YOLO V6系列(二) – 网络结构解析
在YOLO V6系列(一) – 跑通YOLO V6算法这篇blog中简单的介绍了YOLO V6算法的训练及测试过程。那么后面,尽可能地对源码进行解析。首先,先对YOLO V6算法的网络架构进行解析吧~(如果中间有不对的地方,还请指出来,权Q ^ _ ^)
首先基于tools/train.py中trainer = Trainer(args, cfg, device)创建训练的类,通过对训练类的初始化model = self.get_model(args, cfg, self.num_classes, device)来创建网络模型。在models/yolo.py中build_network函数可见,YOLO V4算法网络架构基本上就是三部分:backbone、neck、head,跟yolo系列算法相似。
backbone = EfficientRep(
in_channels=channels,
channels_list=channels_list,
num_repeats=num_repeat
)
neck = RepPANNeck(
channels_list=channels_list,
num_repeats=num_repeat
)
head_layers = build_effidehead_layer(channels_list, num_anchors, num_classes)
这三个部分分别来看下:
一、EfficientRep结构
在YOLO V4算法中,弃用了YOLO V5中CSPDarknet结构,采用ReVGG的结构,并且基于硬件又进行了改良,提出了效率更高的EfficientRep。
这里,先介绍下RepVGGBlock模块,他的实现代码在yolov6/layers/common.py中。
def forward(self, inputs):
'''Forward process'''
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.se(self.rbr_reparam(inputs)))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))
self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups)
这里,为了简洁,我只摘取了训练过程中EfficientRep模块的实现代码。其实可以看的出来,它首先对输入特征图进行3X3卷积,同时进行1X1卷积,最后再加上输入本身。这里盗个图(转载于EfficientRep模块示意图)
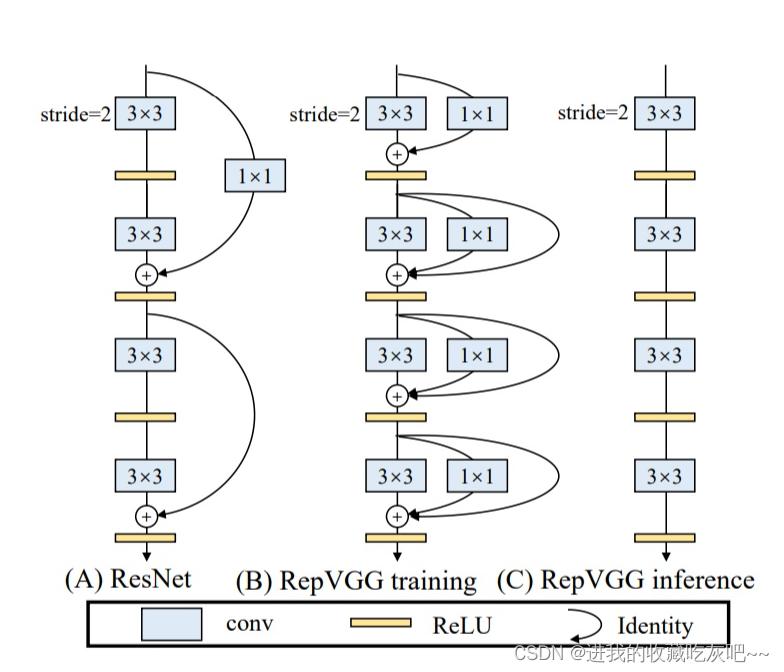
基于RepVGGBlock模块,可组成EfficientRep结构
outputs = []
x = self.stem(x)
x = self.ERBlock_2(x)
x = self.ERBlock_3(x)
outputs.append(x)
x = self.ERBlock_4(x)
outputs.append(x)
x = self.ERBlock_5(x)
outputs.append(x)
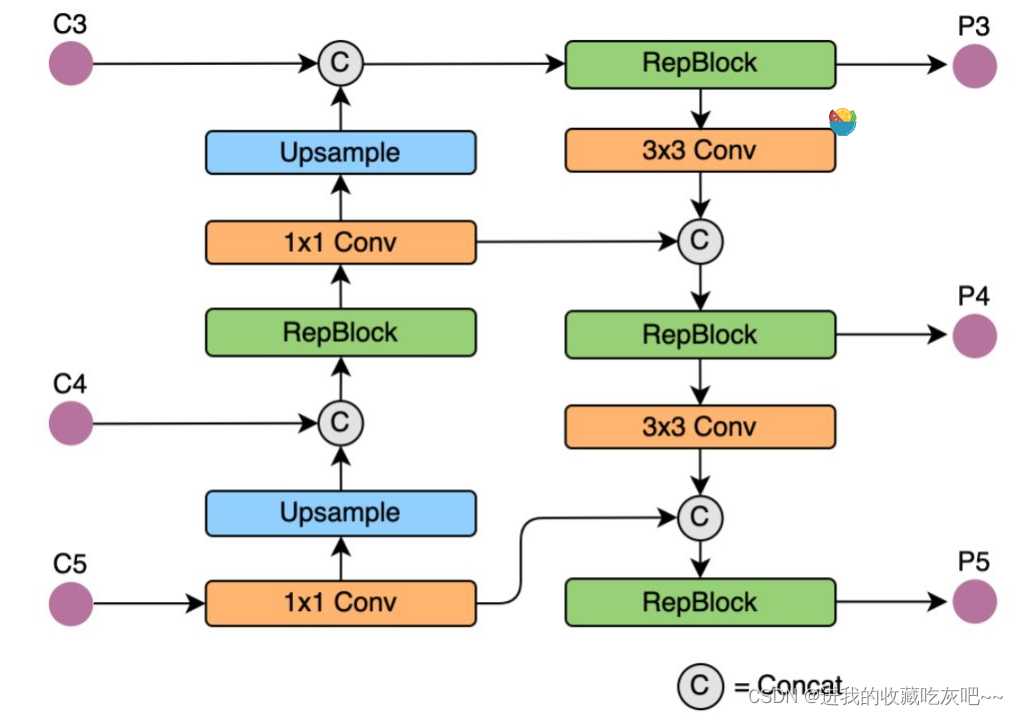
二、RepPANNeck结构
(x2, x1, x0) = input
fpn_out0 = self.reduce_layer0(x0)
upsample_feat0 = self.upsample0(fpn_out0)
f_concat_layer0 = torch.cat([upsample_feat0, x1], 1)
f_out0 = self.Rep_p4(f_concat_layer0)
fpn_out1 = self.reduce_layer1(f_out0)
upsample_feat1 = self.upsample1(fpn_out1)
f_concat_layer1 = torch.cat([upsample_feat1, x2], 1)
pan_out2 = self.Rep_p3(f_concat_layer1)
down_feat1 = self.downsample2(pan_out2)
p_concat_layer1 = torch.cat([down_feat1, fpn_out1], 1)
pan_out1 = self.Rep_n3(p_concat_layer1)
down_feat0 = self.downsample1(pan_out1)
p_concat_layer2 = torch.cat([down_feat0, fpn_out0], 1)
pan_out0 = self.Rep_n4(p_concat_layer2)
outputs = [pan_out2, pan_out1, pan_out0]
上述x2, x1, x0均为backbone进行特征提取之后所得到的三个特征图。从结构上来看,其实还是用了YOLO V5这PANET结构,只不过将其中的CSPDarknet换做了RepBlock。
三、effidehead模块
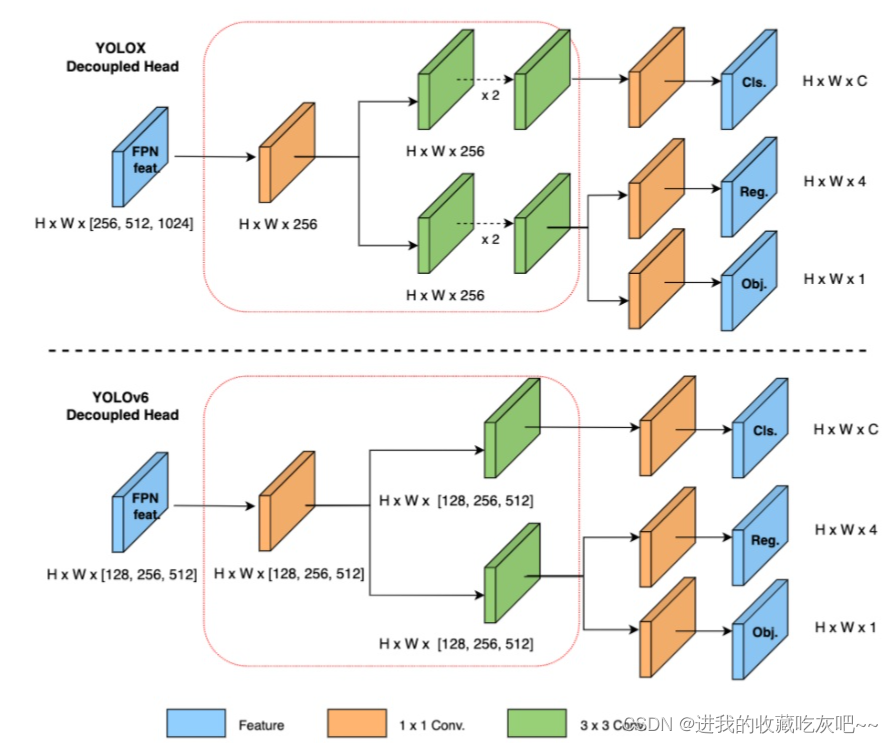
这里,获取预测头的代码有点长,我就直接贴图了。从上图所示,YOLO V6相对于YOLO X来说把解耦头部分的两个卷积减少成一个卷积,这样做应该是缩短训练和测试时间,但是精度应该会有一些损失。最后生成的head应该是
- (cls_convs): ModuleList()
- (reg_convs): ModuleList()
- (cls_preds): ModuleList()
- (stems): ModuleList()