目录
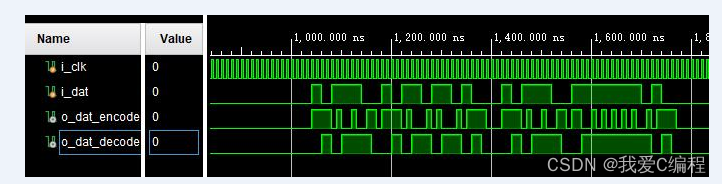
1.算法仿真效果
vivado2019.2仿真结果如下:
2.算法涉及理论知识概要
viterbi译码算法是一种卷积码的解码算法。优点不说了。缺点就是随着约束长度的增加算法的复杂度增加很快。约束长度N为7时要比较的路径就有64条,为8时路径变为128条。 (2<<(N-1))。所以viterbi译码一般应用在约束长度小于10的场合中。
先说编码(举例约束长度为7):编码器7个延迟器的状态(0,1)组成了整个编码器的64个状态。每个状态在编码器输入0或1时,会跳转到另一个之中。比如110100输入1时,变成101001(其实就是移位寄存器)。并且输出也是随之而改变的。
这样解码的过程就是逆过程。算法规定t时刻收到的数据都要进行64次比较,就是64个状态每条路有两条分支(因为输入0或1),同时,跳传到不同的两个状态中去,将两条相应的输出和实际接收到的输出比较,量度值大的抛弃(也就是比较结果相差大的),留下来的就叫做幸存路径,将幸存路径加上上一时刻幸存路径的量度然后保存,这样64条幸存路径就增加了一步。在译码结束的时候,从64条幸存路径中选出一条量度最小的,反推出这条幸存路径(叫做回溯),得出相应的译码输出。
卷积码是把k个信息比特的序列编成n个比特的码组,每个码组的n-k个校验位与本码组的k个信息位有关,而与其他码组无关。为了达到一定的纠错能力和编码效率,分组码的长度一般都比较大。编译码时必须把整个信息码组存储起来,由此产生的译码延时随n的增加而增加。
卷积码是一个有限记忆系统,它也将信息序列分割成长度k的一个个分组,然后将k个信息比特编成n个比特,但k和n通常很小,特别适合以串行形式进行传输,时延小。与分组码不同的是在某一分组编码时,不仅参看本时刻的分组而且参看以前的N-1个分组,编码过程中互相关联的码元个数为nN。N称为约束长度。常把卷积码写成(n,k,N-1)卷积码。正因为卷积码在编码过程中,充分利用了各级之间的相关性,无论是从理论上还是实际上均已证明其性能要优于分组码。
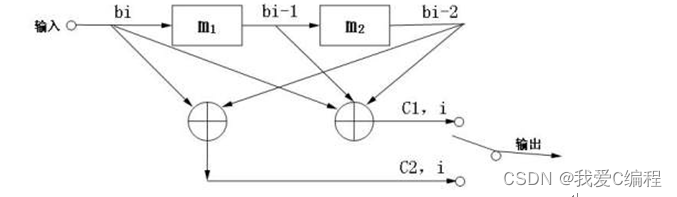
本次设计以(2,1,2)卷积码为例。图2-1为这种卷积编码器的结构,它的编码方法是:序列依次移入一个两级移位寄存器,编码器每输入一位信息b,输出端的开关就在c和c之间来回切换一次,输出为c和c,其中
c=b+b+b
c=b+b
设寄存器m、m的起始状态为全零,则编码器的输入输出时序关系可用图2-2表示。
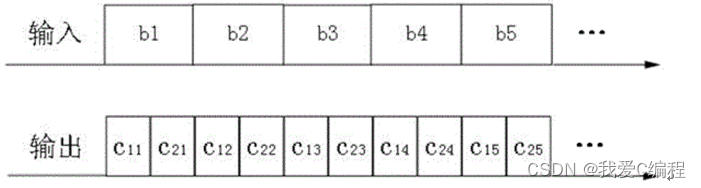
要使最后1 位输入同样影响3对输出,并且使编码器回到全零状态,还需使编码器多输出2对信息,为了做到这一点,需要增加2个时钟循环,并且在此期间保持输入为0,这一过程叫做“点亮”编码器。如果不执行“点亮”操作,最后2位输入信息的纠错能力就会下降。
因为卷积码的编码器的记忆性是有限的,所以可以使用状态转移图来表示其转移过程。在状态转移图中,卷积编码器的每一个状态对应于一个椭圆,状态的转移用两个椭圆间的有向线段表示,在线上标出状态转移的输入和对应的输出。
3.Verilog核心程序
`timescale 1ns / 1ps
//
// Company:
// Engineer:
//
// Create Date: 2023/04/16 22:37:19
// Design Name:
// Module Name: TEST
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
module TEST();
reg i_clk;
reg i_dat;
wire o_dat_encode;
wire o_dat_decode;
tops tops_U(
.i_clk (i_clk),
.i_dat (i_dat),
.o_dat_encode (o_dat_encode),
.o_dat_decode (o_dat_decode)
);
initial
begin
i_clk=1'b1;
end
always #5 i_clk=~i_clk;
initial
begin
i_dat=1'b0;
#1020
{i_dat} =1'b0;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b0;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b0;
#20
{i_dat} =1'b0;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b0;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b0;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b0;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b0;
#20
{i_dat} =1'b0;
#20
{i_dat} =1'b0;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b0;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b0;
#20
{i_dat} =1'b0;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b0;
#20
{i_dat} =1'b1;
#20
{i_dat} =1'b0;
#20
{i_dat} =1'b0;
#20
{i_dat} =1'b0;
#200
$stop();
end
endmodule
A4914.完整算法代码文件
V