第一章
并行程序:有p个核,每个核独立于其他核并累加求和,以得到部分和 ,每个核的计算数为n/p
- 全局总和:每个单独的核计算完结果后,将结果发送给master的核,master的核将每个核的结果加起来。
- 部分总和:每个核计算完之后,先两两相加,再两两求和
显然第二种方法更好!
并行程序的方法:任务并行和数据并行
任务并行:将待解决的任务所需要执行的各个任务分配到各个核上去执行
数据并行:将待处理的数据分配给各个核
第二章
Foster方法:
- 划分问题并识别任务
- 在任务中识别要执行的通信
- 凝聚或聚合使之变成较大的组任务
- 将聚合任务分配给进程/线程
作业
2.1
在梯形图中从上到下容量依次递增,速率依次递减,每字节的成本依次递减
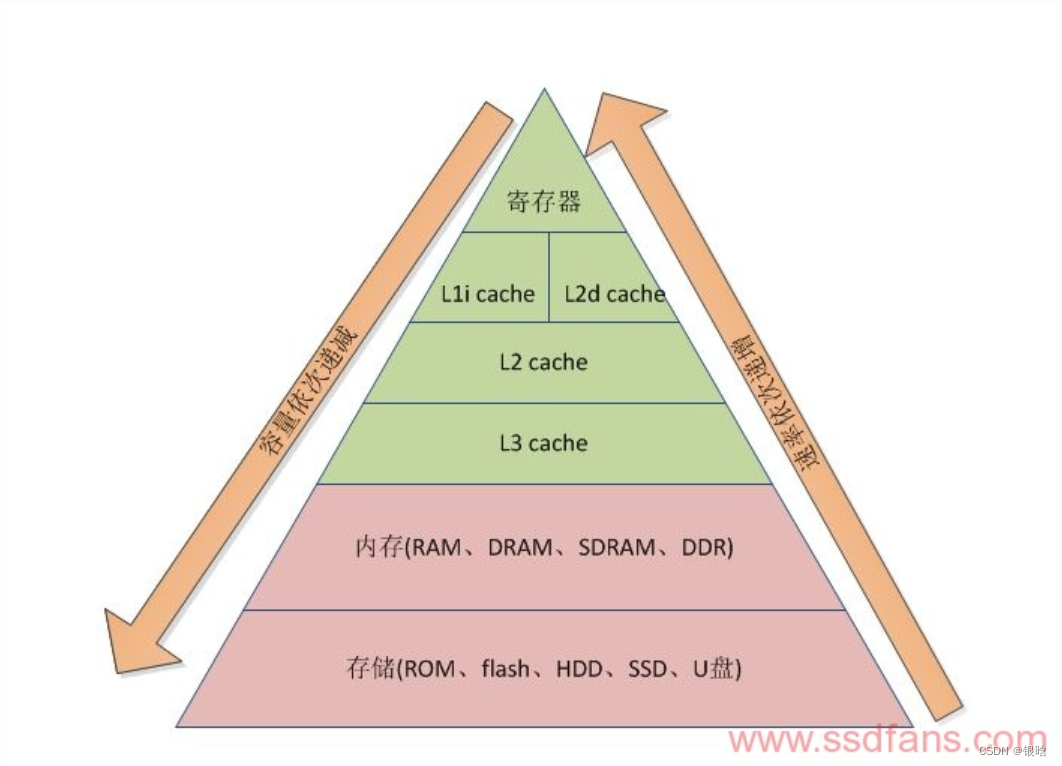
2.2
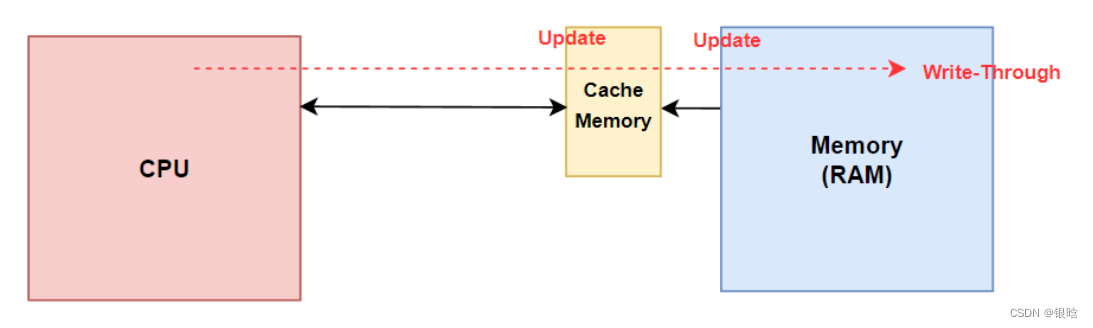
内存的数据被加载到Cache后,在某个时刻其要被写回内存,写内存有如下5种策略:写通(write-through)、写回(write-back)、写一次(write-once)、WC(write-combining)和UC(uncacheable)。

写通(write-through):
当cache写命中时,处理器对Cache写入的同时,将数据写入到内存中,内存的数据和Cache中的数据都是同步的,这种方式比较简单、可靠。但是处理每次对cache更新都需要对内存写操作,因此总线工作繁忙,内存的带宽被大大占用,因此运行速度会受到影响。
假设一段程序在频繁地修改一个局部变量,局部变量生存周期很短,而且其他进程/线程也用不到它,CPU依然会频繁地在Cache和内存之间交换数据,造成不必要的带宽损失。
当cache写未命中时,只有直接向主存写入了,但此时是否将修改过的主存块取到cache,写直达法却有两种选择。
一是取来并且为它分配一个位置,称为WTWA(Write–Through–with–Write–Allocate)。
另一种是不取称为WTNWA法(WriteThrough–with.NO-Write–Allocate)。
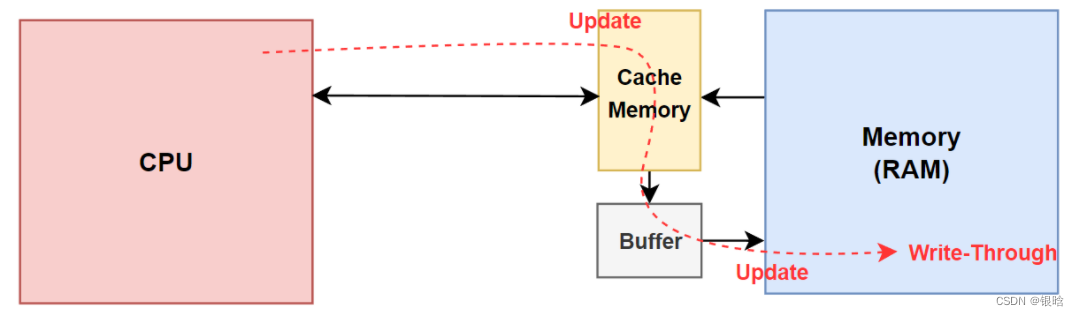
前 一种法保持了cache/主存的一致性,但操作复杂,而后一种方法操作简化,但命中率降低,内存的修改块只有在读未命中对cache 进行替换时,才有可能射到cache 。写通发保证了写cache与写主存同步进行,图中为写通法WTNWA法的流程图。
- 存在一个缓冲区,CPU写入高速缓存器的同时更新主存数据
第5章 OpenMP进行共享内存编程
OpenMP是一个针对共享内存编程的API。
MP = multiprocessing(多处理)
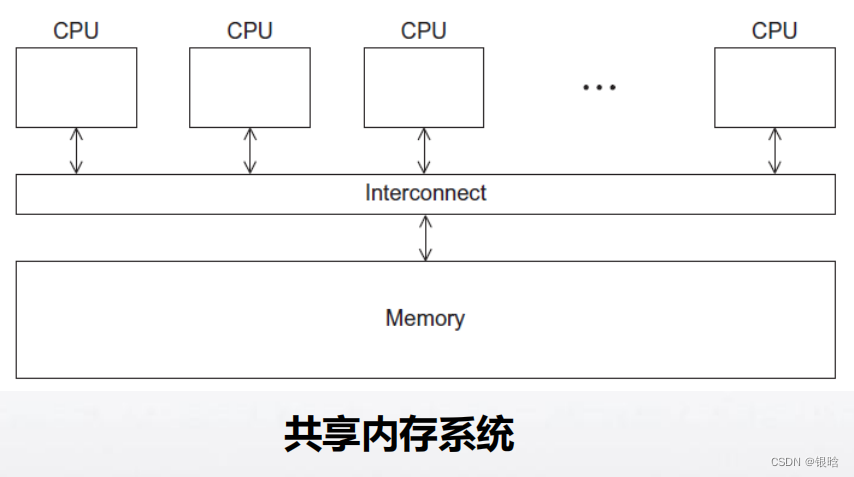
- 在系统中,OpenMP的每个线程都有可能访问所有
可以访问的内存区域 - 共享内存系统:将系统看做一组核或CPU的集合,
它们都能访问主存
OpenMP和Pthread联系和区别

- 在Pthreads中,派生和合并多个线程时,需要为每个线程的特殊结构分配存储空间,需要使用一个for循环来启动每个线程,并使用另一个for循环来终止这些线程
- 在OpenMP中,不需要显式地启动和终止多个线程。它比Pthreads层次更高
OpenMP线程概念
启动一个进程,然后由进程启动这些线程。
线程共享启动它们的进程的大部分资源,如对标准输入和标准输出的访问,但每个线程有它自己
的栈和程序计数器
在parallel之前,程序只使用一个线程,而当程序开始执行时,进程开始启动。当程序达到parallel指令时,原来的线程继续执行,另外thread_count-1个线程被启动。
- 在OpenMP语法中,执行并行代码块的线程集合( 由原始线程和新产生的线程组成)被称作线程组
- 原始的线程被称作主线程,新产生的线程被称作从线程
隐式路障:即完成代码块的线程将等待线程组中的所有其他线程返回
私有栈:每个线程有它自己的栈,所以一个执行Hello函数的线程将在函数中创建它自己的私有局部变量
乱序输出:注意因为标准输出被所有线程共享,所以每个线程都能够执行printf语句,打印它的线程编号和线程数。由于对标准输出的访问没有调度,因此线程打印它们结果的实际顺序不确定
错误检查
- 头文件omp.h以及调用omp_get_thread_num和
omp_get_num_threads将引起错误 - 如果编译器不支持OpenMP,那么它将只忽略parallel指令
- 为了处理这些问题,可以检查预处理器宏
_OPENMP是否定义。如果定义了,则能够包含
omp.h并调用OpenMP函数

变量作用域
-
共享作用域:能够被线程组中所有线程访问的变
量。 -
在 main 函 数 中 声 明 的 变 量 ( a,b,n,global_result 和
thread_count)对于所有线程组中被parallel指令启动的线
程都可访问- parallel块之前被声明的变量缺省作用域是共享的。
- 每个线程都能访问a,b,n(Trap的调用);
- 在Trap函数中,虽然global_result_p是私有变量,但
它引用了global_result变量,该变量是共享作用域的。
因此,
- global_result_p拥有共享作用域。
- parallel块之前被声明的变量缺省作用域是共享的。
-
私有作用域:只能被单个线程访问的变量。
- parallel块中声明的变量有私有作用域(函数中局部变量)
在parallel指令中,所有变量的缺省作用域是共享的
在parallel for中,由其并行化的循环中,循环变量的缺省作用域是私有的。
- 采用“Fork/Join”方式,并行执行模式
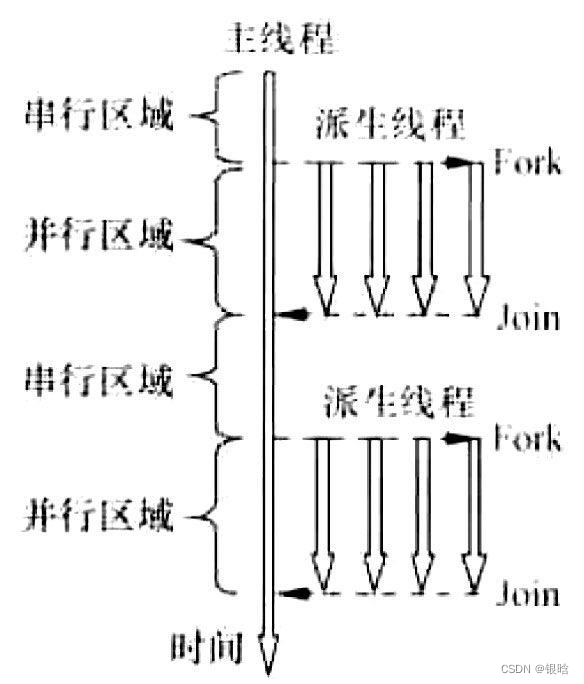
OpenMP程序编写
-
OpenMP是“基于指令”的共享内存API。
-
OpenMP的头文件为omp.h
-
omp.h是由一组函数和宏库组成
-
stdlib.h头文件即standard library标准库头文件。
- stdlib.h里面定义了五种类型、一些宏和通用工具函数
预处理指令
- 预处理指令是在C和C++中用来允许不是基本C语言规范部分的行为;
- eg:特殊的预处理器指令
#pragma - 不支持pragma的编译器会忽略pragma指令提示
的那些语句. - 允许使用pragma程序在不支持它们的平台上运
行。
- eg:特殊的预处理器指令
# pragma omp parallel:
parallel指令是用来表示之后的结构化代码块应该被多个线程并行执行
结构化代码块是一条C语言语句或者只有一个入口和出口的一组复合C语句
编写规范:
- 预处理器指令以#pragma开头
- #放在第一列
- pragma: 与其它代码对齐
- pragma的默认长度是一行
- 如果有一个pragma在一行中放不下,那么新行需要被转
义——’\’
OpenMP规则
OpenMP中,预处理器指令以#pragma omp开头
# pragma omp parallel clause1 \
clause2 … clauseN new-line
- 编译指导语句由directive(指令)和clause list(子句列表)组成
#pragma omp parallel [clause…] new-line
Structured-block
#pragma omp parallel private(i,j)
其中parallel就是指令,private是子句,且指令后
的子句是可选的。
编译指导语句后面需要跟一个new-line(换行符)。然后跟着的是一个structured-block
- structured-block: for循环或一个花括号对(及内部的全部代码)
当整个编译指导语句较长时,也可以分多行书写,用
C/C++的续行符“\”连接起来即可。如:
#progma omp parallel claused1 \
Claused2 … clausedN new-line
Structured-block
规约子句 reduction
-
规约操作是一个二元操作 (such as addition or multiplication).
-
规约操作就是将一个相同的操作重复应用在一个序列上,得到一个结果。所有的中间结果和最终结果都存储在规约变量里
规约操作通过reduction指令实现:
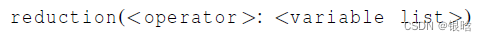

for & parallel for
for指令是用来将一个for循环分配到多个线程中执行
for指令的使用方式:
1.单独用在parallel语句的并行块中;
2.与parallel指令合起来形成parallel for指令
注意:for指令与parallel for指令
派生出一组线程来执行后面的结构化代码块
只能并行for语句
parallel 结合 for实例:
include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[]){
int j=0;
#pragma omp parallel num_threads(4)
{
#pragma omp for
for(j=0;j<4;j++)
printf("j=%d,ThreadId=%d\n",j,omp_get_thread_num());
}
return 0;
}
如果二者不结合,从结果可以看出四次循环都在一个线程里执行,可见,for指令要与parallel指令结合起来使用.
- 多个for
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[]){
int j=0;
#pragma omp parallel num_threads(4)
{
#pragma omp for
for(j=0;j<4;j++)
printf("First:j=%d,ThreadId=%d\n",j,omp_get_thread_num());
#pragma omp for
for(j=0;j<4;j++)
printf("Second:j=%d,ThreadId=%d\n",j,omp_get_thread_num());
}
return 0;
}
for循环的限制

for循环构造的一些限制如下:
变量index必须是整型或指针类型。
表达式start、end和incr必须是兼容类型。
表达式start、end和incr不能够在循环执行期间改变,也
就是迭代次数必须是确定的。
在循环执行期间,变量index只能够被for语句中的“增
量表达式”修改。
for语句中不能含有break。
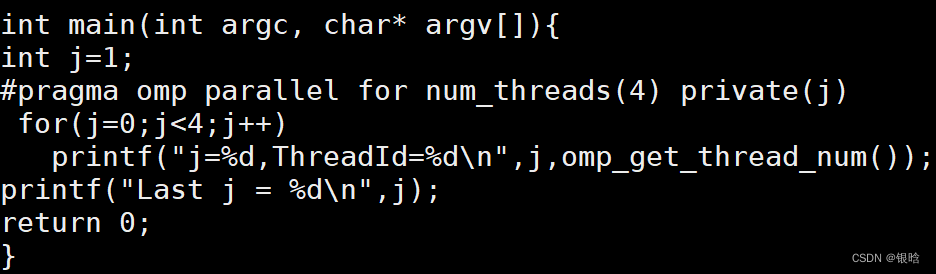
private子句
出现在reduction子句中的参数不能出现在private
用private子句声明的私有变量的初始值在parallel块或parallel for块的开始处是未指定的,且在完成之后也是未指定的
- demo: for循环前的变量j和循环区域内的变量j其实是两个不同的变量
- 它不会继承同名共享变量的值
default子句
- default子句用来允许用户控制并行区域中变量的共享属性,
用法如下:default(shared|none)
- 使用shared时,缺省情况下,传入并行区域内的同名变量被
当做共享变量来处理,不会产生线程私有副本,除非使用
private等子句来指定某些变量为私有的才会产生副本。 - 如果使用none作为参数,那么线程中用到的变量必须显式指
定是共享变量还是私有变量,那些有明确定义的除外

shared子句
用来声明一个或多个变量是共享变量,
用法如下:shared(list)
注意的是:
在并行区域内使用共享变量时,如果存在写操作,必须对共享变量加以保护;
否则,不要轻易使用共享变量,尽量将共享变量的访问转化为私有变量的访问
概念总结


- parallel for 中缺省循环变量为私有作用域的权限大于default(none)或default(shared)的设置权限
实例代码
for循环串行代码:
#include <stdio.h>
int main(int argc, char *argv[]){
int i;
for (i=0; i<10; i++){
printf("i=%d\n",i);
}
printf("Finished.\n");
return 0;
}
并行代码:
#include <stdio.h>
#include <stdlib.h>
#include <omp.h>
int main(int argc, char *argv[]){
int i;
//用来指定执行之后的代码块的线程数目
int thread_count = strtol(argv[1],NULL,10);
# pragma omp parallel for num_threads(thread_count)
for (i=0; i<10; i++){
printf("i=%d\n",i);
}
printf("Finished.\n");
return 0;
}
编译:gcc −g −Wall −fopenmp −o omp_example omp_example .c
执行:. /omp_example 4 4个线程执行
HelloWorld代码
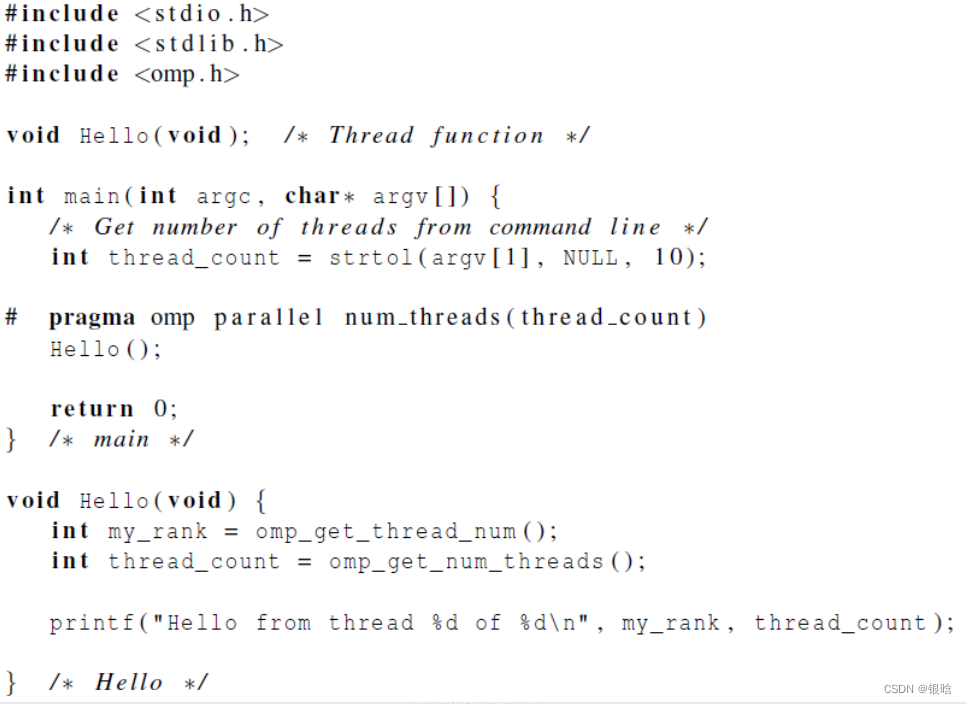
- 每个被启用的线程都执行Hello函数,并且当线程从Hello调用返回时,该线程就被终止。
- 先执行完的线程处于阻塞等待状态 (隐式路障)
- 在执行return语句时进程被终止
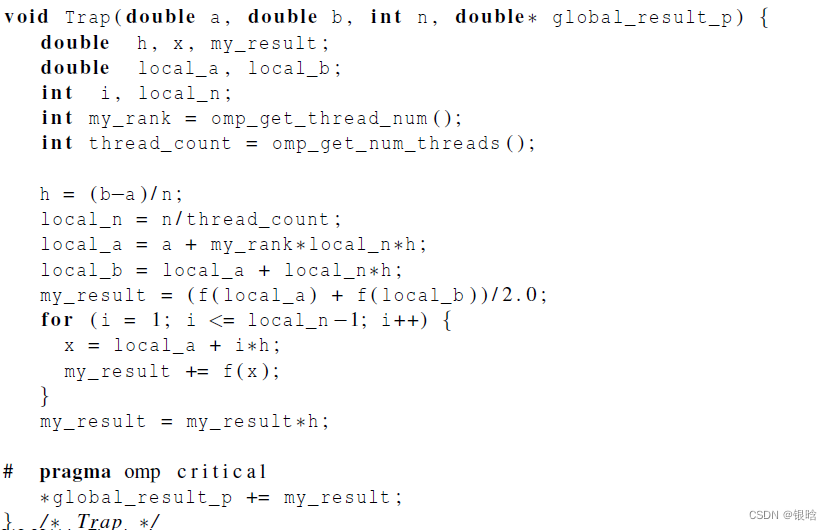
梯形积分
串行代码
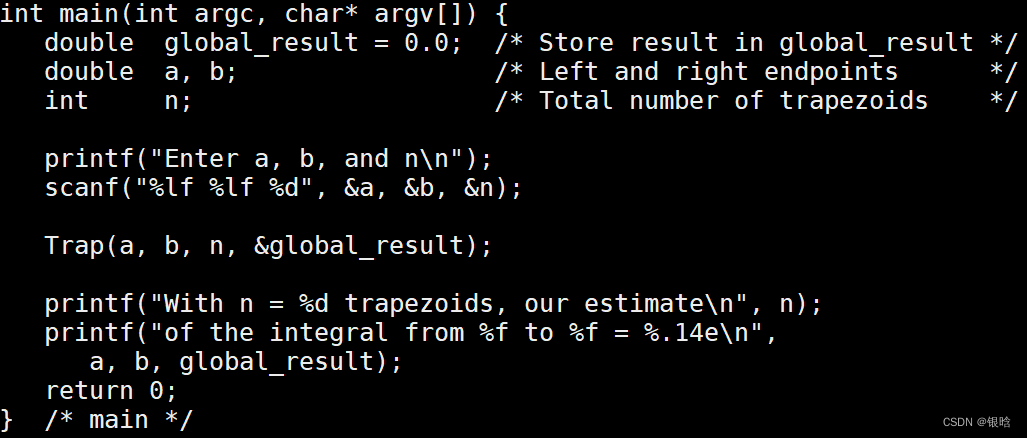
- 在trap函数中,每个线程获取它的编号,以及线程总数,然后确定以下的值:
1、梯形底长
2、给每个线程分配梯形数目
3、梯形的左右端点值
4、部分和my_result
5、将部分和增加到全局和global_result里
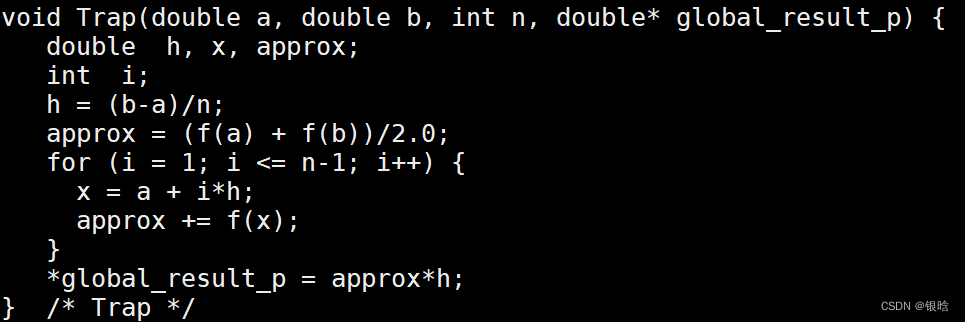
- 给线程分配任务
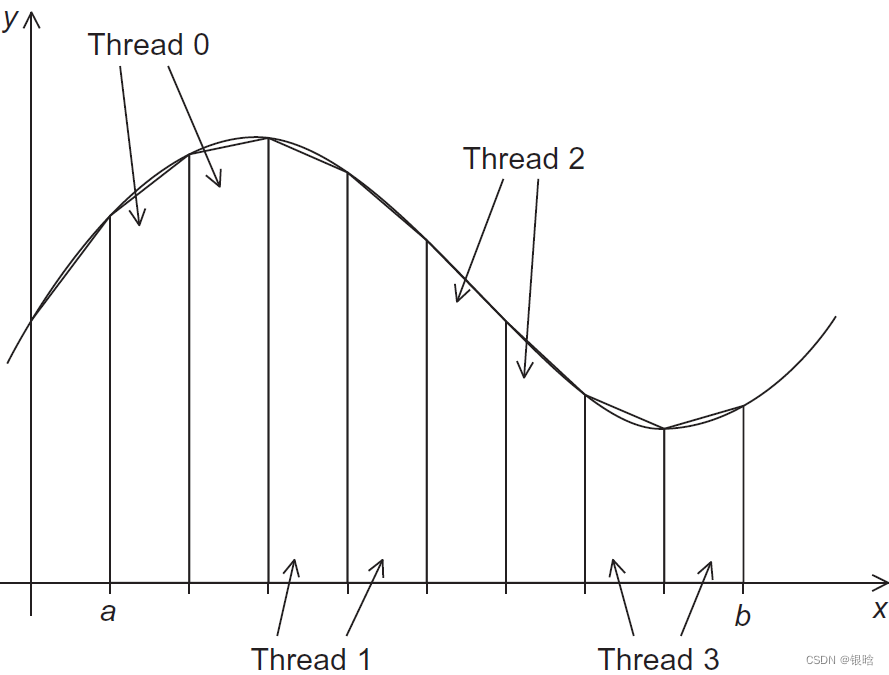
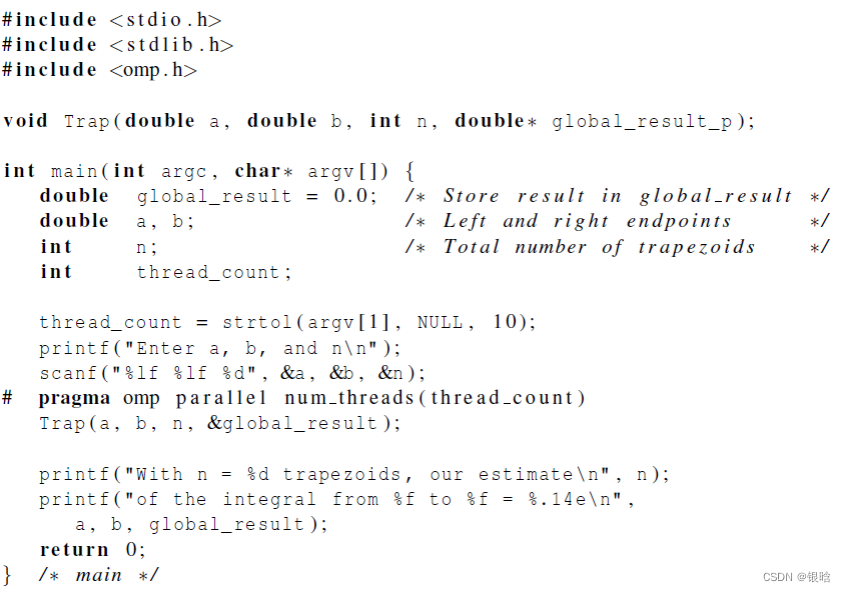
改并行

临界区
- 引起竞争的代码,称为临界区
- 竞争:多个线程试图访问并更新一个共享资源。
- 因此需要一些机制来确保一次只有一个线程执行临界区,这种操作,我们称为互斥
当两个或更多的线程加到global_result中,可能会出现不可预期的结果
critical:
critical指令用在一段代码临界区之前,临界区在同一时间内只能有一个线程执行它,其他线程要执行临界区则需要排队来执行它。
#pragma omp critical[(name)] new-line
structured-block
# progma omp critical
global_result += my_result
Π估计
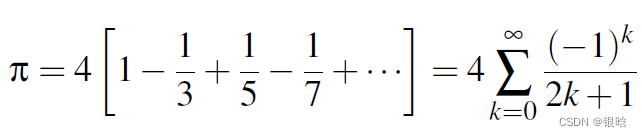
- 串行

- 并行


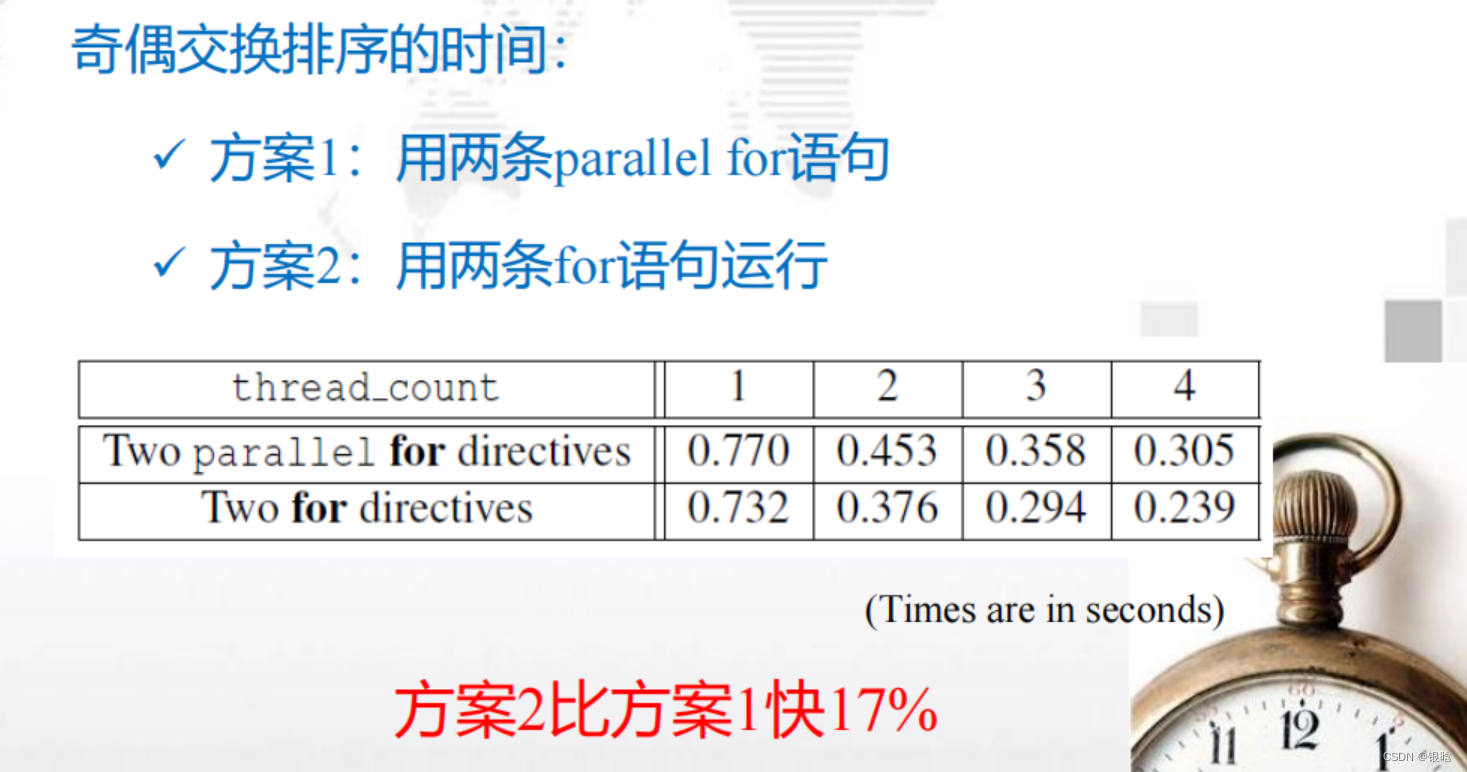
奇偶交换排序
三个点:OpenMP实现奇偶排序,循环调度,环境变量
排序:

奇偶交换排序是冒泡排序的一个变种,该算法更适合并行化
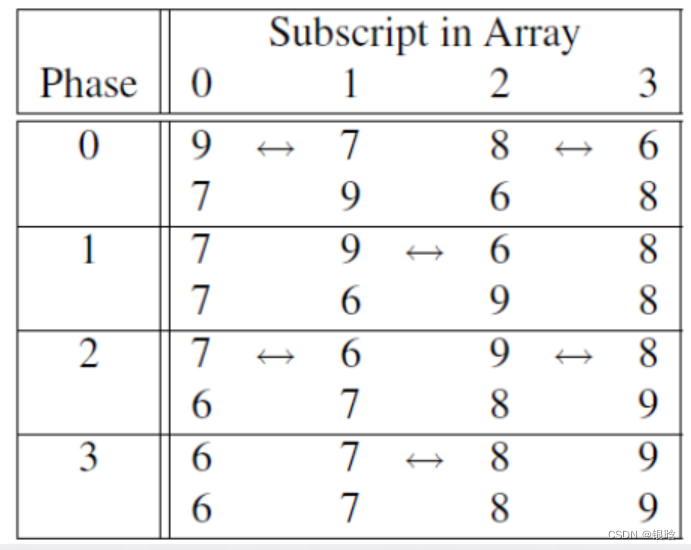
- 串行函数实现:

- OpenMP并行实现(版本1):用两个 parallel for循环来实现奇偶
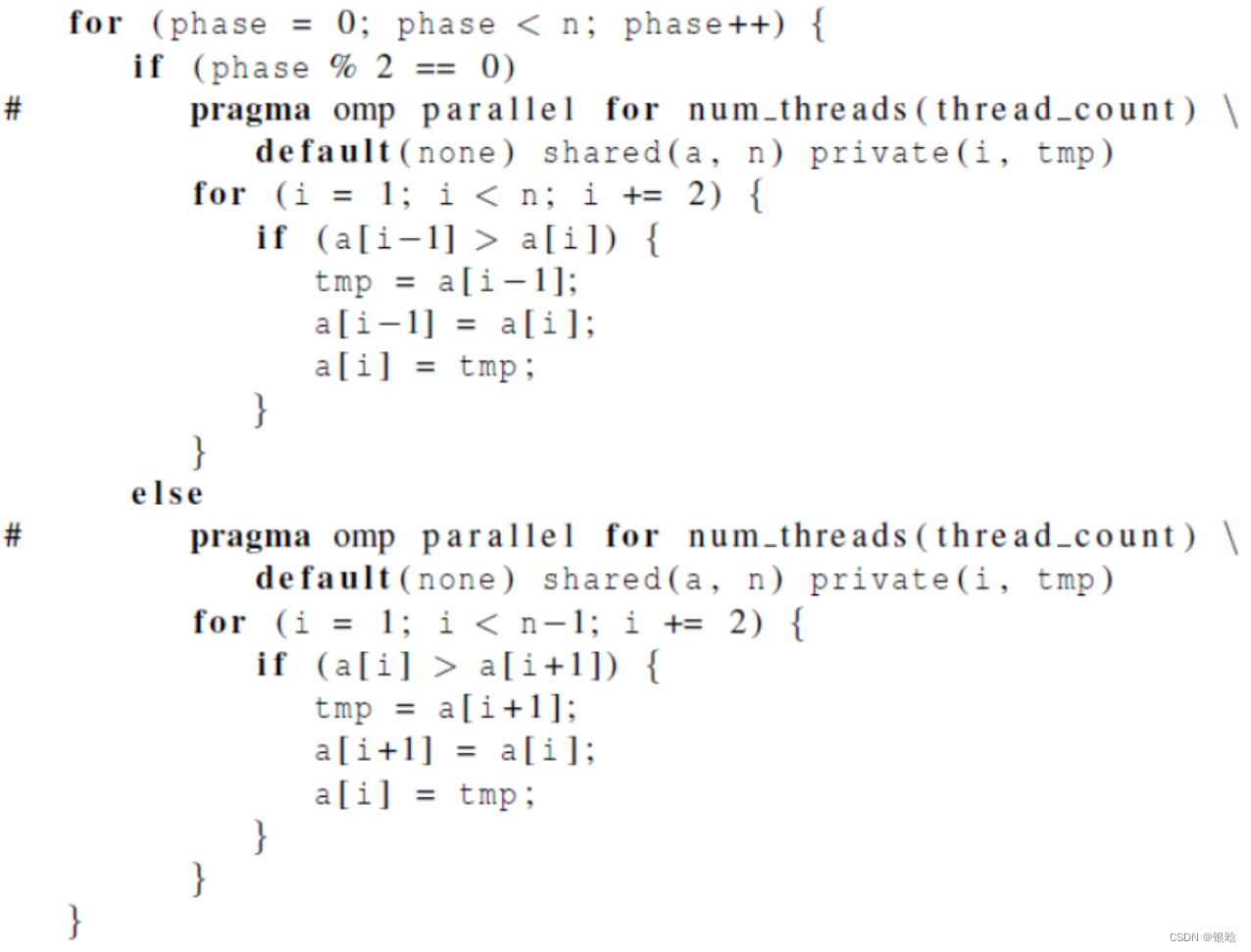
- OpenMP并行实现(版本2):用两个for循环来实现奇偶

double omp_get_wtime(void): 返回从某个特殊点所经过的时间,单位秒;(这个时间点在程序运行过程中必须是一致性)
- 两个方案对比:
循环调度
OpenMP中,任务调度主要用于for循环的并行。当循环中每次迭代的计算量不等时,如果简单地给各个线程分配相同次数的迭代,则会造成各个线程计算负载不均衡,使得有些线程先执行完、有些后执行完,造成某些CPU核空闲,影响程序性能。
更好的方案是轮流分配线程的工作

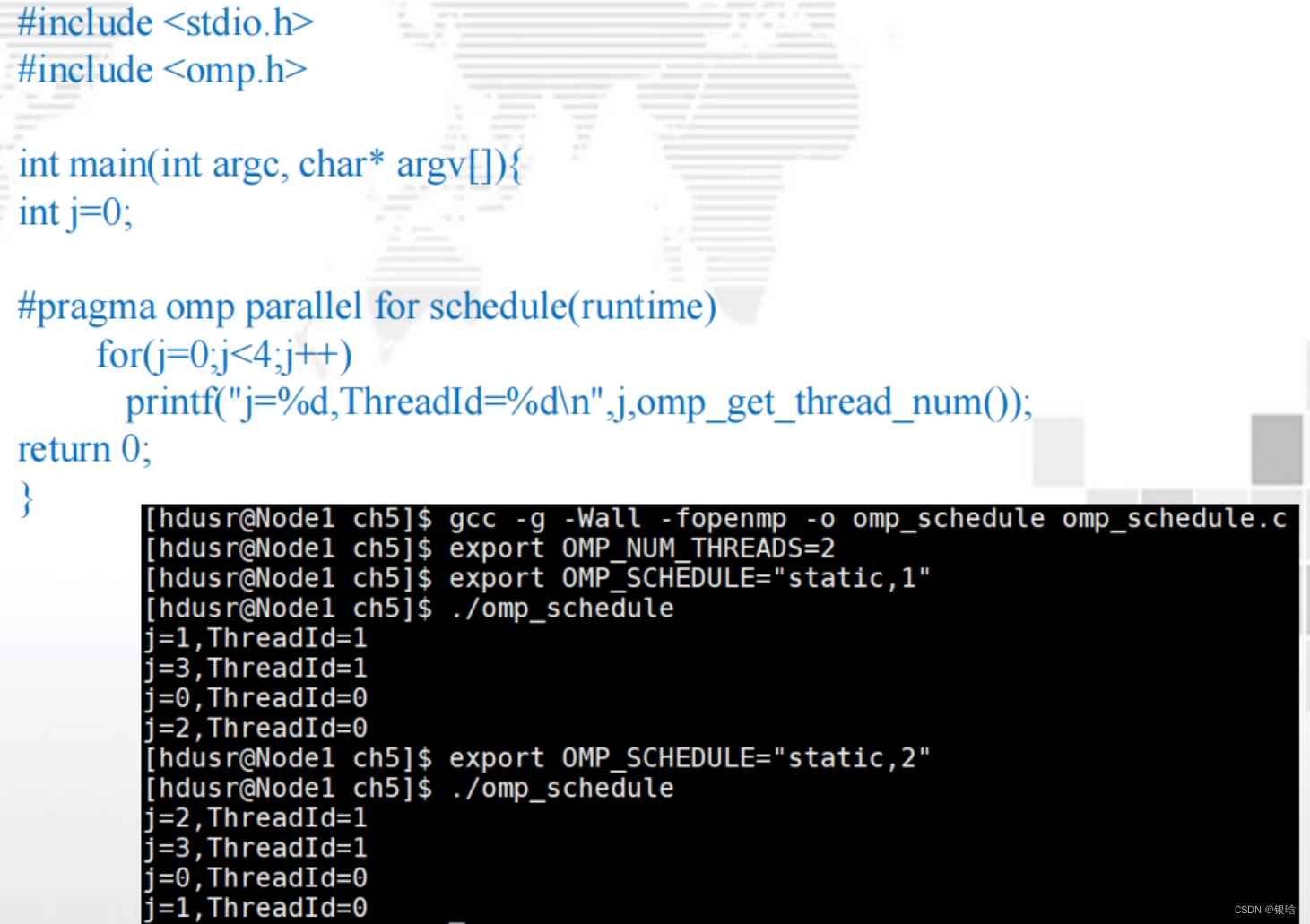
schedule子句
OpenMP中,对for循环并行化的任务调度可使用schedule子句来实现。
schedule(<type[< chunksize >]>)
type的类型:
-
static:迭代能够在
循环执行前分配给线程系统,以轮转的方式将任务分配给线程; -
dynamic 或 guided :迭代
循环执行时被分配给线程- 在循环执行时被分配给线程,因此在一个线程完成了它的当前迭代集合后,它能从运行时系统
中请求更多 。 - 迭代被分成chunksize(默认为1)大小的连续迭代任务块
- 每个线程执行一块,执行完之后,将向系统请求另一块,新块大小会变化,越来越小
- 在循环执行时被分配给线程,因此在一个线程完成了它的当前迭代集合后,它能从运行时系统
-
runtime:调度在
运行时决定- 当 schedule(runtime) 指定时 , 系统使用环境变量
- OMP_SCHEDULE 在 运 行 时 来 决 定 如 何 调 度 循 环 。
export OMP_SCHEDULE="static,1"- OMP_SCHEDULE可能会呈现任何能被static、dynamic或guided调度所使用的值。
- 当type参数类型为runtime时,
chunksize参数是非法的。
-
auto :编译器和运行时系统决定调度方式
chunksize是一个正整数,是块中的迭代次数 ,一次分配一个线程几个数
- 调度开销:
guided>dynamic>static- 如果我们断定默认的调度方式性能低下,那么我们会做大量的试验来寻找最优的调度方式和迭代次数。
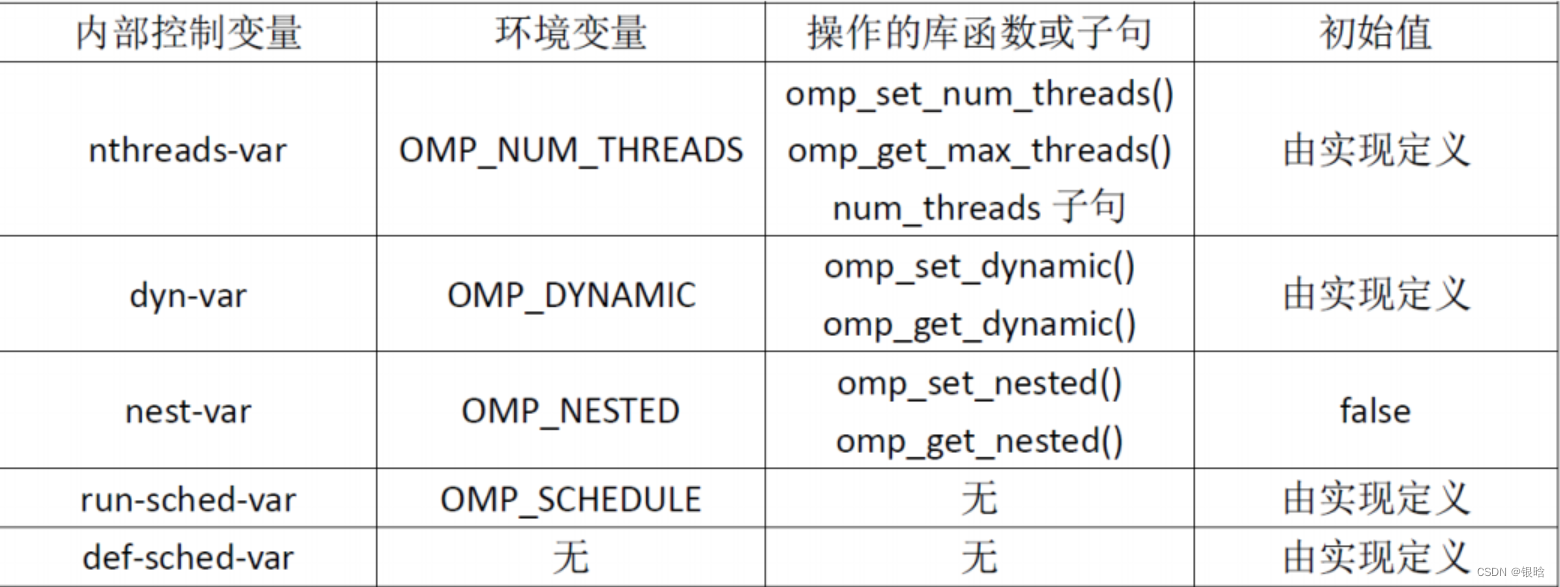
环境变量
定义:环境变量是能够被运行时系统所访问的命名值,即它们在程序的环境中是可得的。
- Linux系统常见环境变量:PATH、HOME、SHELL
使用export命令设置环境变量值 export OMP_DYNAMIC=TRUE
OpenMP的环境变量主要有四个:
-
OMP_DYNAMIC
- FALSE:允许函数omp_set_num_thread()或者num_threads子句设置线程的数量;
- TRUE:那么运行时会根据系统资源等因素进行调整,一般而言,生成与CPU数量相等的线程就是最好的利用资源了。
-
OMP_NUM_THREADS
- OMP_NUM_THREADS环境变量主要用来设置parallel并行区域的默认线程数量。
- 必须OMP_DYNAMIC为FALSE时,OMP_NUM_THREADS环境变量才起作用。
指定线程数目的方法:
1. 不指定,即默认为处理器的核数;
2. 使用库函数omp_set_num_threads(int num)
3. 在#parama omp parallel num_threads(num)
4. 使用环境变量
$gcc –fopenmp -o 1 1.c
$OMP_NUM_THREADS =4
$export OMP_NUM_THREADS//设置环境变量值
-
OMP_NESTED
- OMP_NESTED为TURE时,将启动嵌套并行
- 可以使用omp_set_nested()函数用参数0调用来停止嵌套并行
-
OMP_SCHEDULE
- 主要是用来设置调度类型,只有在schedule子句的参数为runtime时才有效

- 主要是用来设置调度类型,只有在schedule子句的参数为runtime时才有效
内部控制变量
子句:
schedule:调度任务实现分配给线程任务的不同划分方式
函数:
omp_get_wtime():计算OpenMP并行程序花费时间
omp_set_num_thread(): 设置线程的数量
OpenMP实现生产者&消费者
生产者/消费者模型描述的是有一块缓冲区作为仓库,生产者可将产品放入仓库,消费者可以从仓库中取出产品,模型图如下所示:

- 三种关系:消费者和消费者;生产者和生产者;生产者和消费者;
- 两类角色:指的是生产者和消费者;
- 一个交易场所:交易场所指的是生产者和消费者之间进行数据交换的仓库,这块仓库相当于一个缓冲区,生产者负责把数据放入到缓冲区中,消费者负责把缓冲区中的数据取出来
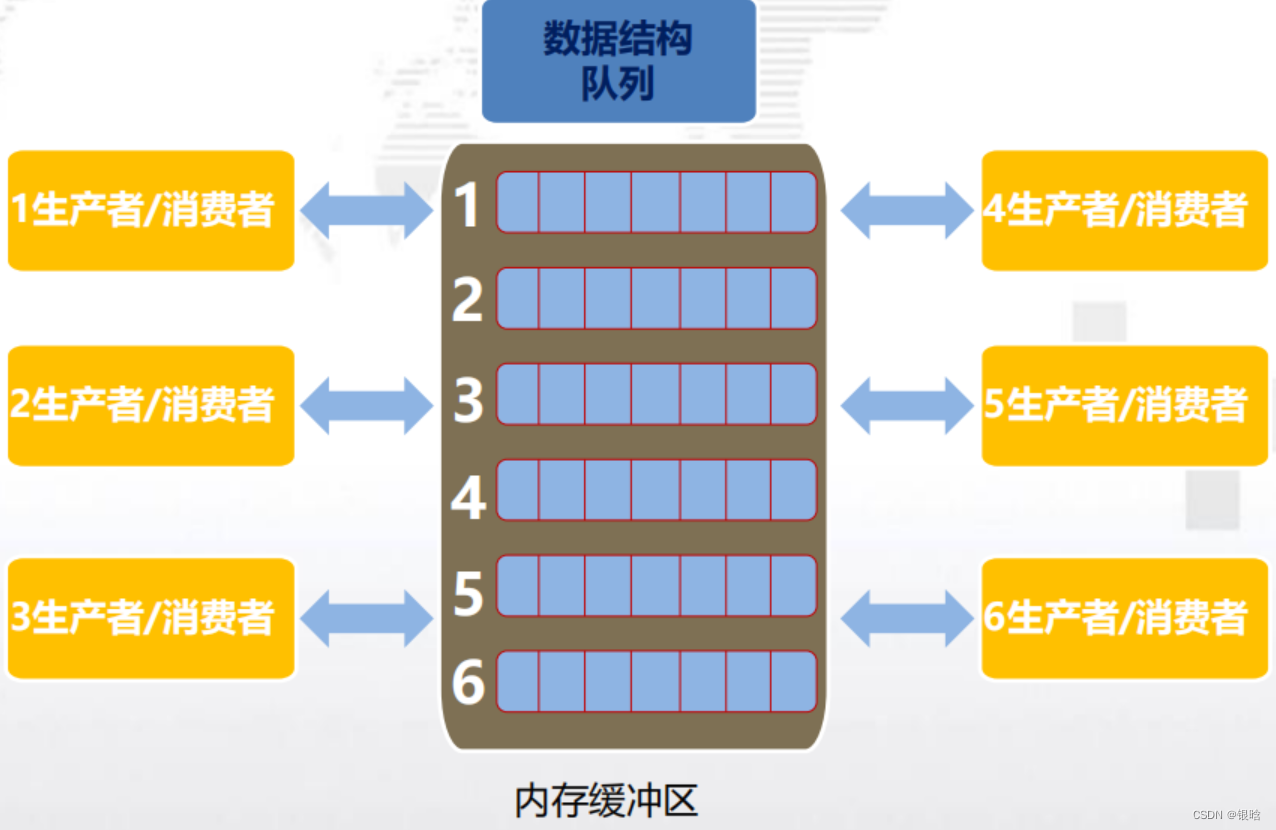
队列
- 队列是一种抽象的数据结构,插入元素时将元素插入到队列的尾部,而读取元素时,队列头部的元素被返回并从队列中被移除(先进先出)
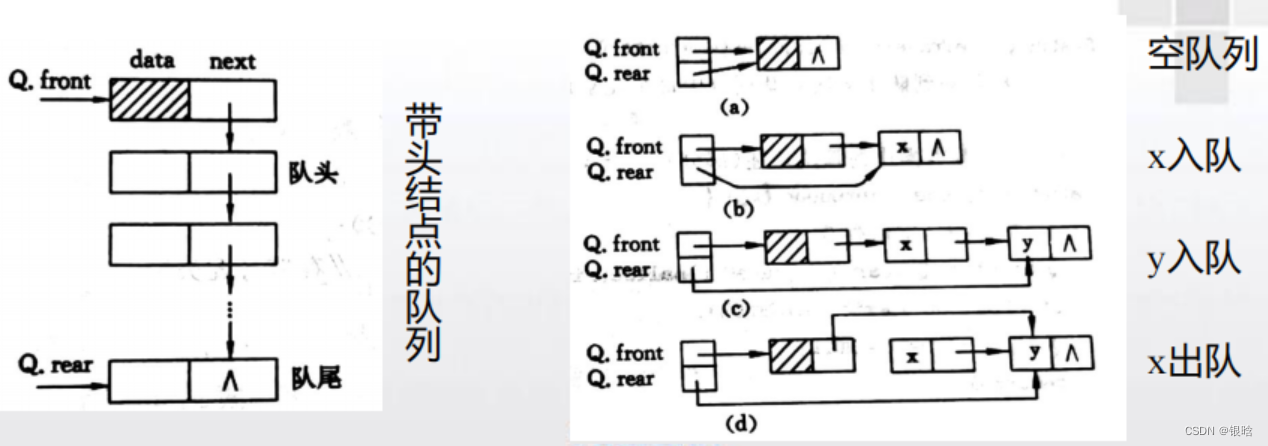
队列中的元素就是消费者
消息传递
生产者和消费者模型的另外一个应用:共享内存系统上实现多线程消息传递。
每一个线程有一个共享消息队列,当一个线程要向另外一个线程发送消息时,它将消息放入目标线程的消息队列中一个线程接收消息时,只需从它的消息队列的头部取出消息。
-
每个线程交替发送和接收消息,用户需要指定每个线程发送消息的数目。
-
当一个线程发送完所有消息后,该线程不断接收消息直到其他所有的线程都已完成,此时所有线程都结束了。
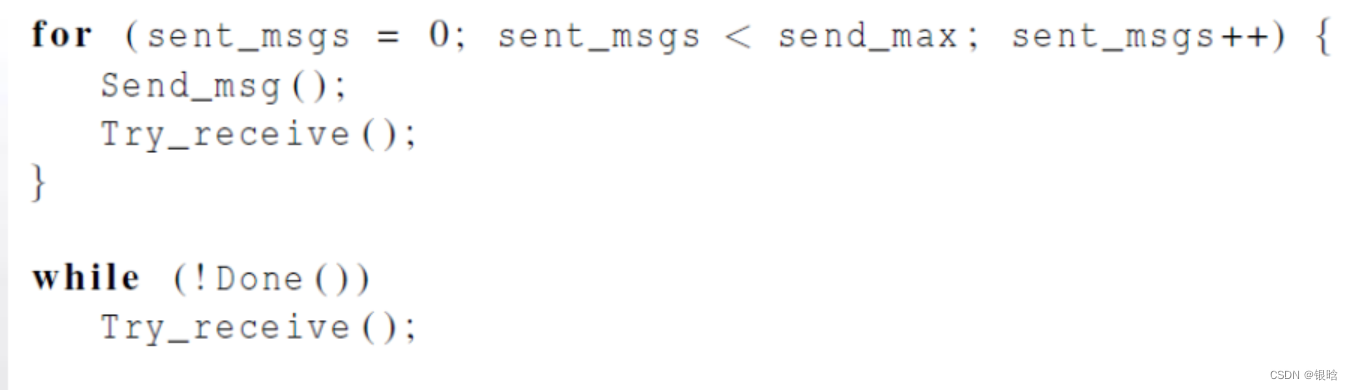
发送消息
注意:访问消息队列并将消息入队,可能是一个临界区
- 消息入队需要一个变量来跟踪队列的尾部
- 如,使用一个单链表实现消息队列,链表的尾部对应队列尾部。然后,为了有效地进行入队操作,需要存储指向链表尾部的指针
- 当一条新消息入队时,需要检查和更新这个队尾指针
- 如果两个线程试图同时更新队尾指针,可能会丢失一条已经由其中一个线程入队的消息

接收消息
接收消息的临界区问题与发送消息有些不同。
- 只有消息队列的拥有者(即目标线程)可以从给定的消息队列中获取消息。
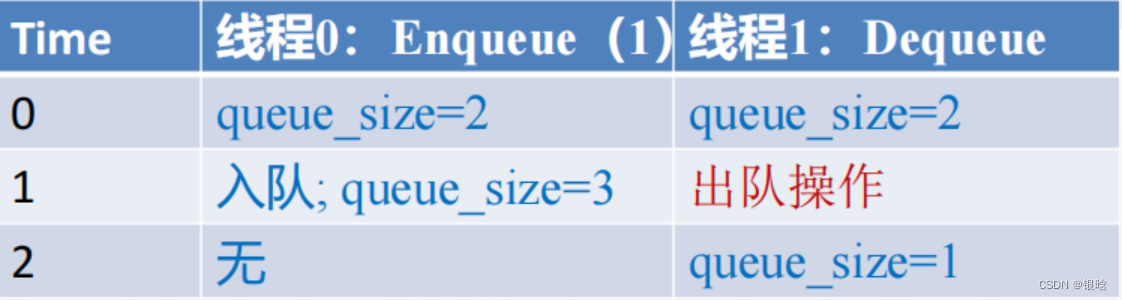
- 如果消息队列中至少有两条消息,只要每次只出队一条消息,那么出队操作和入队操作就不可能冲突。因此如果队列中至少有两条消息,通过跟踪队列的大小就可以避免临界区问题。
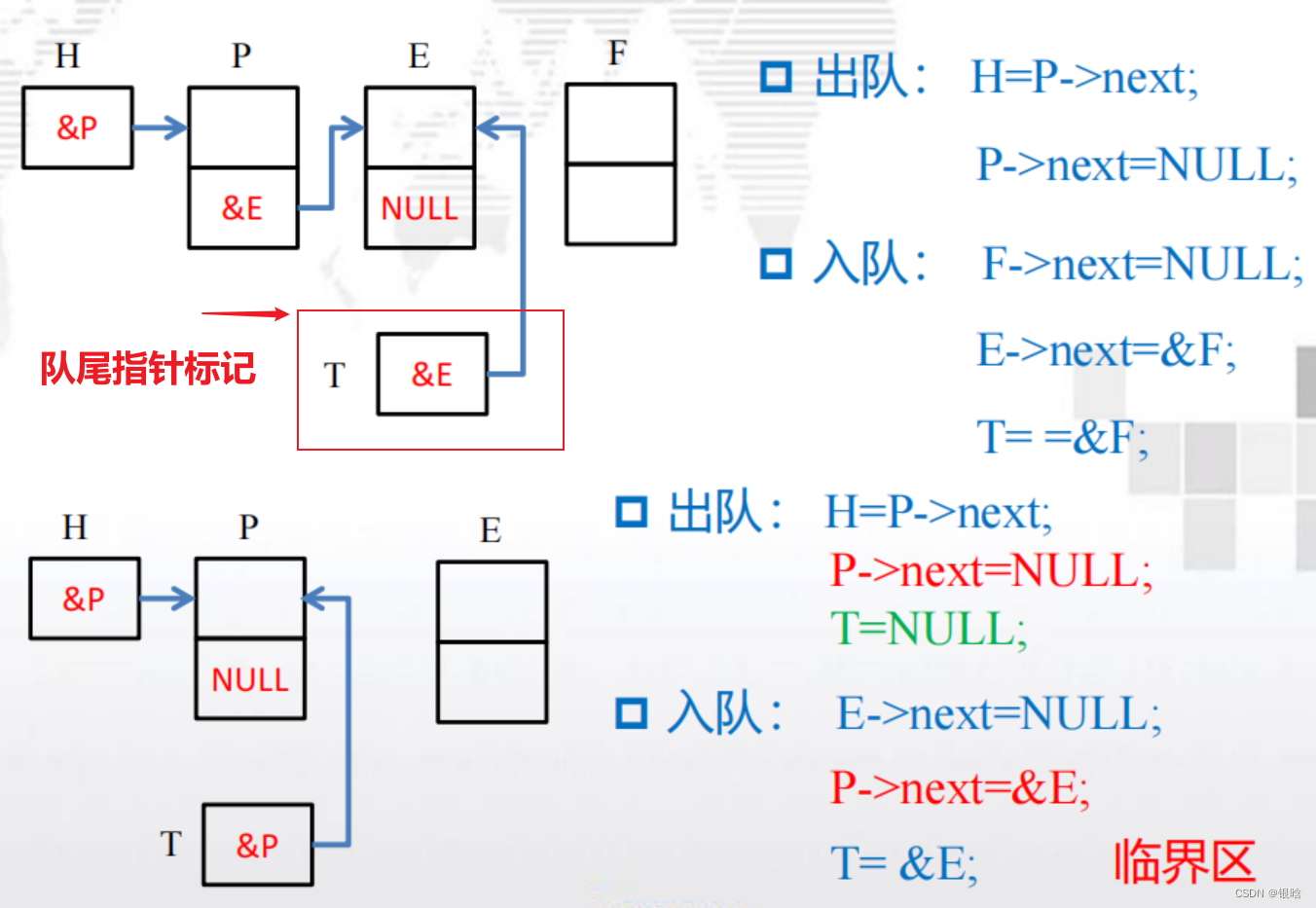

- 如何存储或计算队列大小queue_size?
如果只使用一个变量来存储队列大小,那么对该变量的操作会形成临界区(有冲突)
如下:
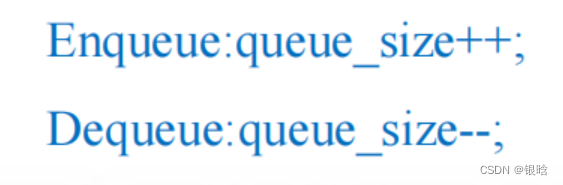
-
解决方案:
可以使用两个变量:enqueued和dequeued,那么队列中消
息的个数(队列的大小)就为queue_size = enqueued – dequeued- 唯一能够更新dequeued的线程是消息队列的拥有者。
- 对于enqueued,可以在一个线程使用enqueued计算队列大小的同时,另外一个线程可以更新enqueued.
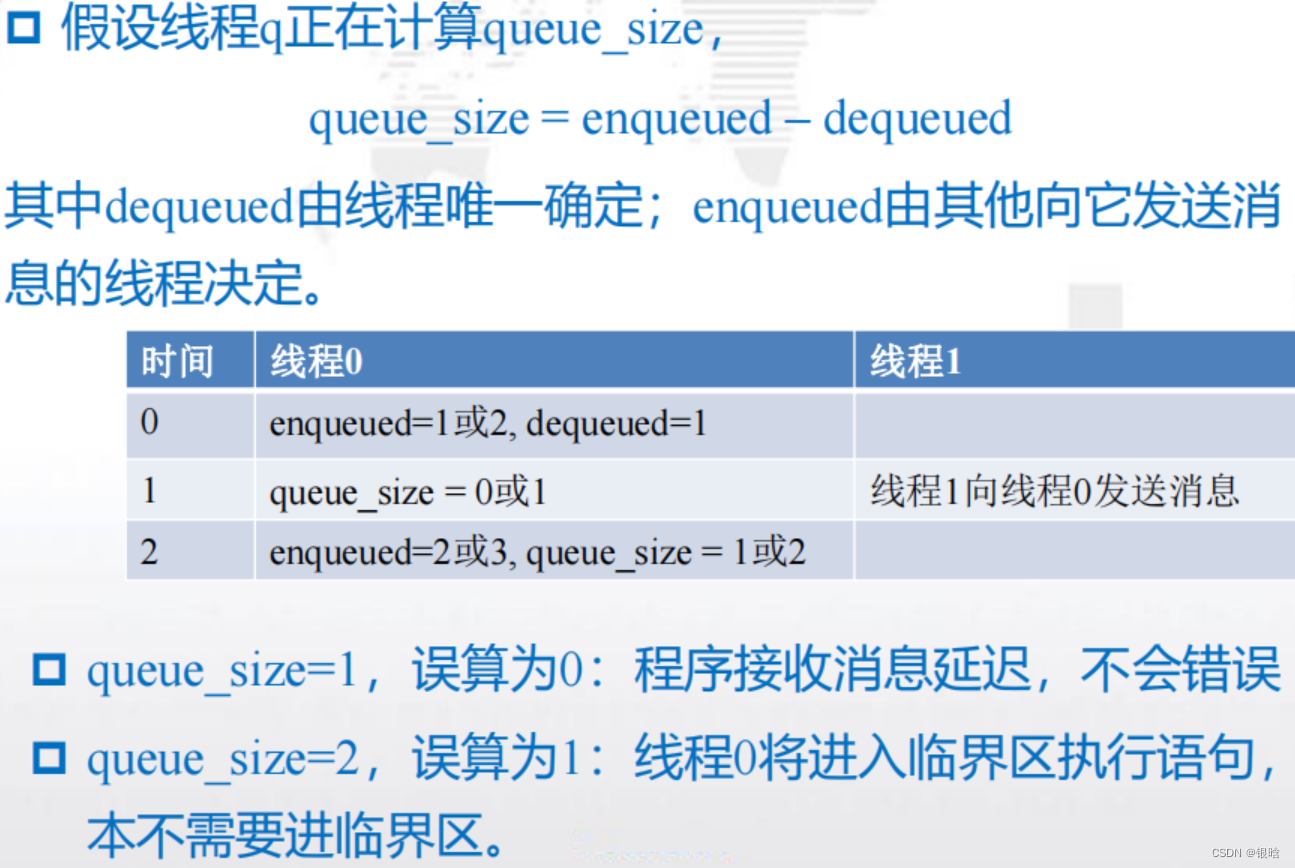
终止检查
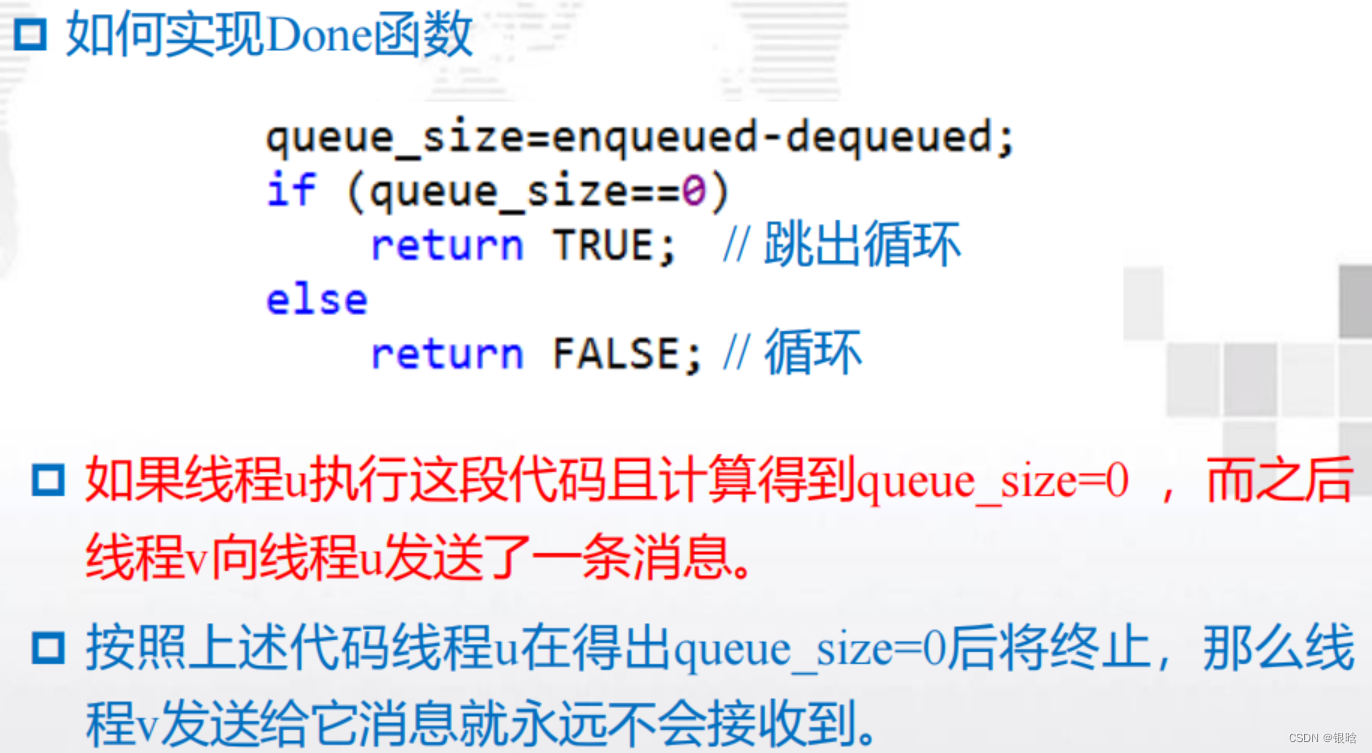
- 解决方案:
在我们的程序中,每个线程在执行完for循环后将不再发送任何消息。
可设置一个计数器done_sending,每个线程在for循环结束后将该计数器加1, Done的实现如下:
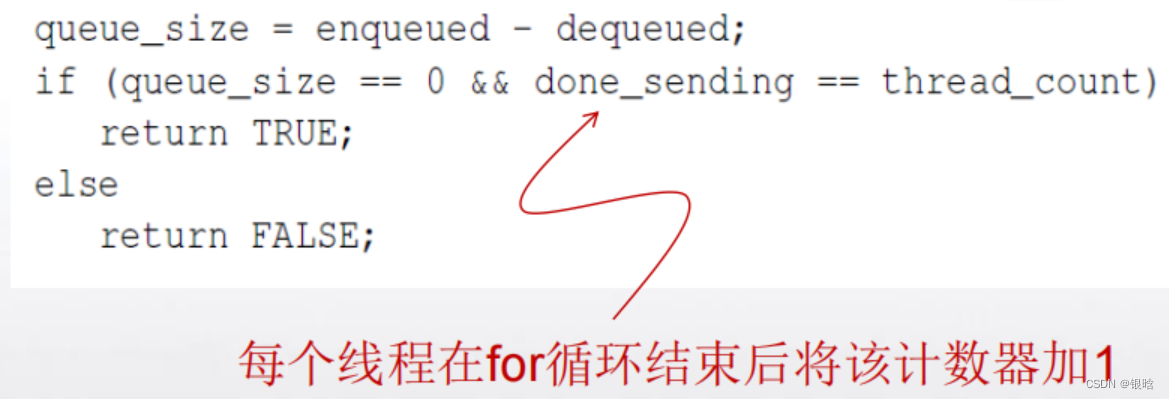
启动
- 当程序开始执行时,主线程将得到命令行参数并且分配一个消息队列的数组,每个线程对应着一个消息队列。
- 由于每个线程可以向其它任意的线程发送消息,即每个线程可以向任何一个消息队列插入一条消息,所以这个队列数组应该被所有的线程共享。
队列分配问题
问题:一个或多个线程可能在其它线程之前完成它的队列分配。那么完成分配的线程可能会试图开始向那些还没有完成队列分配的线程发送消息,这将导致程序崩溃。
必须确保任何一个线程都必须在所有线程都完成了队列分配后才开始发送消息
解决: 需要一个显式路障,使得当线程遇到路障时,它将被阻塞,直到组中所有的线程都达到这个路障。
- 隐式路障:OpenMP指令结束。
- 显式路障:OpenMP指令中间,如parallel块的中间。

- 阻塞:线程组中的线程都达到这个路障之后将接着往下执行。
atomic
用来解决临界区的问题的
critical指令
atomic指令:只能保护由一条C语言赋值语句所形成的临界区。#pragma omp atomic
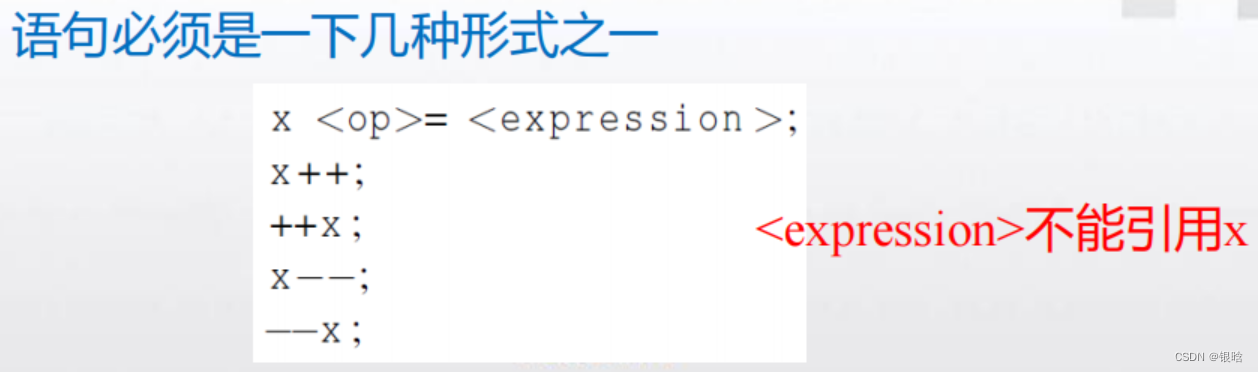
思想:
许多处理器提供专门的装载-修改-存储指令
使用这种专门的指令而不使用保护临界区的通用结构,可以更高效地保护临界区。
消息队列的结构:
1. 消息列表
2. 队尾指针
3. 队首指针
4. 入队消息的数目
5. 出队消息的数目
为了减少参数传递时复制的开销,最好使用指向结构体的指针数组来实现消息队列
一个数组,若其元素均为指针类型数据,称为指针数组。即指针数组中的每一个元素都相当于一个指针变量。
类型名 *数组名[数组长度]; 如int *p[4];



条件编译

锁
- 锁机制:用于需要互斥的是某个数据结构而不是代码块的情况。
指令:
atomic指令: 实现互斥访问最快的方法。
critical指令:保护临界区,实现互斥访问。
函数:
void omp_init_lock(omp_lock_t*lock);//初始化锁
void omp_destroy_lock(omp_lock_t*lock)//销毁锁
void omp_set_lock(omp_lock_t*lock);//尝试获得锁
void omp_unset_lock(omp_lock_t*lock);//释放锁
OpenMP的编译命令
$gcc -g -Wall -fopenmp -o outputdir filename.c
$./outputdir