并行与分布式计算:并行程序设计的基本原则(三)
鱼生苦短,争取更咸!!!
Section 3 并行程序的基本设计原则
设计一个并行程序,一般是从两方面出发的:
- 从实际工程的角度考虑,我们一般试图改进已有的串行程序,而不是凭空创造并行程序,这就是所谓的增量并行化原则
- 从并行设计的角度考虑,我们一般采用Foster的抽象模型,从而设计出逻辑严密结构清晰效率很高的并行程序
下面我们一一进行介绍
3.1 增量并行化
一般并行程序的设计过程
- 研究一个串行程序
- 寻找串行性能瓶颈和并行化可能
- 尝试使所有处理器开始干活吧!
3.2 Foster的设计理念(四步法)
划分、通信、聚集、映射(吐槽:罗老师的PPT接下来的部分完全照抄了教材)
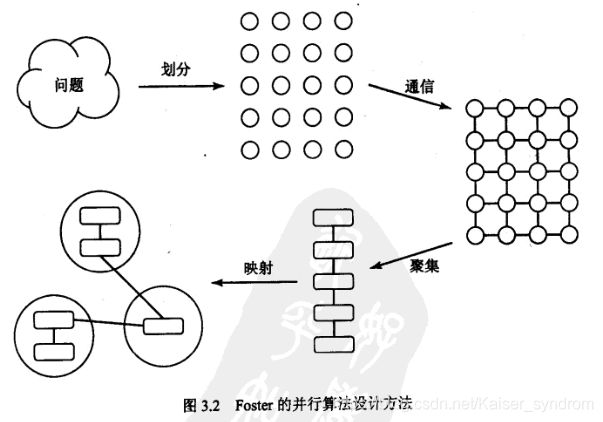
3.2.1 划分
主要内容:选取合适的方式将计算和数据分成小模块
- 考虑方向一:如何最大化利用数据并行(即所谓的域分解)
- 将数据分成小块
- 决定如何将计算与数据结合(通常考虑最大和最频繁访问的数据)
- 考虑方向二:如何最大化利用任务并行
- 将计算分成小块
- 决定如何将数据与计算结合
- 考虑方向三:利用流水线并行性
- 如最大化利用每一个循环
- 尽可能降低initial interval
数据划分
- 决定数据应该如何在处理器间分配
- 决定每一个处理器的计算任务
例子:寻找一个数组中的最大值,数组被均分给n-1个处理器,每个处理器找到最大值,将其汇总到最后一个处理器,这个处理器给出最大值
任务划分
- 将计算任务分配给不同处理器
- 决定哪些数据元素应该被哪些处理器读写
例子:GUI的事件处理器
Pipelining(生产线)
- 装配流水线式并行
- 每一个“工人”只干一件事
- 可以想象,每一个人干完自己的加工部分就把东西传给下一个人,然后从上一个人那里拿到材料重复这个过程
例子:3D渲染
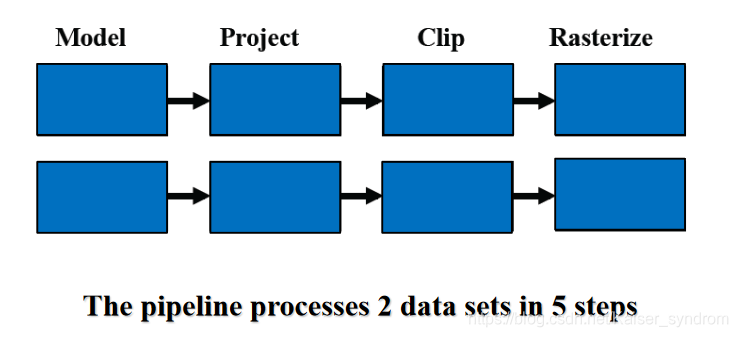 在这个例子里,处理N个data sets,需要N+3步(一个处理器只能同时搞一个数据集,故而每个数据集要排队顺次进入生产线)
在这个例子里,处理N个data sets,需要N+3步(一个处理器只能同时搞一个数据集,故而每个数据集要排队顺次进入生产线)
注意 生产线只能提高产量,不能解决线程间或处理器间交互延迟(这是显然的)
- Initial Interval(II)的限制
-
在上述举例中,四个逻辑单元要流水线式的完成两个数据集的任务,必须让第二个数据集额外等待1 step
-
很显然,当II=1时,总产量将达到最大,但这并不总是可能的
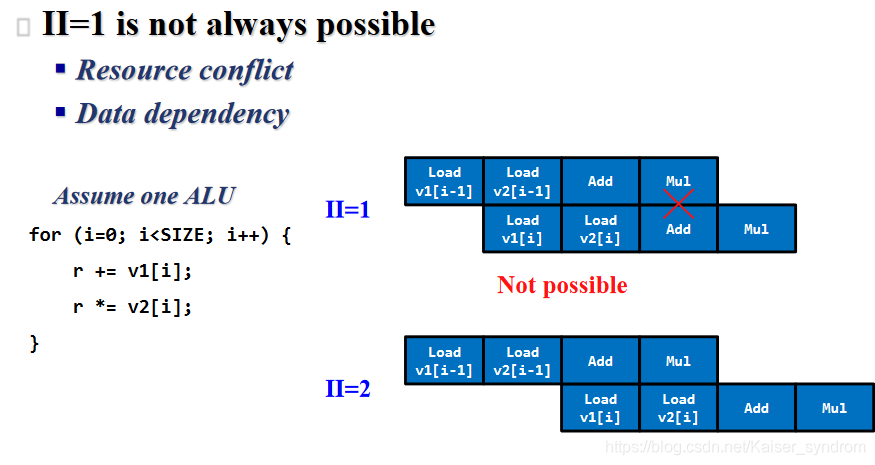
- 在这个例子中,使用1间隔将引发错误(在r*v2和r+v1同时进行了,这就可能引发错误——先加的话结果就错了)
- 第三个处理器加完v1[i-1]第四个处理器开始给r乘v2[i-1],此时第三个处理器也回过头去给r加v1[i]
- 在这个例子中,使用1间隔将引发错误(在r*v2和r+v1同时进行了,这就可能引发错误——先加的话结果就错了)
-
Foster检查表
完成设计后,对划分步骤进行如下考察(后面的检查表也是同理)
- 原始任务至少要比处理器数高一个数量级
- 冗余计算和冗余数据结构存储最小化
- 原始任务的大小大概相同
- 任务数是问题规模的一个增量函数
3.2.2 通信
- 局部通信:部分任务之间通讯的通道
- 全局通信:全部任务间通讯的通道
一般来说,在算法设计阶段为任务规划通信通道并没有什么卵用
Foster检查表
- 平衡任务间的通讯操作
- 每个任务仅仅与少量邻居进行通讯
- 任务能够并发执行通讯
- 任务能够并发执行计算
3.2.3 聚集
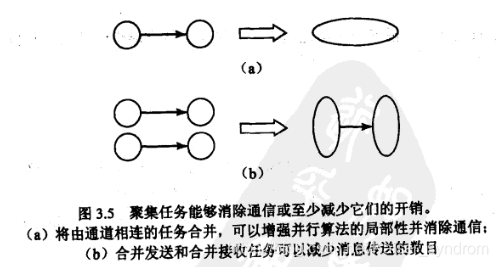
聚集是为了改善性能或简化编程而将任务合并为大的任务的过程。
在MP程序中,一般是每个处理器一个聚集任务
目标
-
降低通信开销
-
将相互通讯的原始任务聚集起来,他们之间的通信就会完全消除
-
合并发送信息的任务组与接受信息的任务组(发送少量长信息比发送总长相等的大量短消息耗时更少)
-
-
维持并行设计的可扩展性
- 例如对8x128x256的矩阵问题的第二维和第三维做聚集是目光短浅的做法,因为这将导致并行算法无法移植到具备8个以上CPU的系统上
-
减少软件工程上的开销
- 如果我们正在对一个串行程序进行并行化,聚集允许我们更多的使用现成的串行代码,节约开发时间和成本
Foster检查表
- 聚集增加了并行算法的局部性
- 复制的计算比它们所替代的通信花费的时间要少
- 复制的数据总量足够小,使得算法具有可扩展性
- 聚集后的任务有相似的计算和通信开销
- 任务数是问题规模的一个增函数
- 任务数尽可能少,但至少要与目标计算机中的处理器数目一样多
- 合理权衡聚集带来的好处与修改现有串行代码的开销
3.2.4 映射
映射是将任务分配给处理器的过程。对于集中式多处理器系统来说,操作系统会自动解决这个问题,所以我们假定目标系统为分布存储的并行计算机
目标
- 最大化处理器的利用率
- 处理器利用率:执行用于求解问题的时间的平均百分比
- 最小化处理器之间的通信
- 尽量将通道相连的任务映射到同一个处理器
- 两者不可兼得,要找一个合理的折中点(不过寻找这个东西的最优解是一个NP难问题,所以这句话的意思是这玩意还得靠感觉…)
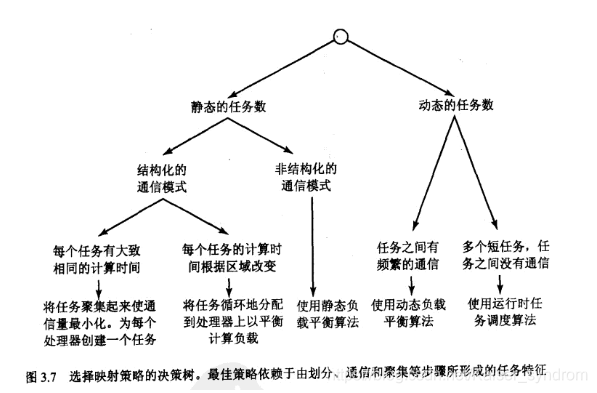
任务数固定时的映射方法
映射方法应因地制宜,平衡利用率与通信消耗
- 对于高度结构化的通讯
- 每个任务都是固定的计算量
- 将任务聚集以减少通讯
- 每个处理器开一个聚集任务
- 每个任务有变化的计算量
- 周期性的将任务分配给处理器
- 每个任务都是固定的计算量
- 对于非结构通讯
- 使用静态负载平衡算法(Static Load Balancing Algorithm)
任务数量动态变化
- 任务间有大量通讯
- 使用动态负载平衡算法(Dynamic Load Balancing Algorithm)
- 有大量执行时间较短的小任务
- 使用伴随程序运行的任务分配方法(Runtime Task-Scheduling Algorithm)
任务数动态变化时常见的任务调度算法
- 集中式算法
- 有一个管理者CPU,工人CPU完成任务时从管理者处申请一个任务,管理者则回复一个任务,工人完成任务后返回解并申请另一个任务
- 分布式算法
- 推:有太多可用任务的处理器将任务分给临近处理器
- 拉:没有任务的处理器向临近处理器请求任务
- 综合算法
总结
Foster检查表
- 是否已经考虑基于一个处理器对应一个任务和一个处理器对应多个任务的设计
- 是否已经评估了静态和动态地将任务分配给处理器
- 动态:管理者是否是性能的瓶颈
- 静态:任务数与处理器个数比例不低于10:1