学习自此处
致谢李沐大神!
0、Word2vec
它将每个词表示成一个定长的向量,并使得这些向量能较好地表达不同词之间的相似和类比关系。Word2vec 工具包含了两个模型:跳字模型(skip-gram)和连续词袋模型(continuous bag of words,简称 CBOW),此外还有两种训练方法,分别为负采样和层次softmax。
1、skip-gram
跳字模型假设基于某个词来生成它在文本序列周围的词。举个例子,假设文本序列是“the”、“man”、“loves”、“his”和“son”。以“loves”作为中心词,设背景窗口大小为 2。跳字模型所关心的是,给定中心词“loves”,生成与它距离不超过 2 个词的背景词“the”、“man”、“his”和“son”的条件概率,即
假设给定中心词的情况下,背景词的生成是相互独立的,那么上式可以改写成:

skip-gram训练:
跳字模型的参数是每个词所对应的中心词向量和背景词向量。训练中我们通过最大化似然函数来学习模型参数,即最大似然估计。
最大似然估计是将文本序列中的所有条件概率连乘,然后求使该乘积最大化的参数。
这等价于最小化以下损失函数:
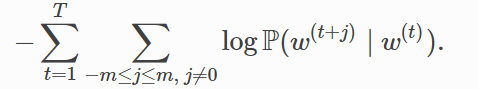
如果使用随机梯度下降,那么在每一次迭代里我们随机采样一个较短的子序列来计算有关该子序列的损失,然后计算梯度来更新模型参数。梯度计算的关键是对数条件概率有关中心词向量和背景词向量的梯度。根据定义,首先看到:
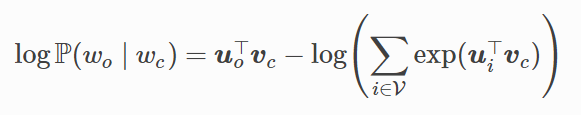
通过微分,我们可以得到上式中中心词向量Vc的梯度:
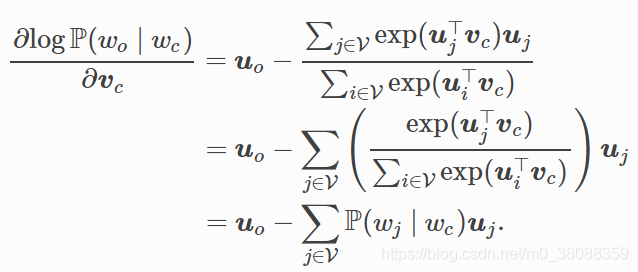

2、连续词袋模型(CBOW)
连续词袋模型与跳字模型类似。与跳字模型最大的不同在于,连续词袋模型假设基于某中心词在文本序列前后的背景词来生成该中心词。在同样的文本序列“the”、 “man”、“loves”、“his”和“son”里,以“loves”作为中心词,且背景窗口大小为 2 时,连续词袋模型关心的是,给定背景词“the”、“man”、“his”和“son”生成中心词“loves”的条件概率:

注意以上的窗口大小为m!

CBOW训练:
连续词袋模型训练同跳字模型训练基本一致。连续词袋模型的最大似然估计等价于最小化损失函数:
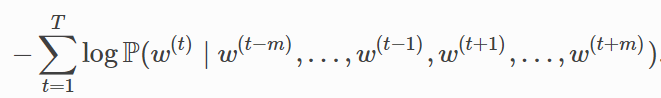
其中:
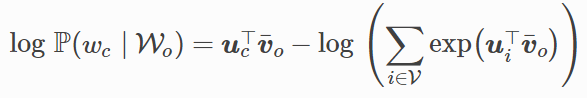
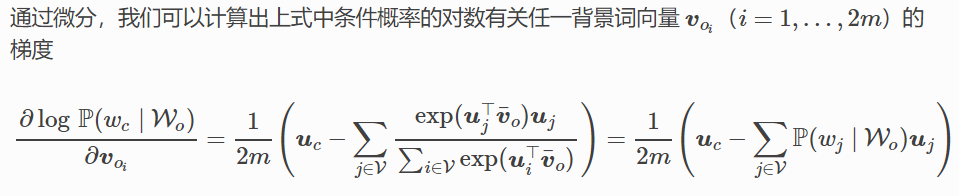
有关其他词向量的梯度同理可得。同跳字模型不一样的一点在于,我们一般使用连续词袋模型的背景词向量求平均作为词的表征向量。
综上,发现用softmax做条件概率计算,每一步的梯度计算都包含词典大小V数目的项的累加。对于含几十万或上百万词的较大词典,每次的梯度计算开销可能过大。也即计算复杂度为O(|V|),如此训练显然有些不友好。
所以延伸了以下的两个近似训练方法:负采样(negative sampling)或层序 softmax(hierarchical softmax),使得计算复杂度降低,减少时间开销。
3、negative sampling
以skip-gram为例:



可以发现对数损失中的每一项的复杂度不再是与词典大小V线性相关,而是噪声词的数量大小K线性相关,当K取值较小时(不能为负),负采样在每一步的梯度计算开销较小。
补充:
噪声词概率P(w)在实际中被建议设为w的单字概率的3/4次方。原因是这样可以使生僻词更容易被采样。
要表示一个短语的向量,原论文里是直接将组成该短语的单词的向量线性相加。当然实际工程中也可以对这些单词求平均。
4、层次softmax
层序 softmax 是另一种近似训练法。它使用了二叉树这一数据结构,树的每个叶子节点代表着词典 V 中的每个词。所以第一步我们需要先构建霍夫曼树,霍夫曼树的构建依赖的是词频统计,然后按照霍夫曼树的规则建立起来,树的每个节点表示词典每个词。规定左子树[x]=1,右子树[x]=−1。
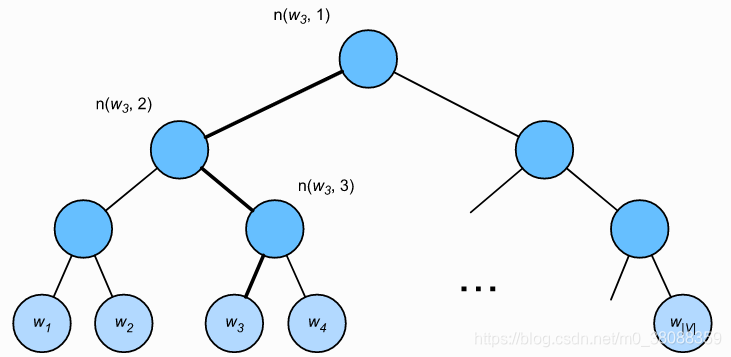

5、小结
(1)负采样通过考虑同时含有正类样本和负类样本的相互独立事件来构造损失函数。其训练中每一步的梯度计算开销与采样的噪音词的个数线性相关。
(2)层序 softmax 使用了二叉树,并根据根节点到叶子节点的路径来构造损失函数。其训练中每一步的梯度计算开销与词典大小的对数相关。
(3)在使用softmax的跳字模型和连续词袋模型中,词向量和二叉树中非叶子节点向量是需要学习的模型参数。
(4)层序softmax已经通过Huffman编码唯一的确定了所有遍历路径。