Path 是一门在 XML 文档中查找信息的语言, 使用路径表达式在 XML 文档中进行导航,包含一个标准函数库,是 XSLT 中的主要元素,是一个 W3C 标准。
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点,节点之间的关系有以下几种:
- 父(Parent):每个元素以及属性都有一个父
- 子(Children):元素节点可有零个、一个或多个子
- 同胞(Sibling):拥有相同的父的节点
- 先辈(Ancestor):某节点的父、父的父,等等。
- 后代(Descendant):某个节点的子,子的子,等等
以下面books.xml为例,描述xpath语法
1 <?xml version="1.0" encoding="UTF-8"?> 2 <bookstore> 3 <book> 4 <title lang="eng">Harry Potter</title> 5 <price>29.99</price> 6 </book> 7 <book> 8 <title lang="eng">Learning XML</title> 9 <price>39.95</price> 10 </book> 11 </bookstore>
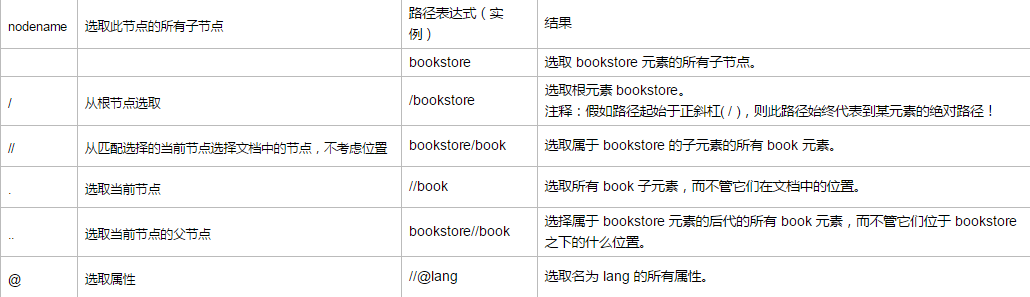
谓语(Predicates):谓语用来查找某个特定的节点或者包含某个指定的值的节点,谓语被嵌在方括号中。
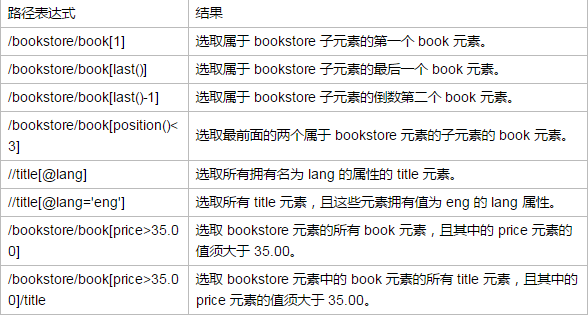
选取未知节点:XPath 通配符可用来选取未知的 XML 元素
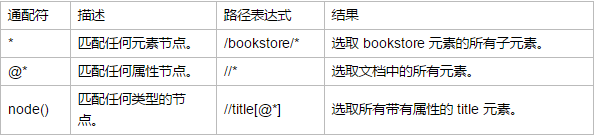
选取若干路径:通过在路径表达式中使用"|"运算符,可以选取若干个路径。在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果

xpathhtml代码:
1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="utf-8" /> 5 <title></title> 6 </head> 7 <body> 8 <script> 9 function loadXMLDoc(dname) { 10 if (window.XMLHttpRequest) { 11 xhttp = new XMLHttpRequest(); 12 } else { 13 xhttp = new ActiveXObject("Microsoft.XMLHTTP"); 14 } 15 xhttp.open("GET", dname, false); 16 xhttp.send(""); 17 return xhttp.responseXML; 18 } 19 20 xml = loadXMLDoc("books.xml"); 21 // path = "/bookstore/book/title"//选取所有 title 还可以这样写:path = "//title[@lang='en']" 22 // path="/bookstore/book[1]/title" //选取第一个 book 的 title 23 //path ="/bookstore/book/price/text()" //选取所有价格 24 //path = "/bookstore/book[price>35]/price" //选取价格高于 35 的 price 节点 25 //path = "//author" //选取作者 26 path = "//price" //选取价格 27 //path = "//year" //选取年份 28 // code for IE 29 if (window.ActiveXObject) { 30 var nodes = xml.selectNodes(path); 31 32 for (i = 0; i < nodes.length; i++) { 33 document.write(nodes[i].childNodes[0].nodeValue); 34 document.write("<br>"); 35 } 36 } 37 // code for Mozilla, Firefox, Opera, etc. 38 else if (document.implementation && document.implementation.createDocument) { 39 var nodes = xml.evaluate(path, xml, null, XPathResult.ANY_TYPE, null); 40 var result = nodes.iterateNext(); 41 while (result) { 42 43 document.write(result.childNodes[0].nodeValue); 44 //document.write(result.nodeValue); //选取所有价格对应的处理 45 document.write("<br>"); 46 result = nodes.iterateNext(); 47 } 48 } 49 </script> 50 </body> 51 52 </html>
实验截图:
