一、算法思想
堆排序是基于二叉树数据结构完成的。
首先,将连续的数组视为一个完全二叉树。
①将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的②根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将③剩余n-1个元素重新构造成一个堆,这样会得到n-1个元素的最大值,也就是n个元素的次大值。如此反复执行,便能得到一个有序序列了。
二、堆排序的优缺点
优点:
- 堆排序的效率与快排、归并相同,都达到了基于比较的排序算法效率的峰值(时间复杂度为O(nlogn))
- 除了高效之外,最大的亮点就是只需要O(1)的辅助空间了,既最高效率又最节省空间,只此一家了
- 堆排序效率相对稳定,不像快排在最坏情况下时间复杂度会变成O(n^2)),所以无论待排序序列是否有序,堆排序的效率都是O(nlogn)不变(注意这里的稳定特指平均时间复杂度=最坏时间复杂度,不是那个“稳定”,因为堆排序本身是不稳定的)
缺点:(从上面看,堆排序几乎是完美的,那么为什么最常用的内部排序算法是快排而不是堆排序呢?)
最大的也是唯一的缺点就是——堆的维护问题,实际场景中的数据是频繁发生变动的,而对于待排序序列的每次更新(增,删,改),我们都要重新做一遍堆的维护,以保证其特性,这在大多数情况下都是没有必要的。(所以快排成为了实际应用中的老大,而堆排序只能在算法书里面顶着光环,当然这么说有些过分了,当数据更新不很频繁的时候,当然堆排序更好些…)
三、源代码
import java.util.Arrays;
import java.util.Random;
/**
* Created by chengxiao on 2016/12/17.
* 堆排序demo
*/
public class HeapSort {
public static void main(String[] args) {
// int[] arr = {65, 80, 12, 23, 67, 49, 27};
int[] arr=new int[new Random().nextInt(9)+1];
for (int i=0;i<arr.length;i++){
arr[i]=new Random().nextInt(100);
}
System.out.println(Arrays.toString(arr));
sort(arr);
System.out.println(Arrays.toString(arr));
}
public static void sort(int[] arr) {
//1.构建大顶堆
for (int i = arr.length / 2 - 1; i >= 0; i--) {
//从第一个非叶子结点从下至上,从右至左调整结构
adjustHeap(arr, i, arr.length);
}
//2.调整堆结构+交换堆顶元素与末尾元素
for (int j = arr.length - 1; j > 0; j--) {
swap(arr, 0, j);//将堆顶元素与末尾元素进行交换
adjustHeap(arr, 0, j);//重新对堆进行调整
}
}
/**
* 调整大顶堆(仅是调整过程,建立在大顶堆已构建的基础上)
*
* @param arr
* @param i
* @param length
*/
public static void adjustHeap(int[] arr, int i, int length) {
int temp = arr[i];//先取出当前元素i
for (int k = i * 2 + 1; k < length; k = k * 2 + 1) {
//从i结点的左子结点开始,也就是2i+1处开始
if (k + 1 < length && arr[k] < arr[k + 1]) {
//如果左子结点小于右子结点,k指向右子结点
k++;
}
if (arr[k] > temp) {
//如果子节点大于父节点,将子节点值赋给父节点(不用进行交换)
arr[i] = arr[k];
i = k;
} else {
break;
}
}
arr[i] = temp;//将temp值放到最终的位置
}
/**
* 交换元素
*
* @param arr
* @param a
* @param b
*/
public static void swap(int[] arr, int a, int b) {
int temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
}
四、过程解析
实例数组:arr = [65, 80, 12, 23, 67, 49, 27]
完全二叉树结构: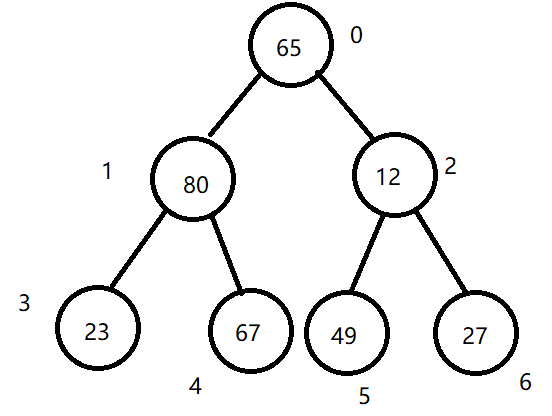
step1:
整理为大根堆,使任意非叶节点总是大于其子节点
(1)用 arr.length / 2 - 1 定位到最后一个非叶结点arr[2]并记录它的值,让其与子节点中较大的一个发生交换。
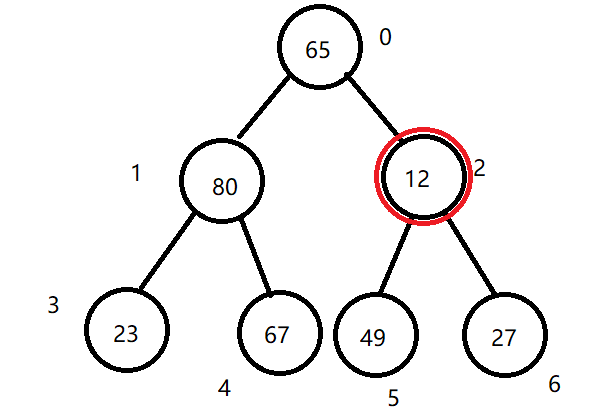
(2)先用 i*2+1 选中左子节点,与右节点比较,确定较大的一个记录它的下标。
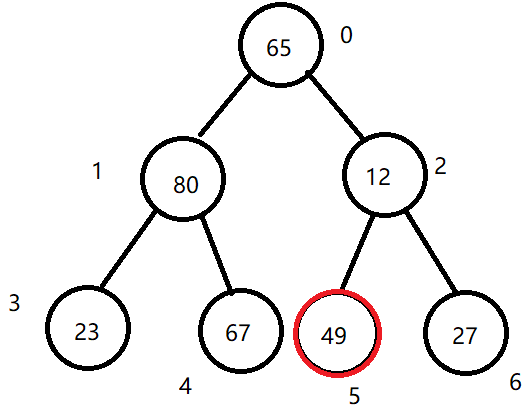
(3)比较记录的父节点的值和子节点的值,如果子节点的值更大则发生交换(之前记录了父节点的值,直接将子节点的值赋值给父节点即可,再将记录的值赋值给子节点)。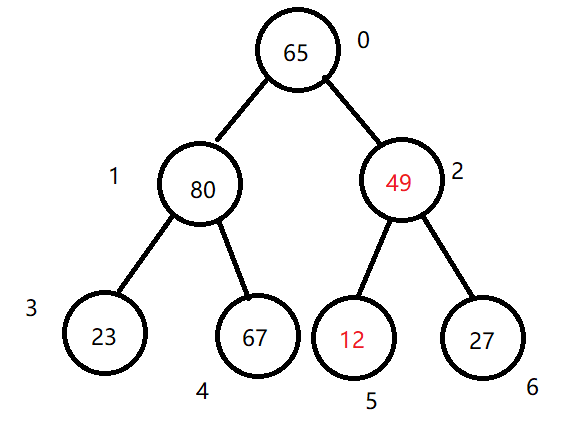
(4)将索引依次减1,按照从右到左、从下到上的顺序逐步构建出大根堆直至根节点。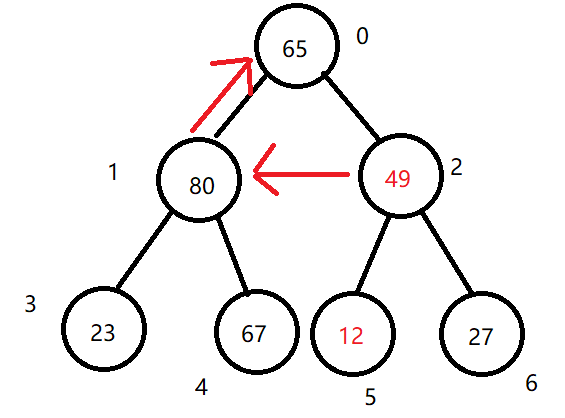
到这一步要注意,从最后一个叶结点的“爷爷结点”(父结点的父结点)开始(此处是arr[0]),如有发生交换的情况,会打乱子树的大根堆结构,所以,arr[0]与子结点arr[1]交换过后,要向下重新排序arr[0]与arr[3]、arr[4]的结构……直至叶节点。
最终结果为:
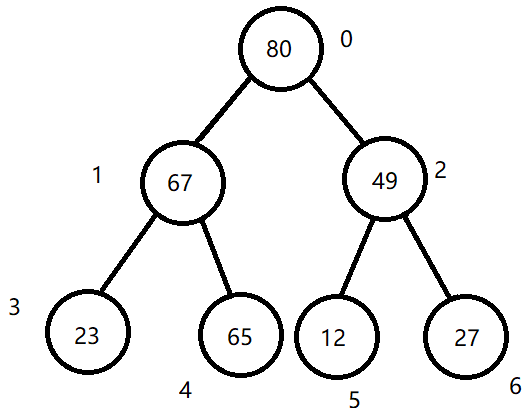
step2:
交换根节点与最后一个叶结点的值,然后将最后一个结点剔除出二叉树结构,不再参与下一次排序。
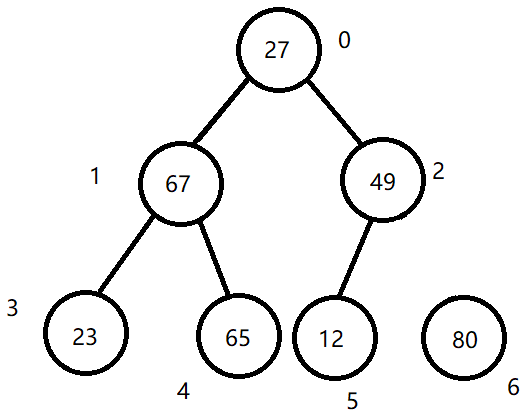
step3:
调整新的二叉树结构。
这时需要再对剩余的二叉树结构进行调整(由于除根结点外,其他结点本就是大根堆结构,所以只需要找到当前根结点的正确位置即可),这时不需要像第一步那样从length/2-1再递减至根结点,而是从根节点开始与子结点进行比较,如果发生交换,则将 索引 移至 发生交换的子结点上,继续进行比较,直至叶结点或不需要发生交换的情况。未发生操作的分支则不需要调整(本身就符合大根堆要求)。
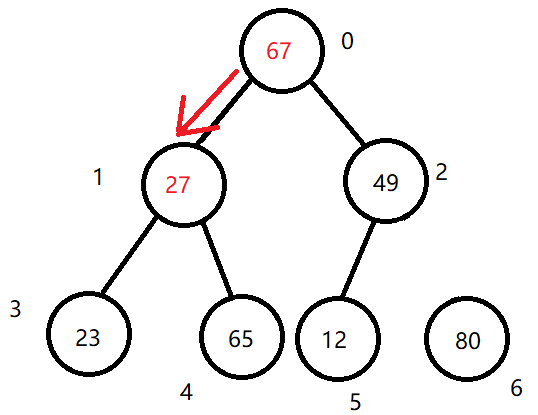
调整结果为:
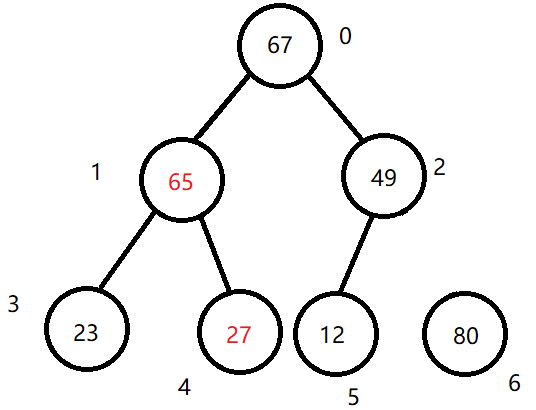
step4:
重复step2、step3,直至二叉树结构中只剩一个结点,至此,排序完成
结果展示:
数组中表示为:[12, 23, 27, 49, 65, 67, 80]
总结
堆排序利用大根堆(小根堆)的特性在时间复杂度为O(logN)的情况下找出最大(最小)的一个数,再逐步缩减优先队列(树结构)的规模,在O(NlogN)的时间复杂度下即可完成对N个数的排序。堆排序在绝大多数情况下都是排序最优解。建议在完成树的学习的前提下,尽快理解并熟练使用堆排序。