分为两种Windows和Linux,我用的Windows。
初学YOLO,如有问题请留言。
进入到darknetv2根目录,运行下面的命令,
darknet.exe detect ./cfg/yolo.cfg yolo.weights ./data/horses.jpg
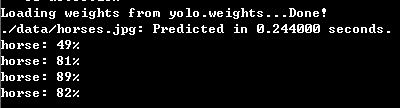
结果如下,运行环境,win7+至强E3cpu+750ti大将,左面为GPU版本,右面为CPU版本,
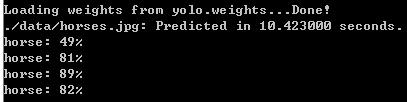
使用cudnn编译后,运行时间,左面为yolo模型,右面为tiny-yolo模型(cudnn版本为v5.1)


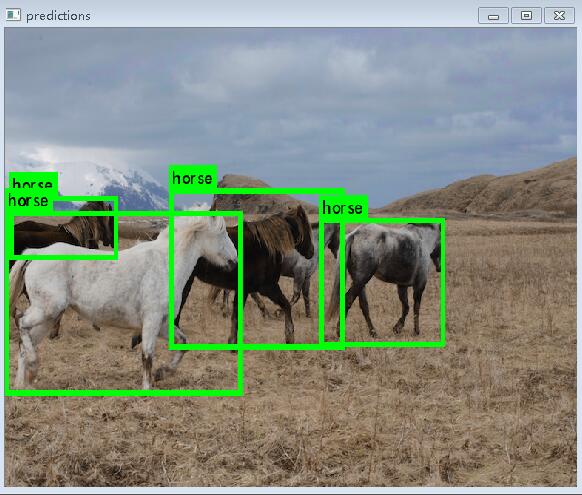
和darknetv1相比,很大的区别就是v1原来的模型750M,2G显存的显卡根本跑不起来,现在v2的模型变小,就可以跑起来了,从速度上来看,还是有点慢,和SSD的速度相比,直接差了1半,这里想说一下,为什么论文中写的速度比ssd快,而测试下不是呢?因为上面的测试都是没有使用cudnn,如果使用的这个,速度会快很多。
windows版本的链接大家可以参考,https://github.com/AlexeyAB/darknet
训练篇:
这里假定我要实现一个简单的人脸检测。
(1)首先就是数据集的准备,这里建议使用python+QT开发的抠图小工具,labelImg。
(2)模仿VOC的格式建立相应的文件夹,执行,- tree -d
目录结构显示如下,
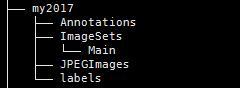
其中,my2017为我自己的数据集起的名字,你也可以起别的名字,Annotations存放XML文件,Main中存放,train.txt,val.txt,test.txt,txt中只写图片的名字,一行一个。JPEGImages中存放图片。labels中存放由XML生成的txt文件。
(3)修改scripts下面的voc_label.py,将数据集的目录修改为自己的目录,然后执行
- python voc_label.py
就会生成labels文件夹,以及文件夹下面的txt标记。

(4)修改,cfg/voc.data
class为训练的类别数
train为训练集train.txt
valid为验证集val.txt
names为voc.names,里面为自己训练的目标名称
backup为weights的存储位置
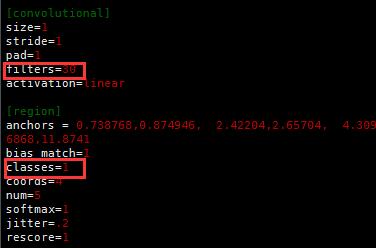
classes= 1
train = /dataSet /2017_train_all.txt
valid = /dataSet /2017_val.txt
names = /opt/darknetv2/data/voc.names
backup = /home/darknet_result_tiny_all/
(5)修改cfg/tiny-yolo.cfg
最后一个卷基层,filters和最后一个region的classes,
其中,filters=num×(classes + coords + 1)=5*(1+4+1)=30,这里我只有1个类别。
(6)执行下面的语句进行训练,
- ./darknet detector train ./cfg/voc.data ./cfg/tiny-yolo.cfg ./darknet19_448.conv.23
训练完毕就可以生成weights文件,
(7)测试,执行下面语句,
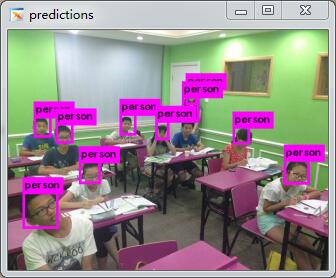
- ./darknetdetect ./cfg/tiny-yolo.cfg /home/darknet_result_tiny_all/tiny-yolo_final.weights ./data/jiaoshi.jpg