目录
一.引言
词嵌入是一种用于将单词映射到实数向量的语言建模技术。它以多个维度表示向量空间中的单词或短语。单词嵌入可以使用各种方法生成,如神经网络、共现矩阵、概率模型等。Word2Vec 由用于生成单词嵌入的模型组成。这些模型是具有一个输入层、一个隐藏层和一个输出层的浅层两层神经网络。前面分享了 Spark 版本大数据场景下的 word2vec 实现方法,这次基于 Python Gensim 库实现 word2vec 的基本操作。
二.Word2vec 简介
1.模型参数
关于完整模型参数,大家可以参考:Gensim Model - Word2vec,这里介绍一些常用参数。
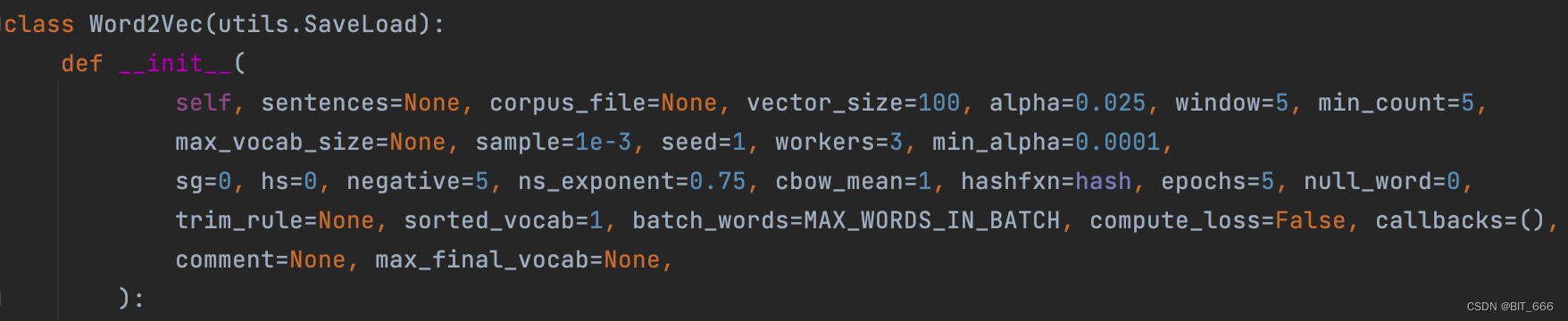
- sentences: 可迭代的语句列表,较大的语料库可以考虑从磁盘/IO的形式传输
- vector_size: 单词向量的维数
- window: 句子中当前单词与预测单词的最大距离
- min_count: 忽略总频率低于此值的所有单词
- workers: 使用多个 worker 线程训练模型
- sg: 训练算法,1-> skip-gram 否则 -> CBOW
- hs: 1 -> 分层 softmax 方法,否则 -> 负采样
- negative: >0 则使用负采样,通常推荐距离为 [5-20],如果设置为0则不适用负采样
- alpha: 初始学习率
- min_alpha: 随着训练进行,学习率将线性下降至 min_alpha
- max_vocab_size: 词库限制,每 1000w 个字类型大约需要1GB的 RAM
- sample: 配置较高频率的单词随机下采样的阈值,生效范围 (0,1e-5)
- epoch: 迭代次数2.Word2vec 网络

Word2vec 的基础模型如上,假设此时词库大小为 10000:
- 输入层
输入 Input 维度为 1x 10000,1 为对应 hit 的单词
- 隐藏层
第二个隐藏层维度为 10000 x K, K 为 emb 维度,此处 K=300,经过隐藏层计算后,输出 [1x10000] x [10000xK] = 1xK = 1x300 的向量,这个 300 就是我们上面设置的 vector_size 参数
- 输出层
输出层维度为 K x 10000,输出后经过 softmax 输出得到最终的概率。此处首先计算 [1 x K] x [K x 10000] = 1 x 10000,所以其实从输入层的 1x10000 到最后的输出层还是 1 x 10000,最终将输出 softmax 处理,得到每个词的概率。
3.Skip-gram 与 CBOW
sg 参数供我们选择使用 Skip-gram 算法和 CBOW 算法,这里简单介绍下两种算法的不同:
- CBOW
多个相邻单词预测一个单词,用一个单词梯度回传多个单词,相当于前向传导多对一,反向传导一对多,这里一般将多个单词在隐藏层得到的 emb 进行求和并取平均的操作,再到输出层继续计算。

- Skip-gram
一个单词预测周围多个单词,用多个梯度回传一个单词,相当于前向传导一对多,反向传导多对一,多个输出词需要更多的矩阵计算和全词库的 softmax,因此训练时间要长于 CBOW,但是由于多个单词可以同时回传一个单词,所以 Skip-gram 训练更充分,一般效果也更好。

4.优化方法
hs 参数可以供我们选择负采样和层次 softmax 方法。不管是 Skip-gram 还是 CBOW 我们都可以发现,如果我们的词库数量 n 过大,最后 softmax 计算概率时计算量都是十分可观的,因此论文中提到了两种优化方法,负采样和层次 Softmax 方法。
4.1 负采样
这个方法很直接,既然我们的 n 太大计算太多,那我们把计算的 n 减少即可,这里并不是直接减少词库规模,而是根据正样本按一定比例选取部分负样本,这样 softmax 计算的 n 就减少了。
4.2 层次 softmax
层次 softmax 基于霍夫曼树生成的词库进行优化,这里直接以一个简单的例子为例,霍夫曼树的构建后面我们抽空写一篇博客:
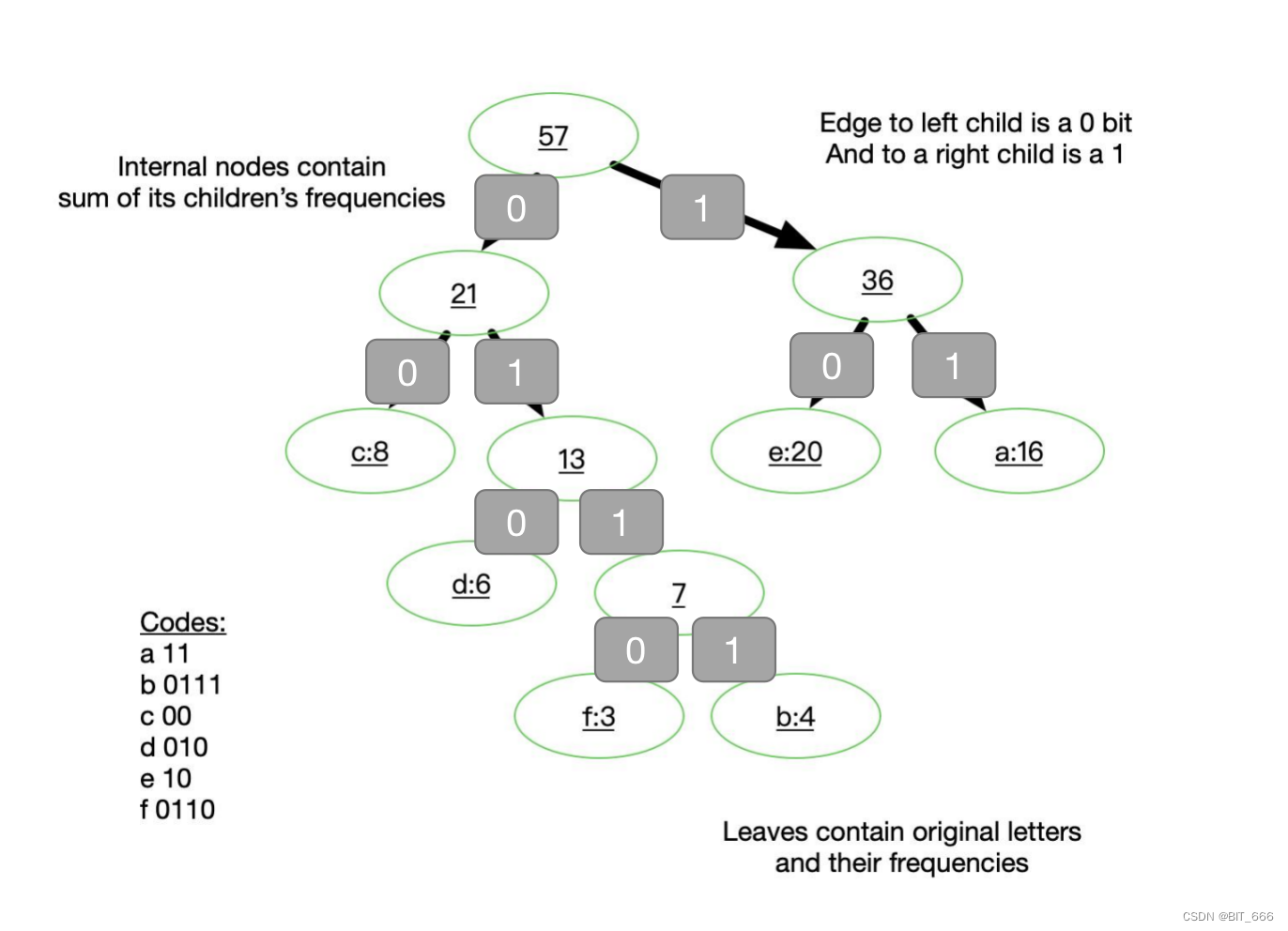
- 单词表示
层次 softmax 利用霍夫曼树的叶子节点表示词库中的每一个词,这里每个叶子节点都有其唯一的路线编号代表其从根节点出发的路径。其中每条路径都对应一个概率,某个词出现的概率的计算方式不再是通过输出层 softmax,而是修改为计算其路径上所有概率的乘积。以 b 为例,从根节点出发,需要 左 -> 右 -> 右 -> 右,所以其编号为 0111。
- 模型结构
输入层和单隐层不变,变化的是输出层,原始方法为计算 n 个数字的 softmax,修改为层次 max 后,每一个节点是一个 K x 1 的向量,经过单隐层输出的向量维度为 1 x K,1 x K 与对应路径每个向量相乘即可得到一个实数 z,代入 sigmoid(z) 得到向左的概率,则向右的概率为 1- sigmoid(z),依次为例,到达 b 的概率为 Predict = sigmod(z1) * (1- sigmoid(z2)) * (1- sigmoid(z3)) * (1- sigmoid(z4))。
- 损失函数
word2vec 目标函数为交叉熵,loss = -Σ Yi * logPi,其中 i 代表单词,而只有目标词的 Yi 为1,其余词的 Yi 为 0,因此 loss = - log P(Predict)。由于 log 函数的引入,因此原始的概率也由多个概率的相乘变成相加 log sigmod(z1) + log (1- sigmoid(z2)) + (1- sigmoid(z3)) + (1- sigmoid(z4))。结合单词的路径表示,我们可以将 0111 看作是 label 向量 label = [0,1,1,1] ,将向量内积概率看作得分向量 Z = [z1,z2,z3,z4] 则 (1-label) * Z + label * (1 - Z) 再分别取 log,当然为了好看也可以把左右概率反一下,就变成 label * Z + (1-label) * (1-Z)。
- 优化方式
上面解释了霍夫曼树路径与单词概率的关系,其中要学习的就是每个中间节点的向量,预测任务中无需关注词带中的 n 个单词并计算 softmax,而是只关注对应单词的路径,例如 b = 0111,这样计算数量由 N 优化至 logN,其次由于霍夫曼树是基于单词词频构建的,因此词频越高路径越短,这也同样优化了高频词的计算程度。
- 碎碎念
下面是 CBOW 和 Skip-Gram 的基础模型结构,但是上面两种优化方式其实与标准模式都有所不同了,所以如果自定义实现还是得稍微修改下,下面我们直接调用 Gensim 实现 word2vec。

三.Word2vec 实战
1.数据预处理
这里我们选择熟悉的 《三国演义》进行 Word2vec 训练,实际场景下需要对文本中的标点符号、异常字符以及停用词去除掉以得到相对干净的数据,这里我们保留字母、数字和空格外其他的所有字符,有需要的同学可以自己加入停用词并更细粒度清理数据。
import jieba
import jieba.analyse
import re
def preHandel(path):
st = time.time()
num = 0
sentences = []
with open(path) as f:
for line in f.readlines():
if line.strip() != "":
# `[^\w\s]` 匹配除了字母、数字和空格之外的所有字符
content = re.sub('[^\w\s]', '', line.strip())
# jieba 分词获取词语序列
content_seq = list(jieba.cut(content))
sentences.append(content_seq)
num += 1
end = time.time()
print("PreHandel End Num:%s Cost:%ss" % (num, (end - st)))
return sentences- 原始文本

执行预处理逻辑:
# 1.数据预处理
path = "./all.txt"
sentences = preHandel(path)- 处理后序列

2.模型训练与预测
from gensim.models import word2vec
from gensim.models import Word2Vec
w2v = word2vec.Word2Vec(sentences, hs=1, sg=1, min_count=1, window=5, vector_size=300, workers=4)根据上面的参数介绍传入参数与分词得到的 sentences 序列即可训练得到 w2v 模型,大家可以根据实际情况调整参数,想要增加单词表达能力就提高 vector_size,想要快速训练就选择 CBOW 并增加 workers 大小。
- 寻找 TopN 相似
def getSimilarSeq(key, model, top=10):
print("Top For %s ======================" % key)
sims = model.wv.most_similar(key, topn=top)
for i in sims:
print(i)
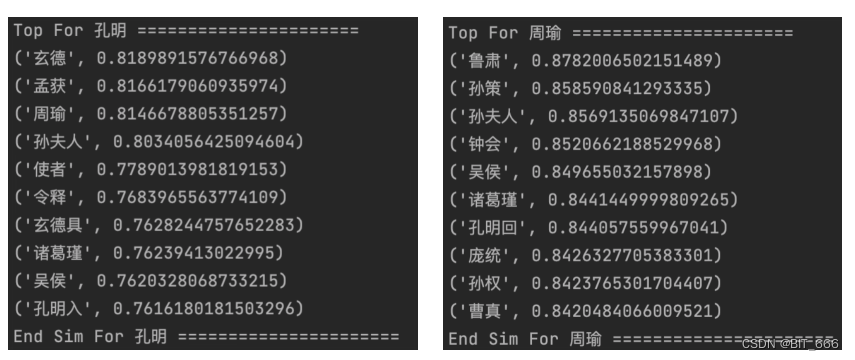
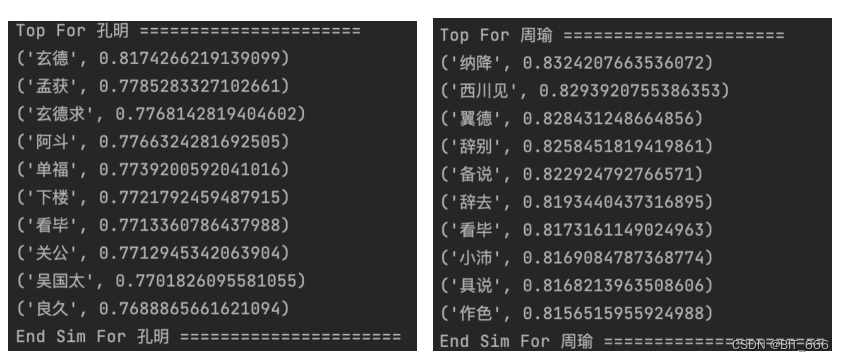
print("End Sim For %s ======================" % key)既生瑜、何生亮,我们找找他们的相似的 Top 10:
getSimilarSeq("孔明", w2v)
getSimilarSeq("周瑜", w2v)效果还不错,而且我们看到孔明和周瑜很像,周瑜和孙夫人很像,所以会发生迁移,猜测孔明和孙夫人很像,这在推荐场景、社交场景或者兴趣迁移时可以提供一些额外的信息。
- 寻找不合群单词
给定多个关键词,找出与其他词最不关联的词
print(w2v.wv.doesnt_match("孔明 张飞 关公 先主 张辽".split()))
这里运行会得到 "张辽",因为前面几位都属于蜀国。
3.模型与向量存取
根据需求不同,存储的内容也会不同,有的同学需要获取训练得到的 emb,有的同学需要获取模型进行相似度预测或者 retrain。如果是前者,我们可以选择单独存储向量,这样可以使用更小的存储且更快的加载使用,反之则使用后者。
- 存储向量
存储后可以用 KededVectors 类进行读取,通过 key 即可获取对应单词向量。
from gensim.models import word2vec, KeyedVectors
word_vectors = w2v.wv
word_vectors.save("./word2vec.wordvectors")
wv = KeyedVectors.load("word2vec.wordvectors", mmap='r')
vector = wv['赵云']
print(vector)- 存储模型
选择存储位置调用 save 方法存储,执行 load 方法即可再次加载。
w2v.save("your_path/w2v.model")
reloadW2V = Word2Vec.load('your_path/w2v.model')- 存储的向量与模型
在对应目录下即可获取自己的模型文件与向量文件,通过对应加载方法即可再次使用。
4.模型 ReTrain 重训
由于原始三国演义文言文偏多,为了提高模型的理解能力,这次博主又找了一版白话文作为样本对原模型进行 ReTrain,先处理数据:
- 原始文本

再次执行相同处理逻辑:
new_sentences = preHandel("./retrain.txt")
- 处理后序列

- 模型重训
重新训练模型只需将刚才存储的模型 load 回来即可,不过需要指定额外的参数,否则会报异常。
from gensim.models import Word2Vec
reloadW2V = Word2Vec.load('your_path/w2v.model')
new_sentences = preHandel("./retrain.txt")
reloadW2V.train(new_sentences, total_examples=reloadW2V.corpus_total_words, epochs=10)
- 效果对比
getSimilarSeq("孔明", reloadW2V)
getSimilarSeq("周瑜", reloadW2V)重训练完感觉还不如最初的版本,还需回炉重铸呀。
5.向量可视化
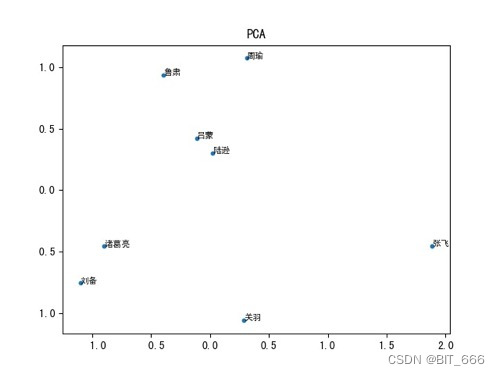
前面介绍 GraphEmbedding 时我们介绍了几种降维方法:向量降维与可视化,下面我们尝试使用 PCA 对部分三国人物的向量可视化:
- PCA 降维
from sklearn.decomposition import PCA
# 数据可视化
key_list = []
emb_list = []
candidate_list = ["诸葛亮", "刘备", "关羽", "张飞", "周瑜", "鲁肃", "吕蒙", "陆逊"]
for k in candidate_list:
emb_list.append(w2v.wv[k])
key_list.append(k)
plt.rcParams['font.sans-serif'] = ['SimHei']
pca = PCA(n_components=2)
compress_emb = pca.fit_transform(np.array(emb_list))
- Plt 标注
candidate_x = [compress_emb[index, 0] for index in range(len(candidate_list))]
candidate_y = [compress_emb[index, 1] for index in range(len(candidate_list))]
plt.scatter(candidate_x, candidate_y, s=10)
for x, y, key in zip(candidate_x, candidate_y, key_list):
plt.text(x, y, key, ha='left', rotation=0, c='black', fontsize=8)
plt.title("PCA")
plt.show()吴国的人物比较聚合,但是刘关张这是桃园三结义了嘛,离这么远!
四.总结
本文从 Wordvec 的模型结构,优化方法以及 Genism 库实践三个方面介绍了 NLP 领域最常见也最易用的模型 Word2vec,除了使用向量进行相似度比较外,训练得到的向量也经常加入 DNN 侧与原模型进行一些列魔改从而提高模型表征能力。
参考:
向量可视化与降维:向量可视化与降维
Word2vec 论文: Efficient Estimation of Word Representations in Vector Space
Gensim 库 API: Gensim Models - Word2vec
三国演义文本: 获取链接与验证码 - s0h2