文章目录
1.梯度下降
1.1基本概念
梯度下降法(gradient descent),又名最速下降法(steepest descent)是求解无约束最优化问题最常用的方法,它是一种迭代方法,每一步主要的操作是求解目标函数的梯度向量,将当前位置的负梯度方向作为搜索方向(因为在该方向上目标函数下降最快,这也是最速下降法名称的由来)。
方向导数:方向导数是在函数定义域的点对某一方向求导得到的导数。
梯度:梯度是一个向量,函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
公式: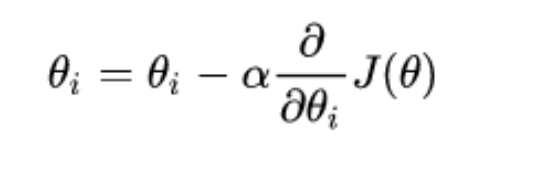
1.2梯度下降法的计算步骤
1.首先给参数设定一个较小的正数值,即随机初始参数,确定学习率(构造损失函数,选择起始点)
2.求当前位置处的各个偏导数(计算偏导)
3.按照公式更新参数(按学习率前进)
4.重复第2步和第3步直到满足终止条件(循环迭代,找到最低点)
1.3经典例题

1.4常用梯度下降算法
1.4.1批量梯度下降(BGD)
BGD需要计算整个训练集的梯度。即:
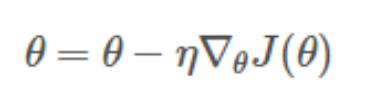
其中η为学习率,用来控制更新的“力度或步长”。
优点:对于凸目标函数可以保证全局最优,对于非凸目标函数只能保证一个局部最优。
缺点:速度慢;数据量大时不可行;无法在线优化(无法处理动态产生的新样本)。
1.4.2随机梯度下降(SGD)
SGD仅计算某个样本的梯度,即针对某一个训练样本 xi及其label yi更新参数。即:
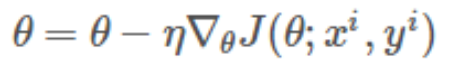
逐步减小学习率,SGD表现得同BGD很相似,最后都可以有不错的收敛。
优点:速度快;可以在线优化(可以处理动态产生的新样本);一定的随机性导致有几率跳出局部最优(随机性来自于用一个样本的梯度去代替整体样本的梯度)。
缺点:随机性可能导致收敛复杂化,即使到达最优点仍然会进行过度优化,因此SGD的优化过程相比BGD充满动荡。
1.4.3小批量梯度下降(MBGD)
MBGD是批量梯度下降法和随机梯度下降法的折衷,也就是对于m个样本,我们采用x个样子来迭代,1<x<m。一般可以取x=10,当然根据样本的数据,可以调整这个x的值。即:
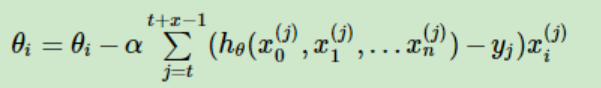
优点;克服上面两种方法的缺点,又同时兼顾两种方法的优点。
在实际使用中:
1)一般情况下,优先采用小批量梯度下降法,在很多情况下SGD默认指代小批量梯度下降法;
2)若数据量小,可直接采用批量梯度下降法;
3)若数据量非常大,或者需要在线优化,可考虑使用随机梯度下降法。
2.一元线性回归
2.1基本概念
回归分析中,如果只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析;如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
一元线性回归其实就是从一堆训练集中去算出一条直线,使数据集到直线之间的距离差最小。
最简单的模型如图所示:
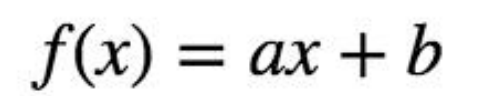
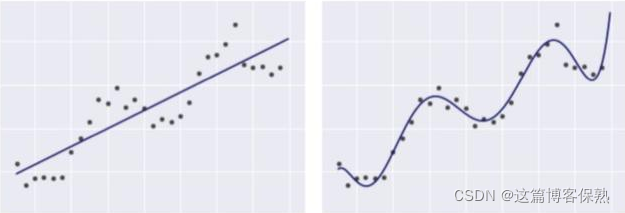
下列2个模型都是线性回归模型,即便右图中的线看起来并不像直线。
2.2原理引入
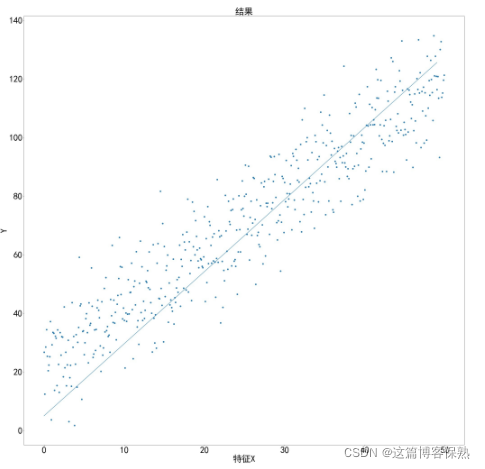
唯一特征X,共有m = 500个数据数量,Y是实际结果,要从中找到一条直线,使数据集到直线之间的距离差最小,如下图所示:

损失函数(代价函数):
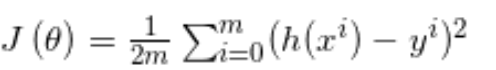
2.3公式推导
