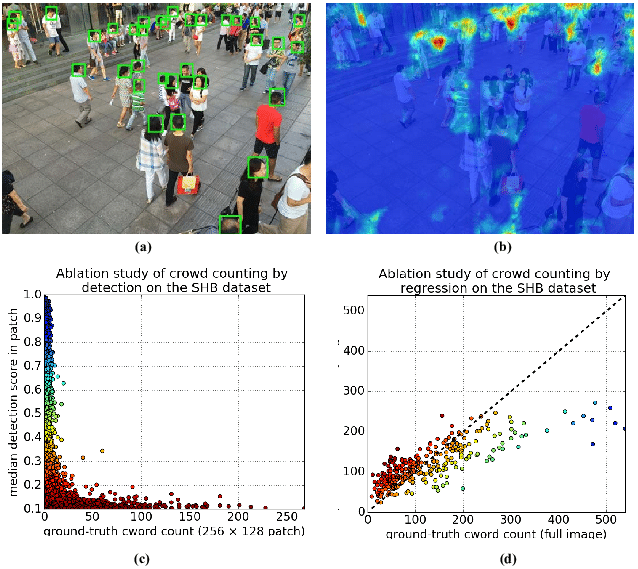
比如下面这个图就对比了detection-based 和regression-based method,我们发现如果图片中的人数一旦超过20人,detection-based method的detection score就会低于0.3,但是对于regression method,随着图片中人数的增加,数出的人数也是随着增加的
(2)对训练数据要求较高,需标注目标的具体位置。
样例:(1)从头到脚打个长方形框的(2)仅仅在人的头部打个方框(3)识别出来了,不搭方框,在人头部上方的位置写个一个数字表示这个第几个经过的人
监控视频的传统基于运动信息的人群分割从而计数
博客网址:https://mp.weixin.qq.com/s?__biz=MzI1
视频相对于离散的图像而言包含运动的信息,因此大多数基于视频的人群计数算法一般分为三个步骤: 1)前景分割;2)特征提取;3)人数回归。接下来将对这三个步骤分别做详细的介绍。 1)、前景分割前景(人群)分割的目的是将人群从图像中分割出来便于后面的特征提取,分割性能的好坏直接关系的最终的计数精度,因此这是限制传统算法性能的一个重要因素。常用的分割算法有:光流法(Optical Flow)、混合动态纹理(Mixture of Dynamic Textures)、小波分析(Wavelets) 等。这种基于运动信息的前景分割算法的缺点非常明显:如果视频中的人站着不动,那么就会把静止不动的人分为背景,从而影响人群计数的性能。(前景提取也是特征工程中的一种) 2)、特征提取在完成前景分割之后,紧接着就是从分割得到的前景(人群)提取各种不同的低层特征(Low-level Features),常用的特征有:人群面积和周长(Area and Perimeter of Crowd Mask)、边的数量(Edge Count)、边的方向(Edge Orientation)、纹理特征(Texture Features)、闵可夫斯基维度(Minkowski Dimension)等。 3)、人数回归该步骤的目的是将上一步提取到的特征回归到图像中的人数,回归可以是简单的线性回归,也可以用复杂的非线性回归。常用的回归方法有:线性回归(Linear Regression)、分段线性回归(Piece-wise Linear Regression)、脊回归(Ridge Regression)、高斯过程回归(Gaussian Process Regression)等。 接下来让我们通过发表于CVPR08的一篇代表性论文Privacy Preserving Crowd Monitoring: Counting People without People Models or Tracking. 来详细了解整个算法流程。图3. 展示了一个经典的视频人群计数系统:首先采用混合动态纹理的方法将运动的人群分割出来。
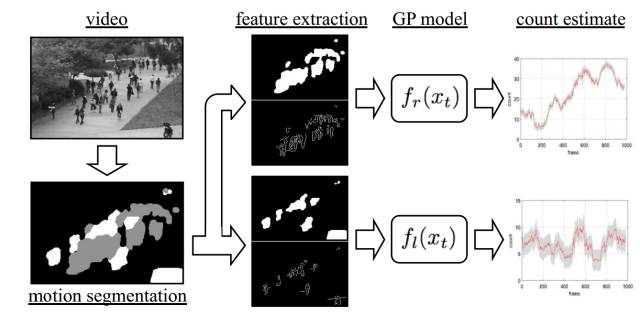
由于视角原因,靠近摄像头的人要比远离摄像头的人在图像中占更多的像素,作者给人群引入了视角归一化 (Perspective Normalization),

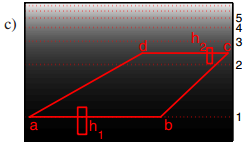
标定一个地平面(Ground Plane),测量在水平方向前面的那条线 $$ab$$上的人的高度 $$h_{1}$$。再去测量水平方靠后的那条线 $$cd $$上的高度 $$h_{2}$$。分别给 $$ab$$和 $$cd$$的像素乘以权重1和 $$\frac{h_{1}|\overline{ab}|}{h_{2}|\overline{cd}|}$$.,中间的像素的权重通过这两条线之间的线性插值得到。接下来在归一化后的人群块(Crowd Blob)上提取多种特征(面积,周长,边缘方向,纹理)。最后采用高斯过程回归将提取的特征回归到图像中人群数量。 平均绝对误差(MAE)和均方误差(MSE)是常用的衡量算法性能的标准,前者表征算法的准确性,后者表征算法的稳定性,二者的定义如下式
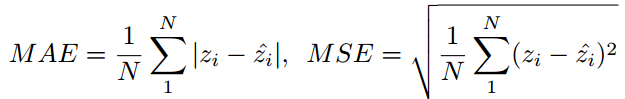
其中 $$N$$是测试的图片数量(视频帧数) $$z_{i}$$是第 $$i$$张图片实际人数, $$\hat{z_{i}}$$是算法估计的人数
优势:传统基于运动信息人群分割的算法也有自己的一个优点,就是能够统计视频中不同方向人流的人数,这是以单张图片作为输入的卷积神经网络很难实现的。
百度Paddle下FairMOT模型(还没跑)
代码:
-
代码怎么跑说的很详细(jupyer notebook):https://aistudio.baidu.com/aistudio/projectdetail/2421822
-
写的比下面这个都更加详细:https://aistudio.baidu.com/aistudio/projectdetail/4171185
-
PaddlePaddle/PaddleDetectionhttps://github.com/PaddlePaddle/paddledetection#%E4%BA%
-
PP-Human实时行人分析全流程实战:写的特别详细,怎么安装、怎么运行写的都很好:https://aistudio.baidu.com/aistudio/projectdetail/3842982 ——;
-
实时行人分析 PP-Human——https://toscode.gitee.com/zyt111/PaddleDetection/tree/release/2.4/deploy/pphuman
-
使用百度AI实现视频的人流量统计(静态+动态)代码及效果演示 https://blog.csdn.net/weixin_419
-
基于PaddleDetection实现人流量统计人体检测https://blog.csdn.net/m0_63642362/article/details/121434604
(文章写的很详细,各部分都很完善,非常好!)
人流量统计任务需要在
(1)检测到目标的类别和位置信息的同时
(2)识别出帧与帧间的关联信息,确保视频中的同一个人不会被多次识别并计数。本案例选取PaddleDetection目标跟踪算法中的FairMOT模型来解决人流量统计问题。
(3)FairMOT以Anchor Free的CenterNet检测器为基础,
(4)深浅层特征融合使得检测和ReID任务各自获得所需要的特征,实现了两个任务之间的公平性,并获得了更高水平的实时多目标跟踪精度。
(5)针对拍摄角度不同(平角或俯角)以及人员疏密程度,在本案例设计了不同的训练方法:
-
针对人员相对稀疏的场景: 基于Caltech Pedestrian、CityPersons、CHUK-SYSU、PRW、ETHZ、MOT16和MOT17数据集进行训练,对场景中的行人进行全身检测和跟踪。 如 图2 所示,模型会对场景中检测到的行人进行标识,并在左上角显示出该帧场景下的行人数量,实现人流量统计。

-
针对人员相对密集的场景: 人与人之间的遮挡问题会非常严重,这时如果选择对行人整体检测,会导致漏检率升高。因此,本场景中使用人头跟踪方法。基于HT-21数据集进行训练,对场景中的行人进行人头检测和跟踪,对人流量的统计基于检测到的人头进行计数,如 图3 所示。

模型选择
PaddleDetection对于多目标追踪算法主要提供了三种模型,DeepSORT、JDE和FairMOT。
-
DeepSORT (Deep Cosine Metric Learning SORT) (1)扩展了原有的 SORT (Simple Online and Realtime Tracking) 算法,(2)增加了一个CNN模型用于在检测器限定的人体部分图像中提取特征,在深度外观描述的基础上整合外观信息,将检出的目标分配和更新到已有的对应轨迹上即进行一个ReID重识别任务。DeepSORT所需的检测框可以由任意一个检测器来生成,然后读入保存的检测结果和视频图片即可进行跟踪预测。ReID模型此处选择 PaddleClas 提供的
PCB+Pyramid ResNet101模型。 -
JDE (Joint Detection and Embedding) 是(1)在一个单一的共享神经网络中同时学习目标检测任务(Anchor Base的YOLOv3检测器)和embedding任务(ReID分支学习embedding),(2)并同时输出检测结果和对应的外观embedding匹配的算法。一个模型有两个输出,所以训练过程被构建为一个多任务联合学习问题。这样做的好处:兼顾精度和速度。
-
FairMOT 【最后用这个】(1)以Anchor Free的CenterNet检测器为基础,(2)克服了Anchor-Based的检测框架中anchor和特征不对齐问题,(3)深浅层特征融合使得检测和ReID任务各自获得所需要的特征,(4)并且使用低维度ReID特征,(5)提出了一种由两个同质分支组成的简单baseline来预测像素级目标得分和ReID特征,实现了两个任务之间的公平性,并获得了更高水平的实时多目标跟踪精度。综合精度和速度,这里我们选择了FairMOT算法进行人流量统计/人体检测。
Faster RCNN
Detection领域的SOTA model
可以做,但是我没发现有代码做
SSD
YOLOv5+deepsort+Fast-ReID
Detection领域的SOTA model
https://blog.csdn.net/zengwubbb/article/details/113422048
下面两篇文章的内容是一样的,代码很丰富可以直接用
yolov5行人检测+deepsort跟踪tracking+在Fast-ReID遮挡的情况下能较好的防止reid模型误识别
——任务:统计摄像头内出现过的总人数,以及对穿越自定义黄线行人计数
——模型:yolov5实现行人检测+deepsort进行跟踪,
——代码地址:(据说可以直接跑)
只做追踪和识别:https://github.com/zengwb-lx/Yolov5-Deepsort-Fastreid
做追踪识别以后再做counting—— https://github.com/zengwb-lx/yolov5-deepsort-pedestrian-counting
上面两个有报错如何解决:https://blog.csdn.net/qq_35054151/article/details/118815485
——样例:

OpenCV传统机器学习做人流量统计,不涉及深度学习
有代码:https://blog.csdn.net/qq_35054151/article/details/118815485
Haar Cascade people Detection Algorithm
从正例和负例中学习一个瀑布函数 It is an ML-based approach where a cascade function is trained from a lot of positive and negative images.
Computer Vision — Detecting objects using Haar Cascade Classifier https://towardsdatascience.com/computer-vision-detecting-objects-using-haar-cascade-classifier-4585472829a9
OpenCV background subtraction
首先的第一步是把人或汽车从画面中提取出来 In all these cases, first, you need to extract the person or vehicles alone. Technically, you need to extract the moving foreground from static background. 她的速度更快,更适合实时的人的识别It is a relatively faster method for real-time people detection.
Opencv 下面三个算法做了实现OpenCV has implemented three such algorithms :
-
BackgroundSubtractorMOG
-
BackgroundSubtractorMOG2
-
BackgroundSubtractorGMG
How to Use Background Subtraction Methods:https://docs.opencv.org/3.4/d1/dc5/tutorial_background_subtraction.html
Simple HOG detection
04年提出,HOG是一个特征描绘器,它能够数出图片中某一定位的部分的梯度导向出现的次数HOG(Histogram of Gradients) is a type of “feature descriptor”. The technique counts occurrences of gradient orientation in localized portions of an image and thereby in a video.
Histogram of Oriented Gradients explained using OpenCV:https://learnopencv.com/histogram-of-oriented-gradients/
HOG with linear SVM algorithm
通过SVM来进一步改善HOG识别器的准确率The accuracy of the Simple HOG detection method can be further improved by using an SVM classifier to classify positive and negative features from sample images.

HOG+傅里叶+兴趣点
CVPR2013的论文Multi-Source Multi-Scale Counting in Extremely Dense Crowd Images
使用多源信息(Multiple Sources of Information)估计单张具有非常密集人群的图像的人数的方法。作者首先把一张图片分成很多较小的区域

然后对每个区域从三种不同而互补的源进行人数估计,最终这张图像的人数是每个区域的人数之和。这三种源分别是:1)基于HOG的人头检测(HOG based Head Detections);2)傅里叶分析(Fourier Analysis);3)基于兴趣点的计数(Interest Points based Counting)。最终每个区域的人数由以上三个源综合得到。
由于实际图像相邻区域的人数差别不是很大,作者采用马尔可夫随机场(Markov Random Field)使得估计得到的相邻区域的人数比较光滑。图6.显示了MRF前后每个区域人数的区别。
SIFT
细节不知道
Centroid Tracking Algorithm目标追踪——针对video而不是图片
(他这个提供了代码,我没详细看,不知道能不能运行——他是卖付费课的,可能第一次注册可以免费地看内容,现在没直接看代码,先不注册,不浪费一次免费学的机会)
https://pyimagesearch.com/2018/07/23/simple-object-tracking-with-opencv/
Object tracking对于人流量统计person counter的重要性:
Object tracking做完了,人也就数出来了:Object tracking allows us to apply a unique ID to each tracked object, making it possible for us to count unique objects in a video.
好的object tracking算法具备的几个特点An ideal object tracking algorithm will:
-
只需要做一次目标检测(???为啥只需要一次?新的人进入摄像头录像范围内不需要重新识别吗?):Only require the object detection phase once (i.e., when the object is initially detected)
-
必须快:Will be extremely fast — much faster than running the actual object detector itself
-
如果tracked object在视线范围内消失,要会处理:Be able to handle when the tracked object “disappears” or moves outside the boundaries of the video frame
-
足够鲁棒Be robust to occlusion
-
Be able to pick up objects it has “lost” in between frames
操作流程 of The centroid tracking algorithm
centroid tracking as it relies on the Euclidean distance between (1) 现存的质心existing object centroids质心 (i.e., objects the centroid tracker has already seen before) and (2)新的质心 new object centroids between subsequent frames in a video.
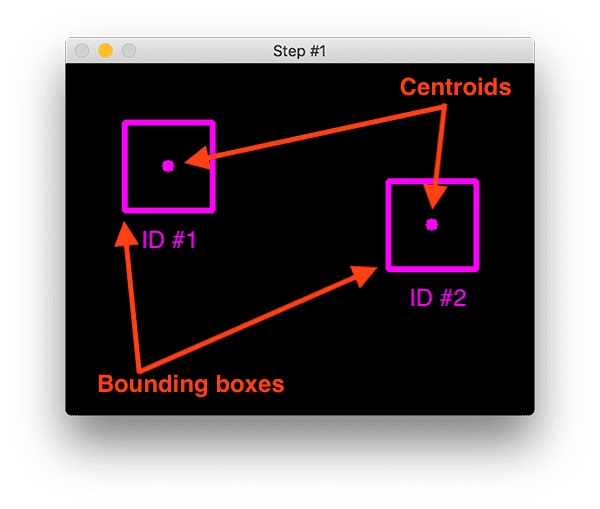
Step #1:画出方框 Accept bounding box coordinates and 计算质心坐标compute centroids
(1)给object打上方框,方框四个角的坐标自然知道了(做目标检测的方法有:color thresholding + contour extraction, Haar cascades, HOG + Linear SVM, SSDs, Faster R-CNNs)
(2)根据方框四角的坐标,计算二者各自质心点的坐标(也就是两个方框中心的坐标)
Step #2:计算老的点和新的点的距离,确定哪个一对点是移动后的样子 Compute Euclidean distance between new bounding boxes and existing objects
计算新出现的bounding box的质心和旧的bounding box的质心之间的距离。
下图中,紫色是是Step1中已经出现的目标的质心位置,有两个。黄色是第二张图中新出现的目标的质心点的bounding box的质心的位置。
上面两个黄色点是之前的紫色点移动后的位置。下面那个黄色点是新出现的目标object。
以已经Step1里面出现的两个紫色点为中心,计算每个点到新出现的三个黄色点的距离,分别用绿色和红色表示
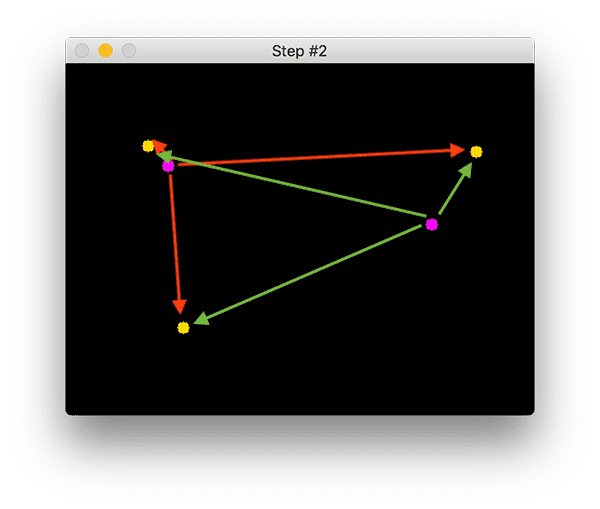
为了判断新的质心点new object centroids(黄色)和old object centroids(紫色)之间是否有关系associate,我们以existing object centroids为中心,计算了它们和new object centroid之间的距离。这个距离是欧几里得距离 Euclidean distances。左上角那个紫色的点和另外三个黄色点的距离用红色表示,右边那个紫色点和其他黄色点的距离用绿色表示。

Step #3: 更新各个点的ID的坐标,扔掉过去的坐标,把新的坐标补充进去。Update (x, y)-coordinates of existing objects
如果判断老的一个点和新的一个点是有关系的associate的呢?(你怎么知道新出现的点对应哪一个之前出现的点呢?)寻找每一个老的点(紫色的点)离它欧氏距离最近的黄色点,最近的黄色点,说明他们与紫色点associate。说明黄色的点是紫色的点的下一步运动轨迹。
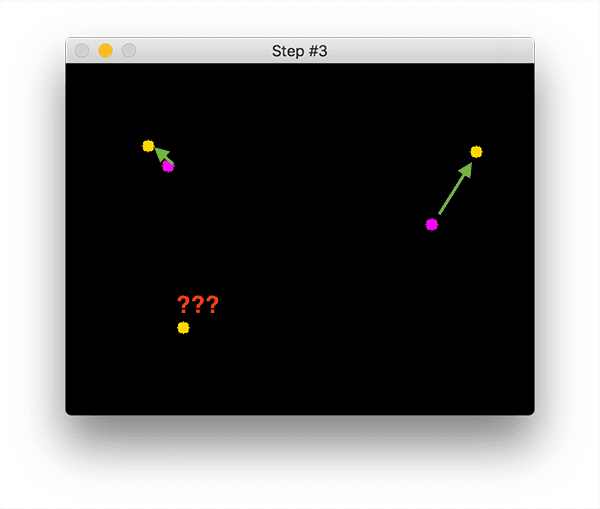
using the minimum Euclidean distances to associate existing object IDs and then registering a new object.
对于bottom left这个点,在第一幅图中没有出现过,在第二幅图中出现了,(1)分配一个新的object ID,Assigning it a new object ID(2)把质心的位置存一下Storing the centroid of the bounding box coordinates for that object

Step #5: 之前有现在没有的点,注销ID_Deregister old objects
第一幅图里面有的东西,但是第二幅图里面没有的,要移除掉
Any reasonable object tracking algorithm needs to be able to handle when an object has been lost, disappeared, or left the field of view.
Limitations and drawbacks
(1) 它要求目标检测的步骤要在输入视频的每一个方框上运行,计算成本很高it requires that object detection step to be run on every frame of the input video.
这里用的这个质心目标检测器速度很慢,和下面这些快的目标检测器没法比, color thresholding and Haar cascades。但是你一旦用了下面这些耗费算力很多的检测器a significantly more computationally expensive object detector比如下面这些算法 such as HOG + Linear SVM or deep learning-based detectors,尤其是用在一些硬件设备笔记差的设备上on a resource-constrained device比如树莓派设备 Raspberry Pi,你整个打方框的步骤都会变慢your frame processing pipeline will slow down tremendously 无法实时的进行追踪may prevent your computer vision pipeline from running in real-time.
(2)It does not handle overlapping objects,你质心追踪算法的假设有可能是错的 the underlying assumptions of the centroid tracking algorithm itself —这个假设是"两个有先后顺序的方框,它们的质心一定lie的很近" centroids must lie close together between subsequent frames.
如果两个object,一个离摄像头近、一个离摄像头远,二者正好在图片上看着近,但是实际很远,而且是两个完全不同的东西,what happens when an object overlaps重叠 with another one?
object ID switching could occur:If two or more objects overlap each other to the point where their centroids intersect and instead have the minimum distance to the other respective object, the algorithm may (unknowingly) swap the object ID.
其他的追踪器(detection+tracker)推荐:
https://pyimagesearch.com/2018/07/30/opencv-object-tracking/
-
BOOSTING tracker
-
它的算法是基于AdaBoost,和Haar cascade算法的底层原理一样,但是这是10年以前的老算法,速度更慢slow,是十年前的老算法
-
-
MIL tracker
-
比上这个准确率更高,但是汇报错误上做的不好。Better accuracy than BOOSTING tracker but does a poor job of reporting failure.
-
-
KCF tracker
-
全名: Kernelized Correlation Filters.。比上面两个快,但是object之间的互相遮蔽和overlap他处理的不好。Faster than BOOSTING and MIL. Similar to MIL and KCF, does not handle full occlusion
-
-
CSRT tracker、
-
全名:Discriminative Correlation Filter with Channel and Spatial Reliability. 准确率比KCF高,但是慢一点Tends to be more accurate than KCF but slightly slower.
-
-
MedianFlow tracker
-
汇报失败这里做的好Does a nice job reporting failures;但是如果有一个快速移动的物品,模型就无法追踪了 however, if there is too large of a jump in motion, such as fast moving objects, or objects that change quickly in their appearance, the model will fail.
-
-
TLD tracker
-
不推荐
-
-
MOSSE tracker
-
速度特别快,但是准确率不如CSRT和KCFVery, very fast. Not as accurate as CSRT or KCF but a good choice if you need pure speed.
-
-
GOTURN tracker
-
这是OpenCV提供的模型里面唯一的一个深度学习为基础的模型
-
My personal suggestion is to:
-
Use CSRT when you need 高的追踪准确率higher object tracking accuracy and can tolerate slower FPS(每秒传输帧数(Frames Per Second) throughput
-
Use KCF when you need faster FPS throughput but can handle 不需要很高的追踪准确率slightly lower object tracking accuracy
-
Use MOSSE when you need pure speed需要速度很快
06-MobileNet-ssd
付费文章,看不了,但是一万多人都买了https://blog.csdn.net/xiao__run/article/details/93196347
YOLO Detector or RCNN
传统机器学习的方法是HOGtraditional HOG-based detector or
深度学习的方法是YOLO和RCNN deeplearning-based detector like YOLOs or RCNNs
(2)Regression-based离现在比较近
Number regression
2008-2014年用的多
出现的原因:detection based methods在下列情况下表现的不好,when there is a (1)dense crowd人群遮挡问题严重 and the (2)randomness or clutter in the background is high。而regression-based methods因为它能够extract low-level features,比如edge values,foreground pixels,设计这个出来就是为了解决克服前面两个问题的。
是什么:直接根据图片做回归预测出途中人数
(S1)把图片crop一个个小碎片patch
(S2)从这些patch中捕捉特征capture some features from original images 。[ 1 ]全局特征global features包括(纹理特征texture-, 梯度特征gradient, 边缘特征edge features)。;[ 2 ] 局部特征local feautes (SIFT, 局部二进制模式LBP, 直方图定向梯度HOG, 灰度共生矩阵GLCM). ; [ 3 ] 使用背景的减法,从前景片段中提取前景特征 [ 4 ] 手动设计并提取各种特征(Hand-crafted Features
——这几个特征我也不知道是local还是global的,但也是特征,放在这里foreground pixels-前景特征-银幕上看上去离观者最近的景物。比如轮廓表示contour representations, 形状表示shape descriptions,渐变特性
——特征构建对于regression-based method这个方法尤为重要,学者的主要工作工作是寻找更加effetive的特征
(S3)用机器学习的方法建立这些feature和 人数这个数字之间的映射关系 use machine-learning models to map the relation between features and numbers,从图片这个矩阵映射出人数这个标量Regression methods are able to directly map the input images to scalar values.;有的用线性回归linear regression、分段线性回归,岭回归和高斯过程回归和神经网络
————注意第二步和第三步,提取特征+构建映射这个构建映射的过程,可以用CNN来实现。我们称这种方法为 end-to-end regression method。用代码实现这个设想的是这个counting计数比赛的第一名做的:https://www.kaggle.com/competitions/noaa-fisheries-steller-sea-lion-population-count/overview,他的模型的结构是 ,用VGG-16做特征提取器used VGG-16 as the feature extractor and全连接层的最后一层是回归层 created a fully connected architecture with the last layer being a regression layer
基于 CNN的 crowd couting方法有两种
——人群比较稀疏的场景下,直接回归计数法,input(图片)—CNN网络—>outout(人数)
——人群比较稠密的产经下,density map estimation法,input(图片)——>output(密度图)——>估计人数。预测的好坏取决于密度图的质量。
优势: are successful in dealing with the problems of (1)occlusion and (2)background clutter杂乱(我也不知道是啥)(3)相比 detection based method,避免对学习检测器的依赖
劣势:
(1)无法得到人群分布unable to correctly understand crowd distributions/ ignore spatial information.、定位人群的位置---不能获知人群个体的具体位置localise the crowd.这一重要特征(它只能笼统的告诉你这张图里面一共多少人,并不能告诉你左上角有多少人右下角几个人,density based methods成功解决了这个问题,因为它可以提供像素级别的回归 as they perform pixel-wise regressions for getting better performance of the model.,密度图上哪个坐标有人都用颜色标出来,你就可以定位人群的位置了
(2)这种方法,前期的特征工程决定了模型performance的上限,严重依赖优秀的特征构建能力。但是深度学习的方法,直接建立original image and its numbers之间的映射关系,比起 hand-crafted features效果好太多,所以regression-based method慢慢被抛弃了
(3)这种方法对图像分辨率很敏感,如果图片的清晰度比较低,那么回归的效果会差。
(4)可能存在鲁棒性较差的情况,因为其网络学习特征与人的关联性不是强相关,当测试环境变化时,很容易失控,且可解释性也较差。
三种方法对比
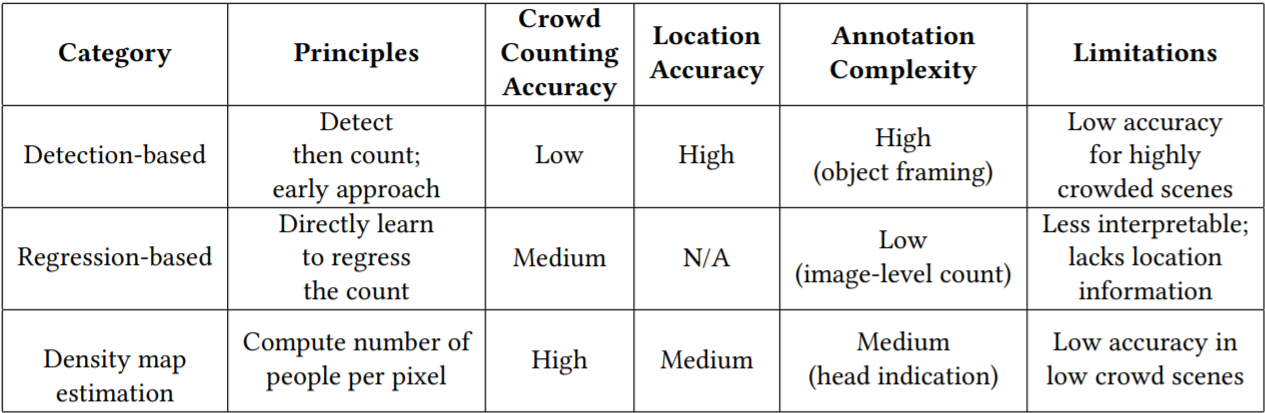
(补充给你,我也没看懂)
文章提到没有一种单独的方法可以计算低分辨率、严重遮挡、透视和透视导致的图片记数问题,发现了一种数学空间关系,可以约束邻近区的计数估计,因此通过将拥挤人群看成不规则非均匀的纹理,使用傅里叶分析和头部检测,并在邻近筛选信息点,通过傅里叶,信息点,和头部检测进行结合,在局部的补丁内进行计算,并在一个多尺度的MRF框架内进行全局约束
当遇到稀疏和不平衡的数据时,提出了学习回归模式的累积属性表示,将特征映射到一个累积的属性空间内。