词向量的表示方法有很多中,比如用语料库、one-hot、词典、bag of words、TF-IDF、n-gram等等,这些都可以将一个词表示成词向量,但是它们有一个问题就是它们只是单纯的把词用向量表示出来,但没有利用到词和词之间的关系,比如猫用[0,0,1,...,0]狗用[0,1,....0]表示,没有注意到猫和狗之间的关系它们都是动物,所以我现在看一下能从其他周围的向量根据关系来预测向量的模型。
一:用一个词附近的其他词来表示该词是核心,怎么表示的呢?就是根据向量的关系,前面的几种方法很明显不好用。
共现矩阵:这是一个对角矩阵,用它的一行或者一列来作为词向量的表示,但是缺点就是向量维数随着词典大小线性增长,存储空间比较大,并且一些文本分类模型会面临稀疏性,在往词典中加入新的词时很难处理,模型可能会欠拟合。
当共现矩阵的维度很高且稀疏时,我们要想办法将其进行降维处理成低维稠密向量,用到了svd,svd很简单不说了,调用numpy库中的函数实现即可,
二:NNLM
NNLM直接从语言模型出发,将模型最优化的过程转化为词向量的表示过程。
三:Continuous Bag of words model(CBOW)
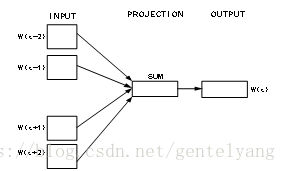
分别为输入层(input),映射层(projection)和输出层(output);输入层为词W(t)周围的n-1个单词的词向量,如果n取5,则词W(t)的前两个词为W(t-2),W(t-1),后两个词为W(t+1),W(t+2),它们对应的向量记为V(W(t-2)),V(W(t-1)),V(W(t+1)),V(W(t+2)),从输入层到映射层即将4个词的向量形式相加,而从映射层到输出层需构造Huffman树,从根节点开始,映射层的值沿着Huffman树进行logistic分类,并不断修正各中间向量与词向量,得到词W(t)所对应的词向量V(W(t))。
这里给出将映射层和输出层构造Huffman树的过程。
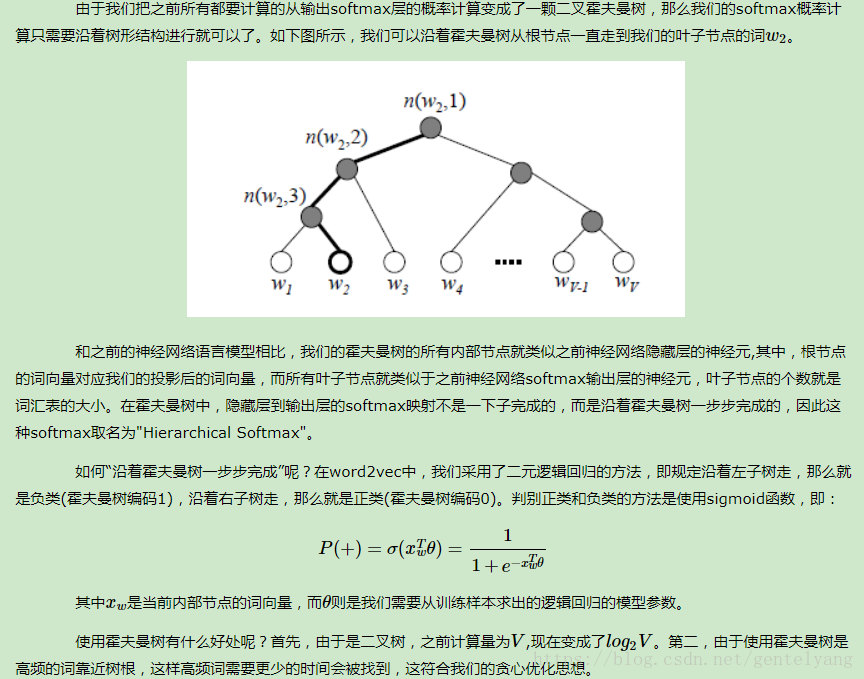

此时中间的单词为w(t),而映射层输入为
pro(t)=v(w(t-2))+v(w(t-1))+v(w(t+1))+v(w(t+2))假设此时的单词为“足球”,即w(t)=“足球”,则其Huffman码可知为d(t)=”1001”(具体可见上一节),那么根据Huffman码可知,从根节点到叶节点的路径为“左右右左”,即从根节点开始,先往左拐,再往右拐2次,最后再左拐。
既然知道了路径,那么就按照路径从上往下依次修正路径上各节点的中间向量。在第一个节点,根据节点的中间向量Θ(t,1)和pro(t)进行Logistic分类。如果分类结果显示为0,则表示分类错误(应该向左拐,即分类到1),则要对Θ(t,1)进行修正,并记录误差量。
接下来,处理完第一个节点之后,开始处理第二个节点。方法类似,修正Θ(t,2),并累加误差量。接下来的节点都以此类推。
在处理完所有节点,达到叶节点之后,根据之前累计的误差来修正词向量v(w(t))。
这样,一个词w(t)的处理流程就结束了。如果一个文本中有N个词,则需要将上述过程在重复N遍,从w(0)~w(N-1)。
四:skip-gram model
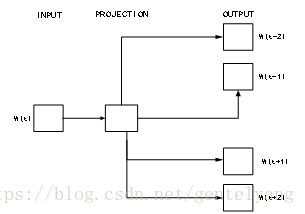
Skip-gram模型与CBOW刚好相反,如图所示,Skip-gram的输入是当前词W(t)的向量形式,输出是周围词的向量形式,通过当前词来预测周围的词,如果上下文窗口大小设置为4,以知中间词W(t)所对应的向量形式为V(W(t)),利用V(W(t))来预测周围4个词所对应的词向量中某个词的词向量的概率,令Context(w)={V(W(t+2)),V(W(t+1)),V(W(t-1)),V(W(t-2))}
,Skip-gram模型计算周围词向量是利用中间词向量V(W(t))的条件概率值来求解的,公式如下:
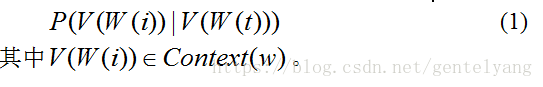
五:转化为词向量后就可以计算余弦相似度,余弦相似度越大,词语之间的相似性越强,反之越小;
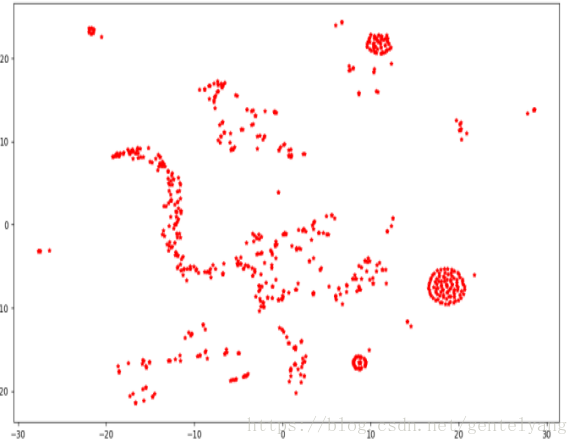
六:因为利用word2vec已经转化为了低维稠密的实数向量,所以可以将其可视化,利用TSNE,下面是我对1000个词所对应的词向量的可视化结果图;