文章目录
一、前言
当我们要说起word2vec,那就不得不再提word2vec之前说一下关于“文本向量化”这个概率啦。既然算法是拿来用的,不言而喻,您肯定会问用在哪里?这就是我们要提“文本向量化”这个概念的意图奥。首先:文本向量化的方法有很多,从之前的基于统计的方法,到时下流行的基于神经网络的方法,而掌握好word2vec词向量算法和doc2vec文本向量化算法是学习文本向量化的再好不过的方式啦。
那接下来咋们就从文本向量化的概念说起吧,走你、、、、、、
二、 向量化算法word2vec
2.1 引言
词袋(Big of Word)模型是最早的以词语为基本处理单位的文本向量化方法。
词袋的原理:
1、两个简单的文本
- John likes to watch movies, Mary likes too.
- John also likes to watch football games.
2、基于上述两个文档出现的词语,我们来构建词典库:
{“John”:1,“likes”:2,“to”:3,“watch”:4,“movies”:5,“also”:6,“football”:7,“games”:8,“Mary”:9,“too”:10}
3、构建向量
此词典包含10个单词,每个单词有唯一的索引,那么每个文本我们可以使用一个10维的向量来表示。如下所示:
[1,2,1,1,1,0,0,0,1,1]
[1,1,1,1,0,1,1,1,0,0]
4、向量说明
该向量与原来文本中单词出现的顺序没有任何关系,,而是词典中每个单词在文本中出现的频率。
那么关于词袋的问题就来了:
1:维度过大。很显然,如果上述例子词典库包含10000个单词,那么每个文本需要用10000维的向量表示,也就是说除了文本中出现的词语位置不为0,其余9000多的位置均为0,这么高维度的向量严重影响到计算速度。
2:无法保留词序信息。
3:存在语义鸿沟的问题(词序信息发生改变,自然语义也就发生的变化)
所以、根据词袋的不足之处,就引出了word2vec。那么接下来我们就开始对word2vec的学习。
2.2 word2vec原理
1、词向量(word2vec)技术就是为了利用神经网络从大量无标注的文本域中提取有用的信息从而产生的。
2、 word2vec主要解决的问题是,把词典中的词表示成一个词向量(或词嵌入,word embedding,把词嵌入到一个向量空间中),这个向量是低维的、稠密的。通过研究词向量的性质,可以得到词之间的各种性质,如距离、相似性等。好吧,以上感觉解释的太过于精简了,那我们继续往下了解。
简而言之,词向量就是将词转化为稠密向量,并且对于相似的词,其对应的词向量也相近。
根据上述所介绍的“词袋”,它就是将词语符号化,所以词袋模型是不包含任何语义信息的。如何将“词表示”包含语义信息也就是接下来我们首先要介绍的。
2.3 词的表示
在自然语言处理任务中,首先需要考虑词如何在计算机中表示。通常,有两种表示方式:one-hot representation和distribution representation。翻译过来就是:离散表示和分布式表示。
one-hot represention:也就是向量中每一个元素都关联着词库中的一个单词,指定词的向量表示为:其在向量中对应的元素设置为1,其他的元素设置为0(每个词表示为一个长向量。这个向量的维度是词表大小,向量中只有一个维度的值为1,其余维度为0,这个维度就代表了当前的词) 。采用这种表示无法对词向量做比较,后来就出现了分布式表征。
distribution representation:word2vec中就是采用分布式表征,在向量维数比较大的情况下,每一个词都可以用元素的分布式权重来表示,因此,向量的每一维都表示一个特征向量,作用于所有的单词,而不是简单的元素和值之间的一一映射。这种方式抽象的表示了一个词的“意义”。 向量的长度为词典的大小,向量的分量只有一个 1,其他全为 0, 1 的位置对应该词在词典中的位置,例如
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
也正是这些原因,Hinton在 1986 年提出了Distributional Representation,可以克服 one-hot representation的缺点。解决“词汇鸿沟”问题,可以通过计算向量之间的距离(欧式距离、余弦距离等)来体现词与词的相似性 。分布式表示所谓基本想法是直接用一个普通的向量表示一个词,这种向量一般长成这个样子:[0.792, −0.177, −0.107, 0.109, −0.542, …],常见维度50或100。
优点:解决“词汇鸿沟”问题
缺点:训练有难度。没有直接的模型可训练得到。所以采用通过训练语言模型的同时,得到词向量 。
当然一个词怎么表示成这么样的一个向量是要经过一番训练的,训练方法较多,word2vec是其中一种。值得注意的是,每个词在不同的语料库和不同的训练方法下,得到的词向量可能是不一样的。
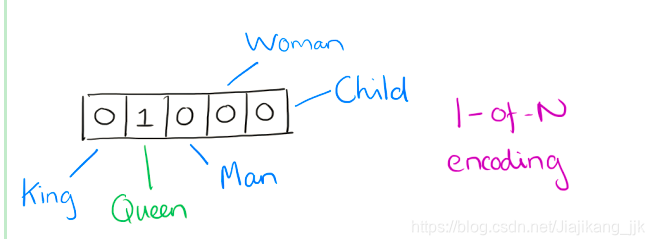
用词向量表示词并不是Word2vec的首创,很久之久就出现了。最早的词向量是很冗长,它使用词向量维度大小为整个词汇表的大小(词袋的原理),对于每个具体的词汇表中的词,将对应的位置置为1。比如我们有下面的5个词组成的词汇表,词"Queen"的序号为2, 那么它的词向量就是(0,1,0,0,0)。词"Woman"的词向量就是(0,0,0,1,0)。这种词向量的编码方式我们一般叫做1-of-N representation或者one hot representation.
Distributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
比如下图我们将词汇表里的词用"Royalty",“Masculinity”, "Femininity"和"Age"4个维度来表示,King这个词对应的词向量可能是(0.99,0.99,0.05,0.7) 。当然在实际情况中,我们并不能对词向量的每个维度做一个很好的解释。
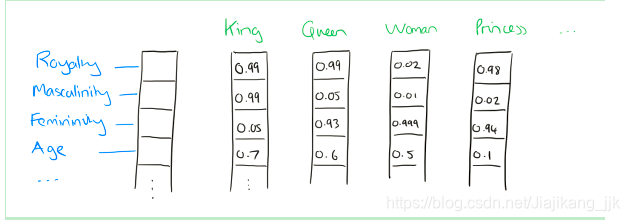
有了用Distributed Representation表示的较短的词向量,我们就可以较容易的分析词之间的关系了.
独白:通过语言模型构建上下文与目标词之间的关系是一种常见的方法。神经网络词向量模型就是根据上下文和目标词之间的关系进行建模。在初期,词向量只是训练神经网络语言模型过程中产生的副产品,而后神经网络语言模型对后期词向量的发展怪好有着决定性的作用。
为了后面能够更好的理解Word2vec,我们先来了解一下神经网络语言模型。
三、神经网络语言模型
神经网络语言模型(Neural Network Language Model,NNLM) ,与传统方法估算
不同,NNLM模型直接通过一个神经网络结构对n元条件概率进行估计(从概率角度出发)。NNLM的基本结构如下所示:
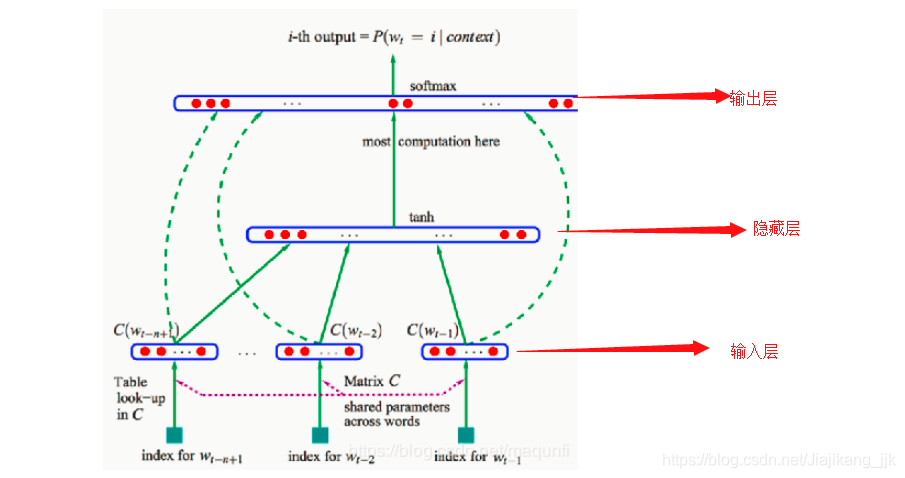
它包含三层:输入层,隐藏层,输出层。大体的操作过程是:
1、从语料库中搜集一系列长度为n的文本序列:
2、假设这些长度为n的文本序列组成的集合为D
3、得到NNLM的目标函数: 意思是:在输入词序列为 的情况下,计算目标词 的概率。
步骤
1、为了解决词袋模型数据稀疏问题,输入层的输入为底维度、紧密的词向量;输入层的操作就是将词序列
中的每个词向量按顺序拼接:
2、拼接完成之后,得到x,将x输入到隐藏层得到h(x—>h),再将h接入到输出层得到最后的输出变量y,其中隐藏层变量h和输出层变量y的计算如下所示:
说明:1、 是输入层到隐藏层的权重矩阵,维度: ;2、 是隐藏层到输出层的权重矩阵,维度: , 表示词表的大小,其他绝对值符号类似;3、 为模型中的偏置顶。
3、NNLM模型中计算量最大的操作就是从隐藏层到输出层的矩阵运算 。输出变量 是一个 维的向量,该向量的每个分量依次对应下一个词为词表中某个词的可能性。用 表示由HHLM模型计算得到的目标词 的输出量,为保证输出 的表示概率值,需要对输出层进行归一化操作。通常会在输出层之后加上一个softmax函数,将 转成对应的概率值:
其中exp(y)是以e为底的指数函数奥。
由于NNLM模型使用低维紧凑的词向量对上文进行表示,这无疑解决了词袋模型带来的数据稀疏,语义鸿沟等问题,显然NNLM模型是一种更好的n元语言模型;另外,在相似的上下文语境中,NNLM模型可以预测处相似的目标词,而传统模型无法做到这一点。
例如,在某语料中 出现了2000次,而 出现了1次。
根据频率计算概率, 自然远远大于 ,而语料 和 唯一的区别在于猫和狗,这两个词无论在语义和语法上都相似,而 远大于 显然是不合理的。如果采用NNLM模型计算则得到的 和 是相似的,原因是:NNLM模型采用低维的向量表示词语,假定相似的词其词向量也应该是相似的。
4、如步骤3中所述,输出的 代表上文出现词序列 的情况下,下一个词为 的概率,因此在语料库 中最大化 便是NNLM模型的目标函数:
一般使用随机梯度下降算法对NNLM模型进行训练。在训练每个batch时,随机从语料库 中抽取若干样本进行训练,梯度迭代公式: ,其中, 是学习率; 是模型中设计的所有参数,包括NNLM模型中的权重,偏置以及输入的词向量。
关于梯度下降算法的学习,可以参考此篇博文。
四、C&W模型
NNLW模型的目标是构建一个语言概率模型,而C&W 则是以生成词向量为目标的模型。
在NNLM模型的求解中,最耗时的部分当属隐藏层到输出层的权重计算。由于C&W模型没有采用语言模型的方式去求解词语上下文的条件概率,而是直接对n元短语打分,这是一种更为快速获取词向量的方式。
C&W模型的核心机理是:如果n元短语在语料库中出现过,那么模型会给该短语打高分;如果是为出现在语料库中的短语则会得到较低的评分。
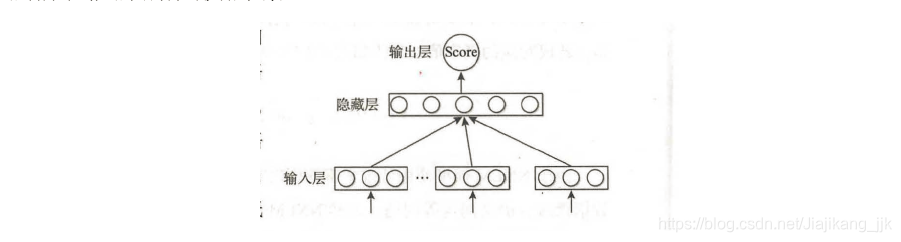
对于整个语料库而言,C&W模型需要优化的目标函数:
说明
1、 为从语料库中抽取出来的n元短语,为了保证上下文词数的一致性, 应为奇数;
2、 是目标词
3、c表示目标词的上下文语境
4、 是从词典中随机抽取的一个词语
5、C&W模型采用成对的词语的方式对目标函数进行优化,
6、公式中可以看出,目标函数期望正样本的得分比负样本至少高一分,其中 表示正样本, 表示负样本。正样本来自语料库,负样本是将正样本序列中的中间词替换成其他词得到的。
一般而言,用一个随机的词语替换正确文本序列的中间词,得到新的文本序列基本上都是不符合语法习惯的错误序列,因此这种构造负样本的方法是合理的。同时由于负样本仅仅是修改了正样本一个词得来的,故其基本的语境没有改变,因此不会对分类效果造成太大影响。
与NNLM模型的目标词在输出层不同,C&W模型输入层就包含了目标词,其输出层也变为一个节点,该节点输出值的大小代表n元短语的打分高低。相应的,C&W模型的最后一层运算次数是
,远低于NNLM模型的
次。综合而言,较NNLM模型而言,C&W模型可大大降低运算量。
到此,C&W模型的理论就学习到这里啦,接下来我们继续学习有关更高效获取词向量的CBOW模型。在学习连续词袋之前,我们不得不先再次复习回顾一下词向量基础:
五、CBOW模型
为了更高效的获取词向量:CBOW(Continuous Bag of-Words)模型是结合了NNLM和C&W模型的核心部分发展而来的语言模型。(CBOW:连续词袋)
5.1 CBOW模型结构图

1、从图中不难看出,CBOW模型就只有两层:输入层,输出层。
2、CBOW模型使用一段文本的中间词作为目标词
3、CBOW模型使用上下文各词的词向量的平均值替代NNLM模型各个拼接的词向量。
4、由于CBOW模型去除了隐藏层,所以其输入层就是语义上下文的表示。
5、CBOW模型对目标词的条件概率计算:
6、CBOW的目标函数与NNLM模型类似,具体为最大化式:
5.2 CBOW的输入输出
CBOW模型的训练输入是某一个特征词的上下文无关的词对应的词向量,而输出就是这个特定的一个词的词向量。
比如下面这段话,我们的上下文大小取值为4,特定的这个词是"Learning",也就是我们需要的输出词向量,上下文对应的词有8个,前后各4个,这8个词是我们模型的输入。由于CBOW使用的是词袋模型,因此这8个词都是平等的,也就是不考虑他们和我们关注的词之间的距离大小,只要在我们上下文之内即可。

这样我们这个CBOW的例子里,我们的输入是8个词向量,输出是所有词的softmax概率(训练的目标是期望训练样本特定词对应的softmax概率最大),对应的CBOW神经网络模型输入层有8个神经元,输出层有词汇表大小个神经元。
隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。这样当我们有新的需求,要求出某8个词对应的最可能的输出中心词时,我们可以通过一次DNN前向传播算法并通过softmax激活函数找到概率最大的词对应的神经元即可
六、Skip-gram模型
在word2vec模型中—skip-gram模型,也是一个比较常用的词向量模型。
6.1 Skip-gram模型结构图

同样,Skip-gram模型也是没有隐藏层,但是和连续词袋模型(CBOW)输入上下文词的平均词向量不同,Skip-gram模型是从目标词w的上下文中选择一个词,将其词向量组成上下文的表示。
Skip-gram和CBOW实际上是word2vec两种不同的思想实现:CBOW的目标是根据上下文来预测当前词语的概率,且上下文所有的词对当前词出现概率的影响的权重是一样的,所以叫做continuous bag-of-words模型。如在袋子中去词,取出数量足够的词就可以了,去除的先后顺序则是无关紧要的。Skip-gram刚好相反,其是根据当前词来预测上下文概率的。
6.2 Skip-gram模型输入输出
1、Skip-gram模型和CBOW的思路是反着来的,即输入是特定一个词的词向量,而输出是特定词对应的上下文词向量。还是上面的例子,我们的上下文大小取值为4, 特定的这个词"Learning"是我们的输入,而这8个上下文词是我们的输出。
2、这样我们这个Skip-Gram的例子里,我们的输入是特定词, 输出是softmax概率排前8的8个词,对应的Skip-Gram神经网络模型输入层有1个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。
3、通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。这样当我们有新的需求,要求出某1个词对应的最可能的8个上下文词时,我们可以通过一次DNN前向传播算法得到概率大小排前8的softmax概率对应的神经元所对应的词即可。
注:既然是反着来的,想着CBOW的输入输出是什么,则skip-gram的输出输入也就是什么啦。
七、向量化算法doc2vec/str2vec
前面我们介绍了word2vec的原理以及生成词向量神经网络模型的常见方法,word2vec基于分布式假说理论可以很好的提取词语的词义信息,因此,利用word2vec技术计算词语间的相似度有非常好的效果。
同样word2vec技术也用于计算句子或者其他长文本间的相似度,其一般做法是对文本分词后,提取关键词,用词向量表示这些关键词,接着对关键词向量求平均或者将其拼接,最后利用词向量计算文本间的相似度。
总结:文本分词—>提取关键词—>词向量表示关键词—>对关键词向量求平均或者将其拼接—>计算相似度
此种方法丢失了文本的语义信息,而恰好文本的语序包含重要信息。例如:“小王送给小红一个苹果”和“小红送给小王一个苹果”,虽然组成两个句子的词语相同,但是表达的信息却是完全不同。为了充分利用文本词序信息,有研究者在word2vec的基础上有提出了文本向量化(doc2vec),又称str2vec和para2vec。
7.1 doc2vec模型
doc2vec技术存在两种模型——Distributed Memory(DM)和Distributed Bag of Words(DBOW),分别对应word2vec技术里的CBOW和Skip-gram模型。
1:DM模型和CBOW模型类似,试图预测给定上下文中某词出现的概率,只不过DM模型的上下文不仅包括上下文单词还包括相应的段落。
2:DBOW模型则在仅给定段落向量的情况下预测段落中一组随机单词的概率,与Skip-gram模型只给定一个词语预测目标词分布类似。
为了更好理解DM模型,咋们先来回顾一下CBOW模型。
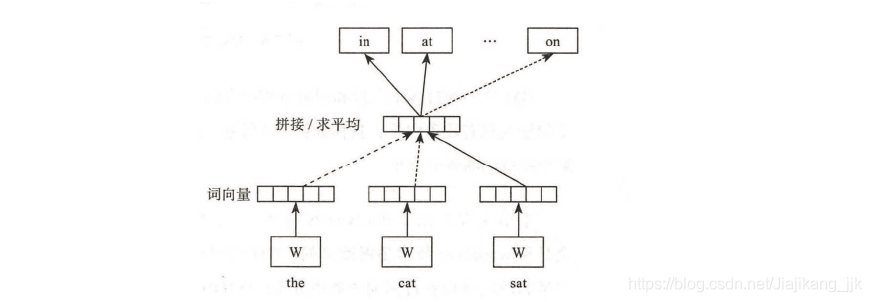
如上图所示的一个利用CBOW模型训练词向量的例子。以“the cat sat”这句话为例,用来构建预测下一个词的概率分布。
首先,用固定长度的不同词向量表示上文的三个词语。
接着,将这三个词向量平均起来组成上文的向量化表示。
最后,将这个上文向量化表示输入CBOW模型预测下一个词的概率分布。
与CBOW模型类似,DM模型增加了一个与词向量长度相等的段向量,也就是说DM模型结合词向量和段向量预测目标词的概率分布。
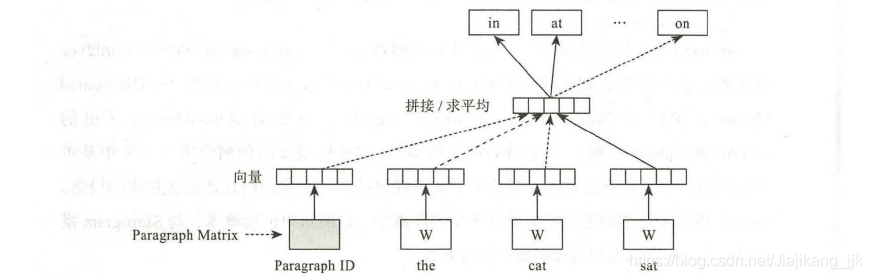
1、如上图所示,在训练的过程中,DM模型增加了一个paragraph ID,和普通的Word2vec一样,paragraph ID也是先映射成一个向量,即paragraph vector。paragraph vector 与word vector的维度虽然一样,但是代表着两个不同的向量空间。
2、在之后的计算里,paragraph vector和word vector 累加或者连接起来,将其输入softmax层。在一个句子或者文档的训练过程中,paragraph ID保持不变,共享这同一个paragraph vector,相当于每次在预测单词的概率时候,都利用了整个句子的语义。
3、在预测阶段,给待预测的句子新分配一个paragraph ID,词向量和输出层softmax的参数保持训练阶段得到的参数不变,重新利用随机梯度下降算法训练待预测的句子。待误差收敛之后,即得到预测句子的paragrap vector。
DM模型通过段落向量和词向量相结合的方式预测目标词的概率分布, 而DBOW模型的输入只有段向量,如下图所示.
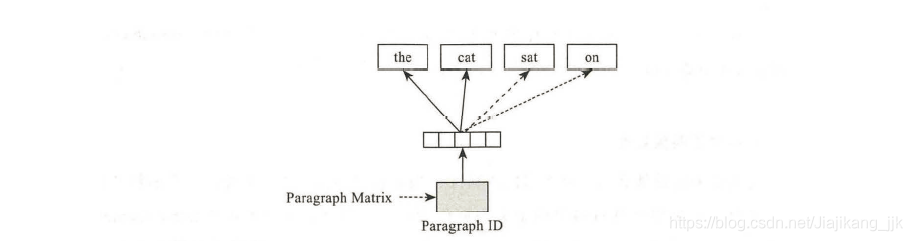
DBOW模型通过一个段落向量预测段落中某个随机词的概率分布。
总结:以上小部分主要介绍了doc2vec的两个模型:DM模型和DBOW模型。由于doc2vec全是从word2vec技术扩展过来的,DM模型和CBOW模型相对应,故可根据上下文词向量和段向量预测目标词的概率分布;DBOW模型和skip-gram模型对应,只输入段向量,预测从段落中随机抽取的词组概率分布。总体来说。doc2vec是word2vec的升级,doc2vec不仅提取了文本的语义信息,而且提取了温饱而语序信息。在一般的文本处理任务中,会将词向量和段向量相结合使用以希望获得更好的效果。
关于第五、六章的理论知识,会继续填补的,暂且就先学习到这里吧!!!
接下来,我们来实际看几个操作案例
八、文本向量化案例
8.1 词向量的训练
8.1.1 说明
windows10
conda 4.6.14
Python 3.6.8 |Anaconda, Inc.| (default, Feb 21 2019, 18:30:04) [MSC v.1916 64 bit (AMD64)] on win32
pycharm
8.1.2 准备工作
在正式开始之前,需要一些准备工作,除了上述一些说明之外,还需要安装gensim库,langconv库。igho
命令安装:pip install gensim

本地安装:pip install 本地文件路径
由于网速的问题,博主就选择本地安装吧,具体安装及结果如下所示:

说明:
1、langconv库:是繁简字体转换的库,gensim
2、Gensim是一款开源的第三方Python工具包,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达。它支持包括TF-IDF,LSA,LDA和word2vec在内的多种主题模型算法,支持流式训练,并提供了诸如相似度计算,信息检索等一些常用任务的API接口。
3、繁简体字使用:将langconv.py,zh_wiki.py放在源码所在目录即可使用
关于繁简体转换说明:
zh_wiki.py和langconv.py这两个文件是放在本地,然后直接来用,而在pycharm自然不会识别所以就会有报错标记,
直接在同目录下:from langconv import * 或者放在创建好的文件夹util下:from util.langconv import * 即可,
我傻吊的,测试都没测试,看到报错就想着如何解决报错了(因为自己觉得没有安装langconv包,所以都不用运行直接思考如何解决报错了,而忽略了本地离线放置的zh_wiki.py和langconv.py文件),
测试源码:
from util.langconv import *
# from langconv import *
def cat_to_chs(sentence): #传入参数为列表
"""
将繁体转换成简体
:param line:
:return:
"""
sentence =",".join(sentence)
sentence = Converter('zh-hans').convert(sentence)
sentence.encode('utf-8')
return sentence.split(",")
def chs_to_cht(sentence):#传入参数为列表
"""
将简体转换成繁体
:param sentence:
:return:
"""
sentence =",".join(sentence)
sentence = Converter('zh-hant').convert(sentence)
sentence.encode('utf-8')
return sentence.split(",")
if __name__ == '__main__':
li_1 = ['鸡', '鸡', '虎', '牛', '猪', '虎', '兔']
li_2 = ['雞', '雞', '虎', '牛', '豬', '虎', '兔']
rest_fon = chs_to_cht(li_1) #简体转换成繁体
# print("简体转换成繁体:{0}".format(rest_fon))
rest_chinese = cat_to_chs(li_2)
print("简体转换成简体:{0}".format(rest_chinese))

8.1.3 前言
统计自然语言处理任务多需要语料数据作为支撑,还不可避免的要对语料进行一定的预处理,因此本小节将对词向量的训练分为两个部分:
- 对中文语料进行处理
- 利用gensim模块训练词向量
8.1.4 中文语料预处理
中文语料库我们就采用的是微机百科里的中文网页作为训练语料库,获取地址:下载链接
维基百科提供的语料是xml格式的,因此需要将其转化为txt格式。由于维基百科中有很多繁体中文网页,所以也需要将这些繁体字转化为简体字。另外,再用语料库训练词向量之前需要对中文句子进行分词,这里我就循规蹈矩的用很成熟的jieba分词吧(关于分词可以浏览博主博客:分词1,分词2
最终处理截图如下所示:


1、源码获取:链接下名为:data_pre_process.py文件
2、转化好的txt格式语料获取:
说明:再将xml格式的语料转化为txt格式的语料的时候,时间会有点长奥。
8.1.5 向量化训练
接下来我们就利用gensim模块训练词向量,word2vec函数中第一个参数是预处理后的训练语料库。sg=0表示使用CBOW模型训练词向量;sg=1表示利用Skip-gram训练词向量。参数size表示词向量的维度。windows表示当前词和预测词可能的最大距离,其中windows越大所需要枚举的预测此越多,计算时间就越长。min_count表示忽略该词语。最后一个workers表示训练词向量时使用的线程数。
最终训练的结果如下所示:


源码获取:此链接下word2vec_training.py文件
8.1.6 测试
接下来我们就测试一波
import gensim
def my_function():
model = gensim.models.Word2Vec.load('./yuliao/zhiwiki_news.word2vec')# 加载训练好的模型
print(model.similarity('西红柿','番茄'))# 0.
print(model.similarity('西红柿','香蕉'))#
#print(model.similarity('人工智能','机器学习'))
#print(model.similarity('滴滴','共享单车'))
word = '中国'
if word in model.wv.index2word:
print(model.most_similar(word))# 如果word包含在模型中,则输出最相似的词
if __name__ == '__main__':
my_function()# 调用函数

到了这里关于词向量的基本语料处理,模型训练以及测试就结束了,接下来我们再来了解一下段落向量的训练。
8.2 段落向量的训练
上一小节介绍了关于词向量的训练方法,接下来将介绍段落向量的训练方法。与训练词向量类似,段落向量的训练分为训练数据预处理和段落向量训练两个步骤。
1、通过定义TaggerdWikiDocument来预处理数据,所不同的是这里不再是将每个文档进行分词,而是直接将转化后的简单文本保留。
2、doc2vec在训练时候能够采用tag信息来更好的辅助训练(表明是同一类doc),因此相对word2vec模型,输入文档多了一个tag属性。
docs:表示用于训练的语料文章
size:代表段落向量的维度
widow:表示当前词和预测此可能的最大距离
min_count:表示最小出现的次数
workers:表示训练词向量时使用的线程数
dm:表示训练时使用的模型种类,一般dm=1,这时默认使用DM模型;当dm=其他值时,使用DBOW模型训练词向量
说明:为了以防万一,博主就使用了学生价位的那种类型的阿里云Centos7.3系统来跑,具体如图所示:

到了此处:你就会深切感受到硬件设备的重要性呀。
源码获取:此链接下的doc2vec_traing_models.py文件
接下来就到了测试的地步了~~~
8.3 word2vec和doc2vec计算网页相似度
前面我们已经利用gensim模块训练词向量和段落向量了,接下来将利用训练好的词向量和段落向量针对一些文章进行向量化,并计算此文章的相似度。
word2vec计算网页相似度的基本方法:抽取测试语料中的关键词,接着将关键词进行向量化,然后将得到的各个词向量相加,最后得到的一个词向量总和和代表测试语料的向量化表示,利用这个总的向量计算网页相似度。具体步骤是:1:提取关键词;2:关键词向量化;3:相似度计算
8.3.1 word2vec计算网页相似度
8.3.1.1 关键词提取源码
"""
author:jjk
datetime:2019/9/23
coding:utf-8
project name:Pycharm_workstation
Program function: 关键字提取
"""
import jieba.posseg as pseg
from jieba import analyse
def keyword_extract(data,file_name): # 提取关键字
tfidf = analyse.extract_tags
keywords = tfidf(data)
return keywords
def getKeywords(docpath,savepath):
with open(docpath,'r',encoding='utf-8') as docf, open(savepath,'w',encoding='utf-8') as outf:
for data in docf:
data = data[:len(data)-1]
keywords = keyword_extract(data,savepath)
for word in keywords:
outf.write(word+' ') # 写入
outf.write('\n') # 换行
if __name__ == '__main__':
getKeywords('../yuliao/P1.txt','../yuliao/P1_keywords.txt')

源码获取:此链接下的keyword_extract.py文件
8.3.1.2 关键词向量化和相似度计算
"""
author:jjk
datetime:2019/9/25
coding:utf-8
project name:Pycharm_workstation
Program function: 利用词向量word2vec计算文本相似度
"""
# -*- coding: utf-8 -*-
import codecs
import numpy
import gensim
import numpy as np
# from keyword_extract import *
wordvec_size = 192
def get_char_pos(string, char):
chPos = []
try:
chPos = list(((pos) for pos, val in enumerate(string) if (val == char)))
except:
pass
return chPos
def word2vec(file_name, model):
#with codecs.open(file_name, 'r') as f:
with open(file_name,'rb',encoding='utf-8') as f:
word_vec_all = numpy.zeros(wordvec_size)
for data in f:
space_pos = get_char_pos(data, ' ')
first_word = data[0:space_pos[0]]
if model.__contains__(first_word):
word_vec_all = word_vec_all + model[first_word]
for i in range(len(space_pos) - 1):
word = data[space_pos[i]:space_pos[i + 1]]
if model.__contains__(word):
word_vec_all = word_vec_all + model[word]
return word_vec_all
def simlarityCalu(vector1, vector2): # 使用余弦函数计算两个向量的相似度
vector1Mod = np.sqrt(vector1.dot(vector1))
vector2Mod = np.sqrt(vector2.dot(vector2))
if vector2Mod != 0 and vector1Mod != 0:
simlarity = (vector1.dot(vector2)) / (vector1Mod * vector2Mod)
else:
simlarity = 0
return simlarity
if __name__ == '__main__':
model = gensim.models.Word2Vec.load('zhiwiki_news.word2vec') # 此处就用使用提前训练好的语料啦
#p1 = './data/P1.txt'
#p2 = './data/P2.txt'
p1_keywords = 'P1_keywords.txt'
p2_keywords = 'P2_keywords.txt'
#getKeywords(p1, p1_keywords)
#getKeywords(p2, p2_keywords)
p1_vec = word2vec(p1_keywords, model)
p2_vec = word2vec(p2_keywords, model)
print(simlarityCalu(p1_vec, p2_vec))
说明:此处就要用计算网页相似度训练好的语料了,由于博主硬件设备资源简陋,还没训练出来,再次就不给出结果信息了。
源码获取:此链接下doc2vec_traing_model.py文件
8.3.2 doc2vec计算网页相似度
使用段向量计算网页相似度主要包括:1:预处理;2:文档向量化;3:计算文本相似
"""
author:jjk
datetime:2019/9/25
coding:utf-8
project name:Pycharm_workstation
Program function: 使用段向量计算网页相似度
"""
import gensim.models as g
import codecs
import numpy
import numpy as np
model_path = 'zhiwiki_news.doc2vec'
start_alpha = 0.01
infer_epoch = 1000
docvec_size = 192 # 段落向量的维度
def simlarityCalu(vector1, vector2): # 采用余弦函数计算文本相似度
vector1Mod = np.sqrt(vector1.dot(vector1))
vector2Mod = np.sqrt(vector2.dot(vector2))
if vector2Mod != 0 and vector1Mod != 0:
simlarity = (vector1.dot(vector2)) / (vector1Mod * vector2Mod)
else:
simlarity = 0
return simlarity
def doc2vec(file_name, model):
import jieba
doc = [w for x in codecs.open(file_name, 'r', 'utf-8').readlines() for w in jieba.cut(x.strip())] # 分词
doc_vec_all = model.infer_vector(doc, alpha=start_alpha, steps=infer_epoch) # 句子向量化操作
return doc_vec_all
if __name__ == '__main__':
model = g.Doc2Vec.load(model_path) # 加载模型路径
p1 = './data/P1.txt'
p2 = './data/P2.txt'
P1_doc2vec = doc2vec(p1, model) # 获取文本向量化
P2_doc2vec = doc2vec(p2, model)
print(simlarityCalu(P1_doc2vec, P2_doc2vec))
源码获取:此链接下doc2vec_test_sim.py文件
在训练模式的时候,才深切的感受到硬件设备的重要性,到此,关于word2vec和doc2vec的基本概念和原理以及简单的实现就算完了,word2vec是word embedding最常用的方法,而doc2vec则是基于word2vec发展而来的。它们经常被用来丰富的各种NLP任务的输入,例如在文本分类或者机器翻译中,将输入的文本进行向量化操作后,一般都能取得更好的效果。
