文章目录
一:创新点
YOLOv5/YOLOX 使用的 Backbone 和 Neck 都基于 CSPNet 搭建,采用了多分支的方式和残差结构。对于 GPU 等硬件来说,这种结构会一定程度上增加延时,同时减小内存带宽利用率。因此,YOLOv6对Backbone 和 Neck 都进行了重新设计,Head层沿用了YOLO_x中的Decoupled Head并稍作修改。相当于YOLO_v5而言,v6对网络模型结构进行了大量的更改。
除了网络结构上的改进,作者还对训练策略进行了改进,应用了Anchor-free 无锚范式、SimOTA标签分配策略、SIOU边界框回归损失。
下面我将从不同角度对YOLO_v6进行详细讲解。
二:Backbone
首先,我附上根据源码亲手绘制的backbone流程图:
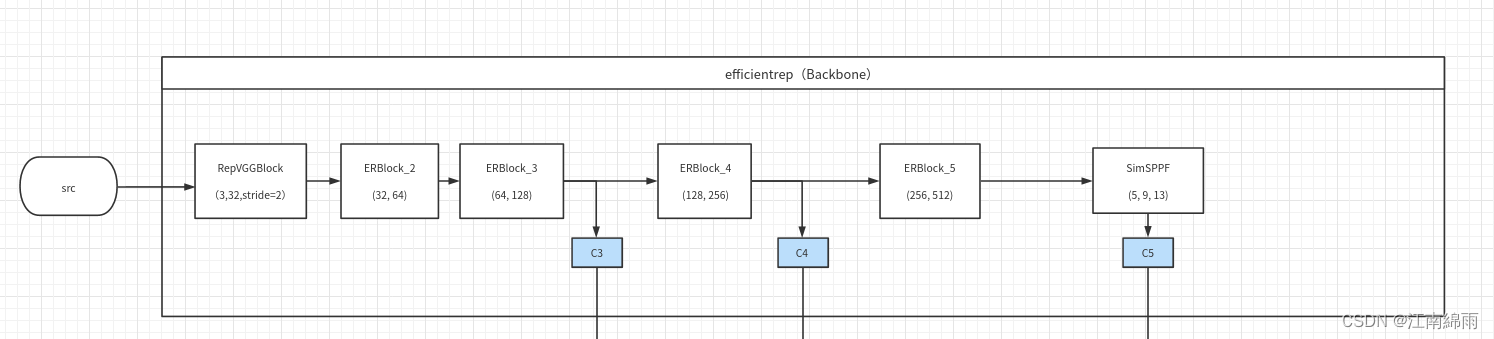
不难发现,Block中都由“Rep”的字样,这也是YOLO_v6的重点——RepVGG style结构。
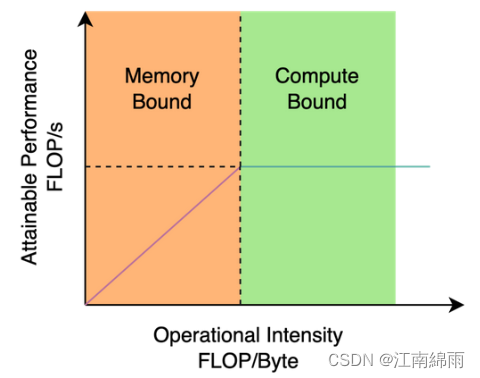
上一大节中提到了YOLOv5/YOLOX使用的CSPNet架构,对GPU等硬件利用率并不高,作者通过对计算机体系结构领域研究后发现,RepVGG style结构对硬件计算能力、内存带宽、编译优化特性、网络表征能力等更加友好,内部原理可见下图:
下面看看RepVGG style结构:
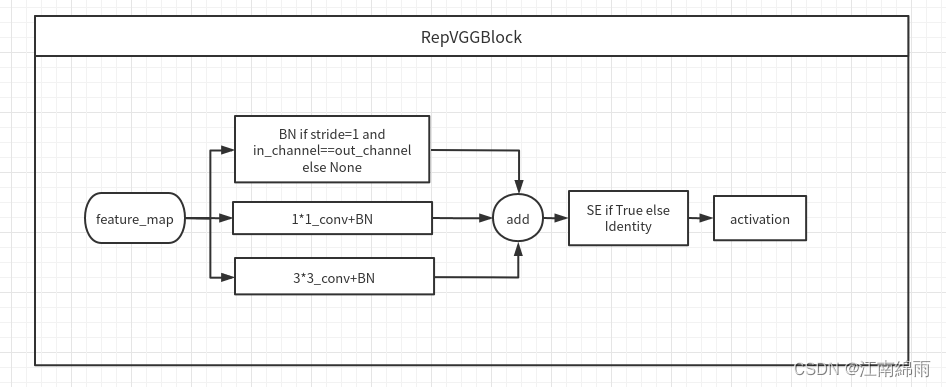
其实就是融合了Inception和残差连接的感觉,里面的SE模块源码中好像并不支持使用,也不知道那为什么还要提出来。。。后面的RepBlock和ERBlock也都是基于RepVGGBlock的,看下图:
 注意!!!RepVGG Style 结构是一种在训练时具有多分支拓扑,而在实际部署时可以等效融合为单个 3x3 卷积的一种可重参数化的结构。通过融合成的 3x3 卷积结构,可以有效利用计算密集型硬件计算能力(比如 GPU),同时也可获得 GPU/CPU 上已经高度优化的 NVIDIA cuDNN 和 Intel MKL 编译框架的帮助。融合过程如下图所示:
注意!!!RepVGG Style 结构是一种在训练时具有多分支拓扑,而在实际部署时可以等效融合为单个 3x3 卷积的一种可重参数化的结构。通过融合成的 3x3 卷积结构,可以有效利用计算密集型硬件计算能力(比如 GPU),同时也可获得 GPU/CPU 上已经高度优化的 NVIDIA cuDNN 和 Intel MKL 编译框架的帮助。融合过程如下图所示:
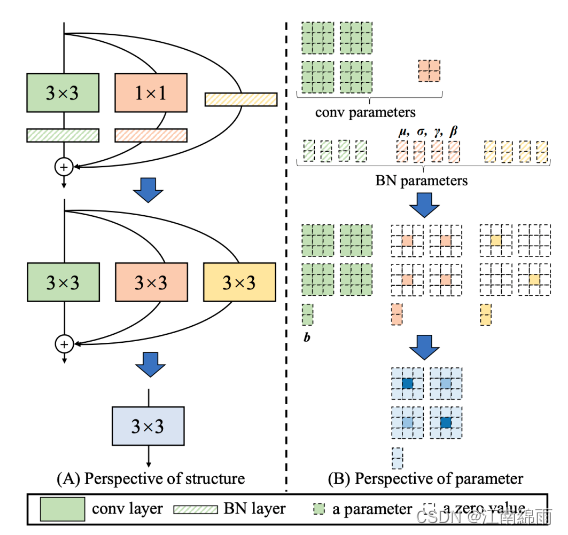
三:RepPANNeck
话不多说,附上亲手绘制的Neck流程图:
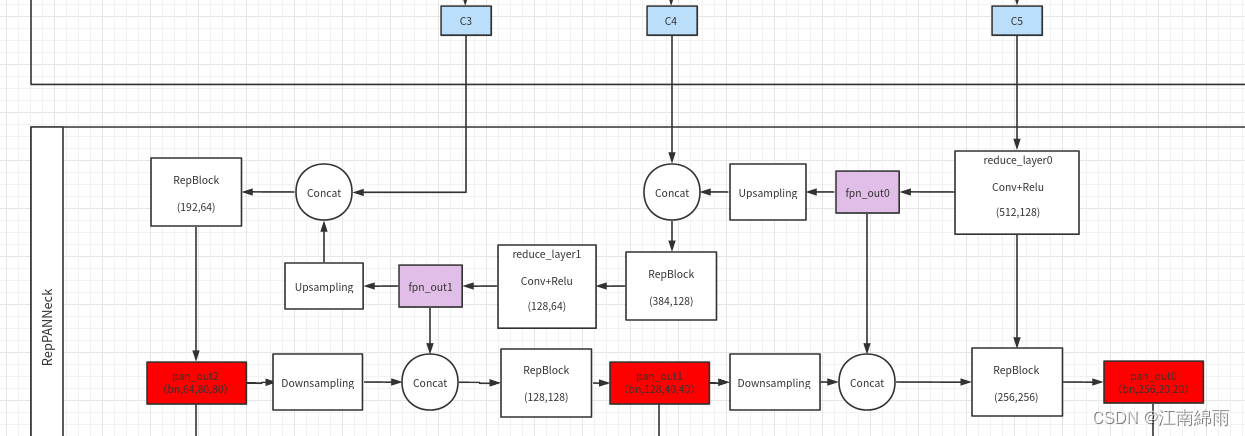
其实就是将CSP-PAN中的CSP模块换成了Rep模块,形成了Rep-PAN罢了,这里不作赘述。
四:Efficient Decoupled Head
就是对YOLO_x中的Decoupled Head进行了精简设计,附上亲手绘制的Head流程图:
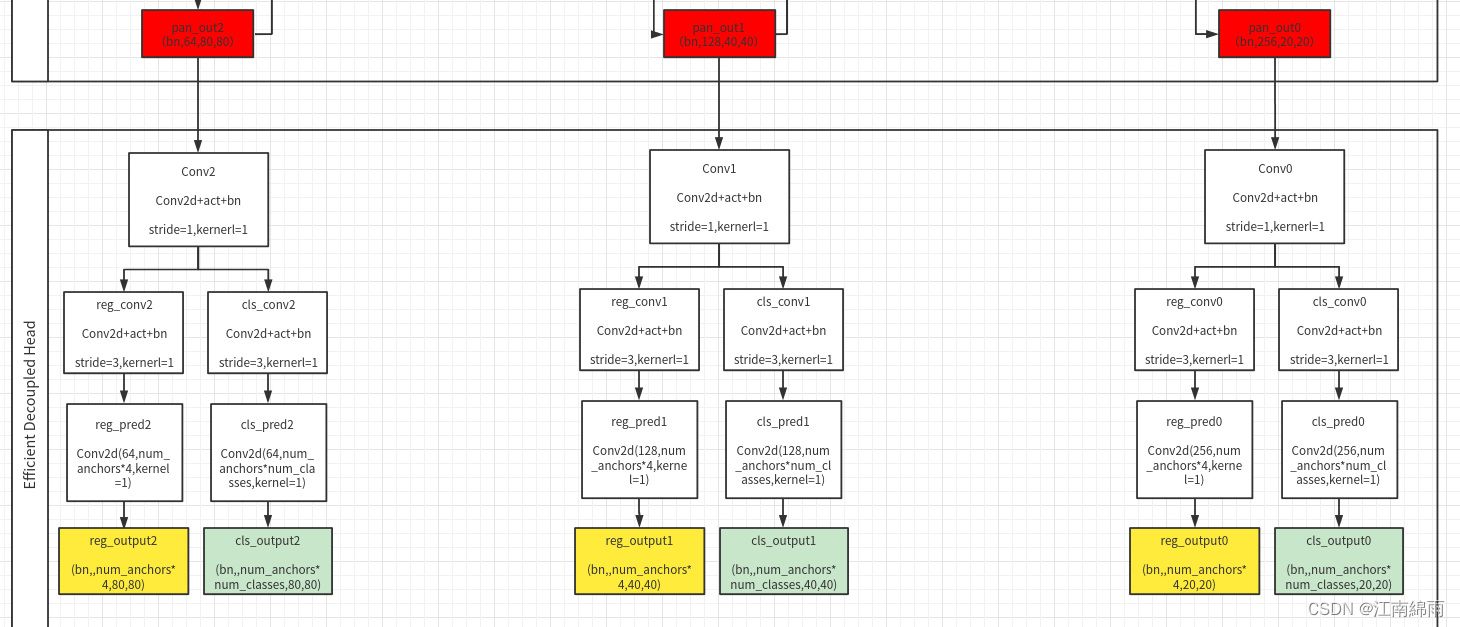
原始 YOLOv5 的检测头是通过分类和回归分支融合共享的方式来实现的,而 YOLOX 的检测头则是将分类和回归分支进行解耦,同时新增了两个额外的 3x3 的卷积层,虽然提升了检测精度,但一定程度上增加了网络延时。
对解耦头进行了精简设计后,同时综合考虑到相关算子表征能力和硬件上计算开销这两者的平衡,采用 Hybrid Channels 策略重新设计了一个更高效的解耦头结构,在维持精度的同时降低了延时,缓解了解耦头中 3x3 卷积带来的额外延时开销。通过在 nano 尺寸模型上进行消融实验,对比相同通道数的解耦头结构,精度提升 0.2% AP 的同时,速度提升6.8%。
五:Anchor-free 无锚范式
YOLOv6 采用了更简洁的 Anchor-free 检测方法。由于 Anchor-based检测器需要在训练之前进行聚类分析以确定最佳 Anchor 集合,这会一定程度提高检测器的复杂度;同时,在一些边缘端的应用中,需要在硬件之间搬运大量检测结果的步骤,也会带来额外的延时。而 Anchor-free 无锚范式因其泛化能力强,解码逻辑更简单,在近几年中应用比较广泛。经过对 Anchor-free 的实验调研,我们发现,相较于Anchor-based 检测器的复杂度而带来的额外延时,Anchor-free 检测器在速度上有51%的提升。
为方便考虑,实现的具体方式和simOTA一同讲解。
六:SimOTA
为了获得更多高质量的正样本,YOLOv6 引入了 SimOTA 算法动态分配正样本,进一步提高检测精度。YOLOv5 的标签分配策略是基于 Shape 匹配,并通过跨网格匹配策略增加正样本数量,从而使得网络快速收敛,但是该方法属于静态分配方法,并不会随着网络训练的过程而调整。
近年来,也出现不少基于动态标签分配的方法,此类方法会根据训练过程中的网络输出来分配正样本,从而可以产生更多高质量的正样本,继而又促进网络的正向优化。例如,OTA通过将样本匹配建模成最佳传输问题,求得全局信息下的最佳样本匹配策略以提升精度,但 OTA 由于使用了Sinkhorn-Knopp 算法导致训练时间加长。
SimOTA算法使用 Top-K 近似策略来得到样本最佳匹配,大大加快了训练速度。故 YOLOv6 采用了SimOTA 动态分配策略,并结合无锚范式,在 nano 尺寸模型上平均检测精度提升 1.3% AP。
传统的Anchor-free样本分配,是设定一堆anchor_points,每个points对应一个范围。当gt_box的center落在哪儿个anchor_points范围内,那么这个point负责该gt_box。出现一个anchor_point范围内包含多个gt_center,那么只负责iou最大的那个gt。也就是说gt_box可以一堆多,但是anchor_point最多负责一个gt。
加入SimOTA匹配策略后,标签分配策略发生一些变化,步骤如下:
- 一个gt会在多个level的feature_map上各找topK个candidate_anchor_points,YOLO_v6是通过计算gt_center与各个anchor_point间的距离远近筛选的,每层寻找前k个近的anchor_points作为candidates。如果
num_levels=3,那么每一个gt初步筛选出3K个candidates - 接着分别统计每层的
k个candidates包括的范围area和gt_box的IOU,计算出每层的标准化后的iou作为thres_iou,只有大于thres_iou的candidate才能保留,其余剔除。这样做,又能剔除一波正样本 - 还没结束,还有一层筛查,就是gt_center要落在这些candidate_point负责的范围内,这里和传统free_anchor一样。
- 通过这三层“选拔”,负责一个gt_box的anchor_points由原本的
3K个到最后的M个 - 因为可能存在一个anchor_point负责了多个gt_box的情况,最后只负责iou最大的那个gt_box
- 最后预测的reg是在feature_map上,pred_box的左上角、右上角相对anchor_points的偏移距离
七:SIoU
使用了一种全新的Iou_Loss,具体可见SIoU Loss论文链接
近年来,常用的边界框回归损失包括IoU、GIoU、CIoU、DIoU loss等等,这些损失函数通过考虑预测框与目标框之前的重叠程度、中心点距离、纵横比等因素来衡量两者之间的差距,从而指导网络最小化损失以提升回归精度,但是这些方法都没有考虑到预测框与目标框之间方向的匹配性。SIoU 损失函数通过引入了所需回归之间的向量角度,重新定义了距离损失,有效降低了回归的自由度,加快网络收敛,进一步提升了回归精度。通过在 YOLOv6s 上采用 SIoU loss 进行实验,对比 CIoU loss,平均检测精度提升 0.3% AP。
八:总结

经过一系列的优化策略和改进,YOLOv6 在多个不同尺寸下的模型均取得了卓越的表现。上表的消融实验展示了 YOLOv6-nano 的消融实验结果,从实验结果可以看出,YOLO_v6在精度和速度上都带来了很大的增益。
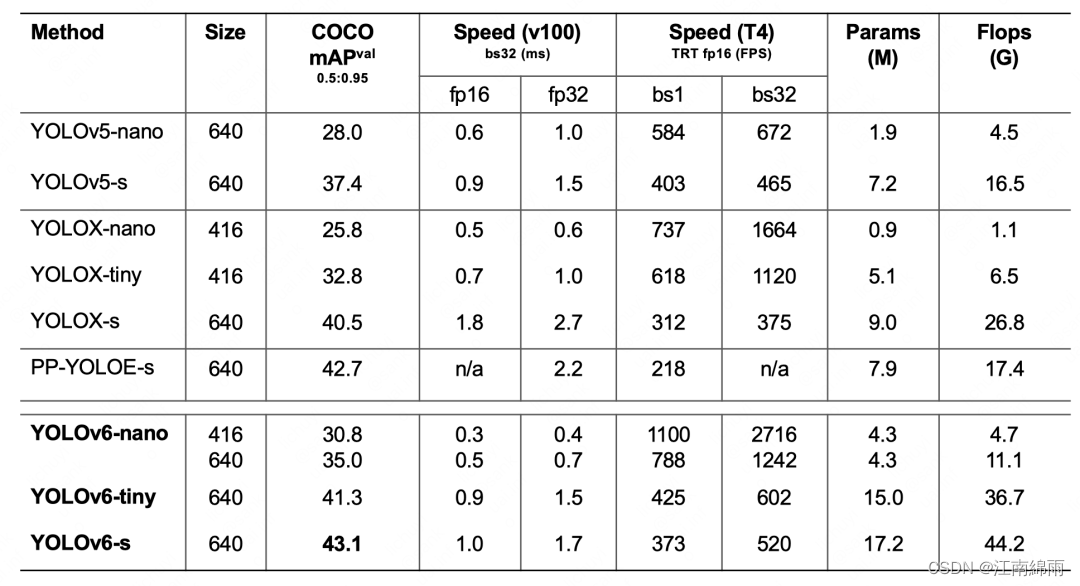
上表是YOLO_v6各尺寸模型性能与其他模型的比较,可见YOLOv6 在检测精度和速度方面都属于佼佼者。虽然参数量比YOLO_v5大了一倍多,但是计算速度还是很快,可见该网络模型对GPU等硬件的利用率很高。
最后附上手撕源码后本人亲手画的YOLO_v6“巨型山水画”:
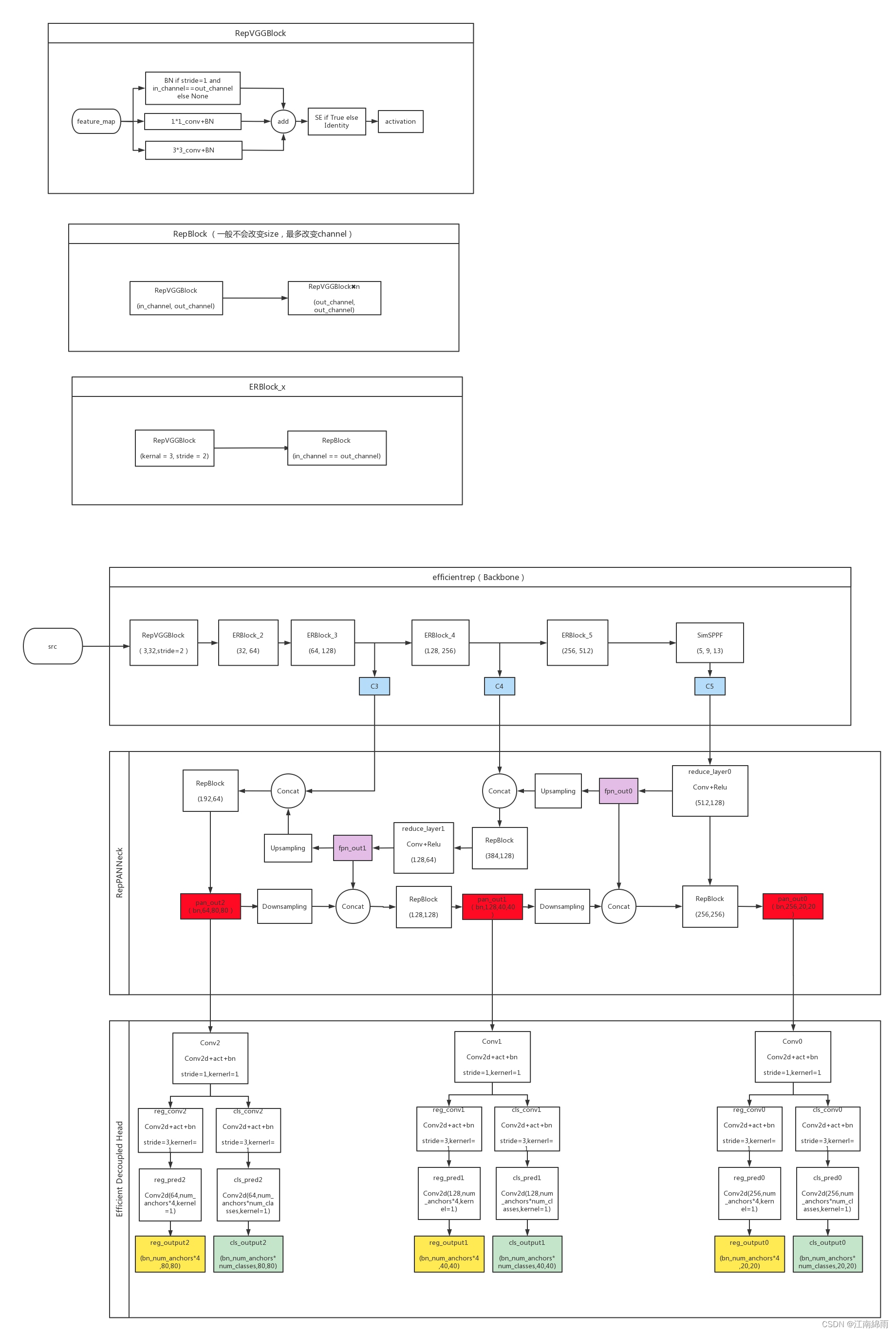
至此我对YOLO_v6中重点流程与细节进行了深度讲解,希望对大家有所帮助,有不懂的地方或者建议,欢迎大家在下方留言评论。
我是努力在CV泥潭中摸爬滚打的江南咸鱼,我们一起努力,不留遗憾!