- 论文地址:VPS
- 代码地址:GitHub - GewelsJI/VPS: Video Polyp Segmentation (VPS)
- 数据集说明:VPS/DATA_PREPARATION.md at main · GewelsJI/VPS · GitHub
贡献:
- 效果:170fps
- 视频息肉分割数据集:SUN-SEG-Easy Dataset
- VPS Baseline:PNS+ (baseline是指基线,表示比该方法性能还低的是不能接受的)
- VPS Benchmark
针对:结肠息肉的多样性(如边界对比、形状、方向、拍摄角度)、内部伪影(如水流、残留物)和成像退化(如颜色失真、镜面反射)。
SUN-SEG数据集
在SUN数据集的基础上,增加了新的注释,包括物体掩码、边界、
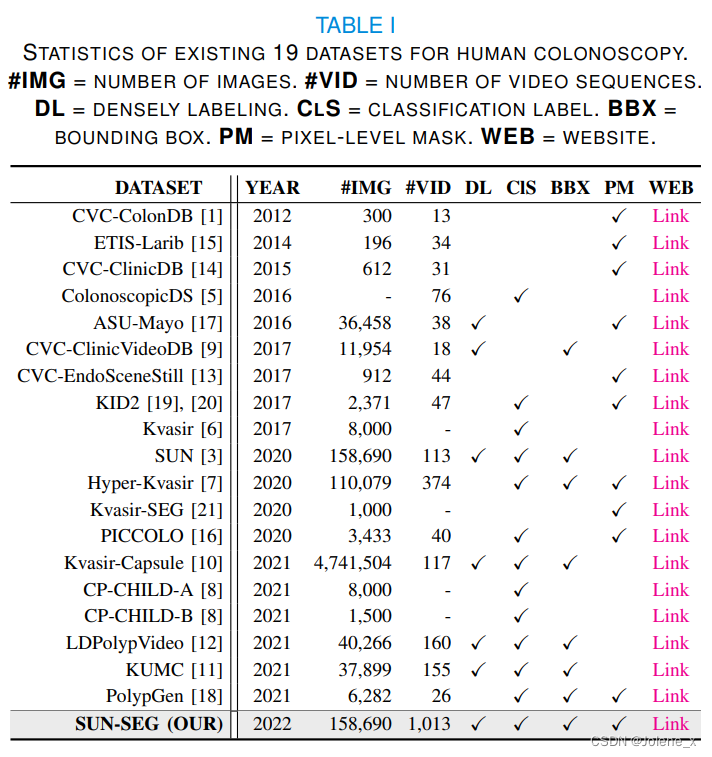
网络架构
Global Encoder
将T帧序列中的第一帧(H’, W’, 3)作为锚点,通过全局编码器提取锚点特征 A h ∈ R H h × W h × C h A^h ∈ R^{H^h×W^h×C^h} Ah∈RHh×Wh×Ch
Local Encoder
利用滑动窗口内的一块连续帧作为输入,利用编码器提取两组特征high和low
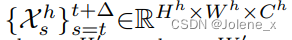
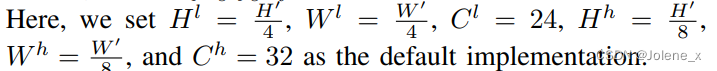
NS块
动态更新感受野
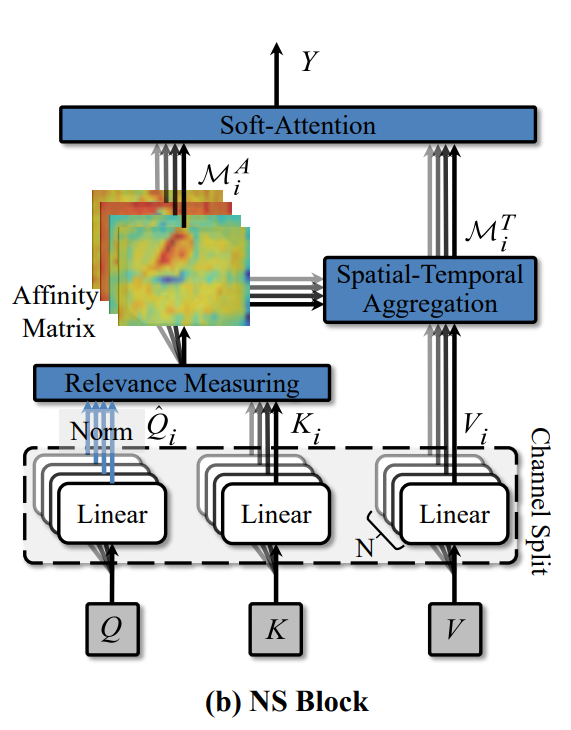
通道划分
得到Q、K、V矩阵(T * H * W * C)后,从通道维度化为N份,得到 Q i , K i , V i ∈ R T × H × W × C N {Q_i, K_i, V_i}∈R^{T\times H\times W\times \frac{C}{N}} Qi,Ki,Vi∈RT×H×W×NC,分别输入N个self-attention模块
查询依赖规则
参考了:PCSA
为了对连续帧之间的时空关系进行建模,需要测量分割的查询特征 ( Q i ) i = 1 N {(Q_i)}_{i=1}^N (Qi)i=1N和关键特征 ( K i ) i = 1 N {(K_i)}_{i=1}^N (Ki)i=1N之间的相似度,参考PCSA引入N个相关性测量块来计算目标像素的受限领域的空间-时间矩阵。

在Non-local中,计算的是Q中的像素与K中所有像素之间的关系,计算查询位置与所有位置关键特征之间的关系,而本文中的块是渐进的扩大特征块的范围
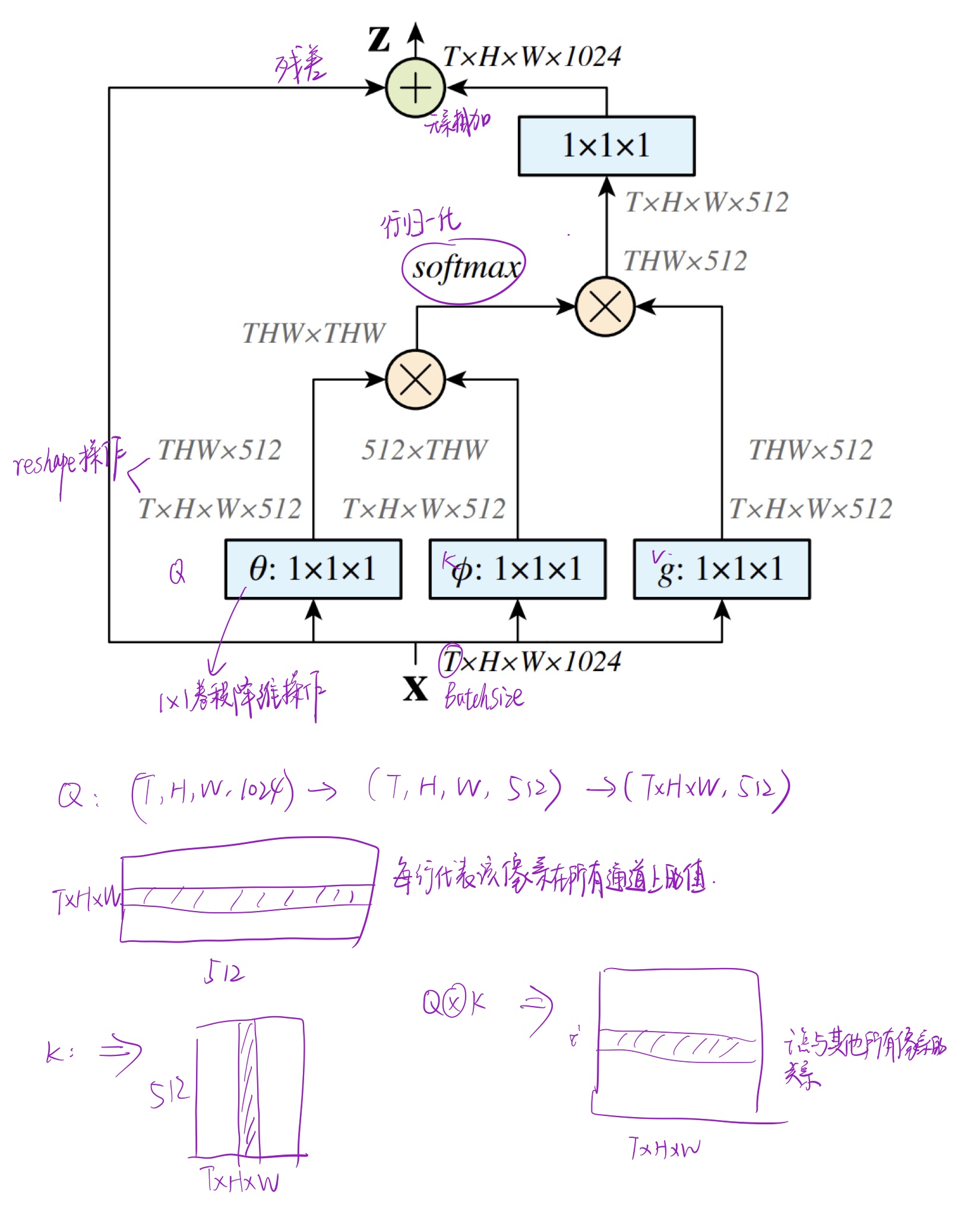
具体的说,就是类似于金字塔网络,给定 Q i Q_i Qi矩阵的一个像素点 X q X^q Xq(更准确地说应该是高x,宽y,第z帧的所有C/8通道像素值),根据窗口的尺寸 k k k和空洞卷积的扩张率 d i d_i di,在 K i K_i Ki矩阵中选取高为 ( x − k d i , x + k d i ) (x-kd_i,x+kd_i) (x−kdi,x+kdi),宽为 ( y − k d i , y + k d i ) (y-kd_i,y+kd_i) (y−kdi,y+kdi),所有帧所有通道的像素值加起来,同时随着N个块中块数的增加, d i = 2 i − 1 d_i=2i-1 di=2i−1会增加,相当于要获取 Q i Q_i Qi与更大范围的 K i K_i Ki之间的关系。类似于扩大感受野

归一化规则
对 Q i Q_i Qi利用 N o r m ( ) Norm() Norm()沿时间维度进行层归一化
Q i ^ = N o r m ( Q i ) \hat{Q_i}=Norm(Q_i) Qi^=Norm(Qi)
相关性测量
最终的相关度计算公式,整体的形式与原始的transformer的自注意力公式是一样的
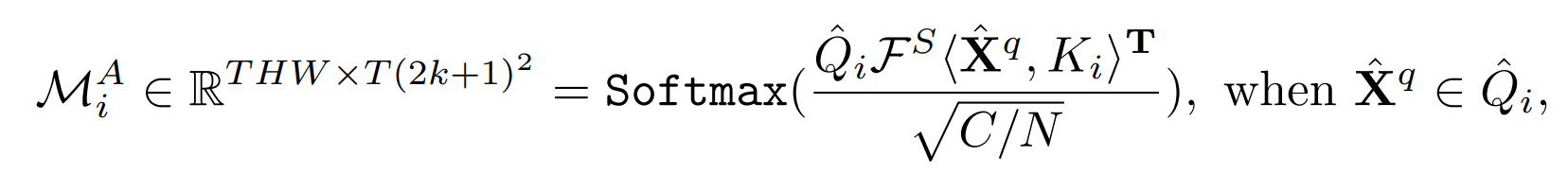
Spatial-Temporal(时空聚合)
与相似度计算类似,计算V矩阵与Q和K相似度结果,其实
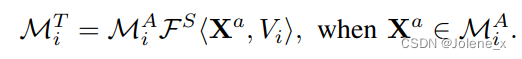
其实整体的计算过程与transformer的自注意力机制是一样的,不过在计算像素之间的相关的方式改了
soft-attention
通过此模块融合相似度矩阵的特征 M i A M^A_i MiA和时空聚合特征 M i T M^T_i MiT,应该加强相关的时空模式,抑制弱相关的时空模式
先将一组相似度矩阵 M i A M_i^A MiA沿通道维度串联起来,生成 M A M^A MA
Max函数计算了 M A M^A MA在通道维度上的最大值,然后将一组沿着通道维度的时空聚合特征 M i T M^T_i MiT拼接生成 M T M^T MT
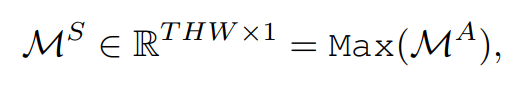
归一化的自注意力
W T W_T WT是可学习的权重,※表示通道式Hadamard积(矩阵对应元素相乘)
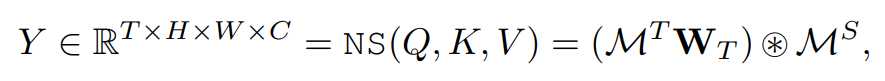
哈达玛积:
对于 m × n m\times n m×n的两个矩阵A和B,相同位置元素相乘
( a 11 a 12 a 13 a 21 a 22 a 23 a 31 a 32 a 33 ) ∗ ( b 11 b 12 b 13 b 21 b 22 b 23 b 31 b 32 b 33 ) = ( a 11 b 11 a 12 b 12 a 13 b 13 a 21 b 21 a 22 b 22 a 23 b 23 a 31 b 31 a 32 b 32 a 33 b 33 ) \left( \begin{matrix} a_{11}\ a_{12}\ a_{13}\\ a_{21}\ a_{22}\ a_{23}\\ a_{31}\ a_{32}\ a_{33}\\ \end{matrix} \right) * \left( \begin{matrix} b_{11}\ b_{12}\ b_{13}\\ b_{21}\ b_{22}\ b_{23}\\ b_{31}\ b_{32}\ b_{33}\\ \end{matrix} \right) = \left( \begin{matrix} a_{11}b_{11}\ a_{12}b_{12}\ a_{13}b_{13}\\ a_{21}b_{21}\ a_{22}b_{22}\ a_{23}b_{23}\\ a_{31}b_{31}\ a_{32}b_{32}\ a_{33}b_{33}\\ \end{matrix} \right) ⎝⎛a11 a12 a13a21 a22 a23a31 a32 a33⎠⎞∗⎝⎛b11 b12 b13b21 b22 b23b31 b32 b33⎠⎞=⎝⎛a11b11 a12b12 a13b13a21b21 a22b22 a23b23a31b31 a32b32 a33b33⎠⎞
NS块的输出
全局-局部学习策略
在任意的时间距离上实现长期和短期的时空传播
Global Spatial-Temporal Modeling
全局时空建模
第一个NS块来模拟任意时间距离的长期关系,需要四维的时间特征作为输入。
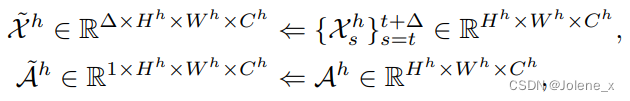
利用锚点特征 A h A^h Ah作为查询矩阵 Q g Q^g Qg,采用局部编码器生成的high特征作为 K g K^g Kg和 Q g Q^g Qg
目的是建立锚点和局部high特征之间的像素相似性,残差连接,得到 Z g Z^g Zg,其中+是逐元素相加
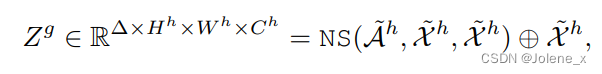
Global-to-Local Propagation
第二个NS块,将长距离依赖关系 Z g Z^g Zg传播到滑动窗口内的帧,将其作为第二个NS块的输入
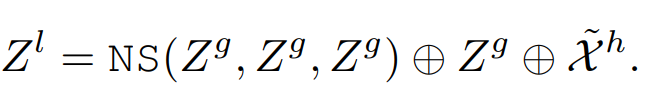
解码器
将局部编码器的low特征和第二个NS块的输出特征 Z l Z^l Zl恢复到空间形式,作为一个两级U-Net解码器的输入
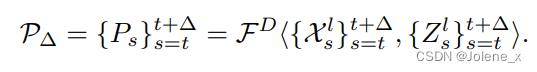
利用二进制交叉熵损失进行优化

PCSA
CSA(受约束的self-attetion)专注于局部运动模式,而不是学习全局背景
考虑到突出物体可以有不同的尺寸,并以不同的速度移动,所以利用一组CSA形成金字塔结构
受约束的self-attention
将连续帧中的相关性测量和上下文约束到Q的邻近区域
比如下面这个图,第一帧中的物体与相邻帧中的物体有相似的位置,基于此,对于Q矩阵中的一个特征元素x(t, h, w),取其在K矩阵中的周围区域用来测量相关性,该区域被限制在帧:1-T,高:h-dr,h+dr,宽:w-dr,w+dr

金字塔的组合
这就是应用于PNS-Net中的参考
具有固定尺寸的单一的受约束的自注意力无法识别有各种速度和各种大小引起的移动目标,多头机制每个头都有不同的窗口大小和移动范围,以适应不同的运动情况
将多头与多尺度相结合
多头:并行的,将输入特征沿着通道分为g组,对每一组使用受约束的自注意力
mg-g44DU2tR-1653467435113)]
金字塔的组合
这就是应用于PNS-Net中的参考
具有固定尺寸的单一的受约束的自注意力无法识别有各种速度和各种大小引起的移动目标,多头机制每个头都有不同的窗口大小和移动范围,以适应不同的运动情况
将多头与多尺度相结合
多头:并行的,将输入特征沿着通道分为g组,对每一组使用受约束的自注意力
多尺度:不同的组,采用不同的窗口大小,d和r不同