LSTM介绍
LSTM(Long Short Term Memory)是 Hochreater 和 Schmidhuber 在 1997 年提出的一种网络结构,尽管该模型在序列建模上的特性非常突出,但由于当时正是神经网络的下坡期,没有能够引起学术界足够的重视。随着深度学习逐渐发展,后来 LSTM 的应用也逐渐增多。
LSTM 区别于 SimpleRNN 的地方,主要就在于它在算法中加入了一个判断信息有用与否的“处理器”,这个处理器作用的结构被称为记忆块(Memory Block)
memory block 结构主要包含了三个门:遗忘门(Forget Gate)、输入门(Input Gate)、输出门(Output Gate)与一个记忆单元(Cell)。
所有RNN都具有一种重复神经网络模块的链式的形式。在标准的RNN中,这个重复的模块只有一个非常简单的结构,例如一个tanh层:
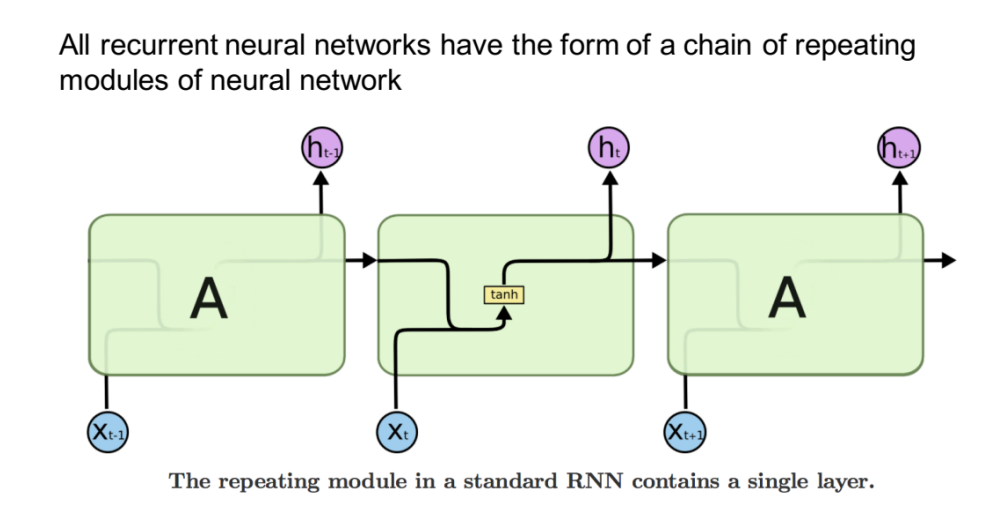
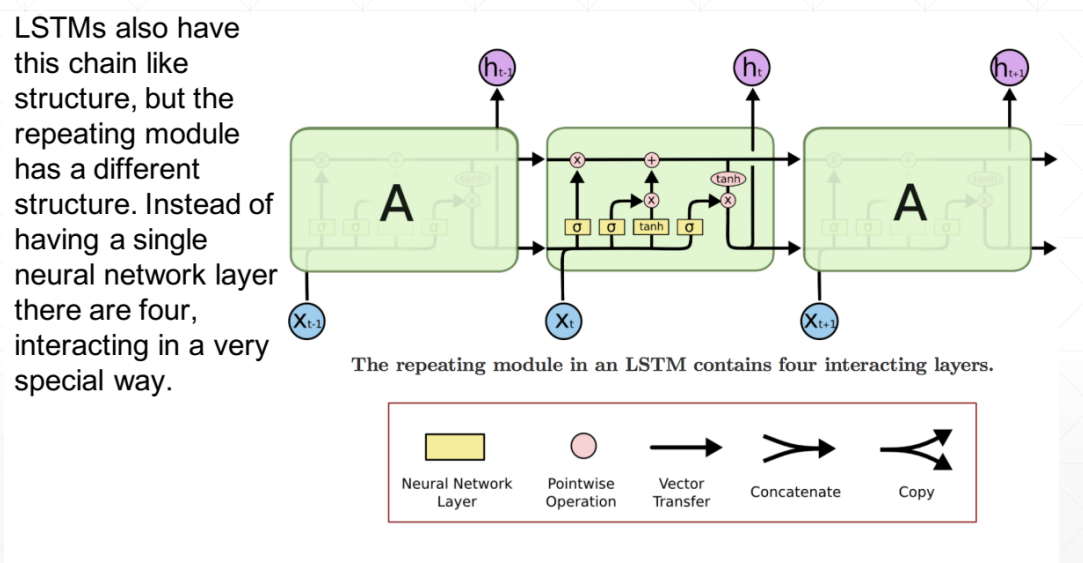
LSTM同样是这样的结构,但是重复的模块拥有一个不同的结构。具体来说,RNN是重复单一的神经网络层,LSTM中的重复模块则包含四个交互的层,三个Sigmoid 和一个tanh层,并以一种非常特殊的方式进行交互。
LSTM的核心思想
LSTM的关键就是细胞状态,水平线在图上方贯穿运行。
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
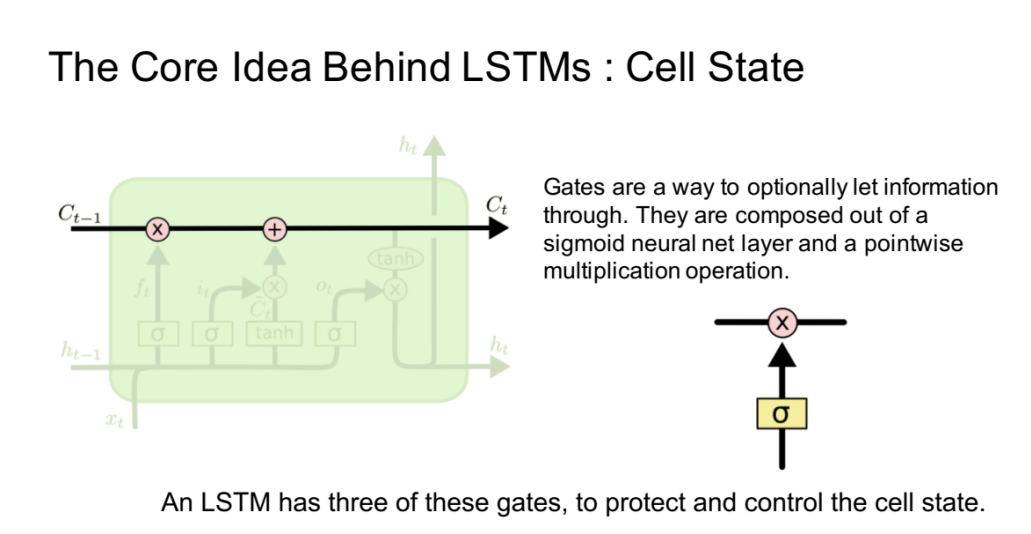
LSTM有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个sigmoid神经网络层和一个pointwise乘法的非线性操作。
如此,0代表“不许任何量通过”,1就指“允许任意量通过”!从而使得网络就能了解哪些数据是需要遗忘,哪些数据是需要保存。
遗忘门(记忆门)
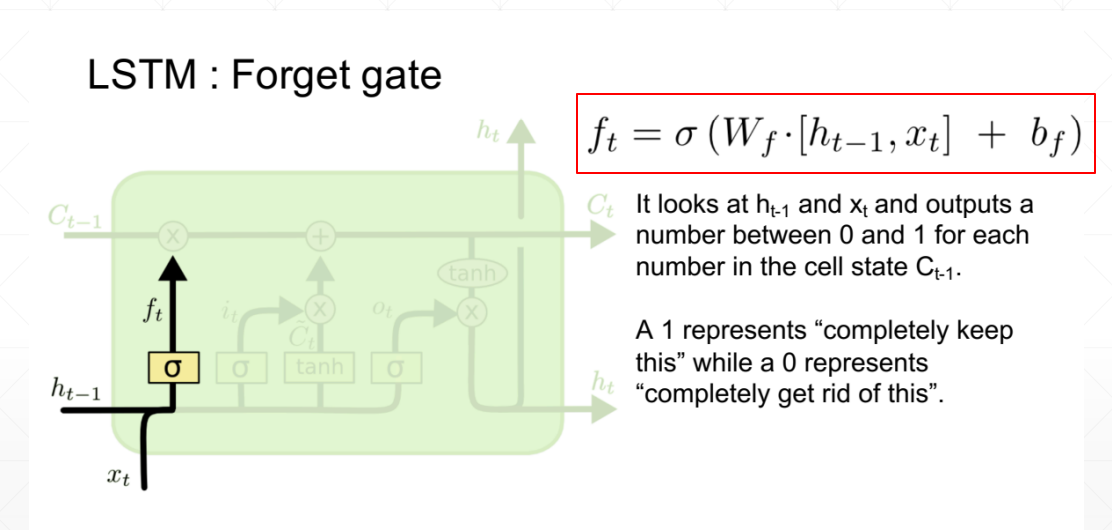
在我们LSTM中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为“遗忘门”的结构完成。该遗忘门会读取上一个输出 h t − 1 h_{t -1} ht−1 和当前输入 x t x_{t } xt,做一个Sigmoid 的非线性映射,然后输出一个向量 f t f_{t } ft(该向量每一个维度的值都在0到1之间,1表示完全保留,0表示完全舍弃,相当于记住了重要的,忘记了无关紧要的),最后与细胞状态 C t − 1 C_{t -1} Ct−1相乘。
输入门和细胞状态
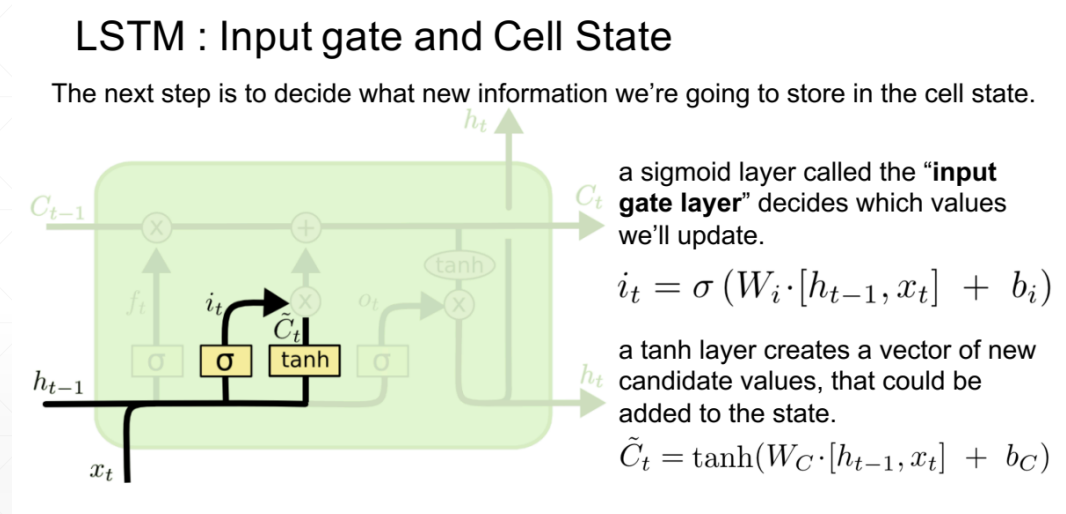
下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分:
- sigmoid层称“输入门层”决定什么值我们将要更新;
- 一个tanh层创建一个新的候选值向量 C ~ t \widetilde{C}_t C t ,会被加入到状态中。
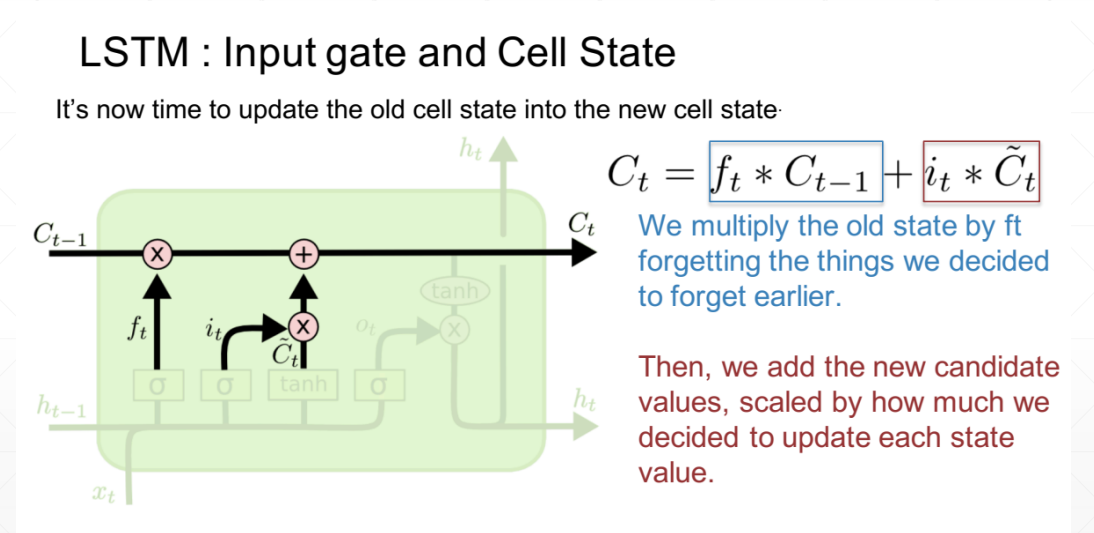
现在是更新旧细胞状态的时间了, C t − 1 C_{t-1} Ct−1更新为 C t C_{t} Ct。前面的步骤已经决定了将会做什么,我们现在就是实际去完成。
我们把旧状态与 f t f_{t} ft 相乘,丢弃掉我们确定需要丢弃的信息,接着加上 i t i_{t} it * C ~ t \widetilde{C}_t C t。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
输出门
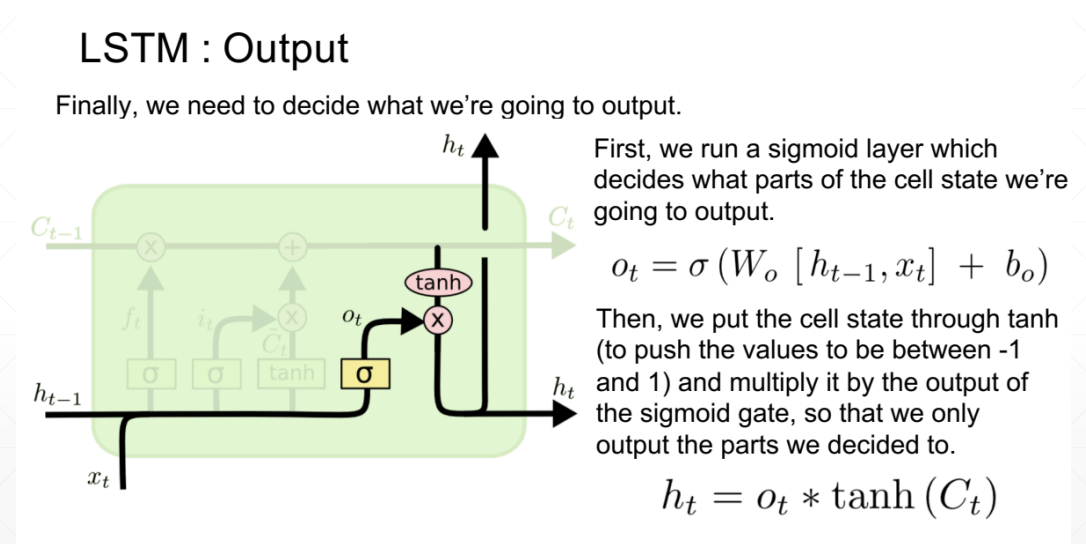
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。
首先,我们运行一个sigmoid层来确定细胞状态的哪个部分将输出出去。
接着,我们把细胞状态通过tanh进行处理(得到一个在-1到1之间的值)并将它和sigmoid门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
LSTM完整结构
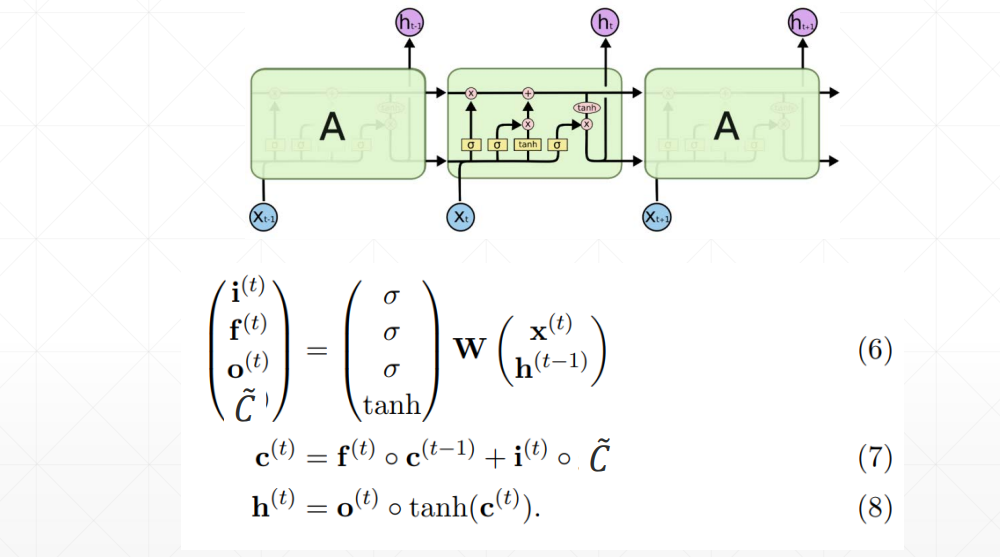
对输入门和遗忘门的理解:

LSTM如何避免梯度弥散?
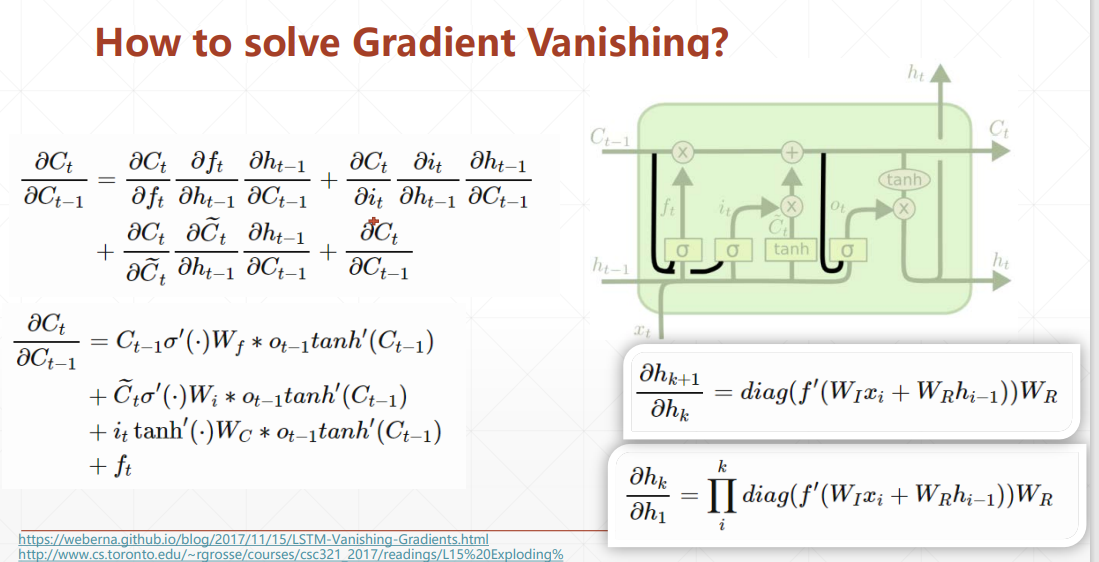
与之前介绍的普通RNN不同,LSTM梯度是几项相加,而不包含激活函数导数连乘。所以LSTM不会存在梯度弥散的问题。
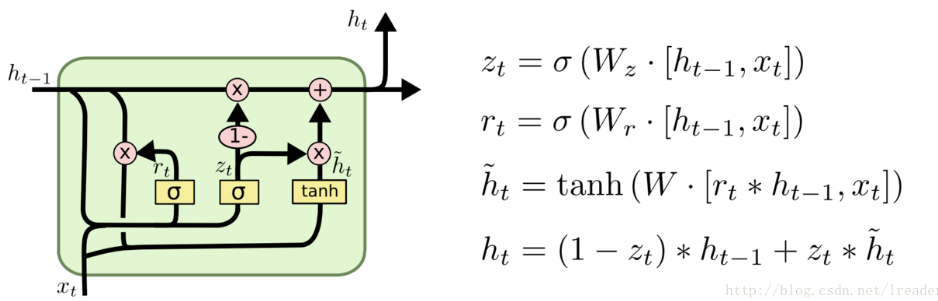
门控循环单元 GRU
GRU(Gated Recurrent Unit)这个结构是 2014 年才出现的,效果跟 LSTM 差不多,但是用到的参数更少,所以计算速度会更快一些。GRU 将遗忘门和输入门合成了一个单一的更新门,同时将记忆单元与隐藏层合并成了重置门,进而让整个结果运算变得更加简化且性能得以增强。