机器学习之MATLAB代码--LSTM+GRU+CNN+RNN(十四)
RNN代码
clc
close all
clear all
%%
%%%% 训练数据
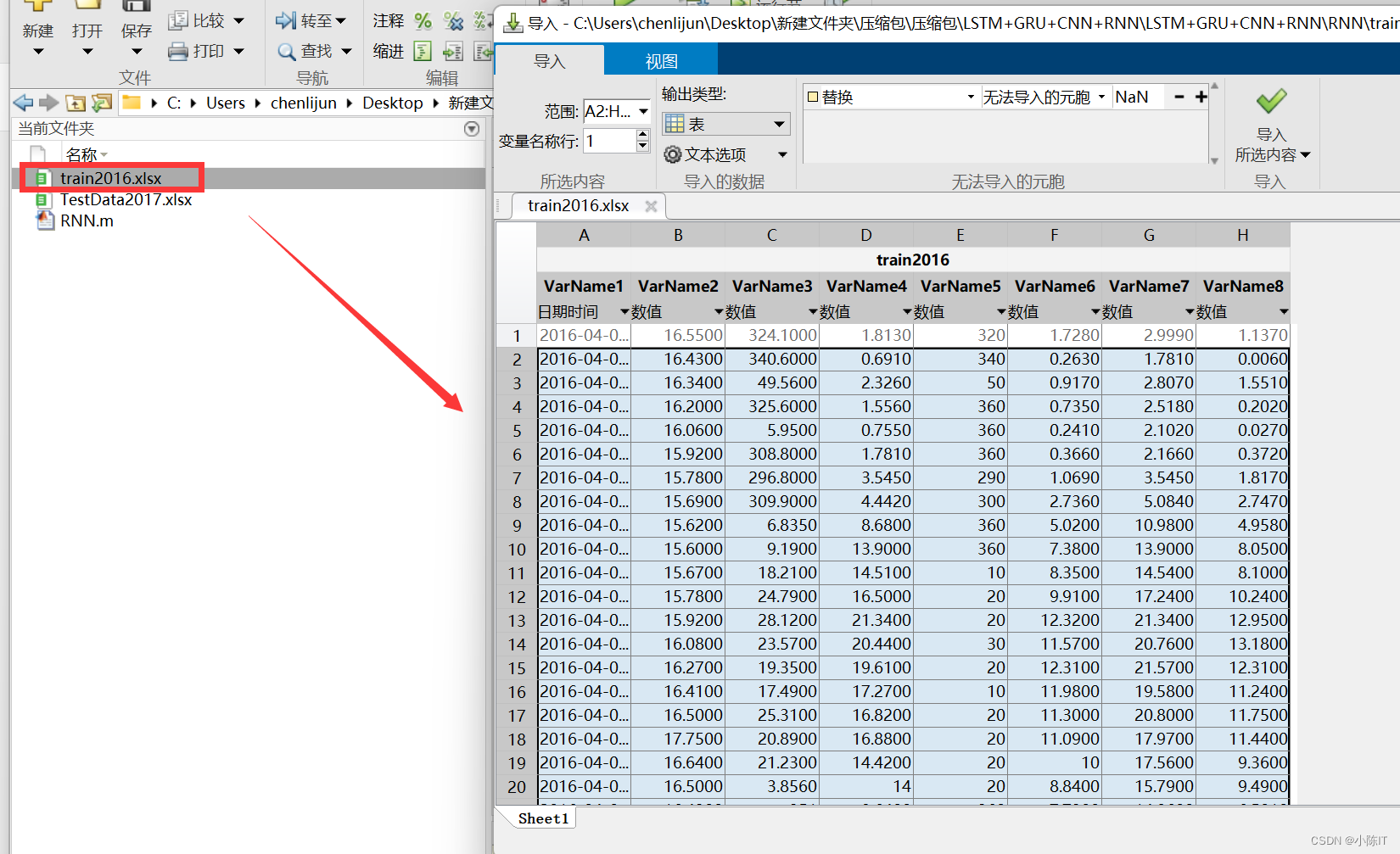
XTrain = xlsread('train2016.xlsx',1,'B1:G5112');
YTrain = xlsread('train2016.xlsx',1,'H1:H5112');
XTrain = XTrain';
YTrain = YTrain';
XrTrain = cell(size(XTrain,2),1);
YrTrain = zeros(size(YTrain,2),1);
for i=1:size(XTrain,2)
XrTrain{
i,1} = XTrain(:,i);
YrTrain(i,1) = YTrain(:,i);
end
% 测试数据
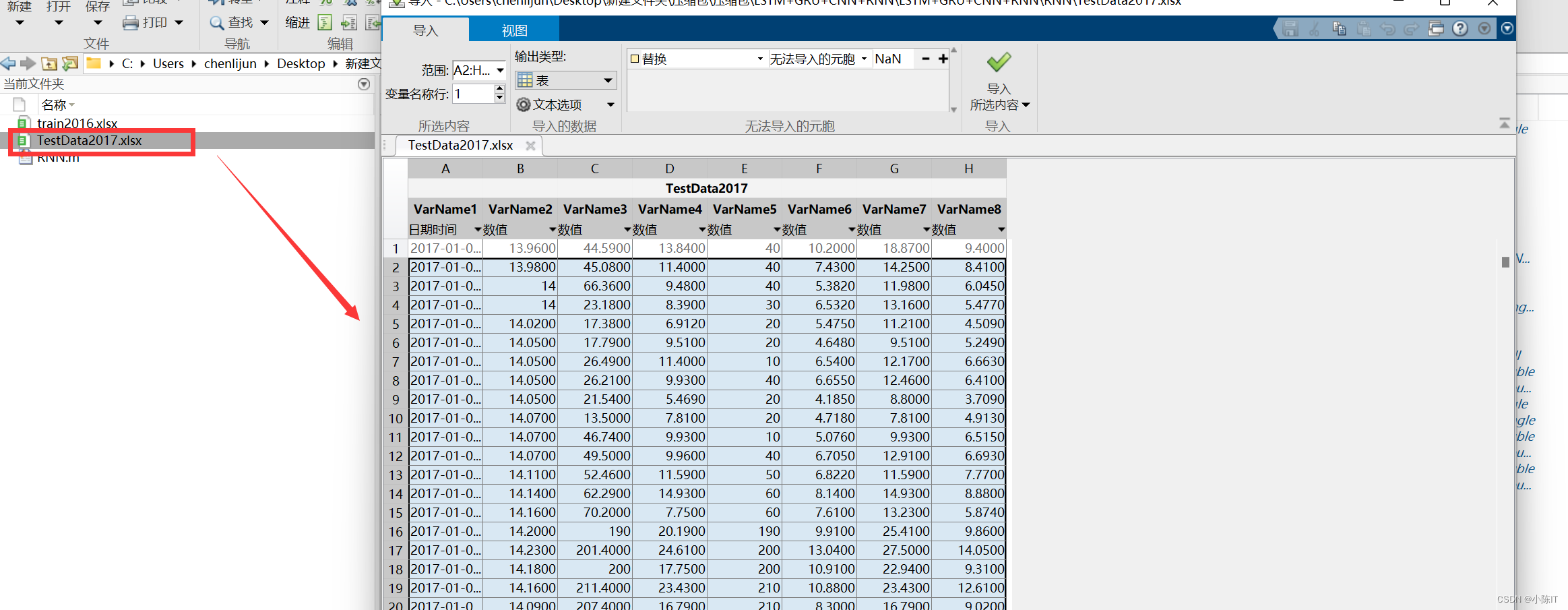
XTest = xlsread('TestData2017.xlsx',1,'B1:G642');
YTest = xlsread('TestData2017.xlsx',1,'H1:H642');
XTest = XTest';
YTest = YTest';
XrTest = cell(size(XTest,2),1);
YrTest = zeros(size(YTest,2),1);
for i=1:size(XTest,2)
XrTest{
i,1} = XTest(:,i);
YrTest(i,1) = YTest(:,i);
end
%%
numFeatures = size(XTrain,1);% 特征维度=滑动窗长度
numResponses = 1;FiltZise = 5;
%%%% RNN 结构设计
layers = [...
sequenceInputLayer(numFeatures,'Name','input')
% from here the RNN design. Feel free to add or remove layers
gruLayer(128,'Name','gru1','RecurrentWeightsInitializer','He','InputWeightsInitializer','He')
lstmLayer(64,'Name','gru2','RecurrentWeightsInitializer','He','InputWeightsInitializer','He')
dropoutLayer(0.5,'Name','drop2')
% this last part you must change the outputmode to last
lstmLayer(32,'OutputMode','last','Name','bil4','RecurrentWeightsInitializer','He','InputWeightsInitializer','He')
dropoutLayer(0.5,'Name','drop3')
% here finish the RNN design
% use a fully connected layer with one neuron because you will predict one step ahead
fullyConnectedLayer(numResponses,'Name','fc')
regressionLayer('Name','output') ];
%%%%% 网络参数设置
if gpuDeviceCount>0
mydevice = 'gpu';
else
mydevice = 'cpu';
end
options = trainingOptions('adam', ...
'MaxEpochs',150, ...
'GradientThreshold',1, ...
'InitialLearnRate',0.001, ...
'LearnRateSchedule',"piecewise", ...
'LearnRateDropPeriod',96, ...
'LearnRateDropFactor',0.25, ...
'MiniBatchSize',64,...
'Verbose',false, ...
'Shuffle',"every-epoch",...
'ExecutionEnvironment',mydevice,...
'Plots','training-progress');
net = trainNetwork(XrTrain,YrTrain,layers,options);
%% 利用模型对测试集进行预测
YPred_Train = predict(net,XrTrain, ...
"ExecutionEnvironment",mydevice,"MiniBatchSize",numFeatures);
YPred_Train = YPred_Train';
YPred = predict(net,XrTest, ...
"ExecutionEnvironment",mydevice,"MiniBatchSize",numFeatures);
YPred = YPred';
%%
figure;
hold on
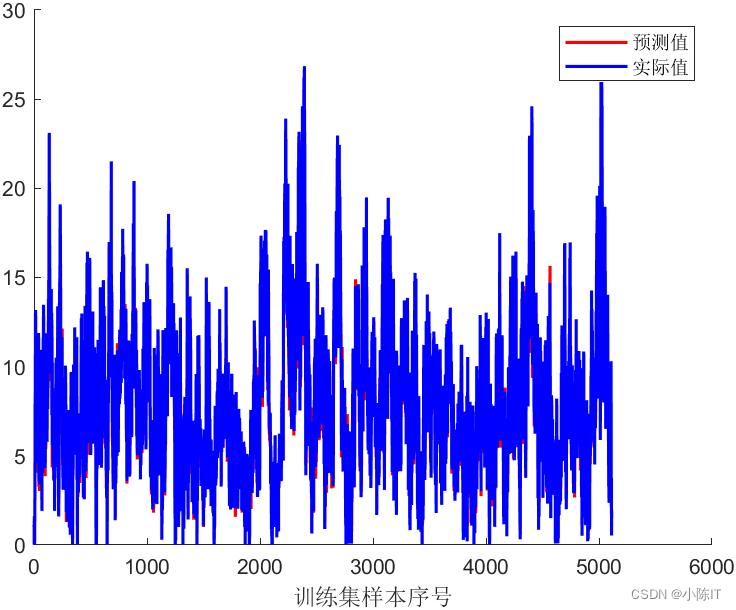
plot(1:size(YrTrain,1), YPred_Train,'r-','LineWidth',1.5);
plot(1:size(YrTrain,1), YrTrain,'b-','LineWidth',1.5);
legend('预测值','实际值')
xlabel('训练集样本序号')
figure;
hold on
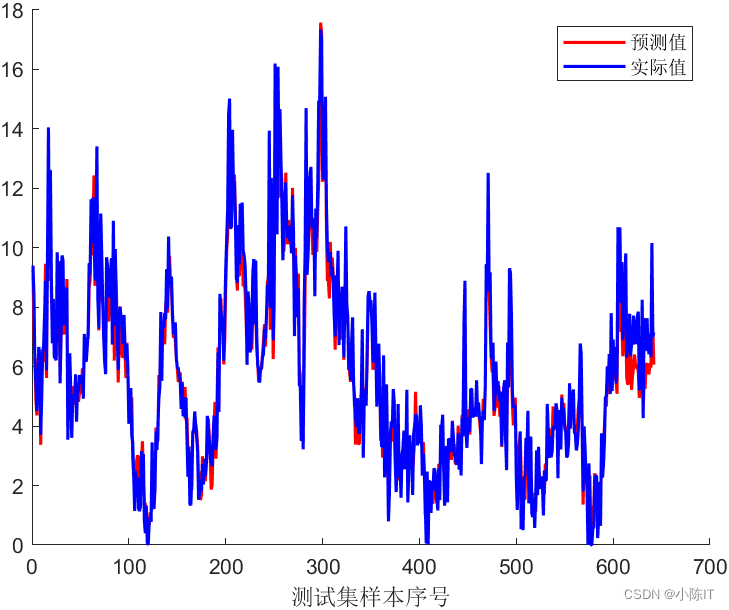
plot(1:size(YrTest,1), YPred,'r-','LineWidth',1.5);
plot(1:size(YrTest,1), YrTest,'b-','LineWidth',1.5);
legend('预测值','实际值')
xlabel('测试集样本序号')
% % 评价
ae= abs(YPred - YTest);
rmse = (mean(ae.^2)).^0.5;
mse = mean(ae.^2);
mae = mean(ae);
mape = mean(ae./YPred);
disp('预测结果评价指标:')
disp(['RMSE = ', num2str(rmse)])
disp(['MSE = ', num2str(mse)])
disp(['MAE = ', num2str(mae)])
disp(['MAPE = ', num2str(mape)])
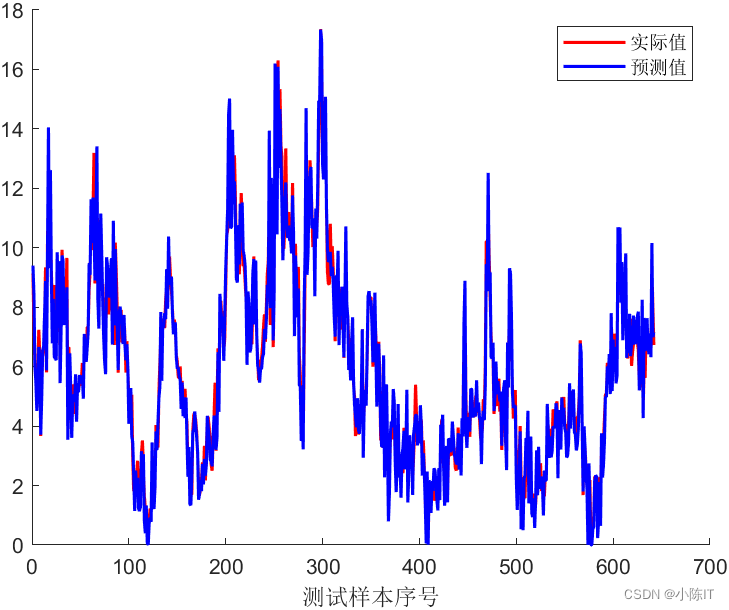
RNN数据
RNN结果
LSTM代码
clc
close all
clear all
%训练数据
XTrain = xlsread('train2016.xlsx',1,'B1:G5112');
YTrain = xlsread('train2016.xlsx',1,'H1:H5112');
mu = mean(XTrain,'ALL');
sig = std(XTrain,0,'ALL');
XTrain = (XTrain - mu)/sig;
YTrain = (YTrain - mu)/sig;
XTrain = XTrain';
YTrain = YTrain';
XTest = xlsread('TestData2017.xlsx',1,'B1:G642');
YTest = xlsread('TestData2017.xlsx',1,'H1:H642');
XTest = (XTest - mu)/sig;
YTest = (YTest - mu)/sig;
XTest = XTest';
YTest = YTest';
%% define the Deeper LSTM networks
%创建LSTM回归网络,指定LSTM层的隐含单元个数125
%序列预测,因此,输入一维,输出一维
numFeatures= 6;%输入特征的维度
numResponses = 1;%响应特征的维度
numHiddenUnits = 100;%隐藏单元个数
layers = [sequenceInputLayer(numFeatures)
lstmLayer(numHiddenUnits)
dropoutLayer(0.5)%防止过拟合
fullyConnectedLayer(numResponses)
regressionLayer];
MaxEpochs=500;%最大迭代次数
InitialLearnRate=0.005;%初始学习率
%% back up to LSTM model
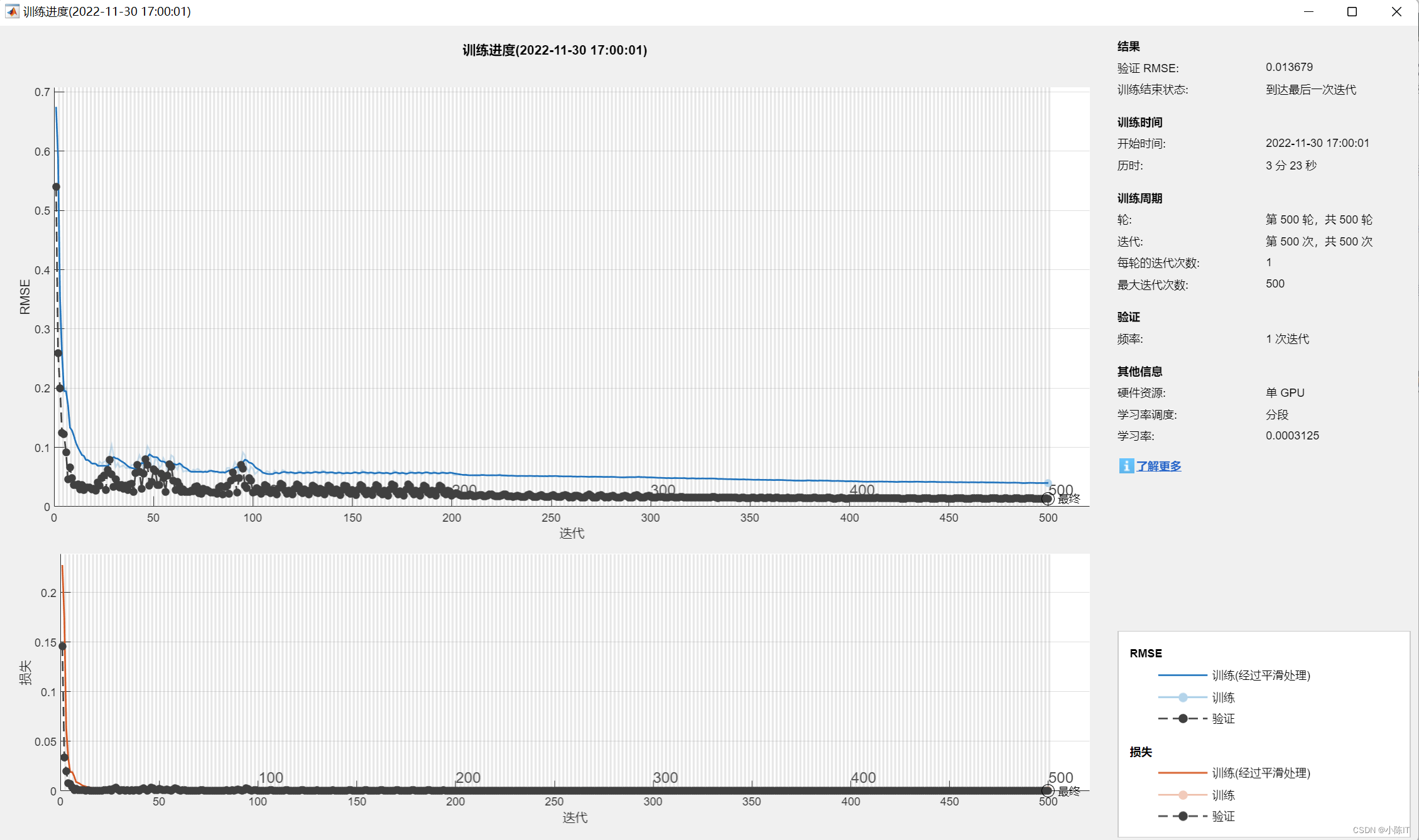
options = trainingOptions('adam', ...
'MaxEpochs',MaxEpochs,...%30用于训练的最大轮次数,迭代是梯度下降算法中使用小批处理来最小化损失函数的一个步骤。一个轮次是训练算法在整个训练集上的一次全部遍历。
'MiniBatchSize',128, ... %128小批量大小,用于每个训练迭代的小批处理的大小,小批处理是用于评估损失函数梯度和更新权重的训练集的子集。
'GradientThreshold',1, ...%梯度下降阈值
'InitialLearnRate',InitialLearnRate, ...%全局学习率。默认率是0.01,但是如果网络训练不收敛,你可能希望选择一个更小的值。默认情况下,trainNetwork在整个训练过程中都会使用这个值,除非选择在每个特定的时间段内通过乘以一个因子来更改这个值。而不是使用一个小的固定学习速率在整个训练, 在训练开始时选择较大的学习率,并在优化过程中逐步降低学习率,可以帮助缩短训练时间,同时随着训练的进行,可以使更小的步骤达到最优值,从而在训练结束时进行更精细的搜索。
'LearnRateSchedule','piecewise', ...%在训练期间降低学习率的选项,默认学习率不变。'piecewise’表示在学习过程中降低学习率
'LearnRateDropPeriod',100, ...% 10降低学习率的轮次数量,每次通过指定数量的epoch时,将全局学习率与学习率降低因子相乘
'LearnRateDropFactor',0.5, ...%学习下降因子
'ValidationData',{
XTrain,YTrain}, ...% ValidationData用于验证网络性能的数据,即验证集
'ValidationFrequency',1, ...%以迭代次数表示的网络验证频率,“ValidationFrequency”值是验证度量值之间的迭代次数。
'Verbose',1, ...%1指示符,用于在命令窗口中显示训练进度信息,显示的信息包括轮次数、迭代数、时间、小批量的损失、小批量的准确性和基本学习率。训练一个回归网络时,显示的是均方根误差(RMSE),而不是精度。如果在训练期间验证网络。
'Plots','training-progress');
%% Train LSTM Network
net = trainNetwork(XTrain,YTrain,layers,options);
% net = predictAndUpdateState(net,XTrain);
numTimeStepsTrain = numel(XTrain(1,:));
for i = 1:numTimeStepsTrain
[net,YPred_Train(i)] = predictAndUpdateState(net,XTrain(:,i),'ExecutionEnvironment','cpu');
end
YPred_Train = sig*YPred_Train + mu;
YTrain = sig*YTrain + mu;
numTimeStepsTest = numel(XTest(1,:));
for i = 1:numTimeStepsTest
[net,YPred(i)] = predictAndUpdateState(net,XTest(:,i),'ExecutionEnvironment','cpu');
end
YPred = sig*YPred + mu;
YTest = sig*YTest + mu;
figure
hold on
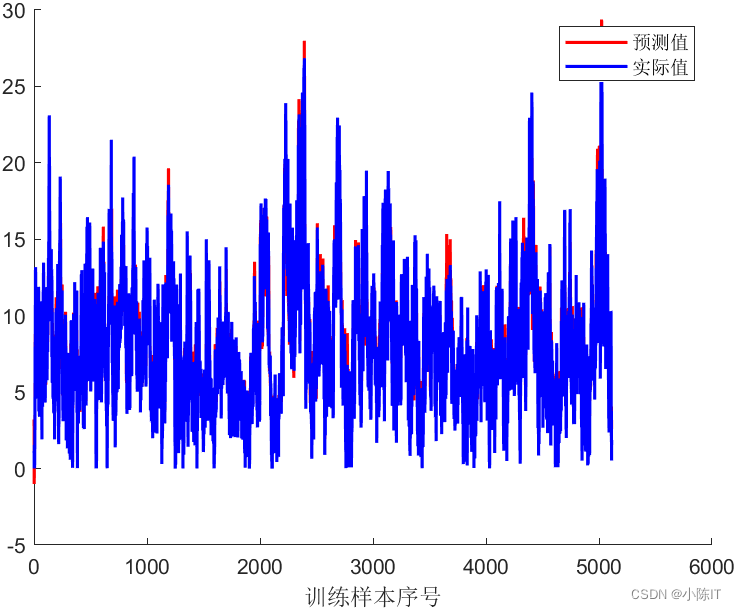
plot(1:length(YPred_Train),YPred_Train,'r-','LineWidth',1.5);
plot(1:length(YTrain),YTrain,'b-','LineWidth',1.5);
legend('预测值','实际值')
xlabel('训练样本序号')
figure
hold on
plot(1:length(YPred),YPred,'r-','LineWidth',1.5);
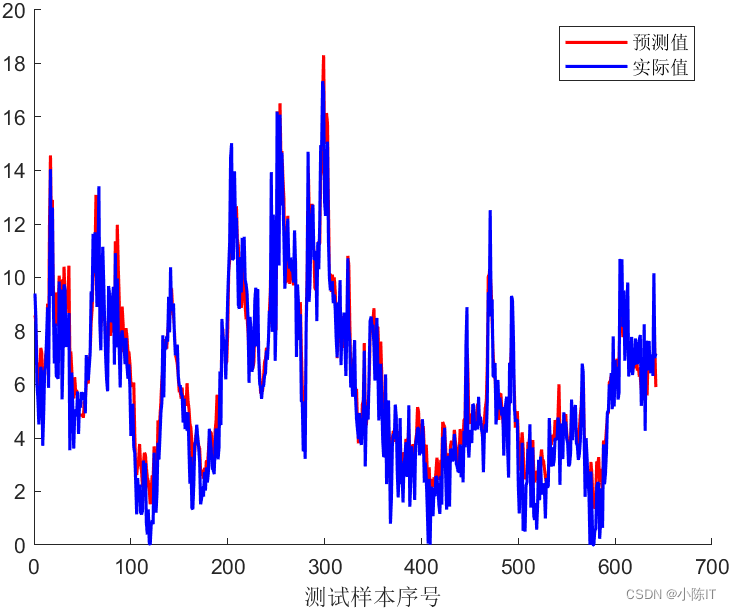
plot(1:length(YTest),YTest,'b-','LineWidth',1.5);
legend('预测值','实际值')
xlabel('测试样本序号')
% % 评价
ae= abs(YPred - YTest);
RMSE = (mean(ae.^2)).^0.5;
MSE = mean(ae.^2);
MAE = mean(ae);
MAPE = mean(ae./YPred);
disp('预测结果评价指标:')
disp(['RMSE = ', num2str(RMSE)])
disp(['MSE = ', num2str(MSE)])
disp(['MAE = ', num2str(MAE)])
disp(['MAPE = ', num2str(MAPE)])
%
% MSE = double(mse(YTest,YPred))
% RMSE = sqrt(MSE)
LSTM数据
LSTM结果
GRU代码
clc
close all
clear all
%训练数据
XTrain = xlsread('train2016.xlsx',1,'B1:G5112');
YTrain = xlsread('train2016.xlsx',1,'H1:H5112');
mu = mean(XTrain,'ALL');
sig = std(XTrain,0,'ALL');
XTrain = (XTrain - mu)/sig;
YTrain = (YTrain - mu)/sig;
XTrain = XTrain';
YTrain = YTrain';
XTest = xlsread('TestData2017.xlsx',1,'B1:G642');
YTest = xlsread('TestData2017.xlsx',1,'H1:H642');
XTest = (XTest - mu)/sig;
YTest = (YTest - mu)/sig;
XTest = XTest';
YTest = YTest';
%% define the Deeper LSTM networks
%创建LSTM回归网络,指定LSTM层的隐含单元个数125
%序列预测,因此,输入一维,输出一维
numFeatures= 6;%输入特征的维度
numResponses = 1;%响应特征的维度
numHiddenUnits = 100;%隐藏单元个数
layers = [sequenceInputLayer(numFeatures)
gruLayer(numHiddenUnits)
% dropoutLayer(0.5)%防止过拟合
fullyConnectedLayer(numResponses)
regressionLayer];
MaxEpochs=500;%最大迭代次数
InitialLearnRate=0.005;%初始学习率
%% back up to LSTM model
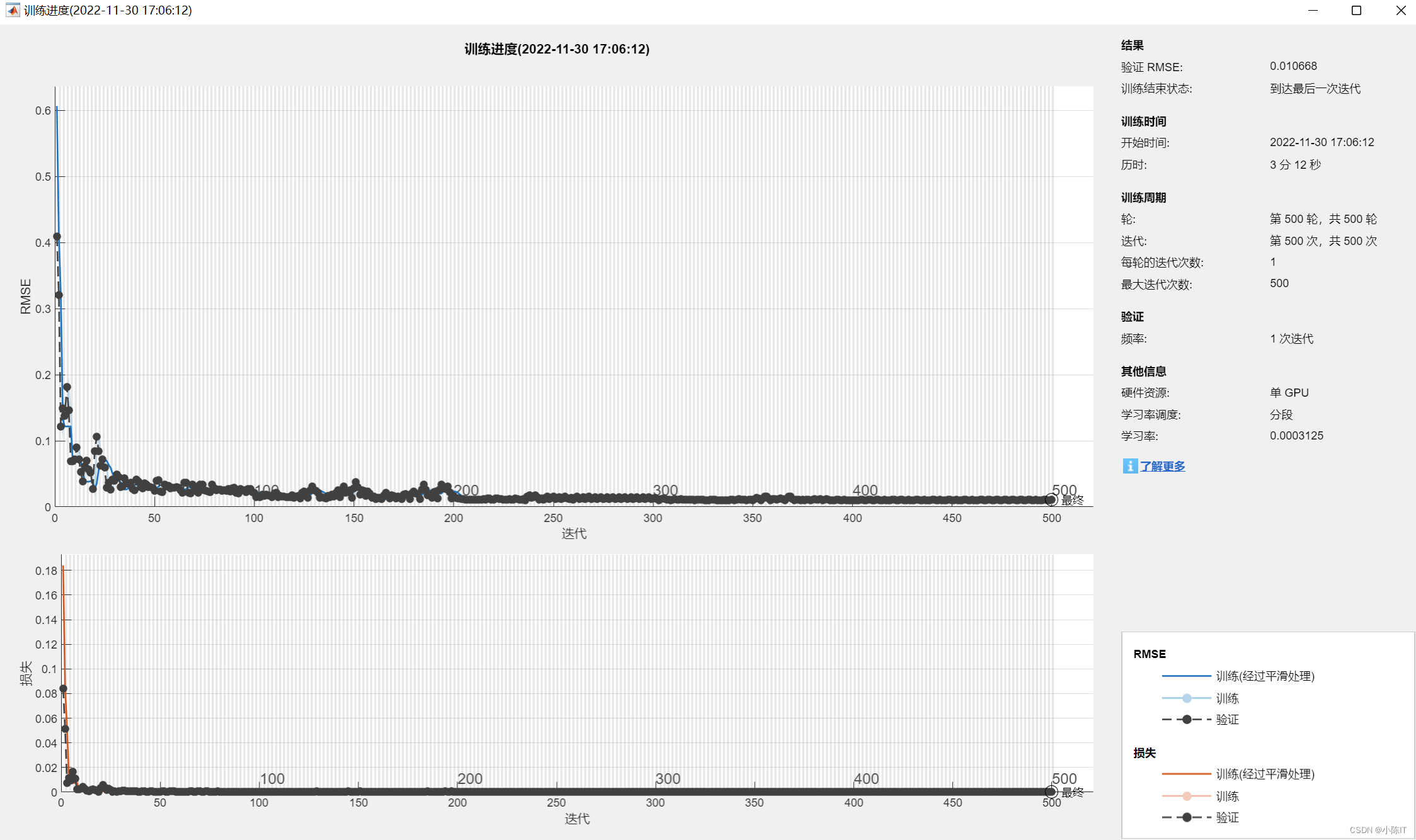
options = trainingOptions('adam', ...
'MaxEpochs',MaxEpochs,...%30用于训练的最大轮次数,迭代是梯度下降算法中使用小批处理来最小化损失函数的一个步骤。一个轮次是训练算法在整个训练集上的一次全部遍历。
'MiniBatchSize',128, ... %128小批量大小,用于每个训练迭代的小批处理的大小,小批处理是用于评估损失函数梯度和更新权重的训练集的子集。
'GradientThreshold',1, ...%梯度下降阈值
'InitialLearnRate',InitialLearnRate, ...%全局学习率。默认率是0.01,但是如果网络训练不收敛,你可能希望选择一个更小的值。默认情况下,trainNetwork在整个训练过程中都会使用这个值,除非选择在每个特定的时间段内通过乘以一个因子来更改这个值。而不是使用一个小的固定学习速率在整个训练, 在训练开始时选择较大的学习率,并在优化过程中逐步降低学习率,可以帮助缩短训练时间,同时随着训练的进行,可以使更小的步骤达到最优值,从而在训练结束时进行更精细的搜索。
'LearnRateSchedule','piecewise', ...%在训练期间降低学习率的选项,默认学习率不变。'piecewise’表示在学习过程中降低学习率
'LearnRateDropPeriod',100, ...% 10降低学习率的轮次数量,每次通过指定数量的epoch时,将全局学习率与学习率降低因子相乘
'LearnRateDropFactor',0.5, ...%学习下降因子
'ValidationData',{
XTrain,YTrain}, ...% ValidationData用于验证网络性能的数据,即验证集
'ValidationFrequency',1, ...%以迭代次数表示的网络验证频率,“ValidationFrequency”值是验证度量值之间的迭代次数。
'Verbose',1, ...%1指示符,用于在命令窗口中显示训练进度信息,显示的信息包括轮次数、迭代数、时间、小批量的损失、小批量的准确性和基本学习率。训练一个回归网络时,显示的是均方根误差(RMSE),而不是精度。如果在训练期间验证网络。
'Plots','training-progress');
%% Train LSTM Network
net = trainNetwork(XTrain,YTrain,layers,options);
% net = predictAndUpdateState(net,XTrain);
numTimeStepsTrain = numel(XTrain(1,:));
for i = 1:numTimeStepsTrain
[net,YPred_Train(i)] = predictAndUpdateState(net,XTrain(:,i),'ExecutionEnvironment','cpu');
end
YPred_Train = sig*YPred_Train + mu;
YTrain = sig*YTrain + mu;
numTimeStepsTest = numel(XTest(1,:));
for i = 1:numTimeStepsTest
[net,YPred(i)] = predictAndUpdateState(net,XTest(:,i),'ExecutionEnvironment','cpu');
end
YPred = sig*YPred + mu;
YTest = sig*YTest + mu;
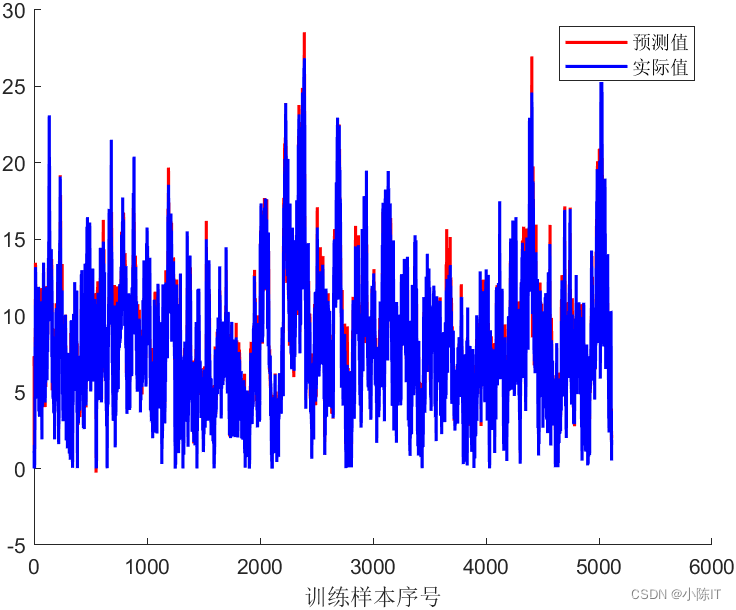
figure
hold on
plot(1:length(YPred_Train),YPred_Train,'r-','LineWidth',1.5);
plot(1:length(YTrain),YTrain,'b-','LineWidth',1.5);
legend('预测值','实际值')
xlabel('训练样本序号')
figure
hold on
plot(1:length(YPred),YPred,'r-','LineWidth',1.5);
plot(1:length(YTest),YTest,'b-','LineWidth',1.5);
legend('预测值','实际值')
xlabel('测试样本序号')
% % 评价
ae= abs(YPred - YTest);
rmse = (mean(ae.^2)).^0.5;
mse = mean(ae.^2);
mae = mean(ae);
mape = mean(ae./YPred);
disp('预测结果评价指标:')
disp(['RMSE = ', num2str(rmse)])
disp(['MSE = ', num2str(mse)])
disp(['MAE = ', num2str(mae)])
disp(['MAPE = ', num2str(mape)])
GRU数据
GRU结果
CNN代码
clc;
clear all
close all
%训练数据
input_train = xlsread('train2016.xlsx',1,'B1:G5112');
output_train = xlsread('train2016.xlsx',1,'H1:H5112');
input_train = input_train';
output_train = output_train';
input_test = xlsread('TestData2017.xlsx',1,'B1:G642');
output_test = xlsread('TestData2017.xlsx',1,'H1:H642');
input_test = input_test';
output_test = output_test';
[inputn_train,inputps]=mapminmax(input_train);
[outputn_train,outputps]=mapminmax(output_train);
inputn_test=mapminmax('apply',input_test,inputps);
outputn_test=mapminmax('apply',output_test,outputps);
inputn =[inputn_train inputn_test];
outputn=[outputn_train outputn_test];
%训练集输入
trainD=reshape(inputn_train, [6,1,1,size(inputn_train,2)]);
%测试集输入
testD =reshape(inputn_test, [6,1,1,size(inputn_test,2)]);
layers = [
imageInputLayer([6 1 1])
convolution2dLayer(3,16,'Padding','same')
reluLayer
fullyConnectedLayer(100)
fullyConnectedLayer(100)
fullyConnectedLayer(1)
regressionLayer];
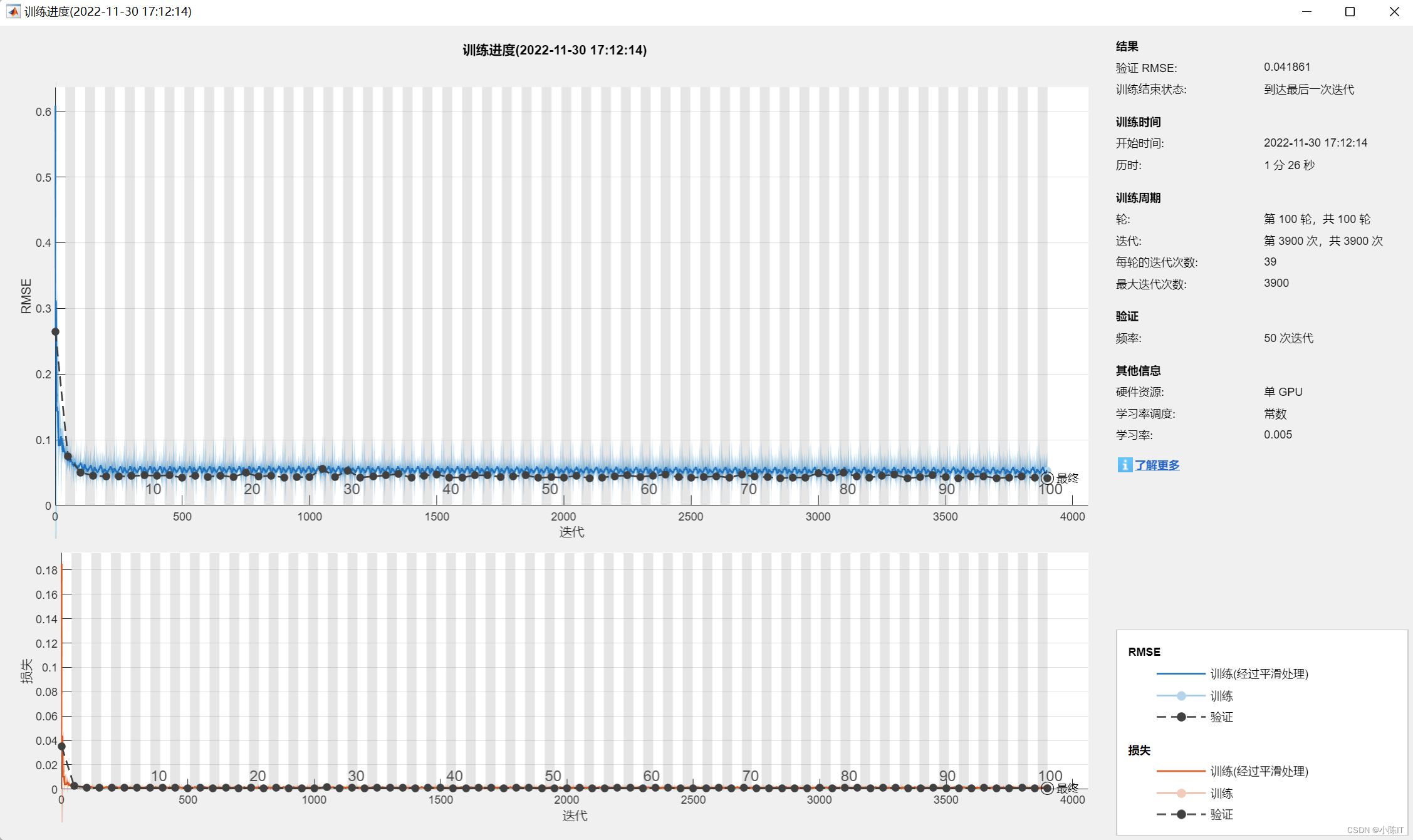
options = trainingOptions('adam', ...
'MaxEpochs',100, ...
'MiniBatchSize',128, ...
'InitialLearnRate',0.005, ...
'GradientThreshold',1, ...
'Verbose',false,...
'Plots','training-progress',...
'ValidationData',{
testD,outputn_test'});
CNNnet = trainNetwork(trainD,outputn_train',layers,options);
CNNoutputr_train = predict(CNNnet,trainD);
CNNoutputr_train = double(CNNoutputr_train');
CNNoutputr_test = predict(CNNnet,testD);
CNNoutputr_test = double(CNNoutputr_test');
%网络输出反归一化
CNNoutput_train= mapminmax('reverse',CNNoutputr_train,outputps);
CNNoutput_train=double(CNNoutput_train);
CNNoutput_test= mapminmax('reverse',CNNoutputr_test,outputps);
CNNoutput_test=double(CNNoutput_test);
figure
hold on
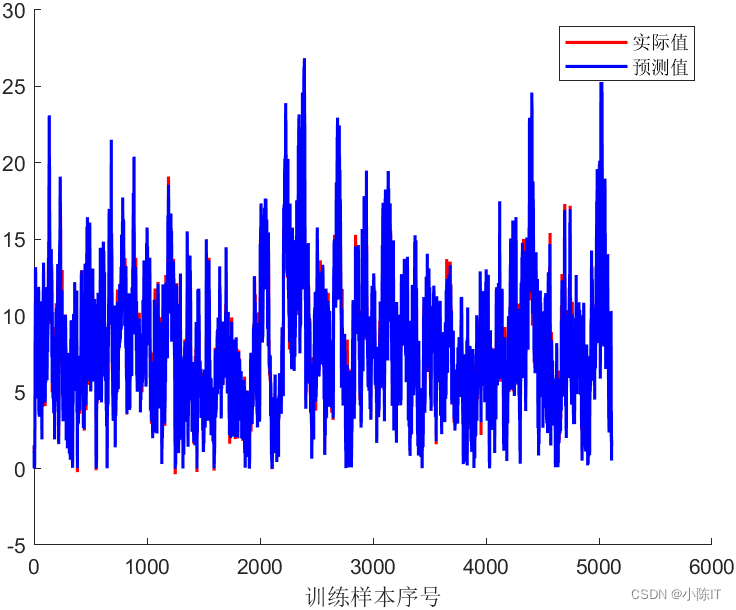
plot(CNNoutput_train,'r-','LineWidth',1.5)
plot(output_train,'b-','LineWidth',1.5)
legend('实际值','预测值');
xlabel('训练样本序号')
figure
hold on
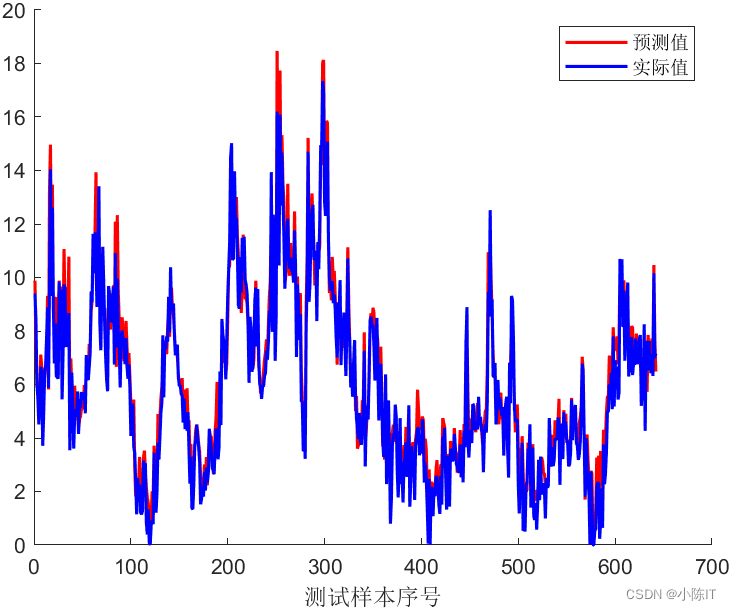
plot(CNNoutput_test,'r-','LineWidth',1.5)
plot(output_test,'b-','LineWidth',1.5)
legend('实际值','预测值');
xlabel('测试样本序号')
ae= abs(CNNoutput_test - output_test);
rmse = (mean(ae.^2)).^0.5;
mse = mean(ae.^2);
mae = mean(ae);
mape = mean(ae./CNNoutput_test);
disp('预测结果评价指标:')
disp(['RMSE = ', num2str(rmse)])
disp(['MSE = ', num2str(mse)])
disp(['MAE = ', num2str(mae)])
disp(['MAPE = ', num2str(mape)])
CNN数据
CNN结果
如有需要代码和数据的同学请在评论区发邮箱,一般一天之内会回复,请点赞+关注谢谢!!