论文:Focal Loss for Dense Object Detection
论文papar地址:ICCV 2017 Open Access Repository
在各个主流深度学习框架里基本都有实现,本文会以mmcv里的focal loss实现为例(基于pytorch)
简介:
本文是何恺明团队ICCV 2017的一篇文章,主要针对检测场景类别不均衡导致一阶段算法没有二阶段算法精度高,在CE loss的基础上进行改进,提出了Focal Loss,并且本文改动了faster rcnn,魔改成了一个一阶段的算法RetinaNet,也是后续很多工作拿来当baseline的anchor-based一阶段算法。
动机是作者认为,一阶段和二阶段算法的精度差距,主要原因是一阶段基本都是dense detect(指采样的区域很密集,简而言之就是anchor box/proposal很多),而二阶段的算法是精选出高质量的样本(比如RPN、selective search),在二阶段产生相对较少的ROI进行回归和分类预测。一阶段产生那么多anchor ,但是其中只有一小部分变成最后预测的bbox result,因此会有很多易分类的负样本在loss function里占很大的比重,就会不利于训练。也就是说Focal Loss的贡献就是缓解了类别不平衡问题(注意:这里的类别不平衡不单单是指正负样本数量的不平衡,还有难易样本数量的不平衡)。
Focal Loss具体原理
修改是基于CE loss的(因此focal loss是分类的loss,当然也用于检测框的分类,只是跟回归无关),首先为正样本加入权重因子α,这样的操作一般叫Balanced Cross Entropy,为了解决正负样本不平衡对损失函数造成的影响。
最原本的CE loss(cross entroy loss交叉熵损失函数)形式如下:

为了解决正负样本不平衡问题(负样本太多,正样本太少),一个nature的思路就是给正负样本添加权重alpha,用来减小负样本的占比影响,
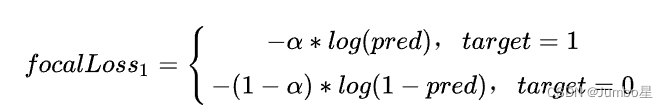
显然alpha越大,正样本的loss占比越大!即α设置的越大,负样本对loss的影响越小。这样就解决了正负样本数量不平衡对最后整个loss函数造成的影响。
下面解决难易样本数量不平衡:在训练时,易分样本数量远大于难分样本数量,易分样本指的是:target为正样本,且pred得分(检测框的score)高,即易分正样本;target为负样本,且pred得分低,即易分负样本。
为此我们再引入一个权重gamma,用来减小易分样本的占比影响
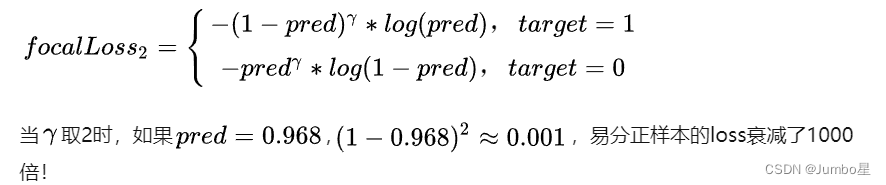
至此,只需要组合上面的α和γ,就得到了Focal Loss的最终形式:
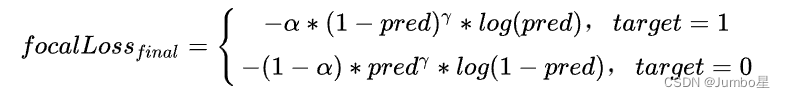
这种分类loss既能够缓解正负样本数量不均衡的问题,也能缓解难易样本数量不均衡问题,只引入了两个超参数。
值得一提的是,作者在原文中通过实验证明,在COCO数据集上,α取0.25,γ取2的组合精度最高。
RetinaNet
因为这篇文章里提出了一个比较著名的网络RetinaNet,因此顺便也介绍下。
RetinaNet是一个一阶段的网络,由一个主干网络和两个特定于任务(目标检测)的两个子网络(其实就是一个分类头+一个回归头)。

作者用这个很简单的retinanet当做一个一阶段算法的baseline,通过在上面用focal loss超越了二阶段的faster rcnn精度,同时又保留了一阶段的高效率。以此来证明一阶段和二阶段的算法精度差距确实就在于作者提出的类别不平衡猜想。
mmcv中focal loss实现源码和调参
这里首先提示一句,一般看到的二阶段算法的cls_loss都是最基础的CE loss,因为二阶段已经有成熟的RPN,因此生成的anchor或者说proposal的类别不均衡问题不严重,因此没必要用focal loss。
这里就以mmdet里的focal loss实现为例,源码位置在mmdet\models\losses\focal_loss.py
class FocalLoss(nn.Module):
def __init__(self,
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
reduction='mean',
loss_weight=1.0,
activated=False):
"""`Focal Loss <https://arxiv.org/abs/1708.02002>`_
Args:
use_sigmoid (bool, optional): Whether to the prediction is
used for sigmoid or softmax. Defaults to True.
gamma (float, optional): The gamma for calculating the modulating
factor. Defaults to 2.0.
alpha (float, optional): A balanced form for Focal Loss.
Defaults to 0.25.
reduction (str, optional): The method used to reduce the loss into
a scalar. Defaults to 'mean'. Options are "none", "mean" and
"sum".
loss_weight (float, optional): Weight of loss. Defaults to 1.0.
activated (bool, optional): Whether the input is activated.
If True, it means the input has been activated and can be
treated as probabilities. Else, it should be treated as logits.
Defaults to False.
"""
super(FocalLoss, self).__init__()
assert use_sigmoid is True, 'Only sigmoid focal loss supported now.'
self.use_sigmoid = use_sigmoid
self.gamma = gamma
self.alpha = alpha
self.reduction = reduction
self.loss_weight = loss_weight
self.activated = activated
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None):
"""Forward function.
Args:
pred (torch.Tensor): The prediction.
target (torch.Tensor): The learning label of the prediction.
weight (torch.Tensor, optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Options are "none", "mean" and "sum".
Returns:
torch.Tensor: The calculated loss
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
if self.use_sigmoid:
if self.activated:
calculate_loss_func = py_focal_loss_with_prob
else:
if torch.cuda.is_available() and pred.is_cuda:
calculate_loss_func = sigmoid_focal_loss
else:
num_classes = pred.size(1)
target = F.one_hot(target, num_classes=num_classes + 1)
target = target[:, :num_classes]
calculate_loss_func = py_sigmoid_focal_loss
loss_cls = self.loss_weight * calculate_loss_func(
pred,
target,
weight,
gamma=self.gamma,
alpha=self.alpha,
reduction=reduction,
avg_factor=avg_factor)
else:
raise NotImplementedError
return loss_cls可以看到只需要在init这个loss的时候赋予gamma和alpha就可以,比如我改变我的htc算法config里的
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
改成
loss_cls=dict(
type='FocalLoss),
即可,用的alpha和gamma都是论文里默认的“最优决策”:α=0.25,γ=2.0
当然这两个超参数要根据你实际的数据集和任务场景调整。