上两章说了urllib和request库如何访问一个页面或者接口,从而获取数据,如果是访问接口,还好说,毕竟返回的json还是很好解析的,他是结构化的,我们可以把它转化成字典来解析,但是如果返回的是xml或者html,就有点麻烦了,今天就主要说一下如果解析这些html内容的工具:xpath和lxml。
xpath
xpath是一个可以在xml和html来查找信息的语言。语法如下
| 表达式 | 描述 | 示例 | 结果 |
|---|---|---|---|
| nodename | 选取该节点下的所有子节点 | article | 获取article下的节点 |
| / | 如果是在最前面,代表从根节点选取。否则选择某节点下的某个节点 | /article | 获取article下节点的信息 |
| // | 从全局节点中选择节点,随便在哪个位置 | //div | 找到所有的节点 |
| @ | 选取某个节点的属性 | //div[@class] | 选取所有div的class的属性值 |
| . | 选取当前节点 | ./a | 选取当钱节点下的a标签 |
例如我们要获取我们csdn博客列表的内容,如下
//div[@class="article-list"]
//获取某一篇文章的简单信息
//div[@class="article-list"]/div[2]
lxml
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。
安装lxml
pip install lxml
使用
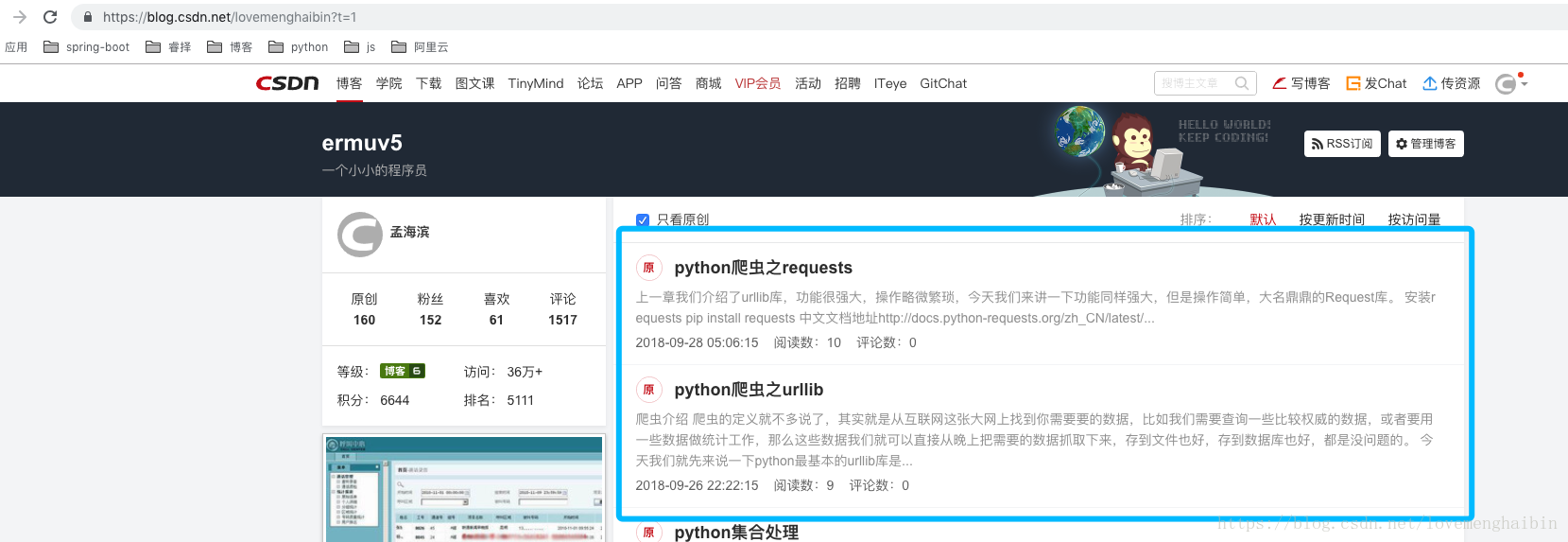
我们打开我的csnd博客也列表,并且获取界面上展示的信息,例如截图下的信息
代码如下:
from lxml import etree
import requests
url = "https://blog.csdn.net/lovemenghaibin?t=1"
header = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
resp = requests.get(url, headers=header)
html = etree.HTML(resp.text)
blogs = html.xpath("//div[@class='article-list']/div[@class='article-item-box csdn-tracking-statistics']")
blogInfos = []
for first in blogs:
href_url = first.xpath("./h4/a/@href")[0]
content = first.xpath("./p[@class='content']/a/text()")[0]
createTime = first.xpath("//span[@class='date']/text()")[0]
readNumStr = first.xpath("//span[@class='read-num']/text()")[0]
readNum = readNumStr.replace("阅读数:", "")
commentStr = first.xpath("//span[@class='read-num']/text()")[1]
commentCount = readNumStr.replace("评论数:", "")
blogInfo = {
"url": href_url,
"content": content,
"createTime": createTime,
"readNum": readNum,
"commentCount": commentCount
}
blogInfos.append(blogInfo)
print(blogInfos)
如果要获取博客的博主信息,则代码如下:
from lxml import etree
import requests
url = "https://blog.csdn.net/lovemenghaibin?t=1"
header = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
resp = requests.get(url, headers=header)
html = etree.HTML(resp.text)
profile = html.xpath("//div[@id='asideProfile']")[0]
meUrl = profile.xpath("./div[1]/div[1]/a/@href")[0]
userName = profile.xpath("./div[1]/div[2]//a/text()")[0]
blogNum = profile.xpath("./div[2]/dl[1]/dd/a/span/text()")[0]
fans = profile.xpath("./div[2]/dl[2]/dd/span/text()")[0]
attentions = profile.xpath("./div[2]/dl[3]/dd/span/text()")[0]
comments = profile.xpath("./div[2]/dl[4]/dd/span/text()")[0]
blogLeve = profile.xpath("./div[3]/dl[1]/dd/a/@title")[0]
readCount = profile.xpath("./div[3]/dl[2]/dd/text()")[0].strip()
pointCount = profile.xpath("./div[3]/dl[3]/dd/text()")[0].strip()
rank = profile.xpath("./div[3]/dl[4]/dd/text()")[0]
profileInfo = {
"homeUrl": meUrl,
"userName": userName,
"blogNum": blogNum,
"fans": fans,
"attentions": attentions,
"comments": comments,
"blogLeve": blogLeve,
"readCount": readCount,
"pointCount": pointCount,
"rank": rank
}
print(profileInfo)
小结
本章介绍了xpath和lxml两个工具,运用比较高效,速度快,学起来语法也比较简单,我们可以直接根据类名查找,也可以根据获取属性的值,例如获取a标签的href属性,也可以获取内部的文本,例如text()语法,查找的话,类似于java解析xml的工具。当然操作xpath的时候一定要在浏览器上安装xpath插件。自己先写一下。
