
一、前言
yoloV7是一种目标检测算法,它是在yoloV5的基础上进一步改进而来的。相比于yoloV5,yoloV7在网络结构、数据增强和激活函数等方面都进行了优化,可以提高模型的表达能力和检测精度。
- 网络结构:yoloV7采用了更深的网络结构,包含更多的卷积层和残差块,可以提高模型的表达能力和检测精度。
- 数据增强:yoloV7引入了更多的数据增强方法,如随机裁剪、随机旋转等,可以增加训练数据的多样性,提高模型的鲁棒性。
- 激活函数:yoloV7采用了swish激活函数,可以提高模型的非线性表达能力,进一步提高检测精度。
二、YOLO_V7
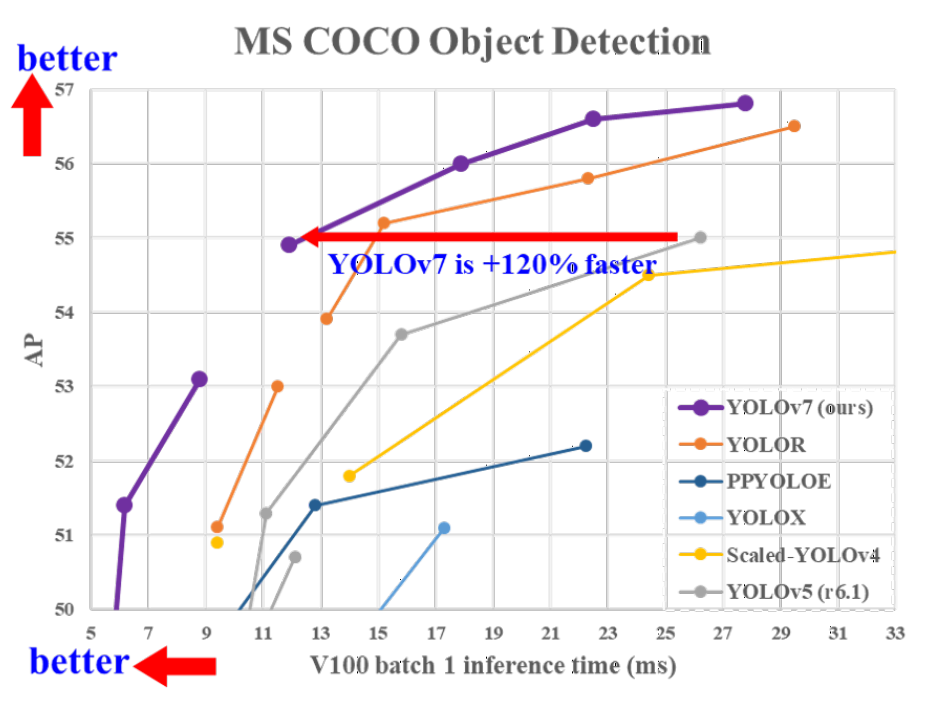
1.概述
- 特征提取单元优化. 使用ELAN作为特征提取单元.
- 下采样优化. 同时使用了最大池化和步长为2的卷积进行下采样.
- 结构重参数化. 在三个不同尺度的检测头前增加了RepConv,并在测试时转换成普通的3x3Conv.
- 检测头改进. 使用了YOLOR的检测头.
- 辅助训练. 在训练时增加辅助head,并在测试时丢弃.
2.网络结构
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov7 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 1, Conv, [64, 1, 1]],
[-2, 1, Conv, [64, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 11
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 24
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 29-P4/16
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 37
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 42-P5/32
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 50
]
# yolov7 head
head:
[[-1, 1, SPPCSPC, [512]], # 51
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[37, 1, Conv, [256, 1, 1]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 63
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[24, 1, Conv, [128, 1, 1]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]], # 75
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 63], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 88
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 51], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-2, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 101
[75, 1, RepConv, [256, 3, 1]],
[88, 1, RepConv, [512, 3, 1]],
[101, 1, RepConv, [1024, 3, 1]],
[[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
看上去很长其实结构不复杂,就是一系列卷积操作,backbone部分结构由stem、ELAN和DS三部分构成,ELAN主要用于特征提取和通道数控制,DS主要用于下采样(输入前后通道数一致). 整体结构可简单描述为:Input->stem->ELAN->(DS->ELAN)^3->Output.
neck部分和head部分的配置通常是写在一起的,因此对neck和head部分做统一描述,以下是YOLO v7的head配置,其主要由ELAN-neck、DS-neck和RepConv构成(由于这里的ELAN和DS形式和backbone中有细微区别,故计作ELAN-neck和DS-neck).
3.模块补充,其他在V4,V5都有提到
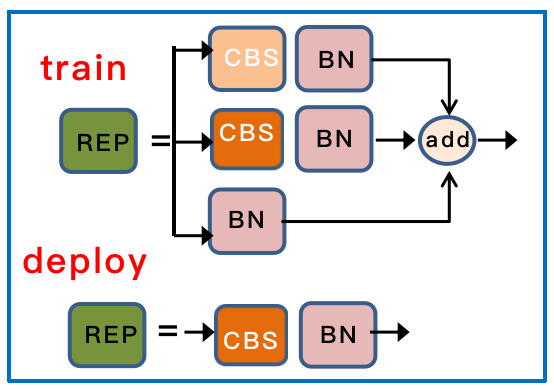
ELAN结构
通过控制最短最长的梯度路径,更深的网络可以有效地学习和收敛。作者提出ELAN结构。基于ELAN设计的E-ELAN 用expand、shuffle、merge cardinality来实现在不破坏原有梯度路径的情况下不断增强网络学习能力的能力。
损失函数
整体和YOLOV5 保持一致,分为坐标损失、目标置信度损失(GT就是训练阶段的普通iou)和分类损失三部分。其中目标置信度损失和分类损失采用BCEWithLogitsLoss(带log的二值交叉熵损失),坐标损失采用CIoU损失。
匹配策略
主要是参考了YOLOV5 和YOLOV6使用的当下比较火的simOTA.
- 训练前,会基于训练集中gt框,通过k-means聚类算法,先验获得9个从小到大排列的anchor框。(可选)
- 将每个gt与9个anchor匹配:Yolov5为分别计算它与9种anchor的宽与宽的比值(较大的宽除以较小的宽,比值大于1,下面的高同样操作)、高与高的比值,在宽比值、高比值这2个比值中,取最大的一个比值,若这个比值小于设定的比值阈值,这个anchor的预测框就被称为正样本。一个gt可能与几个anchor均能匹配上(此时最大9个)。所以一个gt可能在不同的网络层上做预测训练,大大增加了正样本的数量,当然也会出现gt与所有anchor都匹配不上的情况,这样gt就会被当成背景,不参与训练,说明anchor框尺寸设计的不好。
- 扩充正样本。根据gt框的中心位置,将最近的2个邻域网格也作为预测网格,也即一个groundtruth框可以由3个网格来预测;可以发现粗略估计正样本数相比前yolo系列,增加了三倍(此时最大27个匹配)。图下图浅黄色区域,其中实线是YOLO的真实网格,虚线是将一个网格四等分,如这个例子中,GT的中心在右下虚线网格,则扩充右和下真实网格也作为正样本。
- 获取与当前gt有top10最大iou的prediction结果。将这top10 (5-15之间均可,并不敏感)iou进行sum,就为当前gt的k。k最小取1。
- 根据损失函数计算每个GT和候选anchor损失(前期会加大分类损失权重,后面减低分类损失权重,如1:5->1:3),并保留损失最小的前K个。
- 去掉同一个anchor被分配到多个GT的情况。